Download to read offline


![df.registerTempTable("cricket_data");
val result = sqlContext.sql("select name,year,case when month in (10,11,12) then 'Q4'
when month in (7,8,9) then 'Q3' when month in (4,5,6) then 'Q2' when month in(1,2,3)
then 'Q1' end Quarter, run_scored from (select
name,year(convert(REPLACE(date_of_match,'/','-'))) as
year,month(convert(REPLACE(date_of_match,'/','-'))) as month,run_scored from
cricket_data) C");
Convert and REPLACE are custom UDF for this Job
Now this query gives me a result like this:
Now in terms of Data Warehouse this is very inefficient data. As the business user
demands summarized data with full visibility throughout the timestamp.
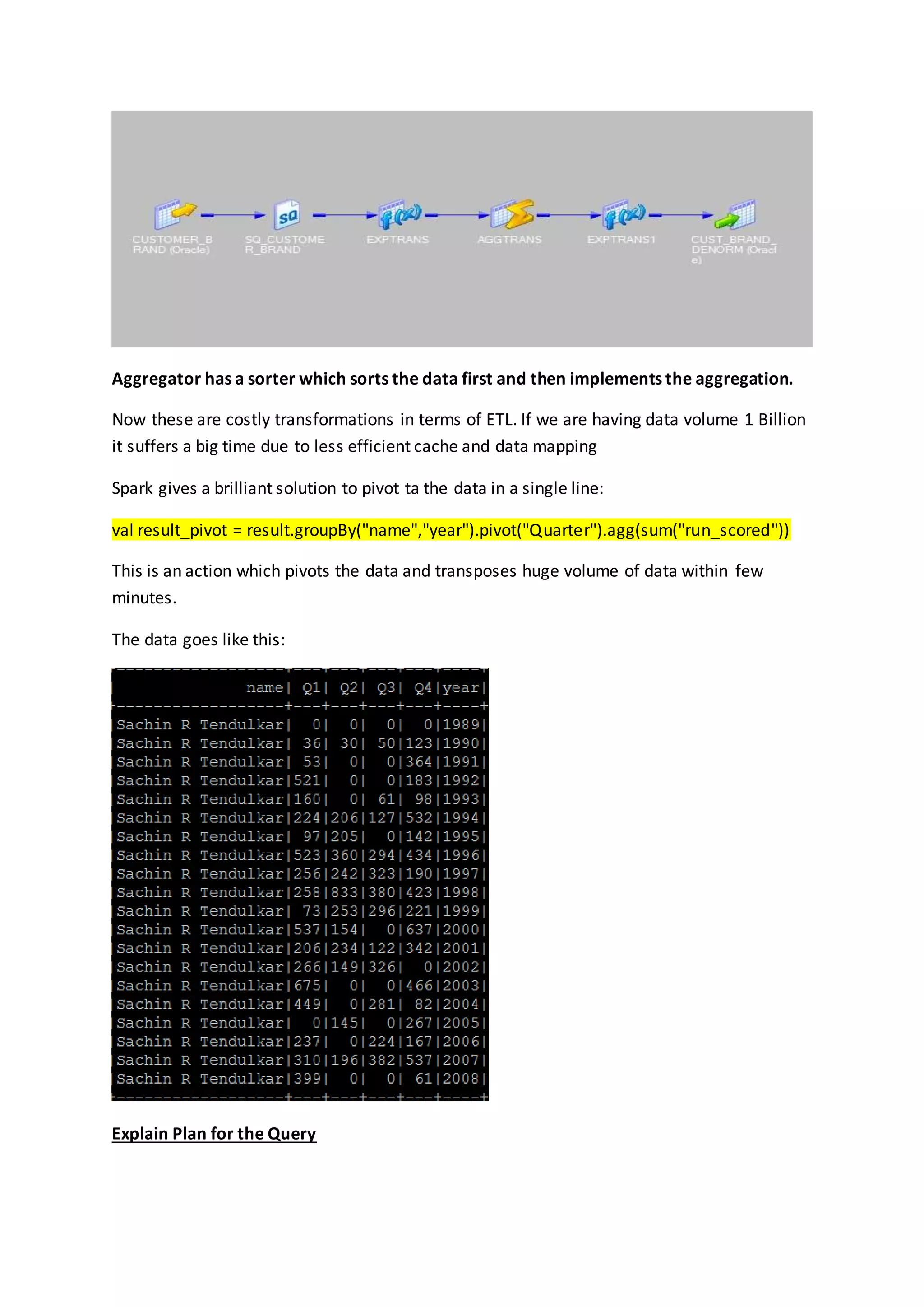
Here in ETL we use a component called “De-Normalizer” [In Informatica]
So it required transformations like:](https://image.slidesharecdn.com/etlandpivotinginspark-160710085529/75/ETL-and-pivoting-in-spark-3-2048.jpg)



1. The document discusses handling small file problems in Spark ETL pipelines. It recommends keeping partition sizes between 2GB and not too small to avoid overhead problems. 2. It provides examples of transformations like aggregation, normalization, and lookup that are commonly used. 3. Pivoting data in Spark is presented as an efficient solution to transform data compared to traditional ETL tools. The example pivots data to summarize by year and quarter within minutes for billions of records.
















































































