























The document presents an overview of Change Data Capture (CDC) architecture, detailing its definition, various implementation methods, and use cases in enterprise environments. It highlights the transition from legacy systems to big data integrations, outlines challenges, and describes the architectural considerations for efficient CDC. Additionally, it emphasizes the role of tools like StreamAnalytix in simplifying CDC workflows for real-time analytics and data processing.
Copyright information and usage restrictions for Impetus Technologies' presentation.
Introduction to planning for the next-generation Change Data Capture architecture.
Details the presentation agenda covering CDC concepts, methods, considerations, demo, and Q&A.
Impetus focuses on creating intelligent enterprises via data insights and is trusted by well-known brands.
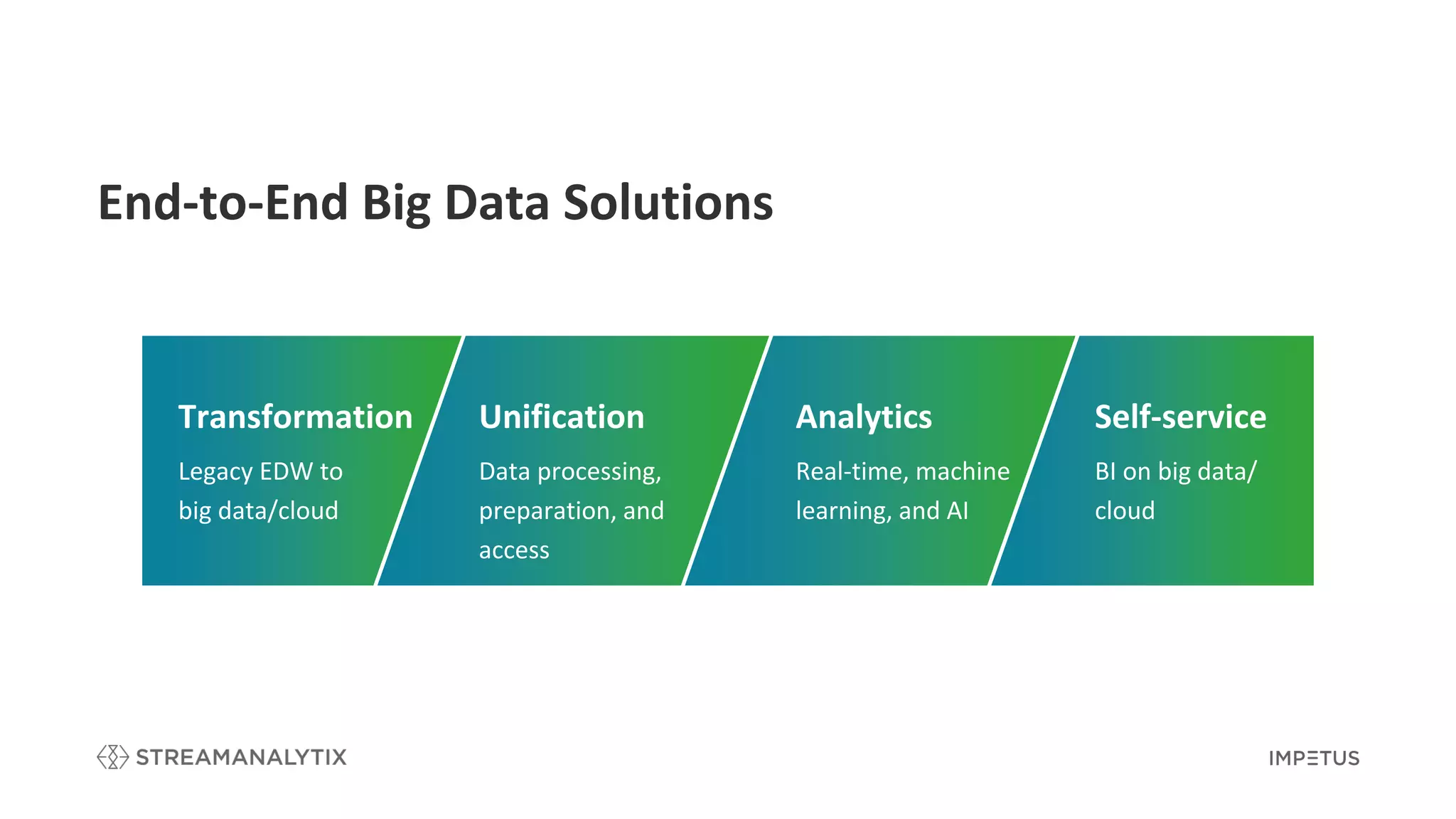
Discusses transformation, unification, analytics, and self-service BI concerning big data and cloud.
Survey to identify different change data capture use cases across organizations.
Highlights the speakers, Saurabh Dutta and Sameer Bhide, who are presenting in the session.
Definition of Change Data Capture (CDC) as a method for tracking changes at data sources.
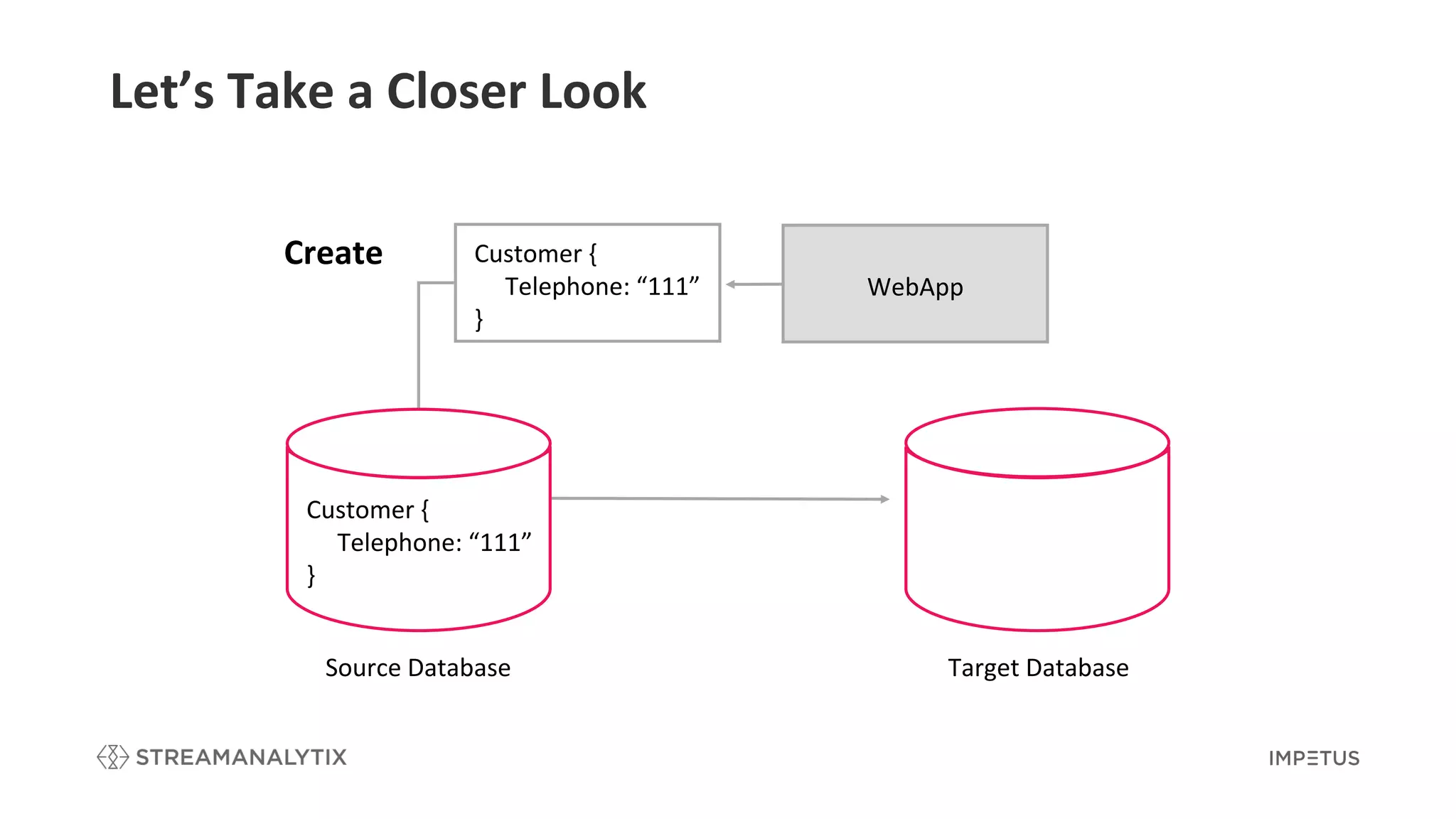
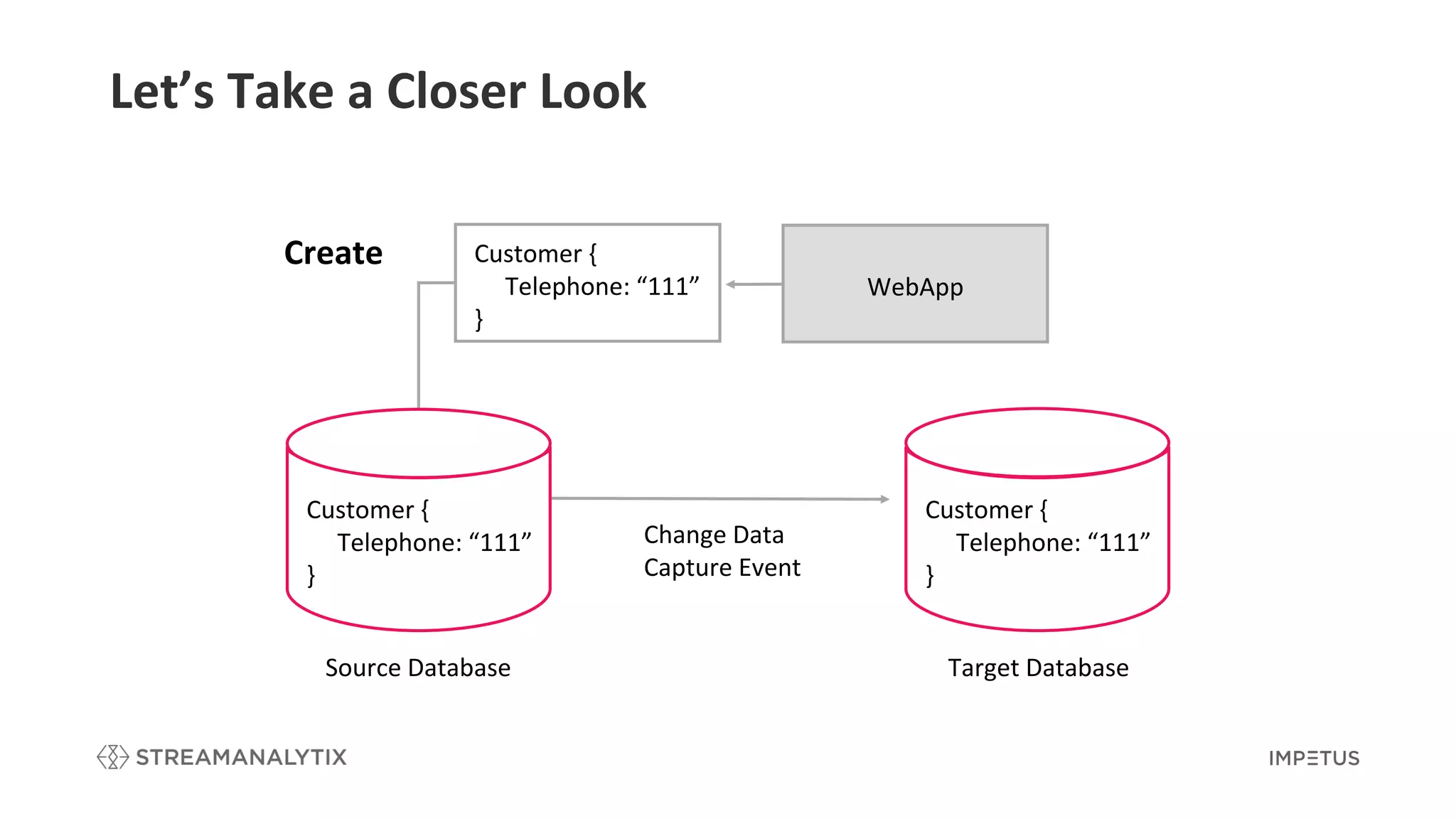
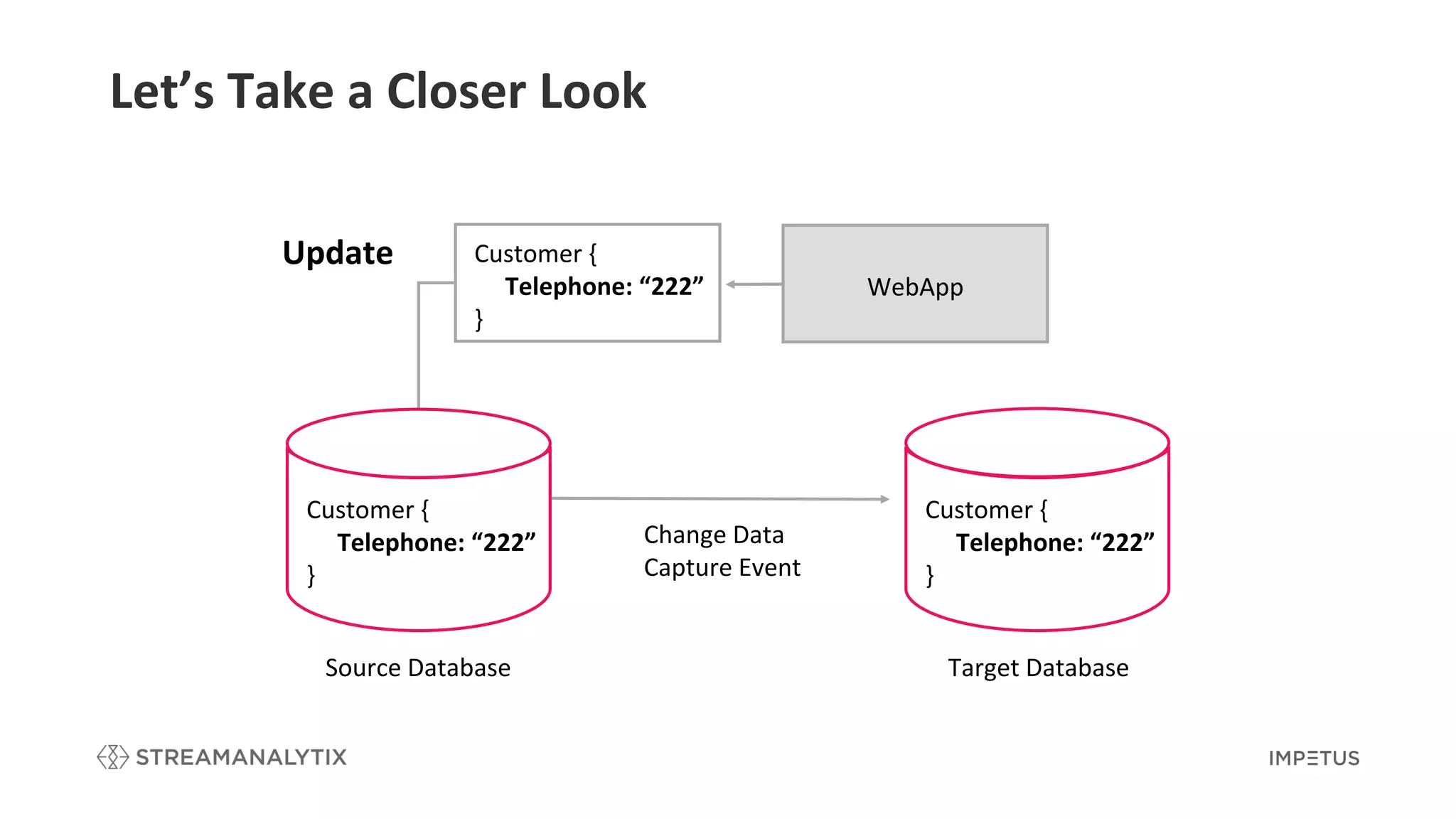
Illustrates how CDC works using source and target databases with detailed examples.
Describes various CDC models' impact, including batch, real-time, and their implementations.
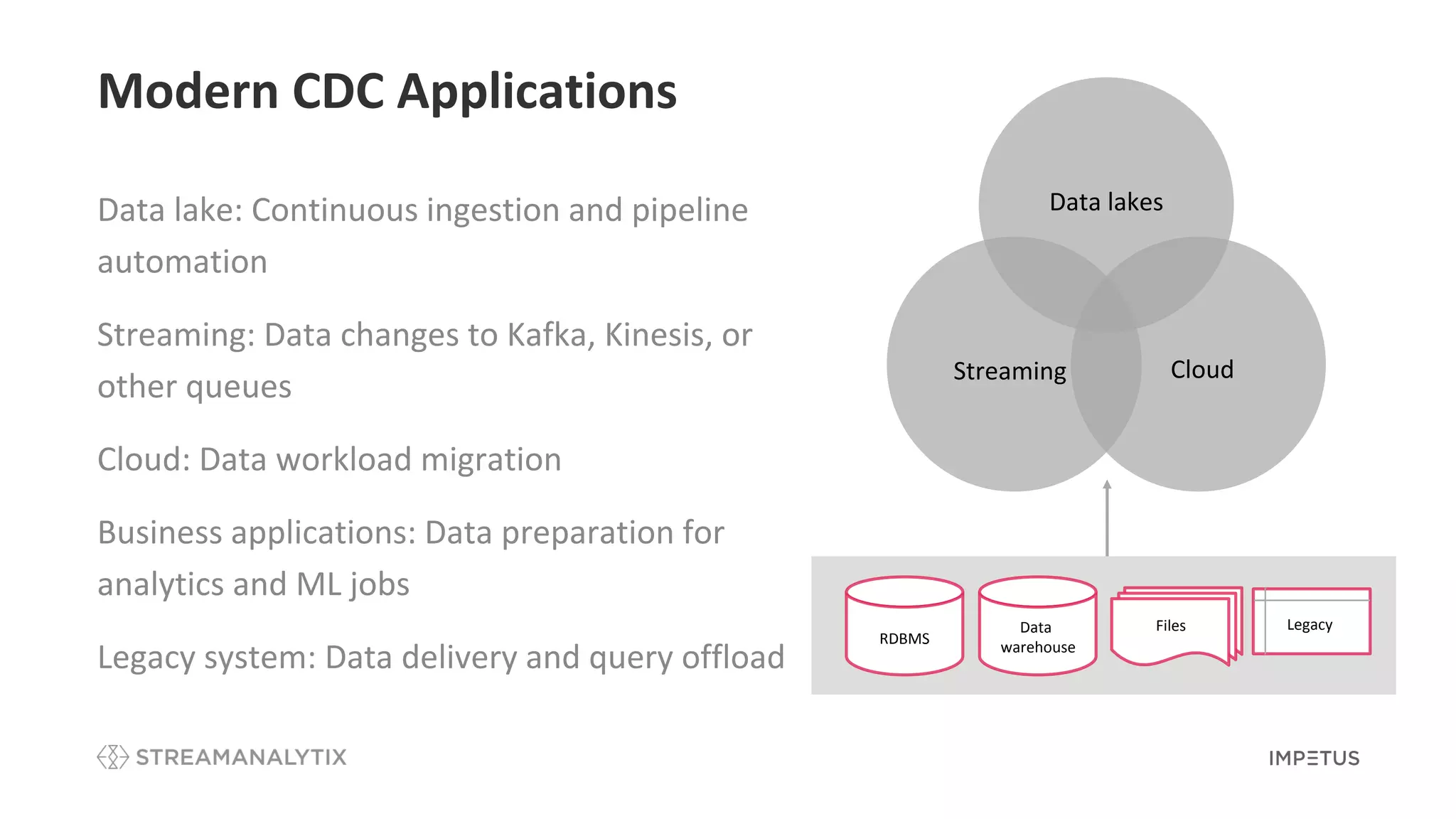
Outlines modern applications of CDC including data lakes, cloud migration, and handling legacy systems.
