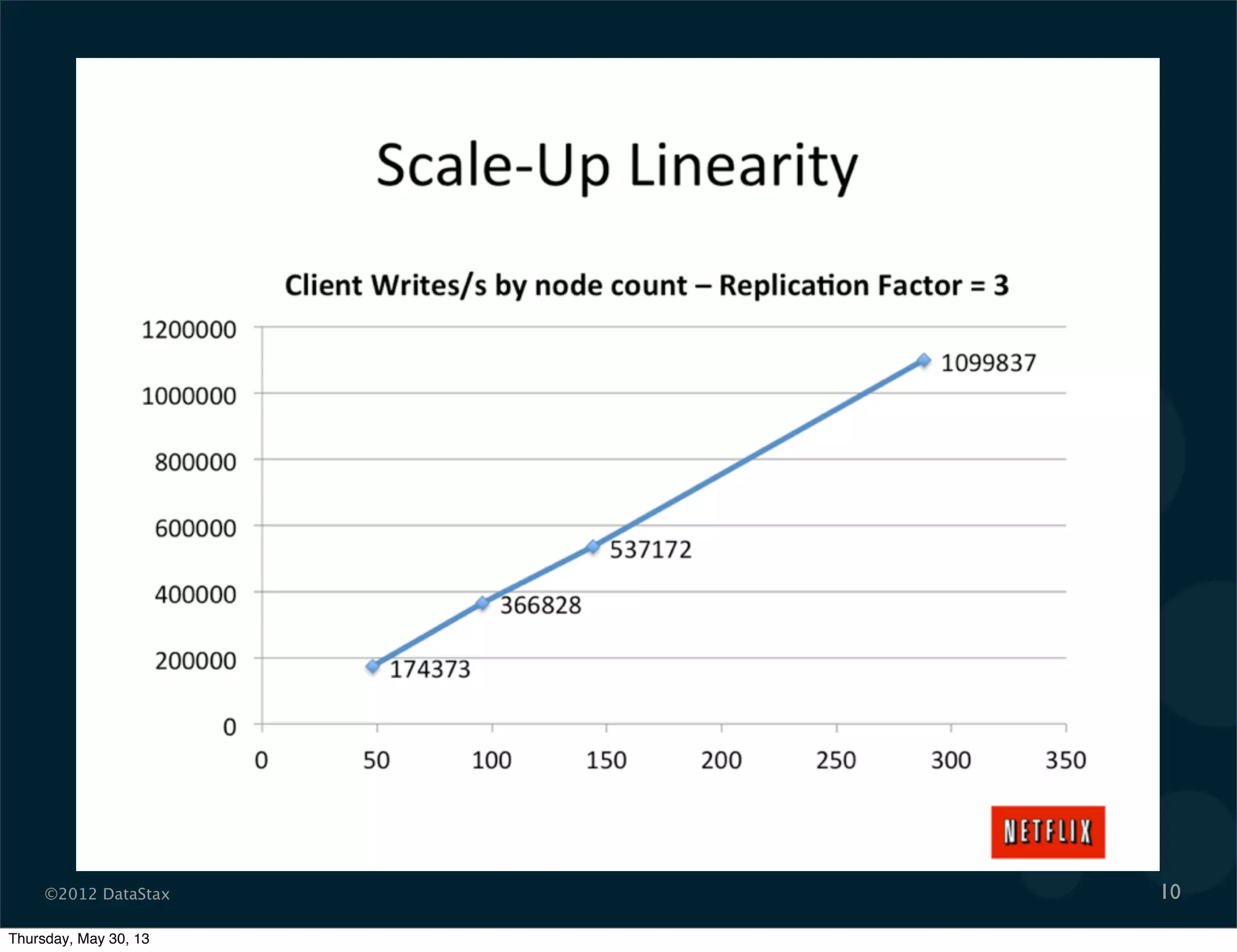
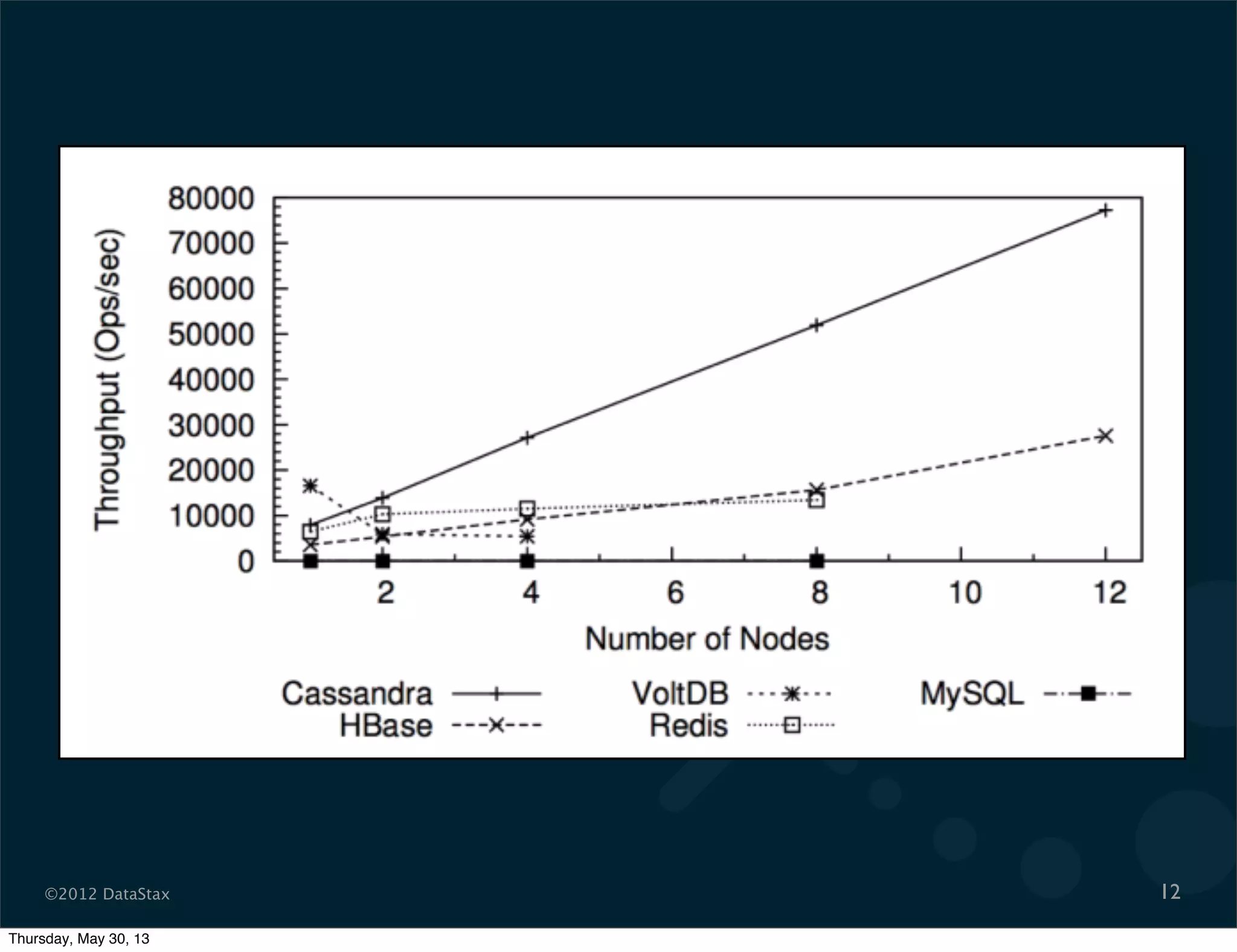
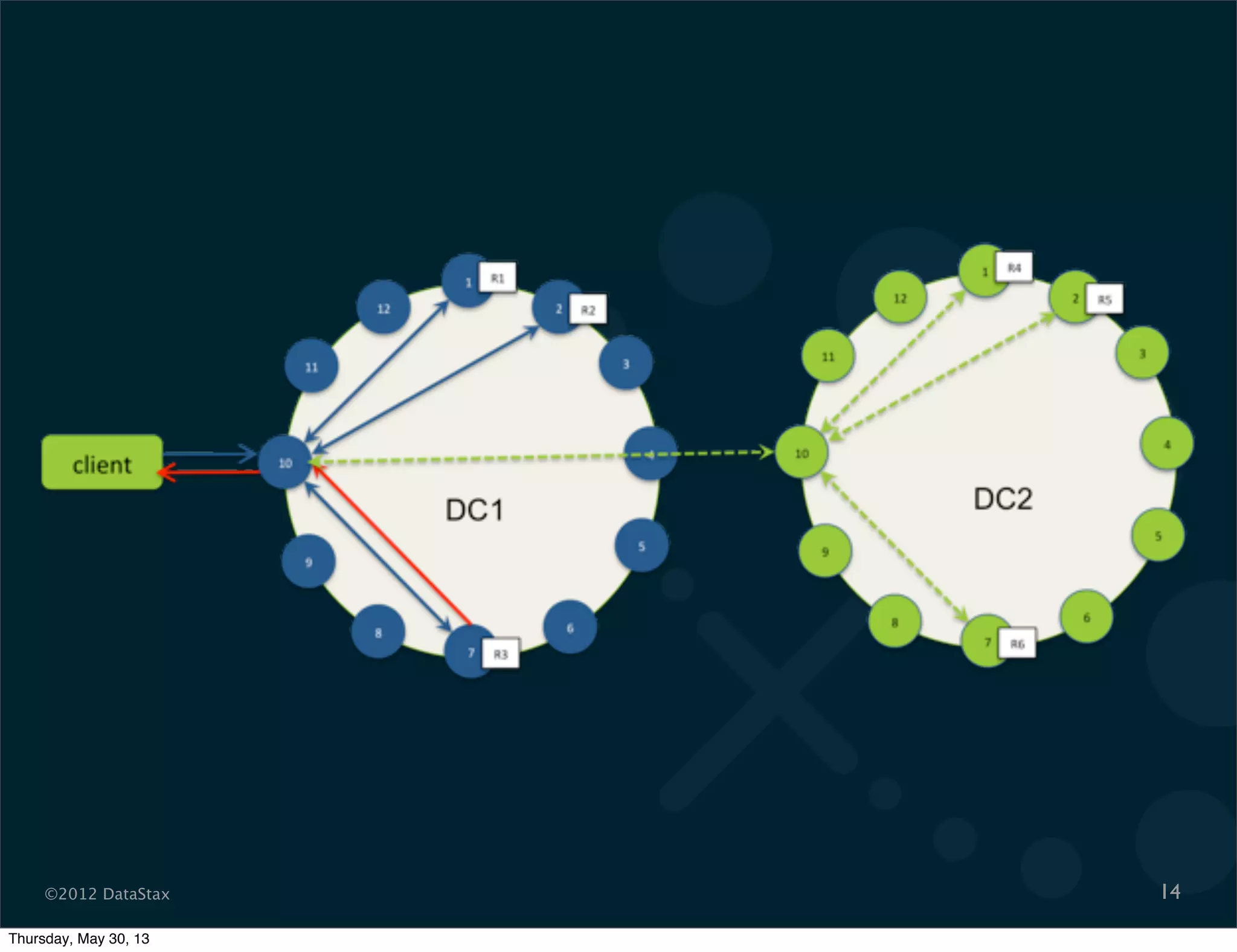
