Download to read offline






![Image prediction (“structured prediction”)
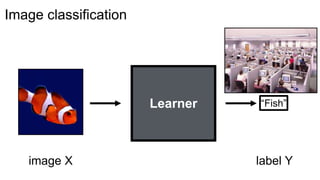
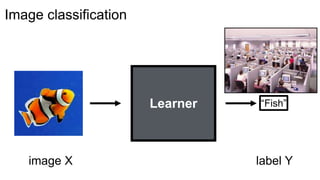
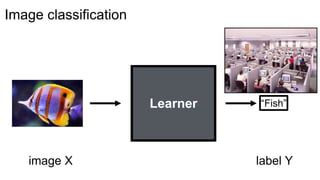
Object labeling
[Long et al. 2015, …]
Edge Detection
[Xie et al. 2015, …]
Style transfer
[Gatys et al. 2016, …][Reed et al. 2014, …]
Text-to-photo
“this small bird has a pink
breast and crown…”](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-11-320.jpg)



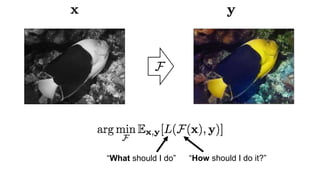
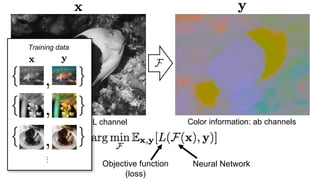
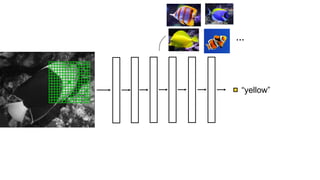
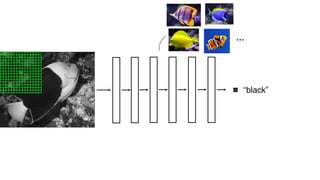
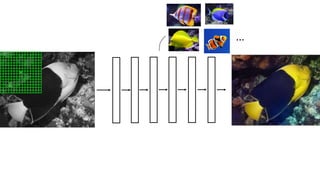
![Color distribution cross-entropy loss with colorfulness enhancing term.
Zhang et al. 2016
[Zhang, Isola, Efros, ECCV 2016]
Designing loss functions
Input Ground truth](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-26-320.jpg)

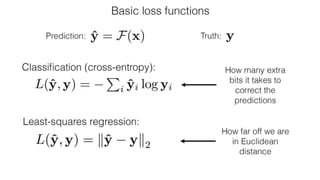
![Image colorization
Designing loss functions
L2 regression
Super-resolution
[Johnson, Alahi, Li, ECCV 2016]
L2 regression
[Zhang, Isola, Efros, ECCV 2016]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-28-320.jpg)
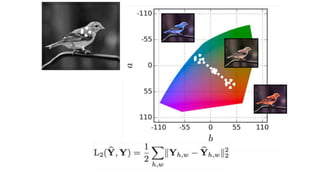
![Image colorization
Designing loss functions
Cross entropy objective,
with colorfulness term
Deep feature covariance
matching objective
[Johnson, Alahi, Li, ECCV 2016]
Super-resolution
[Zhang, Isola, Efros, ECCV 2016]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-29-320.jpg)

![…
Generated
vs Real
(classifier)
[Goodfellow, Pouget-Abadie, Mirza, Xu,
Warde-Farley, Ozair, Courville, Bengio 2014]
“Generative Adversarial Network”
(GANs)
Real photos
Generated images
…
…](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-31-320.jpg)
![Conditional GANs
[Goodfellow et al., 2014]
[Isola et al., 2017]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-32-320.jpg)
![Generator
[Goodfellow et al., 2014]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-33-320.jpg)
![G tries to synthesize fake images that fool D
D tries to identify the fakes
Generator Discriminator
real or
fake?
[Goodfellow et al., 2014]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-34-320.jpg)
![fake (0.9)
real (0.1)
[Goodfellow et al., 2014]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-35-320.jpg)
![G tries to synthesize fake images that fool
D:
real or
fake?
[Goodfellow et al., 2014]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-36-320.jpg)
![G tries to synthesize fake images that fool the best
D:
real or
fake?
[Goodfellow et al., 2014]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-37-320.jpg)
![Loss Function
G’s perspective: D is a loss function.
Rather than being hand-designed, it is learned.
[Isola et al., 2017]
[Goodfellow et al., 2014]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-38-320.jpg)
![real or
fake?
[Goodfellow et al., 2014]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-39-320.jpg)
![real!
(“Aquarius”)
[Goodfellow et al., 2014]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-40-320.jpg)
![real or fake pair ?
[Goodfellow et al., 2014]
[Isola et al., 2017]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-41-320.jpg)
![real or fake pair ?
[Goodfellow et al., 2014]
[Isola et al., 2017]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-42-320.jpg)
![fake pair
[Goodfellow et al., 2014]
[Isola et al., 2017]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-43-320.jpg)
![real pair
[Goodfellow et al., 2014]
[Isola et al., 2017]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-44-320.jpg)
![real or fake pair ?
[Goodfellow et al., 2014]
[Isola et al., 2017]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-45-320.jpg)
![BW → Color
Input Output Input Output Input Output
Data from [Russakovsky et al. 2015]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-46-320.jpg)
![Input Output Groundtruth
Data from
[maps.google.com]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-47-320.jpg)
![Labels → Street Views
Data from [Wang et al, 2018]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-48-320.jpg)
![Day → Night
Input Output Input Output Input Output
Data from [Laffont et al., 2014]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-49-320.jpg)
![Edges → Images
Input Output Input Output Input Output
Edges from [Xie & Tu, 2015]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-50-320.jpg)

![Image Inpainting
Data from [Pathak et al., 2016]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-52-320.jpg)
![Pose-guided Generation
Data from [Ma et al., 2018]](https://image.slidesharecdn.com/lec22gans-200719155103/85/Computer-Vision-Gans-53-320.jpg)


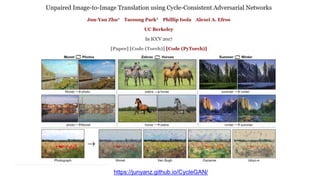
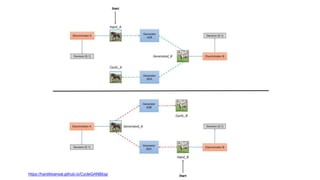




This document discusses using generative adversarial networks (GANs) to synthesize images. GANs involve training a generator network to produce synthetic images and a discriminator network to distinguish real images from synthetic ones. The goal is for the generator to learn to produce highly realistic images that fool the discriminator. The document outlines several applications of GANs like image colorization, super resolution, image-to-image translation (e.g. labels to street views). It explains how GANs can help with challenges in computer vision like high-dimensional, structured outputs and lack of supervised training data by having the discriminator assess image plausibility rather than correctness.





![[213]building ai to recreate our visual world](https://cdn.slidesharecdn.com/ss_thumbnails/213buildingaitorecreateourvisualworld-171017023224-thumbnail.jpg?width=640&height=640&fit=bounds)





























