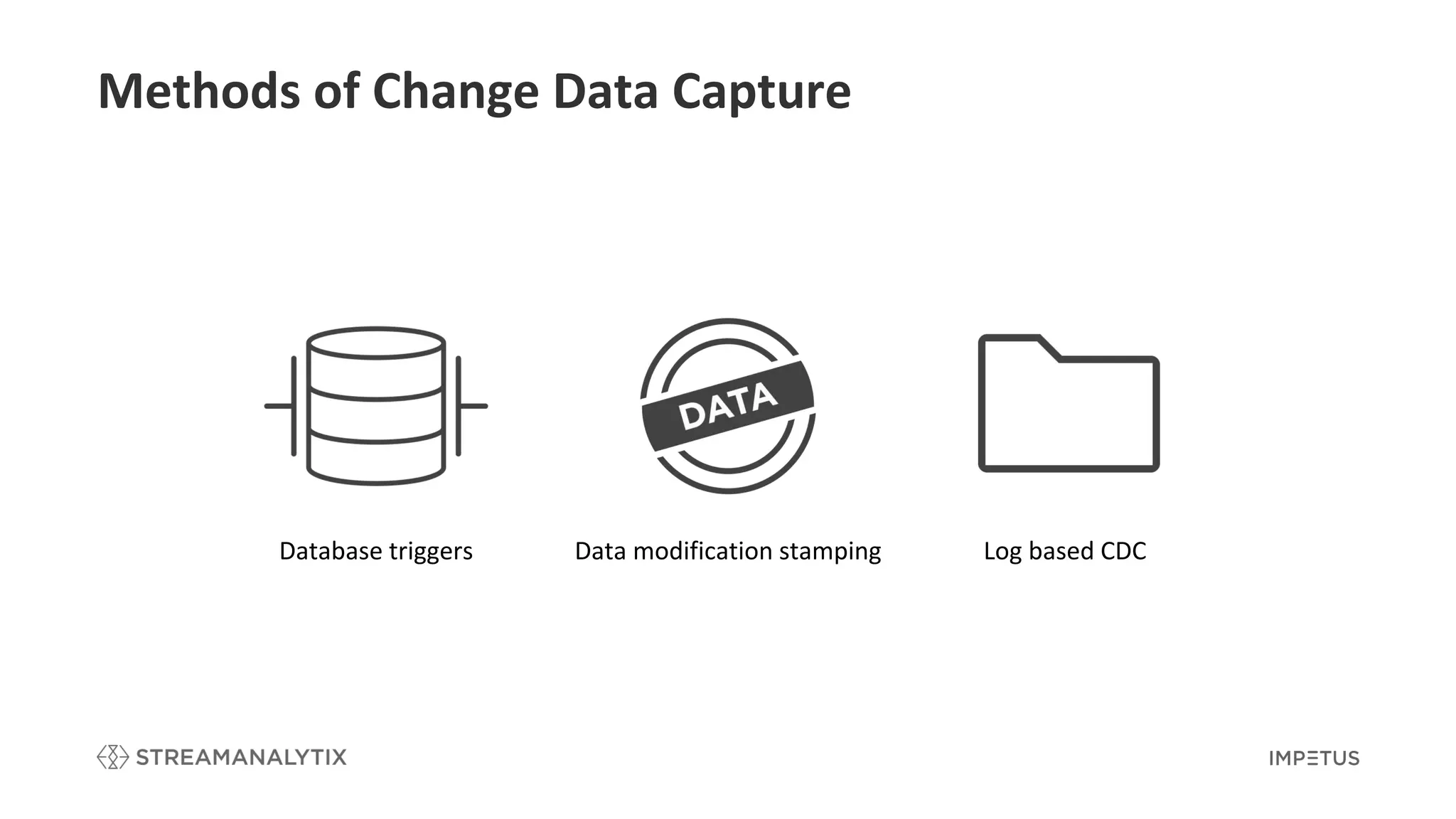
Discusses different CDC methodologies including database triggers, modification stamping, and log-based CDC.
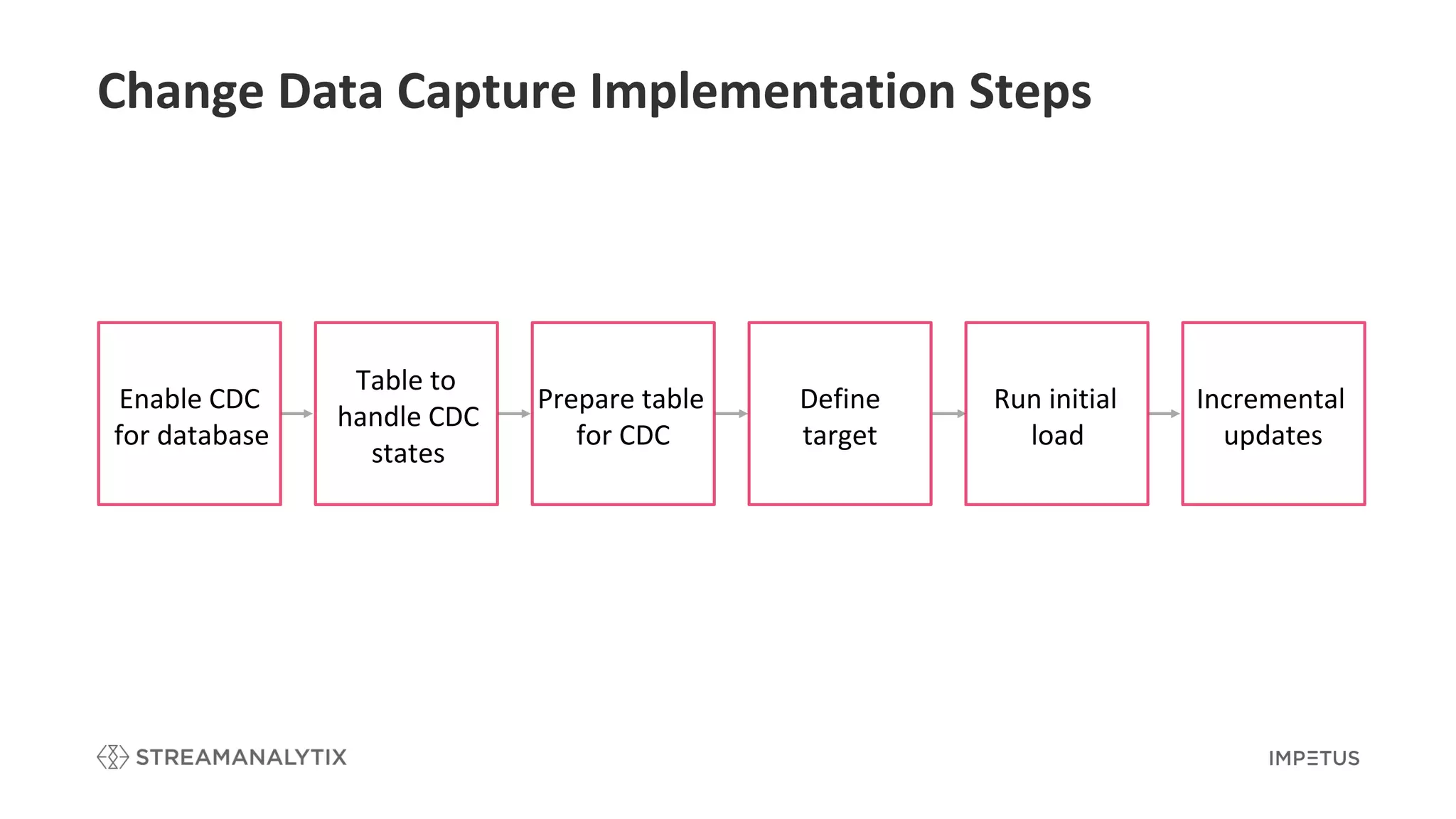
Steps involved in implementing Change Data Capture for effective data integration and management.
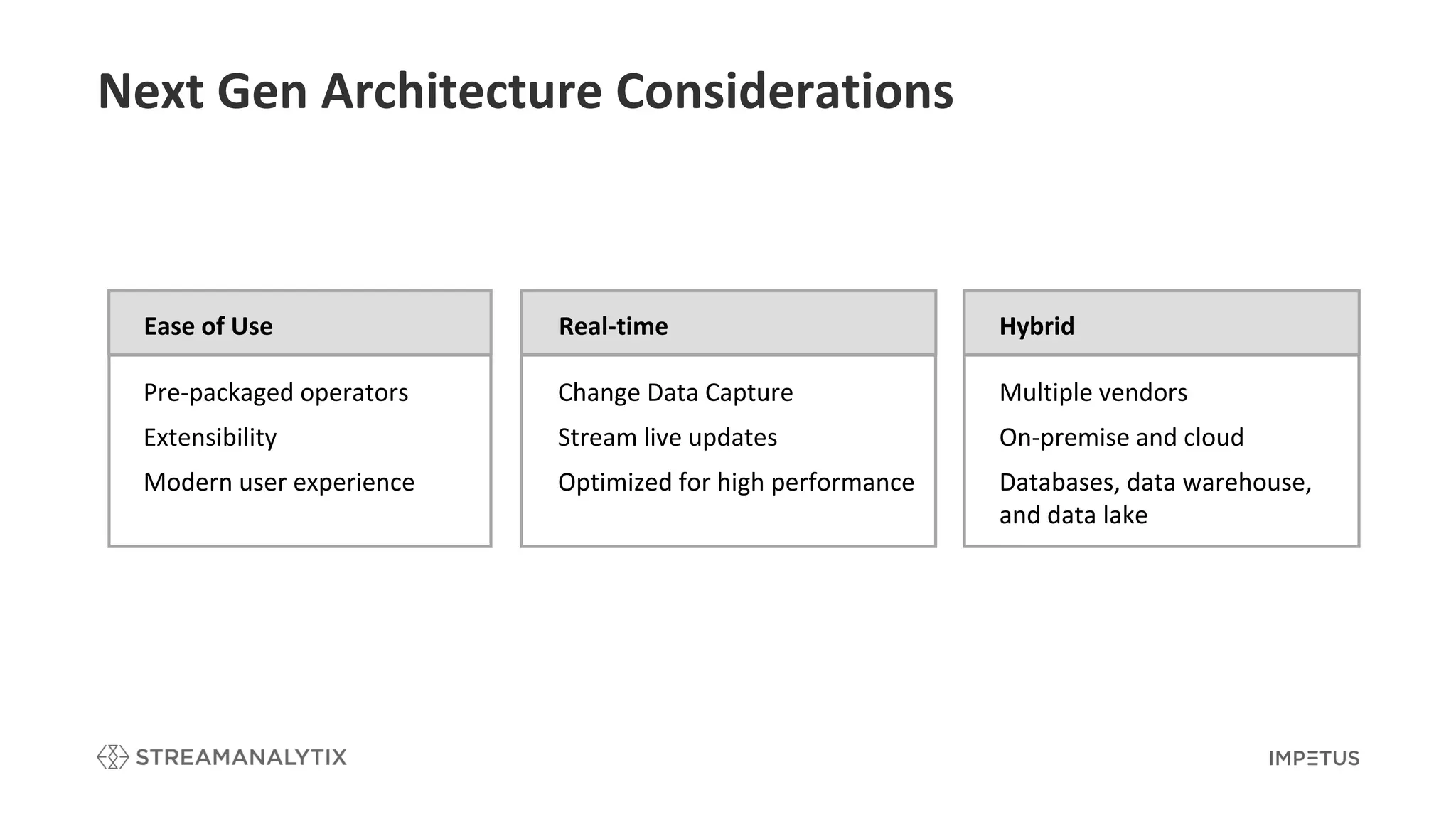
Key considerations for next-gen CDC architecture such as ease of use, real-time updates, and hybrid setups.