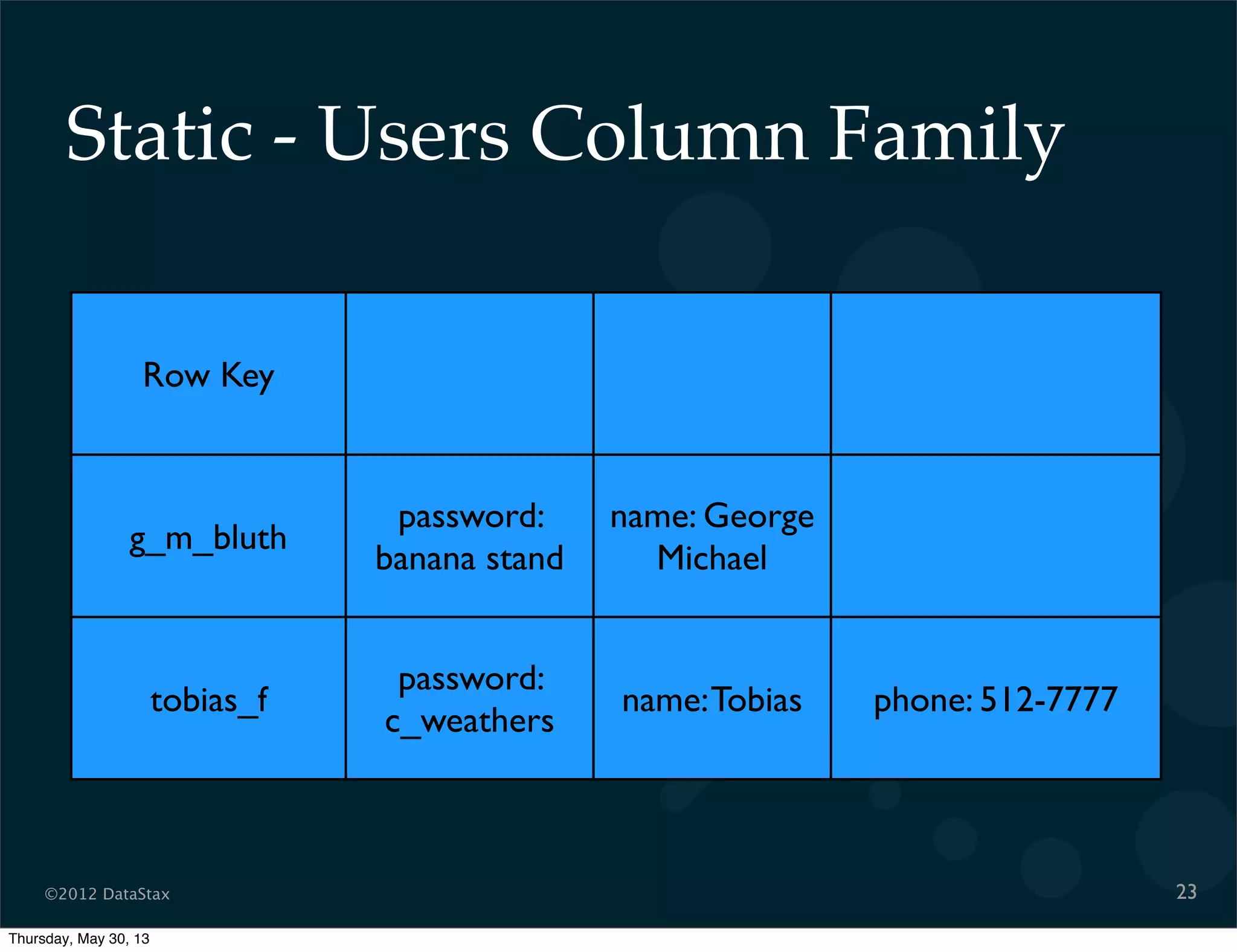
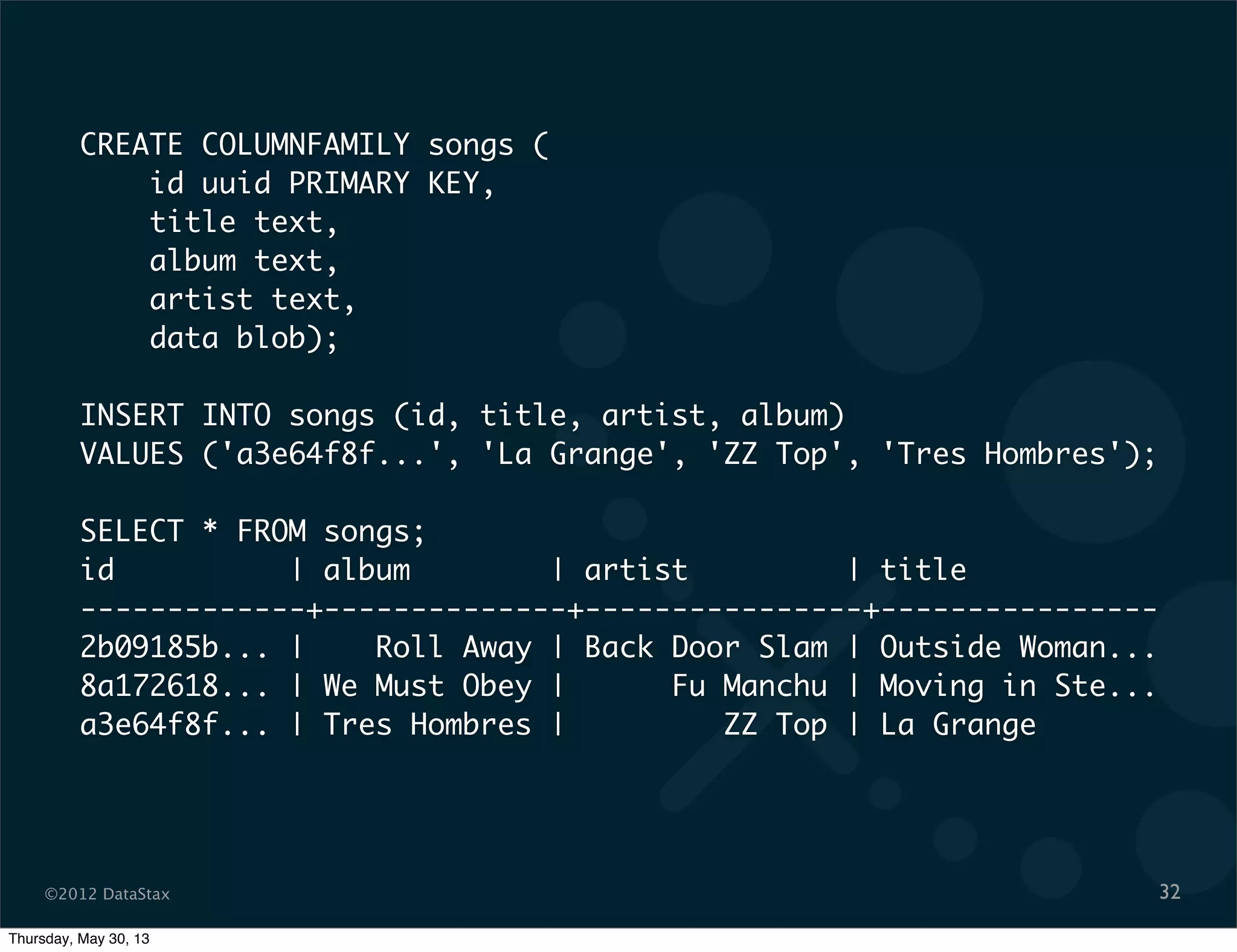
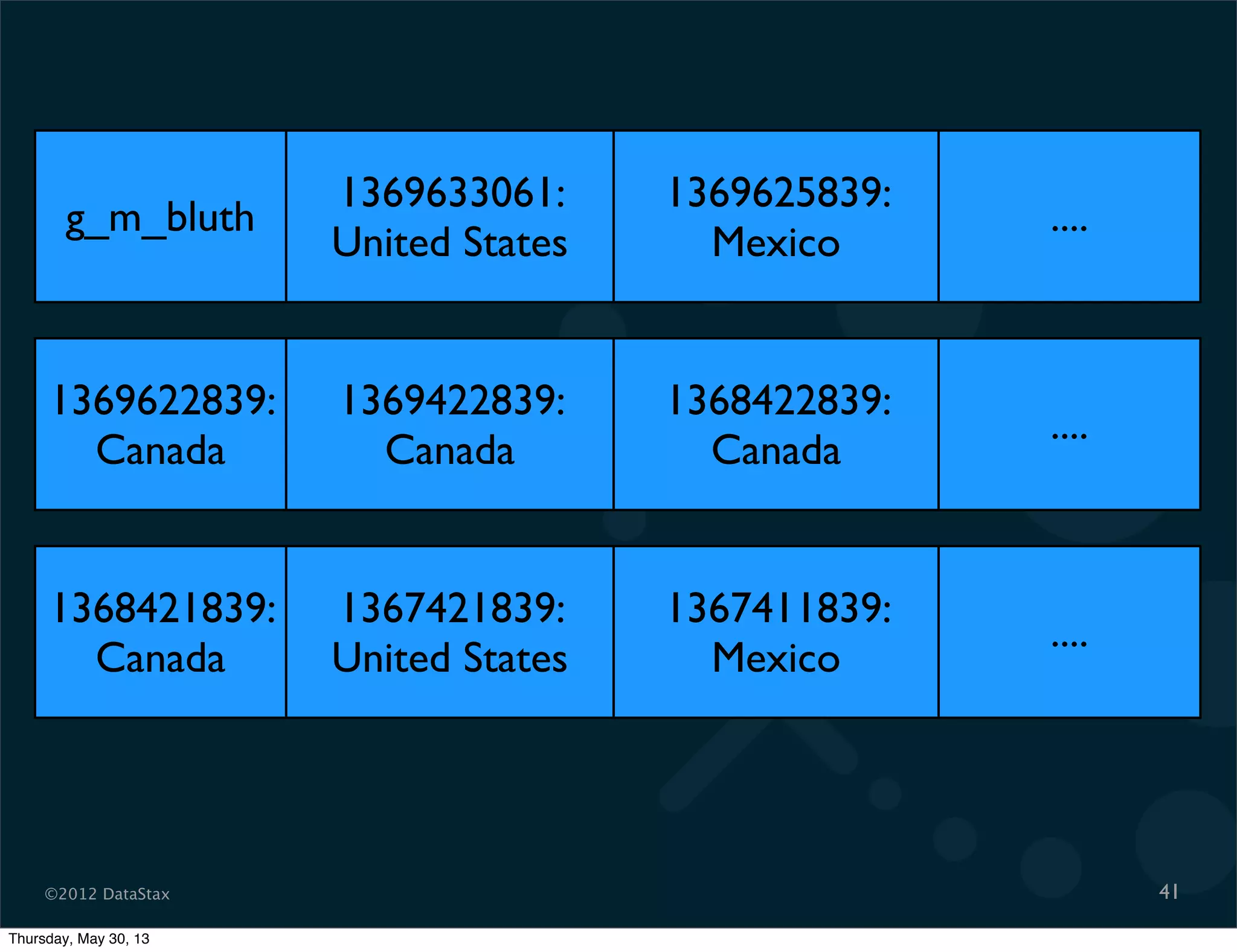
