Downloaded 27 times




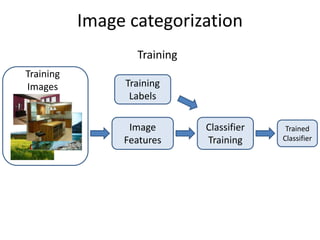




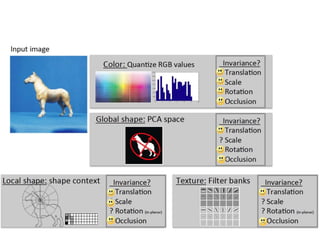



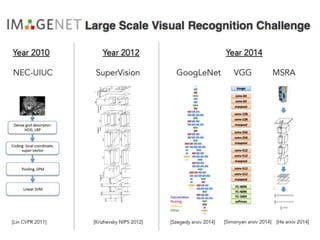








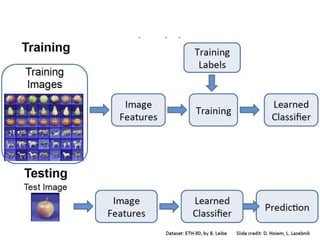


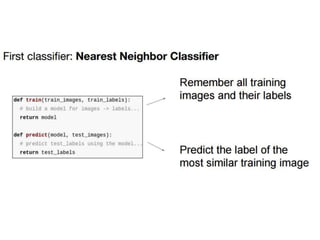







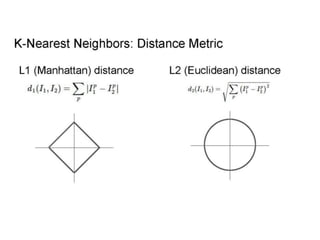
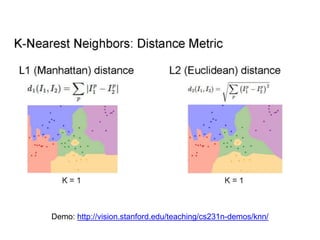







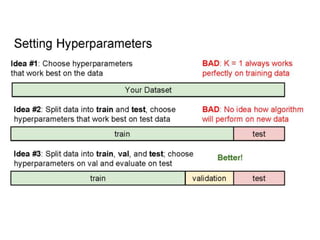

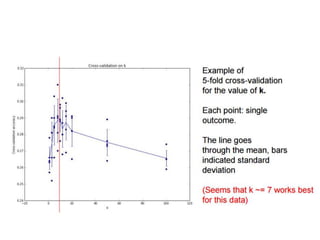


















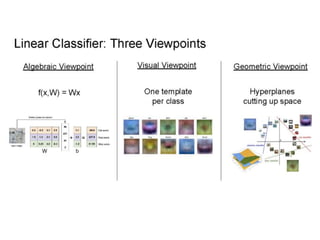
















- Image classification involves training a classifier on labeled images, validating hyperparameters, and testing on unlabeled images. - Nearest neighbor classification predicts labels of nearest training examples while linear classification learns weights to separate classes with a hyperplane. - Loss functions like cross-entropy measure how well the classifier's predicted scores match the true labels and are minimized during training.























































































