Downloaded 21 times



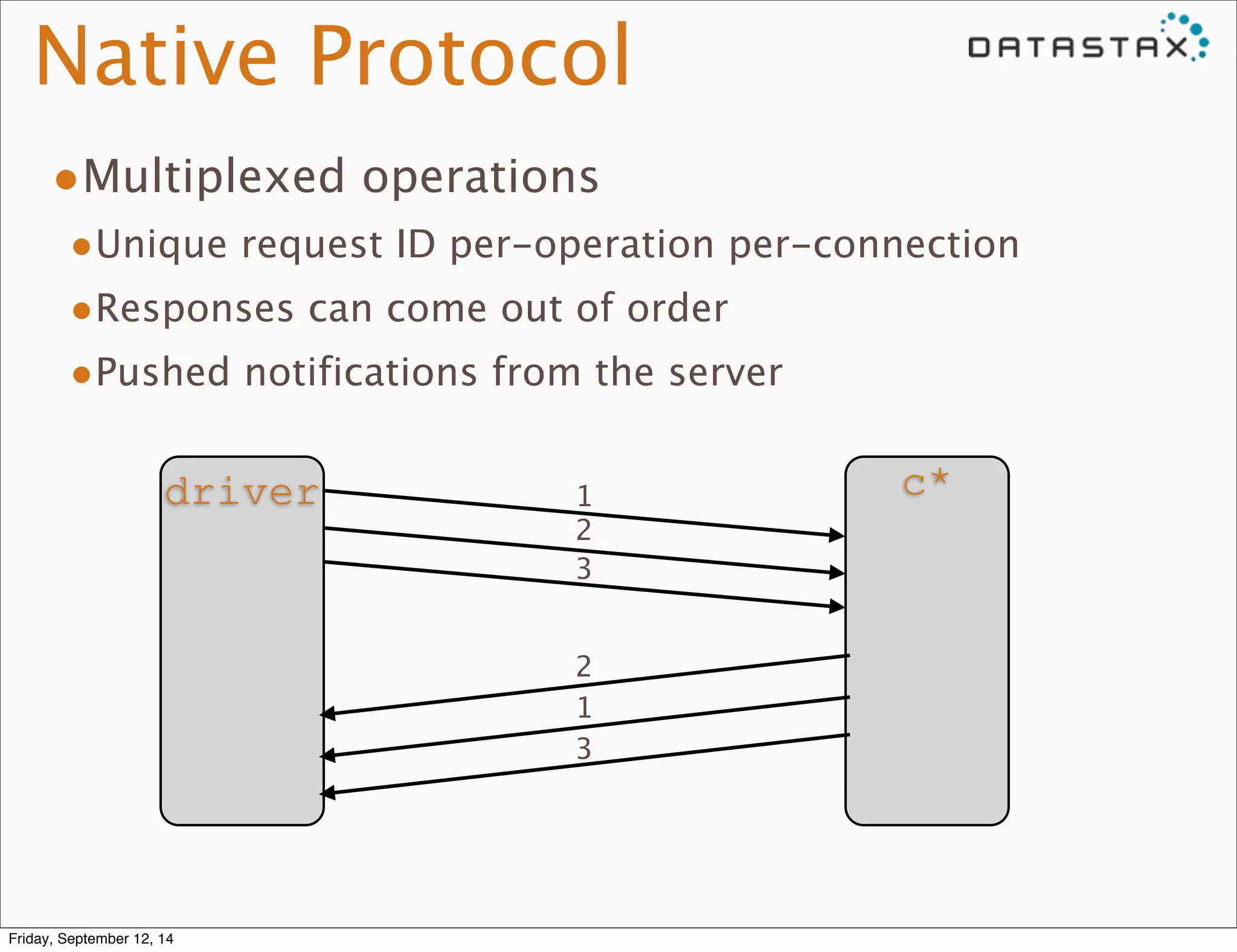































This document summarizes Cassandra's native protocol and data model. It describes how the protocol handles operations like preparation, execution and batching. It explains how CQL statements are parsed and prepared on the server. It also details Cassandra's data model including sparse and dense cell formats for regular and compact storage tables, and how clustering and partition keys define cell names.



























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















