This document discusses formatting bits to better implement signal processing algorithms with integer arithmetic. It begins by introducing the context and objectives, which is to develop a methodology and tools to implement embedded filter algorithms using only integer arithmetic while controlling errors. It then discusses fixed-point arithmetic and how filters can be implemented using sum-of-products operations. The objective is given a bound on the final error, to find an implementation that reduces bit usage while controlling output error. The document proposes a two-step bit formatting method that first formats the most significant bits using Jackson's rule, then determines the minimum number of least significant bits that need to be kept to ensure faithful rounding of the final result.




![Context and Objectives
Bits Formatting
Conclusion
On the first hand... A filter
x[n]
z
b0
+
+
z
+
+
h(z) =
1
z
Pn
1+
b1
i=0
Pn
bi z
1
y[n]
+
b1
a1
b2
z
a2
1
b3
x[n]
1
a1
1
b2
z
y[n]
+
z
b1
z
+
1
a2
z
1
z
1
z
1
i
i=1 ai z
i
z
1
b3
1
z
a3
1
a3
Signal Processing
LTI filters: FIR or IIR
Its transfer function
Algorithmic relationship used to compute output(s) from
input(s), for example:
n
y (k) =
i=0
n
bi u(k − i) −
i=1
ai y (k − i)
4/20](https://image.slidesharecdn.com/peccs090114-140123075723-phpapp01/75/PECCS-2014-5-2048.jpg)







![Context and Objectives
Bits Formatting
Conclusion
Filter
u(k)
e(k)
H
He
y(k)
∆y(k)
+
y † (k)
∆y (k) y † (k) − y (k) can be seen as the result of the error
through the filter He :
He (z) =
1
,
1 + a1 z −1 + · · · + an z −n
∀z ∈ C.
If the error e(k) is in [e; e], then we are able to compute ∆y and
∆y such that ∆y (k) is in [∆y ; ∆y ] :
∆y
=
∆y
=
e +e
e −e
|He |DC −
He
2
2
e +e
e −e
|He |DC +
He
2
2
∞
∞
8/20](https://image.slidesharecdn.com/peccs090114-140123075723-phpapp01/75/PECCS-2014-13-2048.jpg)




















