Downloaded 50 times




![Dictionary
Digital Enterprise Research Institute www.deri.ie
Mapping of strings to correlative IDs. {1..n}
Lexicographically sorted, no duplicates.
Section compression explained at [8]](https://image.slidesharecdn.com/eswc2012last-120531100257-phpapp02/75/Exchange-and-Consumption-of-Huge-RDF-Data-6-2048.jpg)
![Triples Model
Digital Enterprise Research Institute www.deri.ie
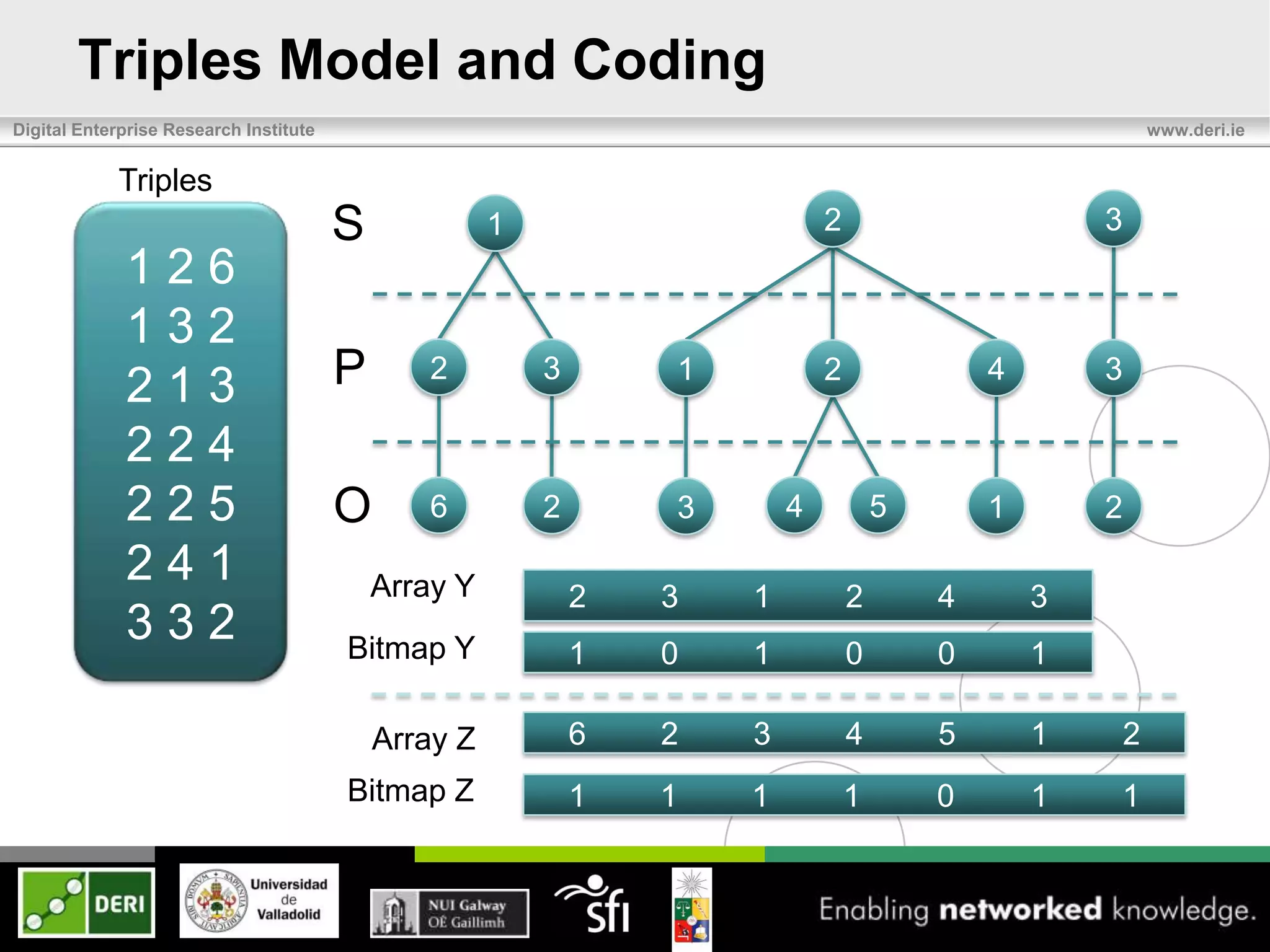
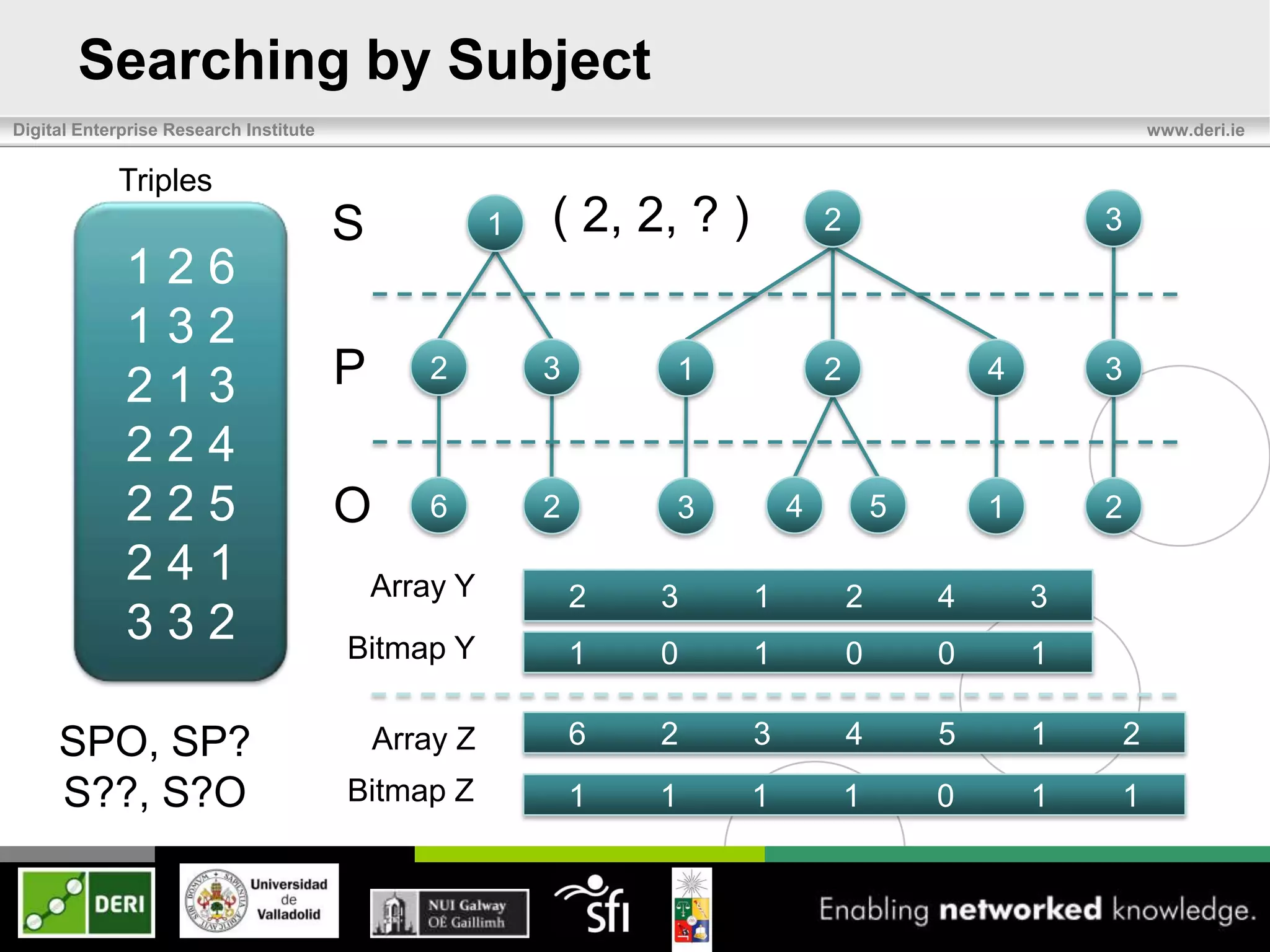
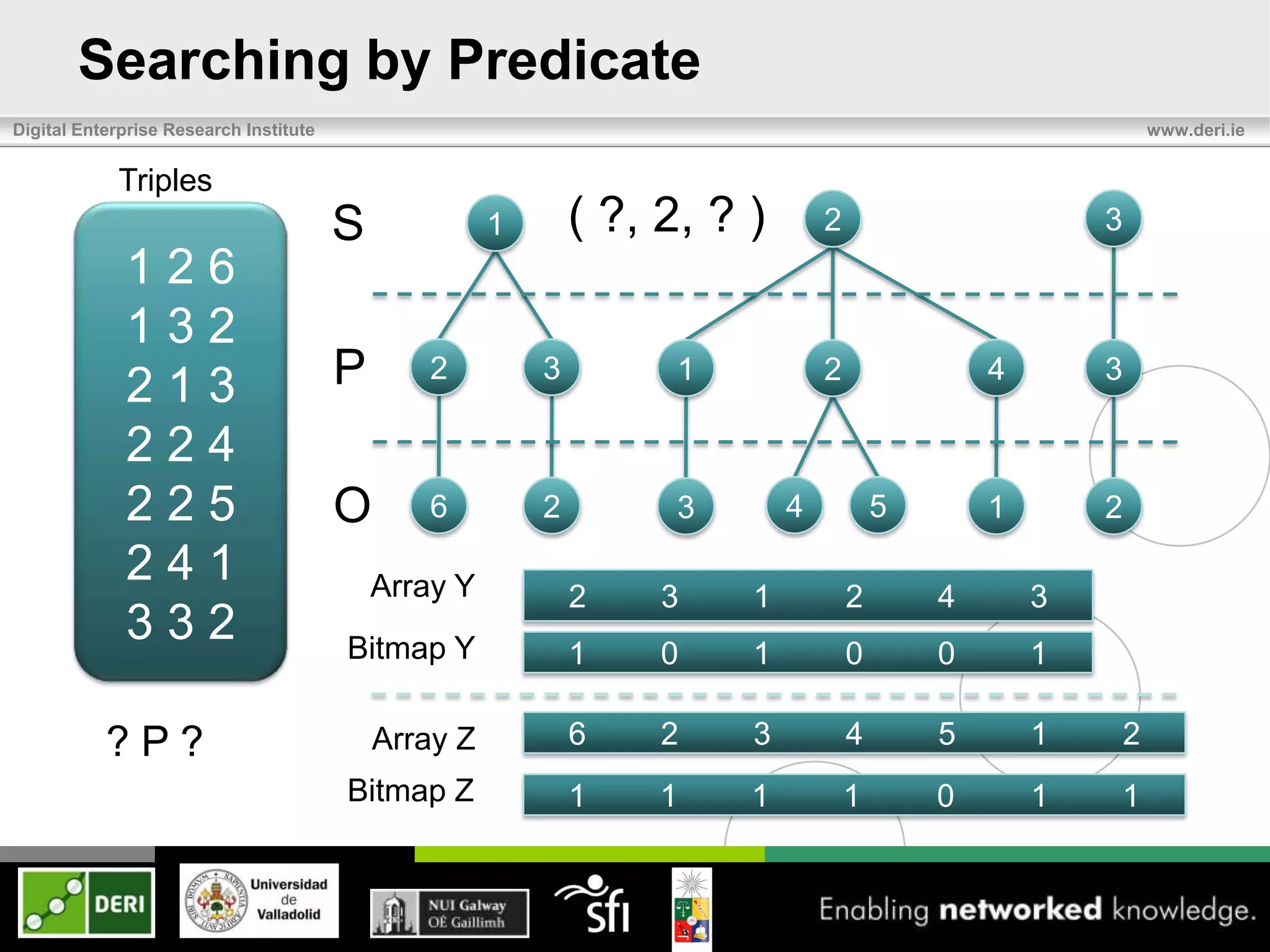
Triples
S 1 2 3
126
132
213 P[ 2 3] [ 1 2 ] [4 ] 3
224
225 O[ 6 ][ 2] [ ][
3 4 ] [5 ] [1 ] 2
241