Explains the value of CDC including efficiency, impact on source systems, time to value, and flexibility.
Statistical data on various CDC use cases currently deployed in organizations.
Introduction to the ETL, real-time stream processing, and machine learning platform with visual IDE.
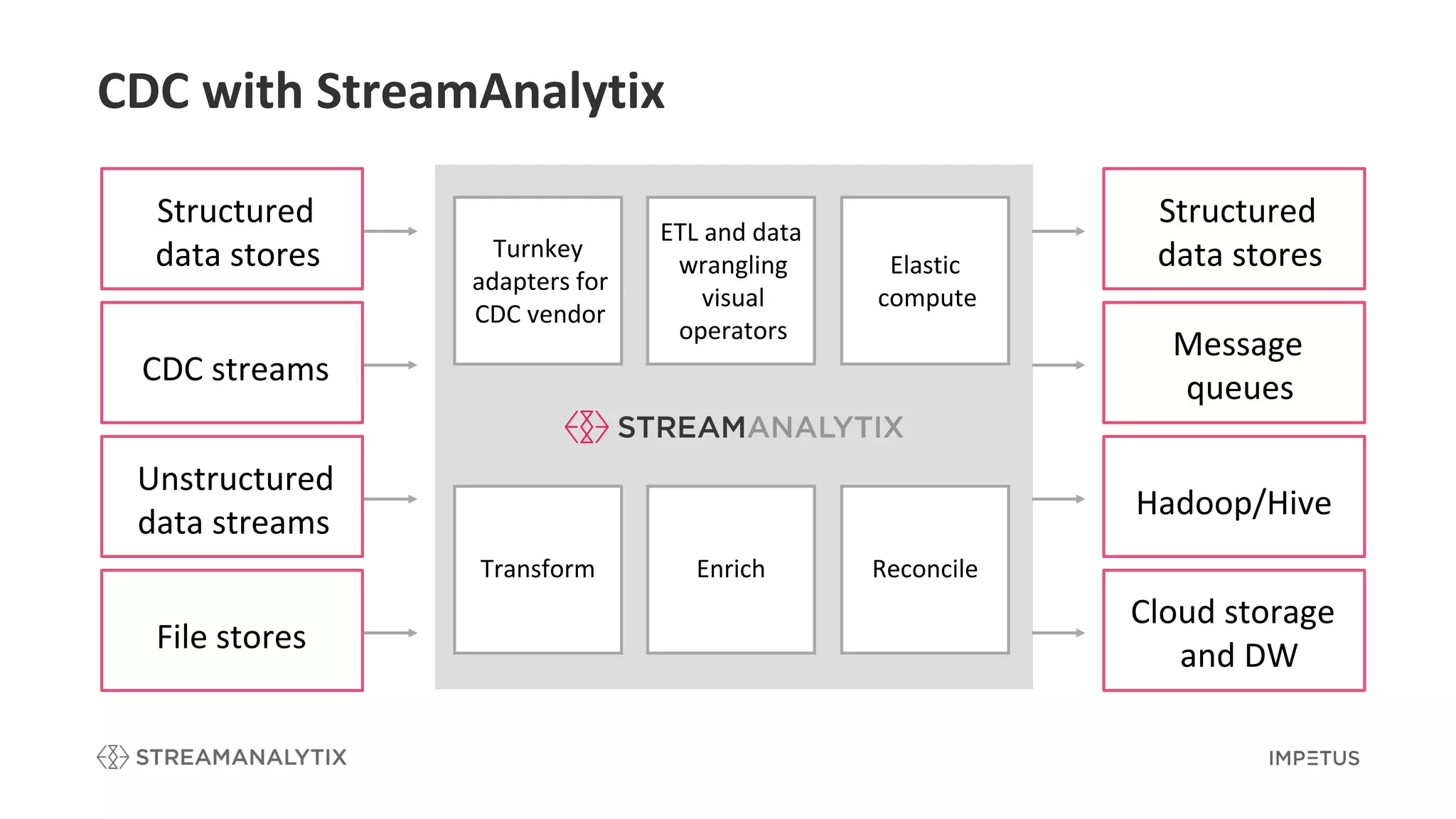
Highlights various CDC capabilities like integration with providers and visual operators for ETL.
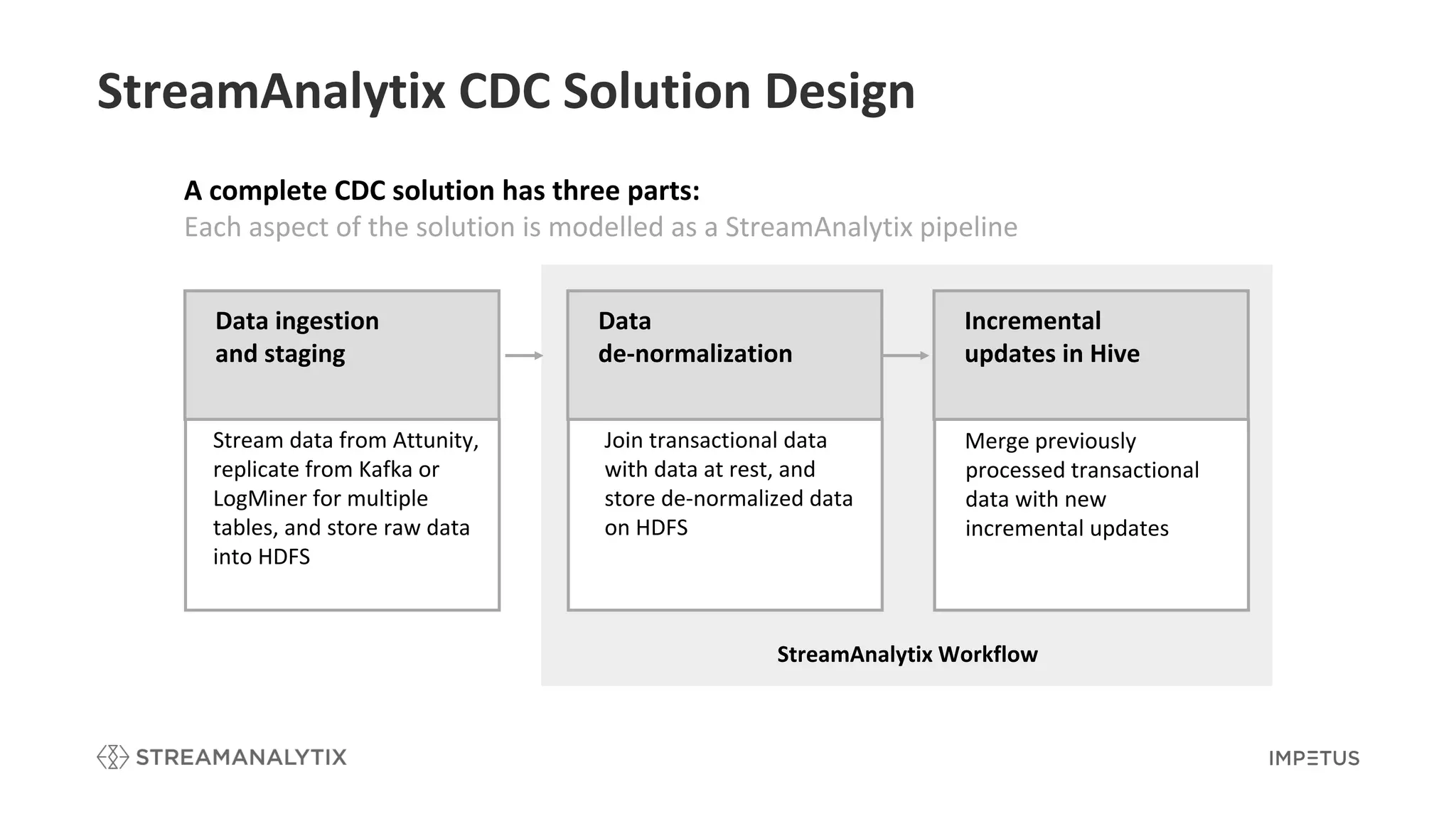
Describes the complete CDC solution as modeled in StreamAnalytix, including data pipelines.