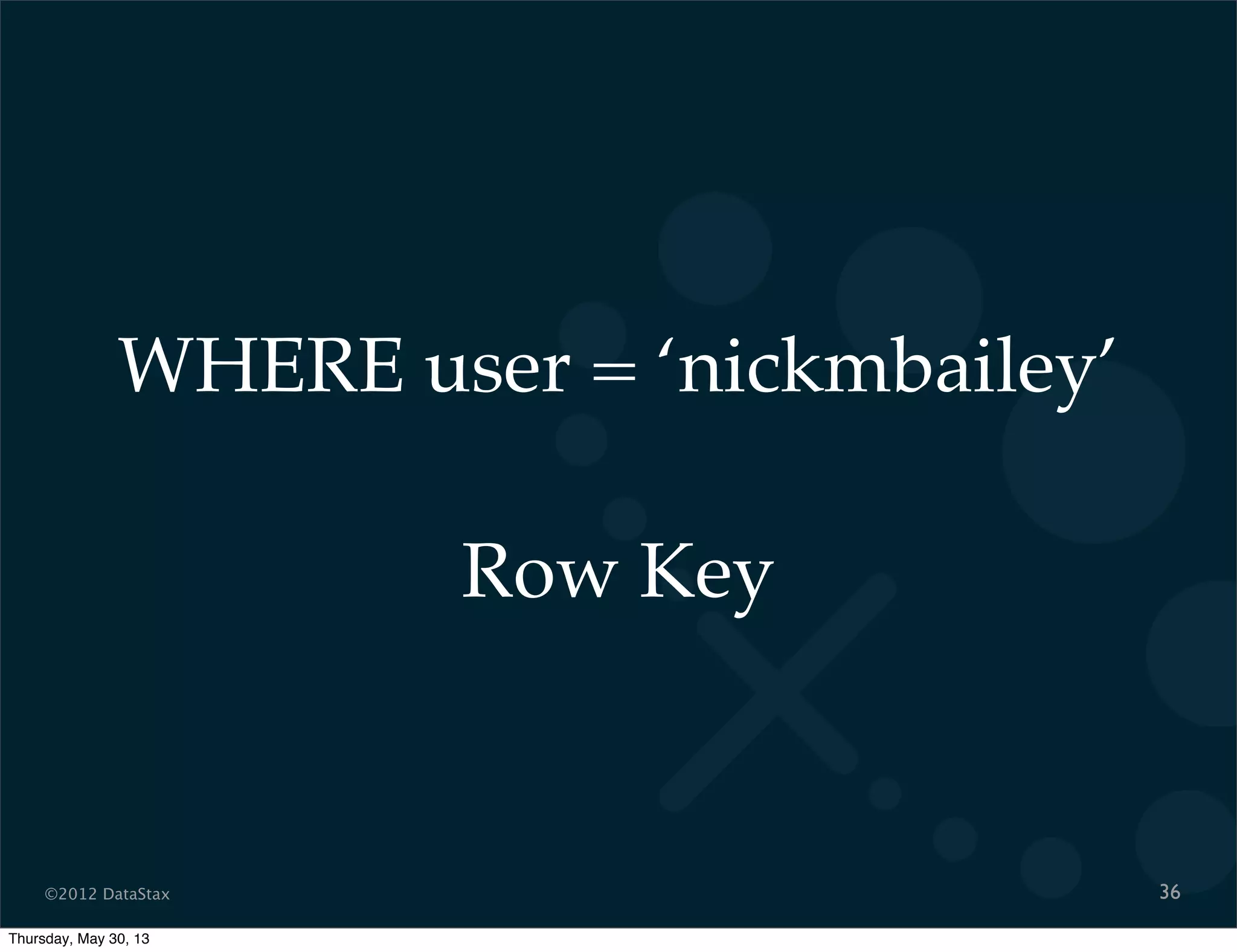This document contains a presentation on Cassandra and how it can be used. It discusses Cassandra's architecture based on Dynamo and BigTable, as well as how it provides availability, scalability, and performance. It covers data modeling techniques in Cassandra like column families, static vs dynamic columns, and using timestamps for time series data. Examples are provided for modeling user login data and social network activity. Anti-patterns like super columns and read-before-write are also discussed. The document concludes with information on an Ebay use case involving social signals and recommendations.