Download as PDF, PPTX














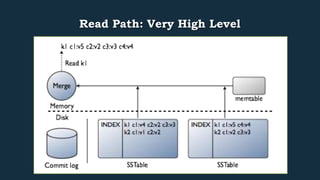
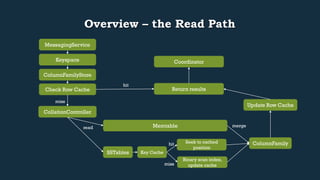


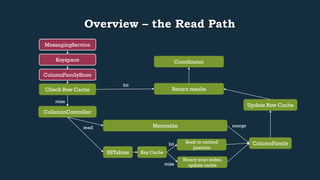

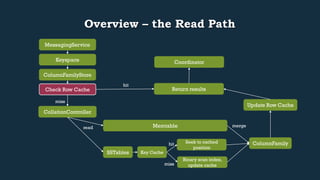

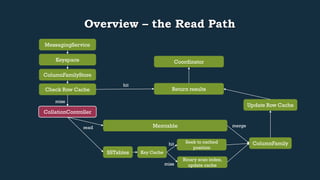

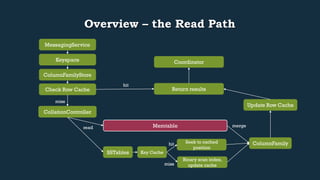

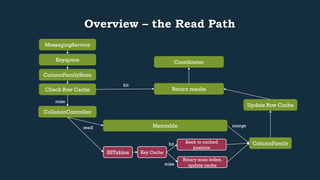

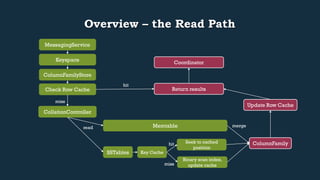

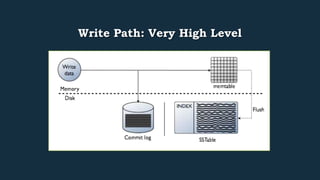
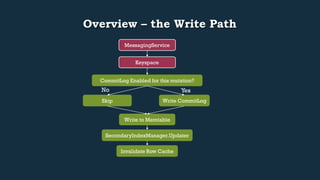

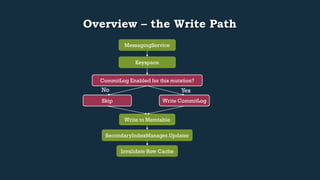




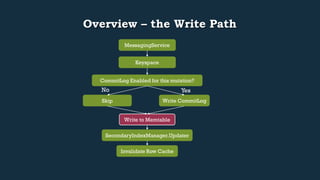


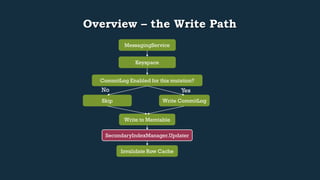

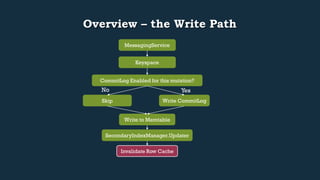

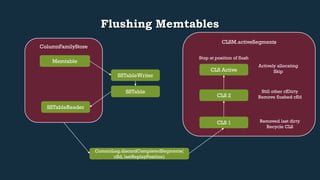





This document provides an overview of Cassandra's read and write paths. It describes the core components involved, including memtables, SSTables, commitlog, cache service, column family store, and more. It explains how writes are applied to the commitlog and memtable and how reads merge data from memtables and SSTables using the collation controller.















































































