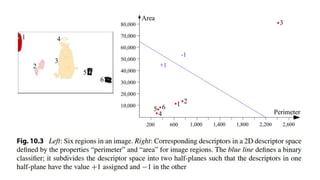
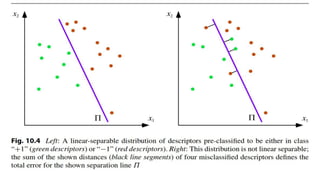
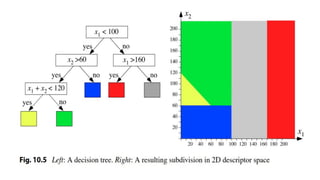
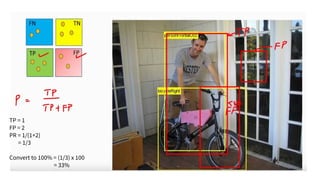
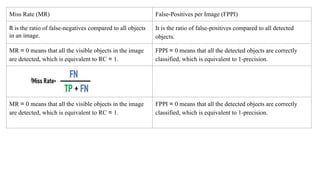
The document discusses the fundamentals of object detection systems, detailing the processes of localization, classification, and evaluation. It explains descriptors, classifiers, and learning techniques, including supervised and unsupervised learning methods, along with performance evaluation metrics such as precision, recall, and accuracy. Additionally, the document emphasizes the importance of combining various learning approaches to enhance classifier performance in detecting objects.





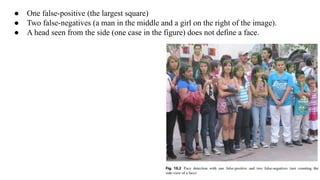







































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)
















