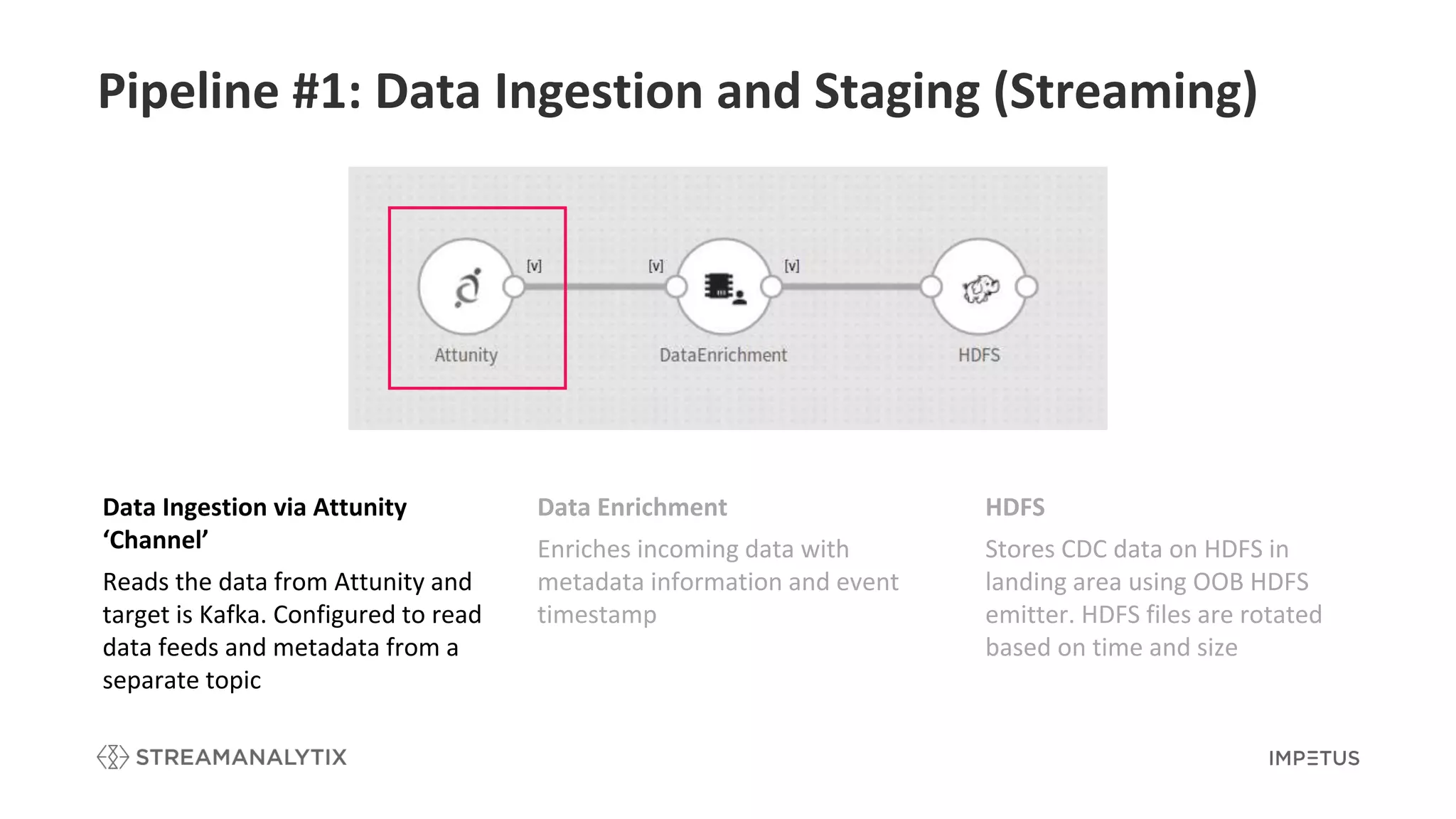
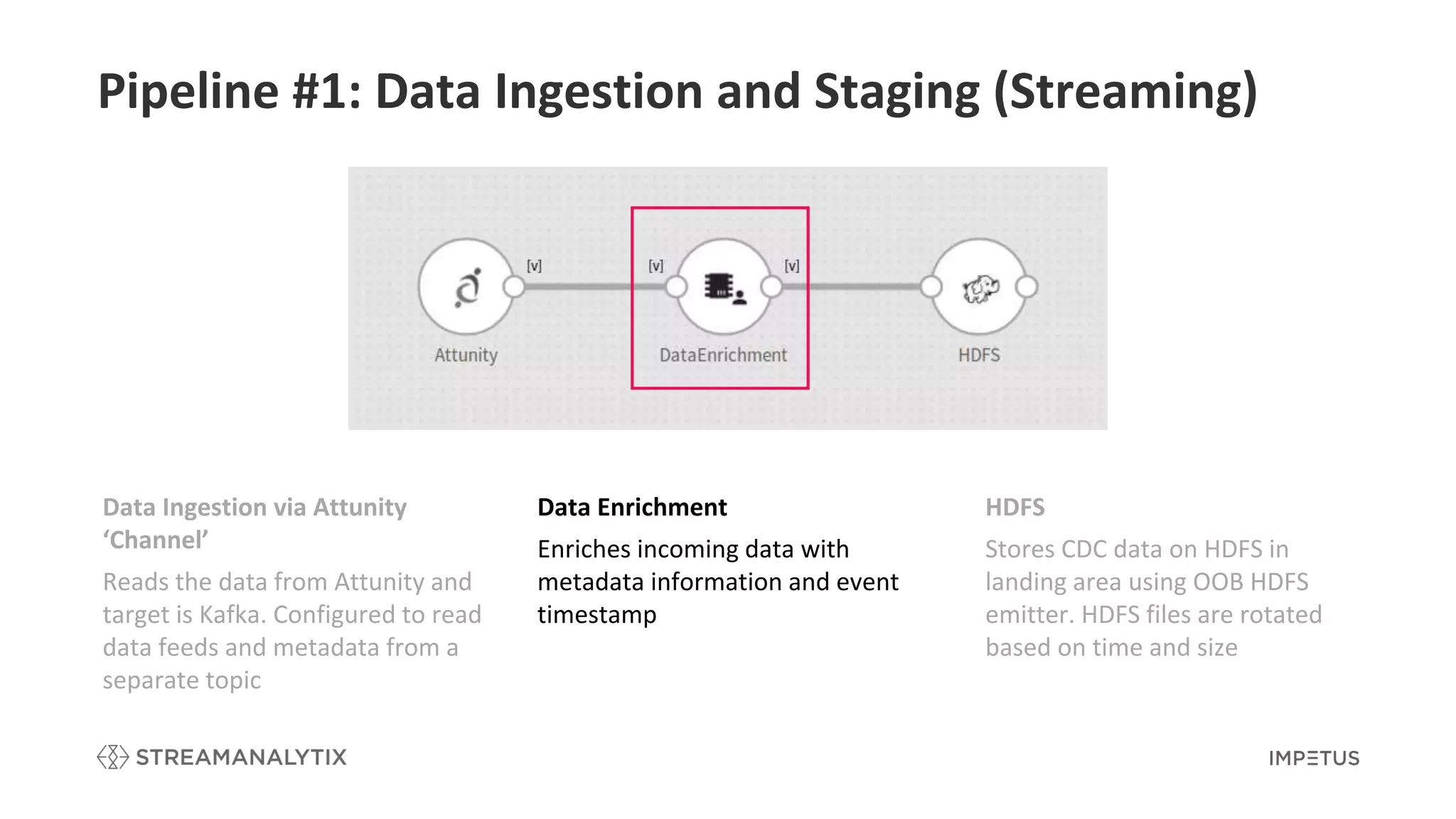
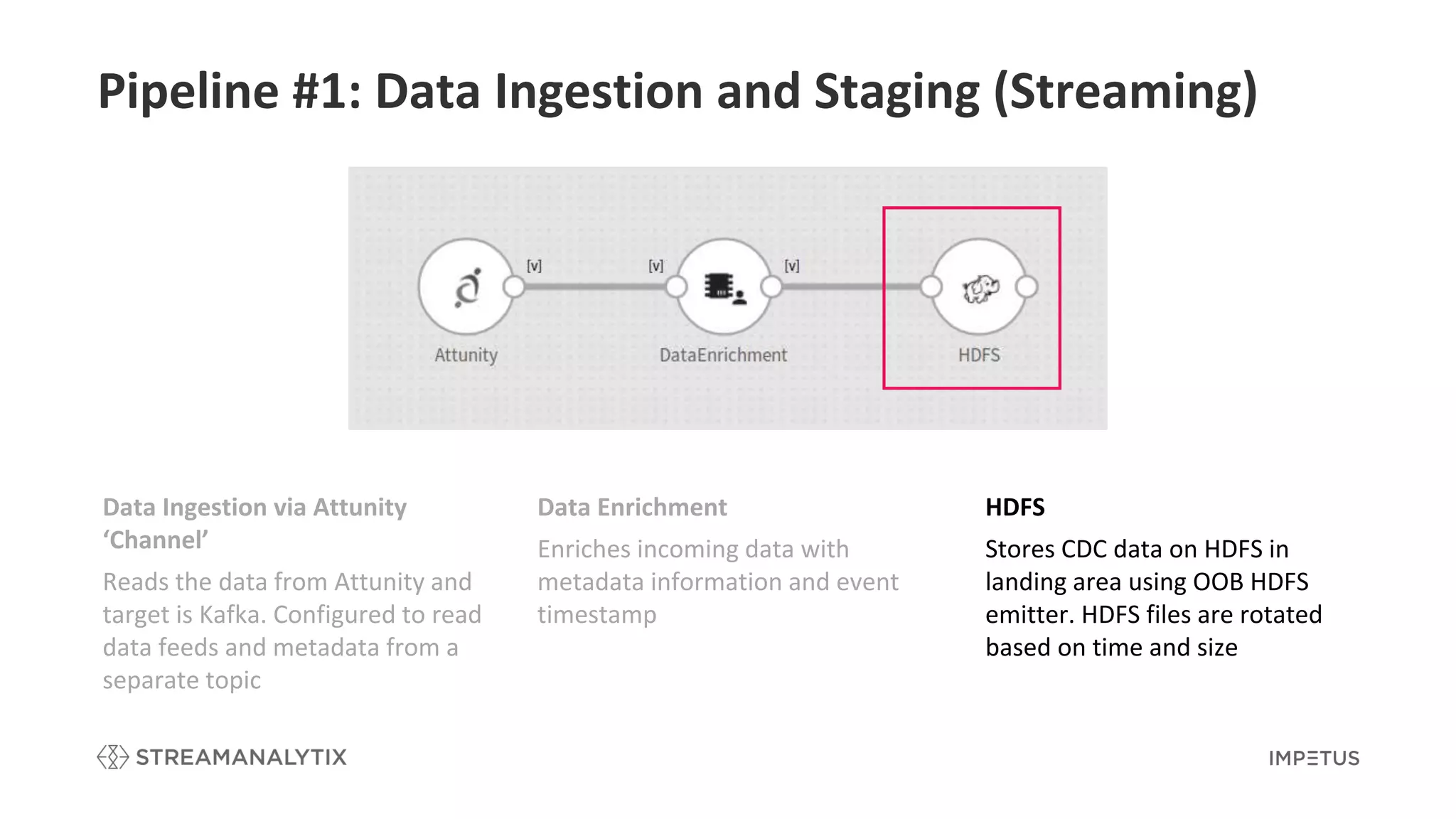
Explains the first pipeline for data ingestion and staging with data enrichment and storage strategies.
