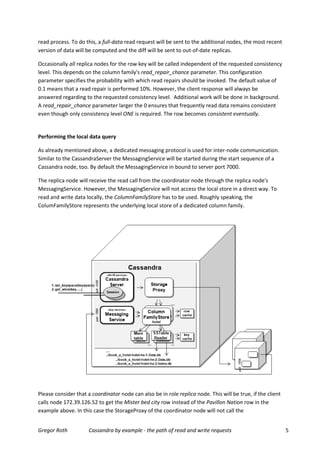
This document details how Cassandra processes read and write requests, exploring its internal architecture and operation paths using a single data center cluster example. It explains the roles of coordinator and replica nodes in handling requests, the interaction between different components like the storage proxy and messaging service, as well as the mechanisms for ensuring data consistency and durability. Additionally, the author discusses the need for configurations such as consistency levels and replication factors in managing requests and data integrity.

![The listing below shows a simple query by using the Hector client library V1.1.
// [1] prepare the client (cluster)
Cluster cluster = HFactory.getOrCreateCluster("TestClstr", "172.39.126.14, 172.39.126.93, 172.39.126.52");
Keyspace keyspaceOperator = HFactory.createKeyspace("book_a_hotel", cluster);
// [2] create the query (fetching the column category)
SliceQuery<String, String, String> query = HFactory.createSliceQuery(keyspaceOperator,
AsciiSerializer.get(), StringSerializer.get(), StringSerializer.get());
query.setColumnFamily("hotel");
query.setKey("26813445");
query.setColumnNames("category");
// [3] perform the request
QueryResult<ColumnSlice<String, String>> result = query.execute();
ColumnSlice<String, String> row = result.get();
String category = row.getColumnByName("category").getValue();
//...
// [4] release the client (cluster)
cluster.getConnectionManager().shutdown();
In the first line of the listing a set of server IP addresses is passed over by creating a Hector Cluster
object. The server address identifies a single Cassandra node. A collection of independent Cassandra
nodes (the Cassandra cluster) represents the Cassandra database. Within this cluster all nodes are
peers. No master node or something like that exists.
The client is free to connect any Cassandra node to perform any request. In the listing above 3
addresses are configured. This does not mean that the Cassandra cluster consist of 3 nodes. It just
defines that the client will communicate with these nodes only.
The connected Cassandra node plays two roles, potentially. In each case the connected node is the
coordinator node which is responsible to handle the dedicated request. Furthermore the connected
node will be a replica store node, if the node is responsible to store a replica of the requested data.
For instance the requested Pavillon Nation hotel record of the example above does not have to be
stored on the connected node. Often the coordinator node has to send sub requests to other replica
nodes to be able to handle the request. As shown in the diagram below the notes 172.39.126.14,
172.39.126.93 and 172.39.126.52 would not able to serve a Pavillon Nation query in a direct way
without sub requesting other nodes.
Gregor Roth Cassandra by example - the path of read and write requests 2](https://image.slidesharecdn.com/cassandrathepathofreadandwriterequests-121014035152-phpapp01/85/Cassandra-by-example-the-path-of-read-and-write-requests-2-320.jpg)



![Processing an write request
To insert, update or delete a row Cassandra's mutate method has to be called. The listing below
shows such a mutate call by using the Hector client.
//...
// [1.b] create and perform an update
Mutator<String> mutator = HFactory.createMutator(keyspaceOperator, AsciiSerializer.get());
mutator.addInsertion("26813445", "hotel",
HFactory.createColumn("category", "5", StringSerializer.get(), StringSerializer.get()));
MutationResult result = mutator.execute();
//...
The write path is very the same to the read path. Similar to the read request a write request also
includes the required consistency level. However, the coordinator node tries to send a write request
including the mutated columns to all replica nodes for the row key.
First, the StorageProxy of the coordinator node checks if enough replica notes for the row key are
alive regarding to the requested consistency level. If this is true, the write request will be sent to the
living replica nodes. If not, an error response will be returned. Write requests to temporarily failed
replica nodes will be scheduled as a hinted handoff. This means that a hint will be written locally
instead calling the failed node. Once the failed replica node is back the hint will be sent to this node
to perform the write operation. By sending the hints the failed nodes becomes consistent to the
other nodes. Please consider that hints will not longer store locally, if the failed node is dead longer
than 1 hour (config param max_hint_window_in_ms).
The coordinator node returns the response to the client as soon as the replica nodes conforming to
the consistency level have confirmed the update (a hinted write will not count towards the
requested consistency level). The updates of the other replica nodes will still be executed in
background. If an error occurs by updating the replica nodes conforming to the consistency level, an
error response will be returned. However, in this case the already updated nodes will not be
reverted. Cassandra does not support distributed transactions, and hence it does not support a
distributed rollback.
The write operation supports an additional consistency level ANY which means that the mutated
columns have to be written to at least one node regardless of whether this node is a replica node for
the key or not. In contrast to consistency level ONE the write will also succeed, if a hinted handoff is
written (by the coordinator node). However, in this case the mutated columns will not be readable
until the responsible replica nodes have recovered.
Gregor Roth Cassandra by example - the path of read and write requests 7](https://image.slidesharecdn.com/cassandrathepathofreadandwriterequests-121014035152-phpapp01/85/Cassandra-by-example-the-path-of-read-and-write-requests-7-320.jpg)

























































