![Context and Objectives
Bits Formatting
Conclusion
Formatting
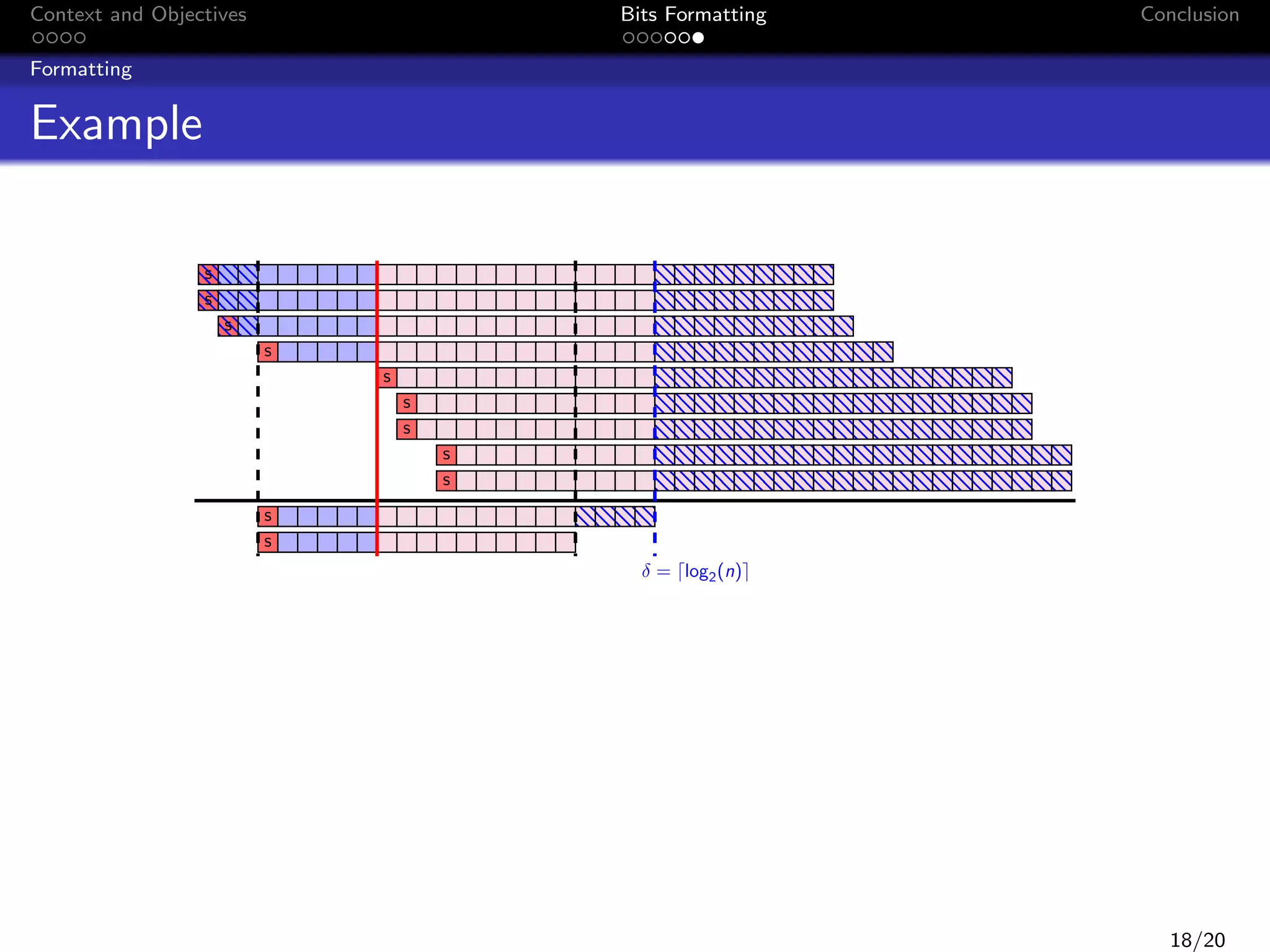
Example
The following algorithm is the fixed-point algorithm of a 4th −order
butterworth filter:
y (k) = 0.0013279914856 u(k) + 0.00531196594238 u(k − 1)
+0.00796794891357 u(k − 2) + 0.00531196594238 u(k − 3)
+0.0013279914856 u(k − 4) + 2.87109375 y (k − 1)
−3.20825195312 y (k − 2) + 1.63458251953 y (k − 3)
−0.318710327148 y (k − 4)
Inputs datas :
wordlength of constants, u(k) and y (k) : 16 bits
u(k) ∈ [−13, 13]
17/20](https://image.slidesharecdn.com/peccs090114-140123075723-phpapp01/75/PECCS-2014-35-2048.jpg)
![Context and Objectives
Bits Formatting
Conclusion
Formatting
Example
The following algorithm is the fixed-point algorithm of a 4th −order
butterworth filter:
y (k) = 0.0013279914856 u(k) + 0.00531196594238 u(k − 1)
+0.00796794891357 u(k − 2) + 0.00531196594238 u(k − 3)
+0.0013279914856 u(k − 4) + 2.87109375 y (k − 1)
−3.20825195312 y (k − 2) + 1.63458251953 y (k − 3)
−0.318710327148 y (k − 4)
Inputs datas :
wordlength of constants, u(k) and y (k) : 16 bits
u(k) ∈ [−13, 13] and y (k) ∈ [−17.123541; 17.123541]
17/20](https://image.slidesharecdn.com/peccs090114-140123075723-phpapp01/75/PECCS-2014-36-2048.jpg)

















































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)