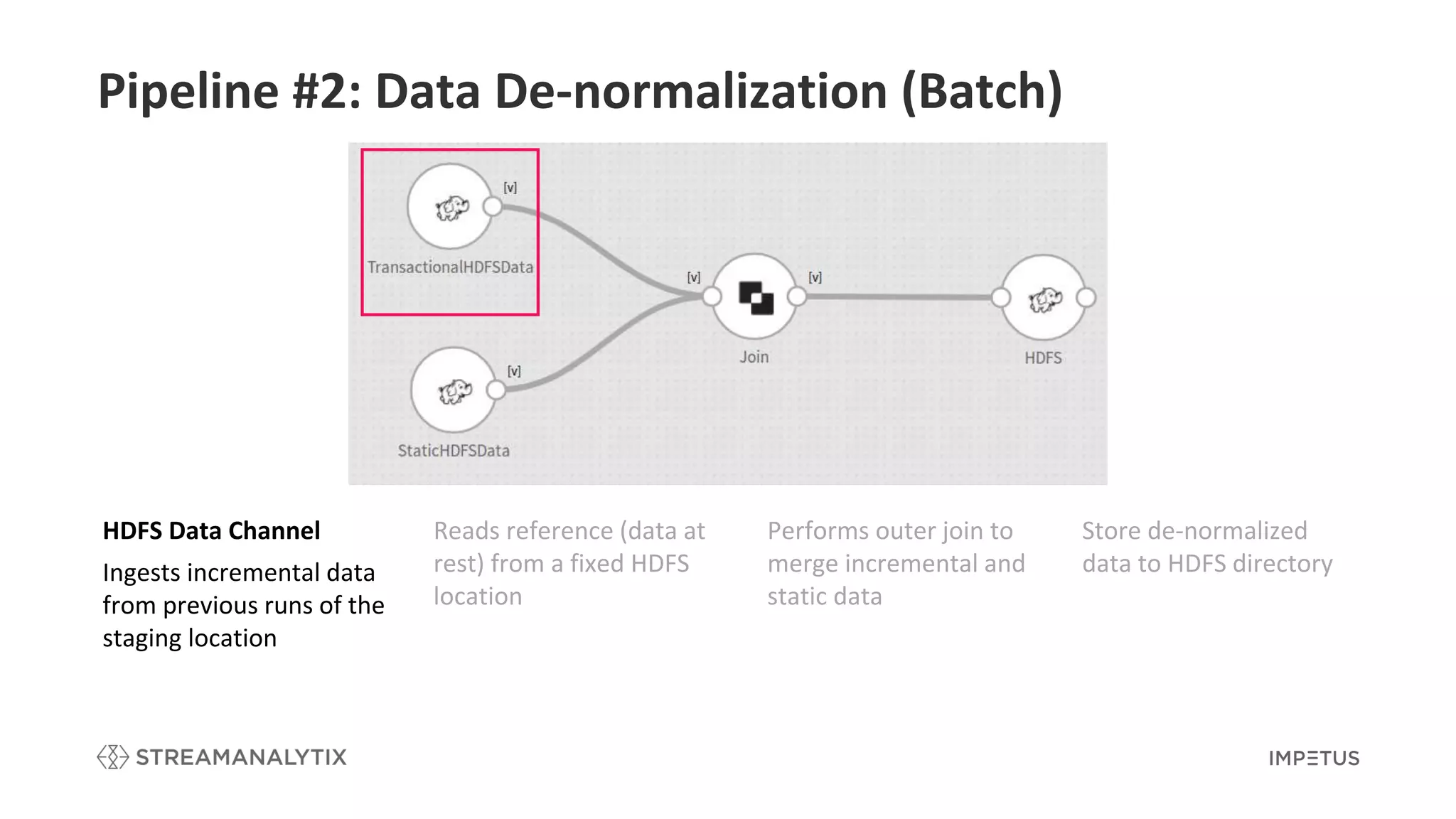
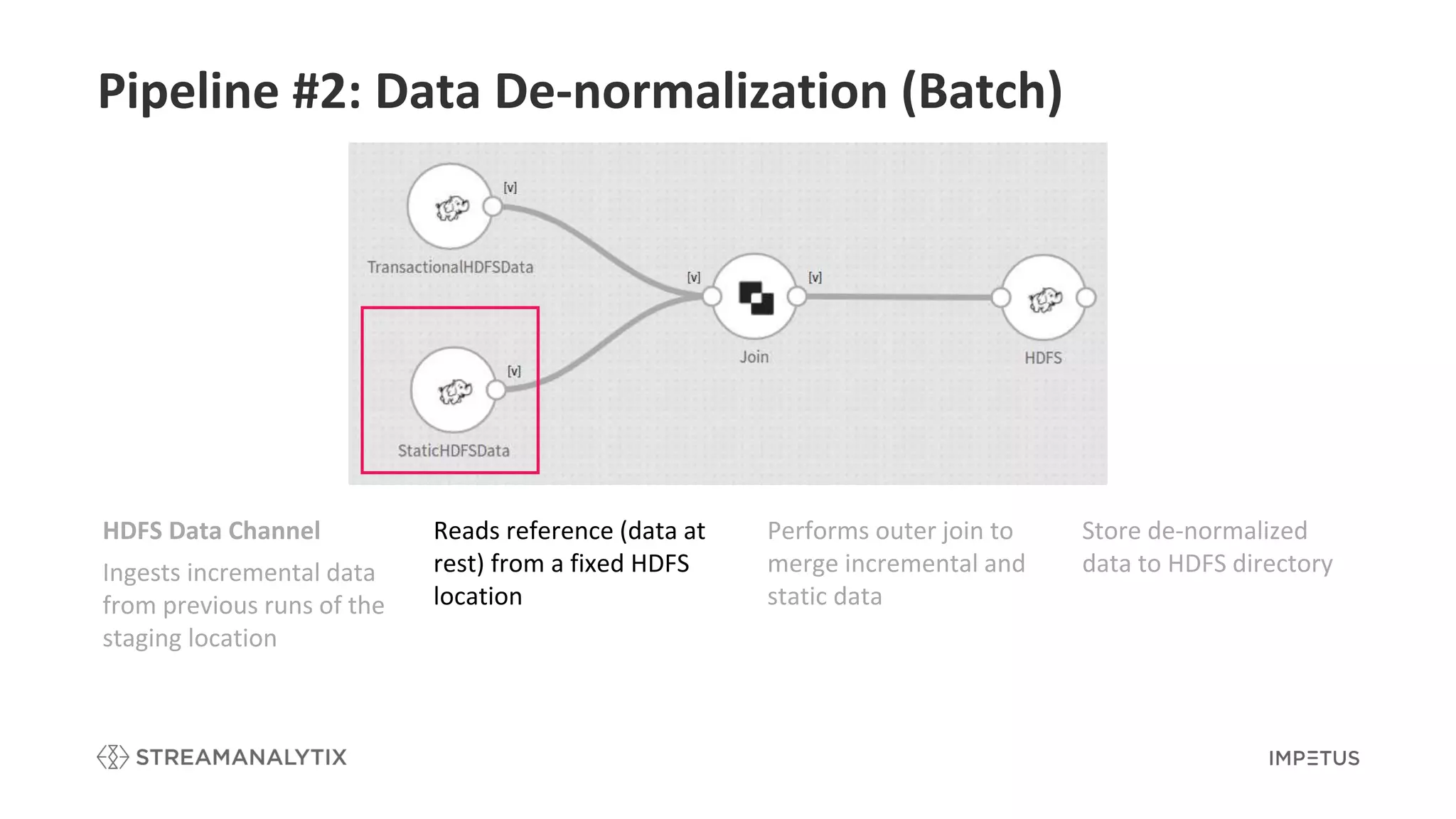
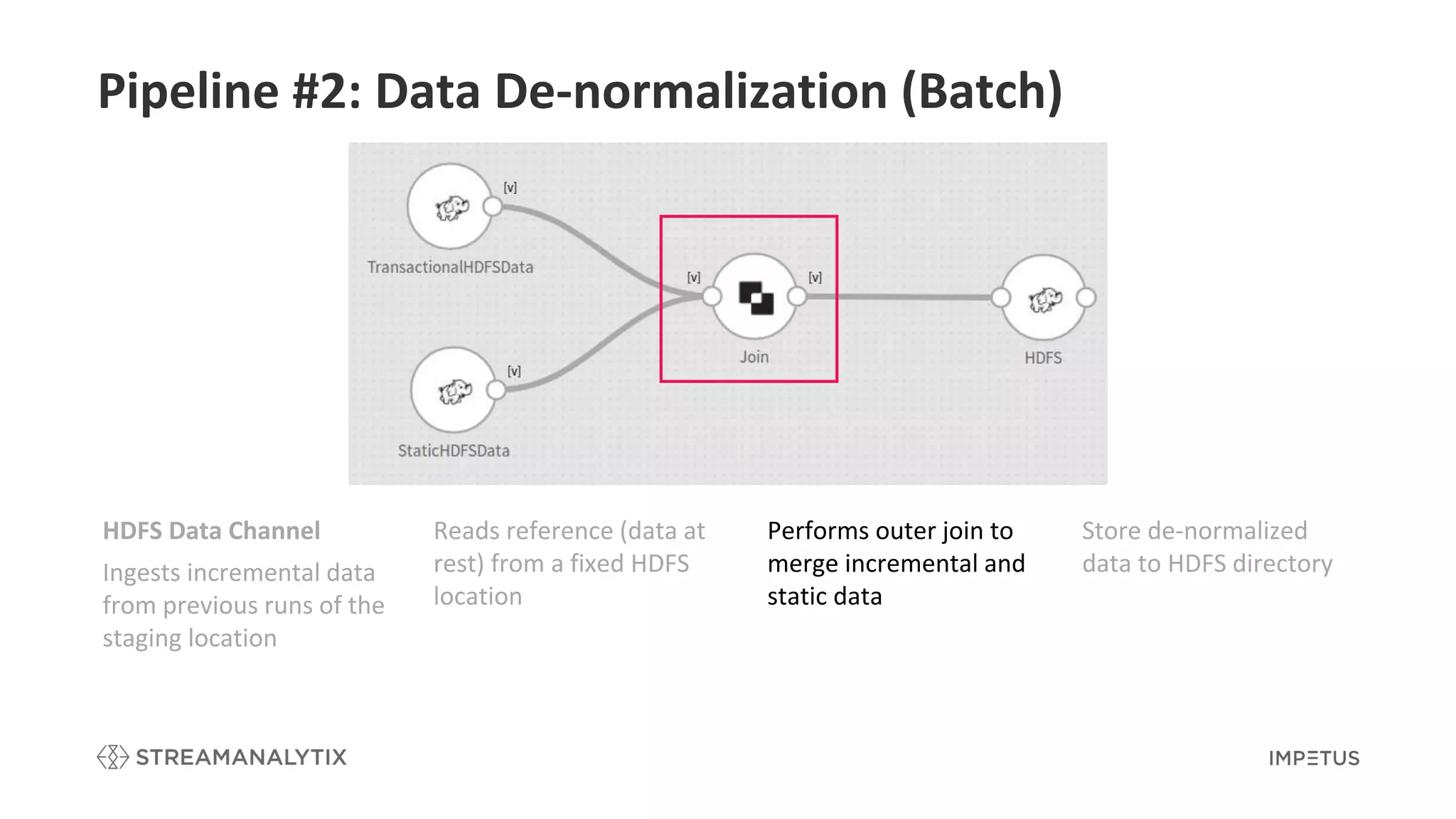
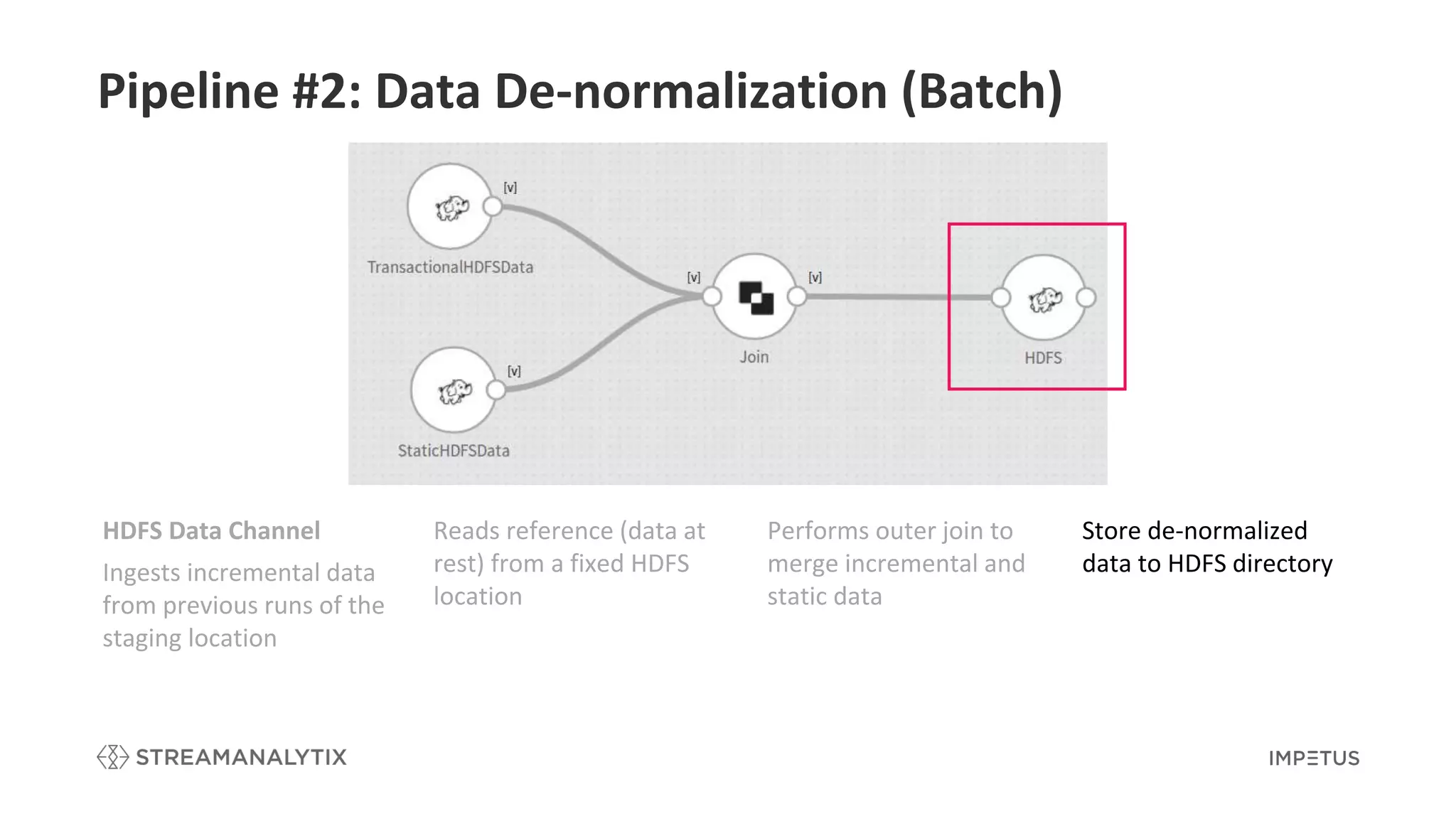
Details the de-normalization process in batch to merge incremental and static data.
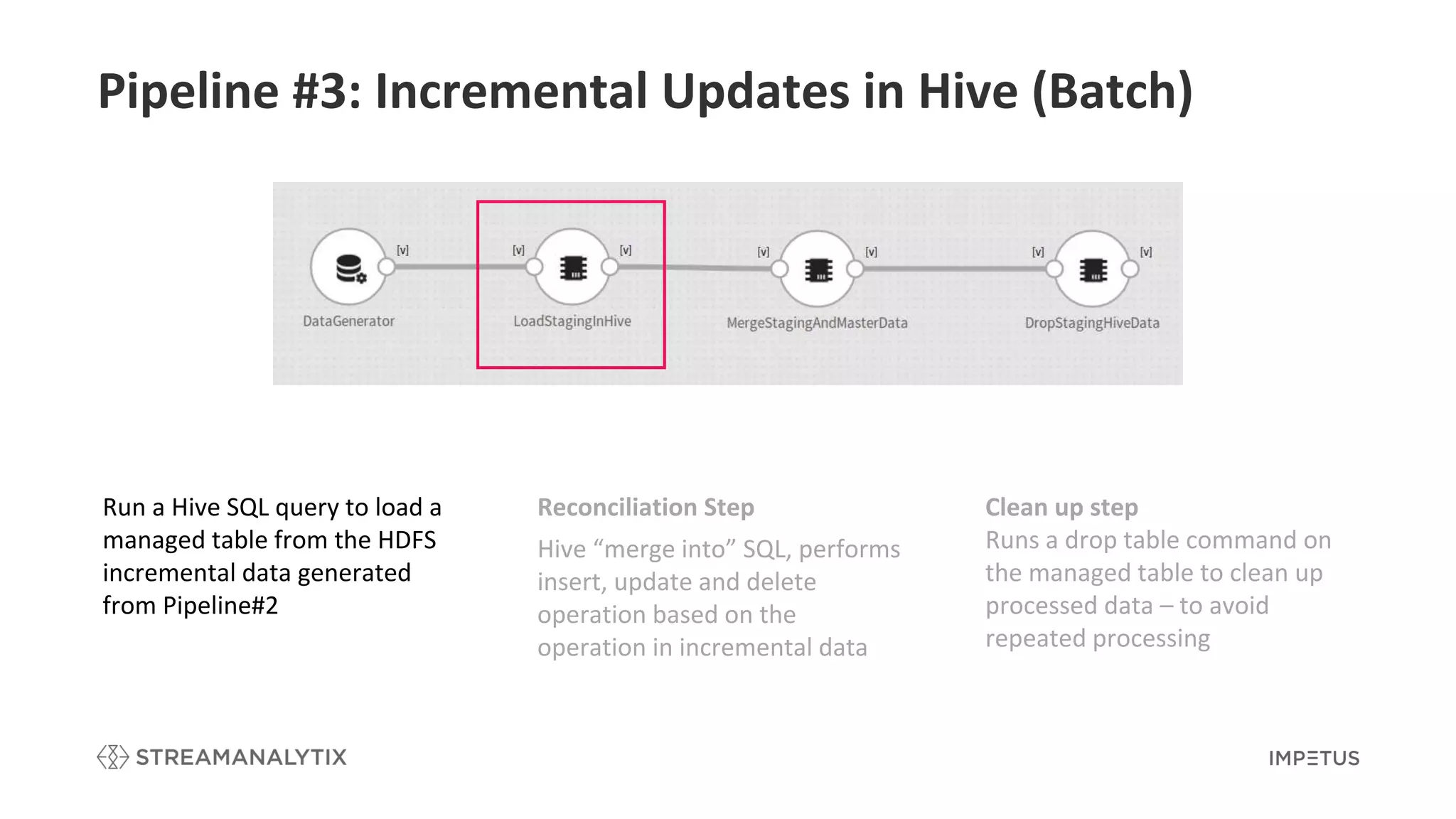
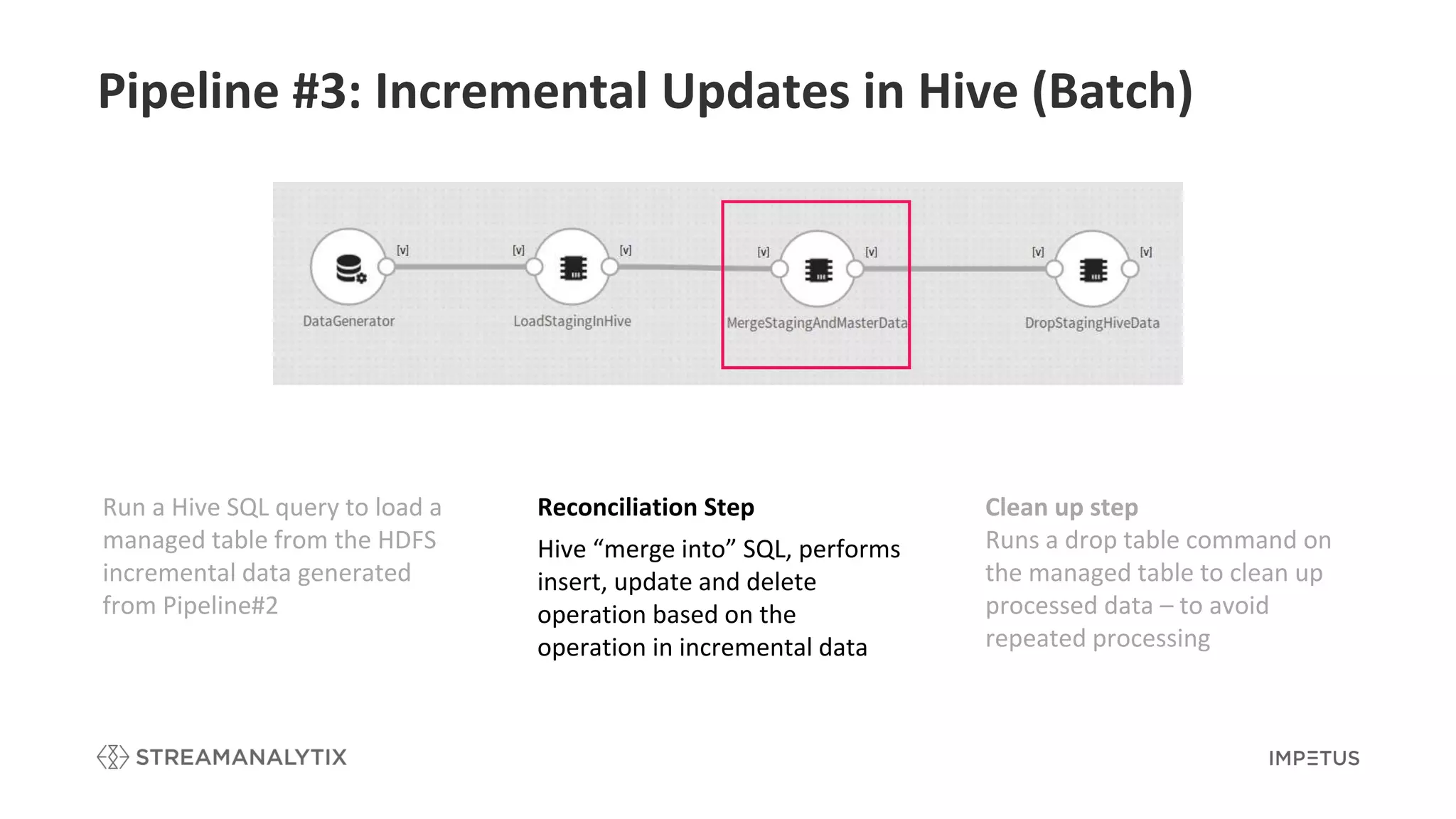
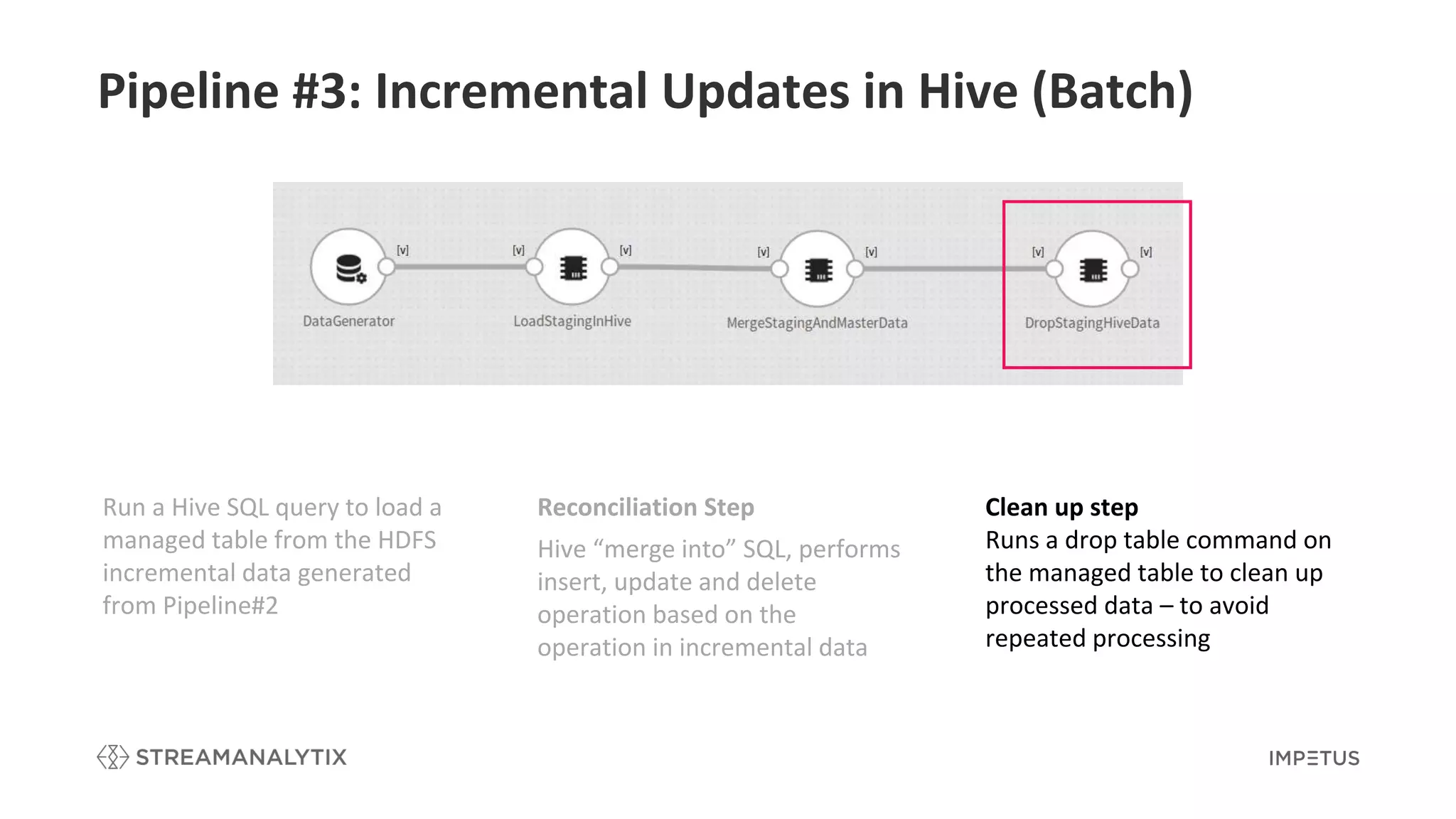
Describes the reconciliation step involved in Hive for performing incremental updates based on changes.
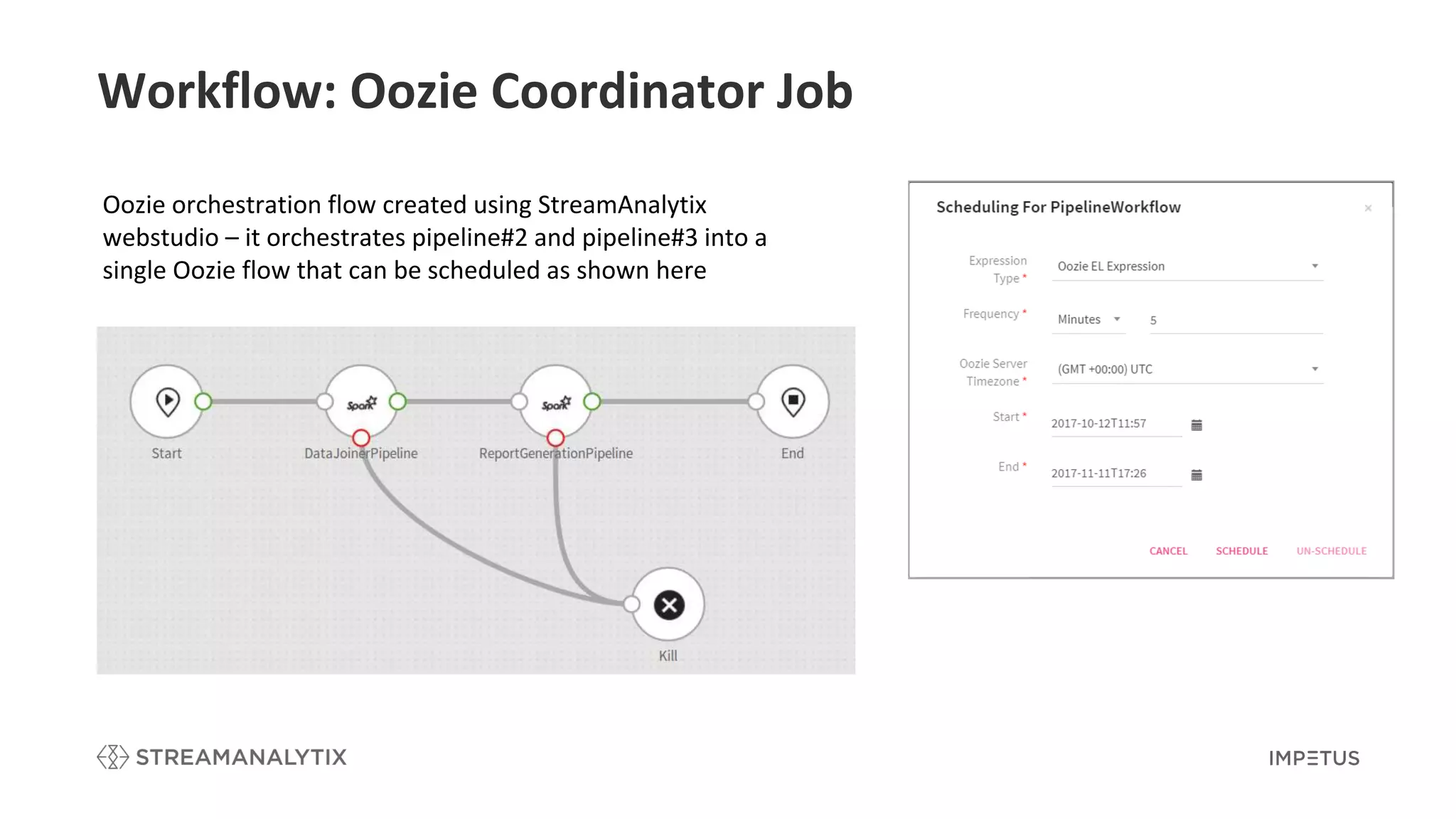
Details the orchestration of data pipelines using Oozie coordination within StreamAnalytix.
Presentation of a demo showcasing data processing workflows and data channels.
Summarizes enhancements in data acquisition flows and the importance of unified processes.
Concludes on the complexities of CDC integration and the benefits of a unified platform.
Information on the live Q&A session; offers details for trial access and further inquiries.
































![[Pulsar summit na 21] Change Data Capture To Data Lakes Using Apache Pulsar/Hudi](https://cdn.slidesharecdn.com/ss_thumbnails/pulsarsummitna21cdcusinghudipulsardeck-210628151056-thumbnail.jpg?width=640&height=640&fit=bounds)









































![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)