332](https://image.slidesharecdn.com/eswc2012last-120531100257-phpapp02/75/Exchange-and-Consumption-of-Huge-RDF-Data-7-2048.jpg)
![Adjacency Lists
Digital Enterprise Research Institute www.deri.ie
1 2 3
[ 2 , 3] [ ,
1 ,2 ] [4 ] 3
1 2 3 4 5 6
Array 2 3 1 2 4 3
Bitmap 1 0 1 0 0 1
Operations:
– access(g) = Given a global position, get the value. O(1)
– findList(g) = Given a global position, get the list number. O(1)
O(log log n)
– first(l), last(l), = Given a list, find the first and last.](https://image.slidesharecdn.com/eswc2012last-120531100257-phpapp02/75/Exchange-and-Consumption-of-Huge-RDF-Data-8-2048.jpg)
![Triples: Object-Search
Digital Enterprise Research Institute www.deri.ie
Triples
S 1 ( ?, ?, 2 ) 2 3
126
132
213 P 2 3 1 2 4 3
224
225 O 6 2 3 4 5 1 2
241
332
??O OP-Index [ 6 ][ 2 ][
7 ]3[ ] [4 ] [5 ] 1
?PO O1 O2 O3 O4 O5 O6](https://image.slidesharecdn.com/eswc2012last-120531100257-phpapp02/75/Exchange-and-Consumption-of-Huge-RDF-Data-14-2048.jpg)

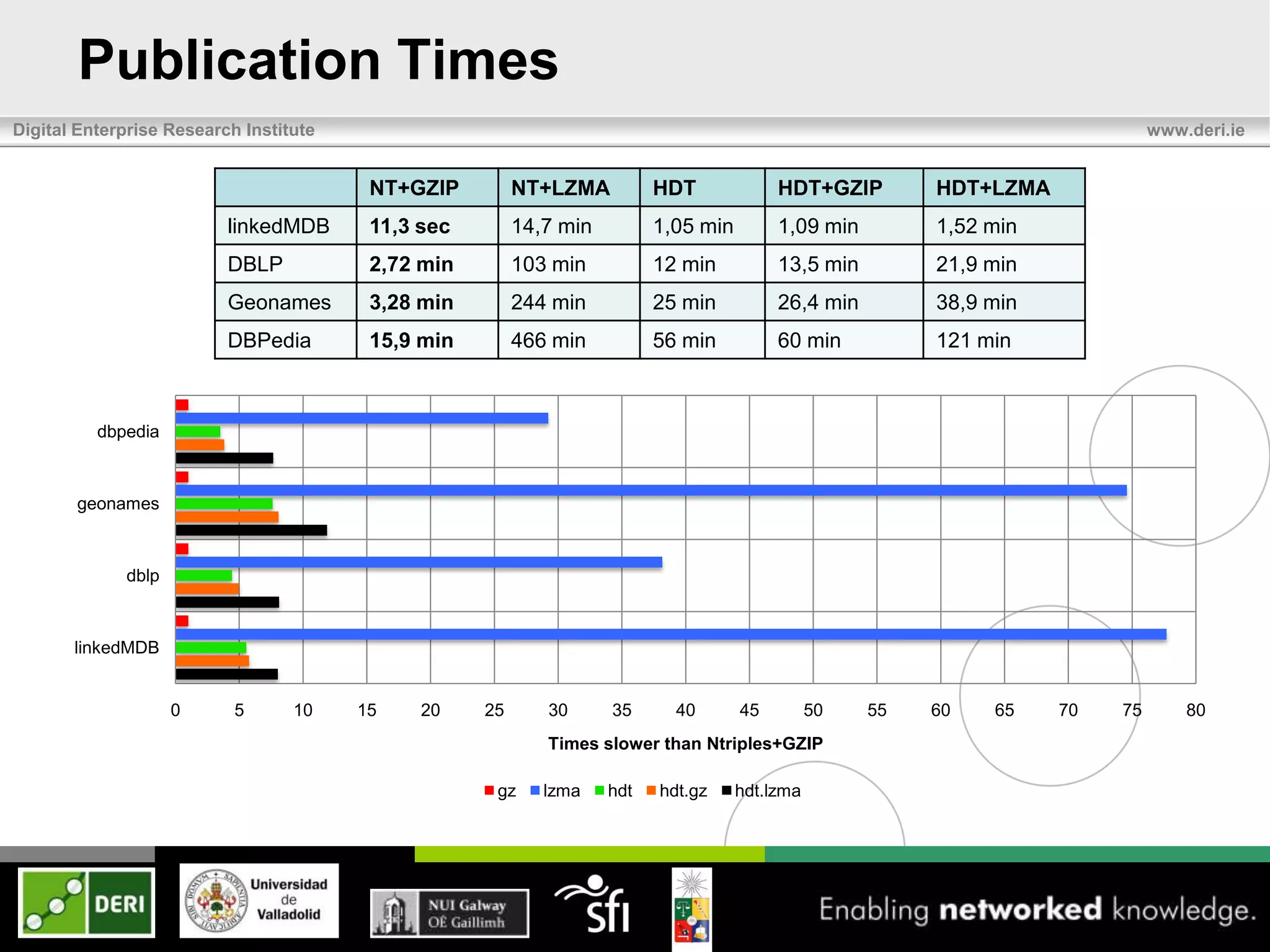
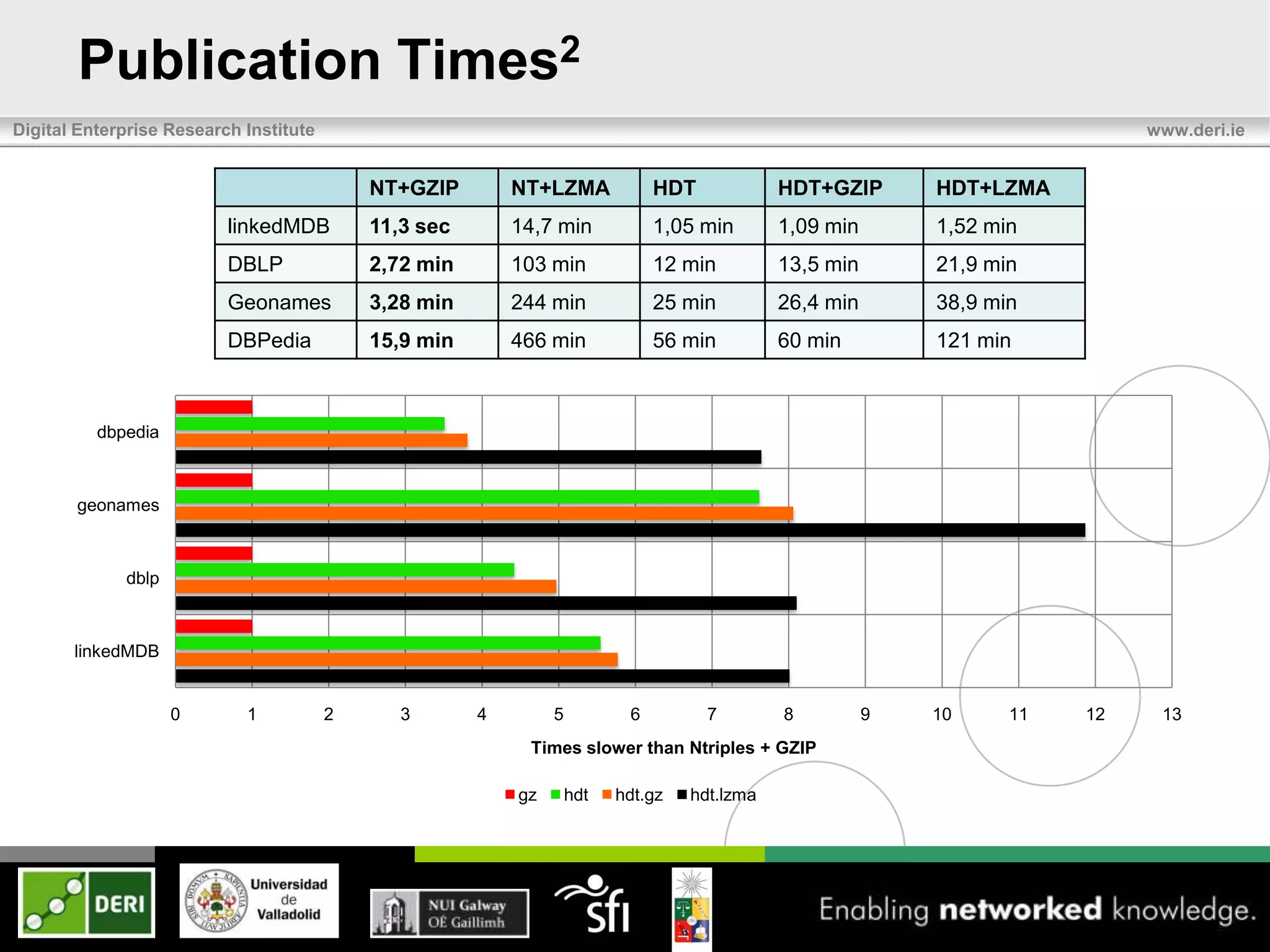
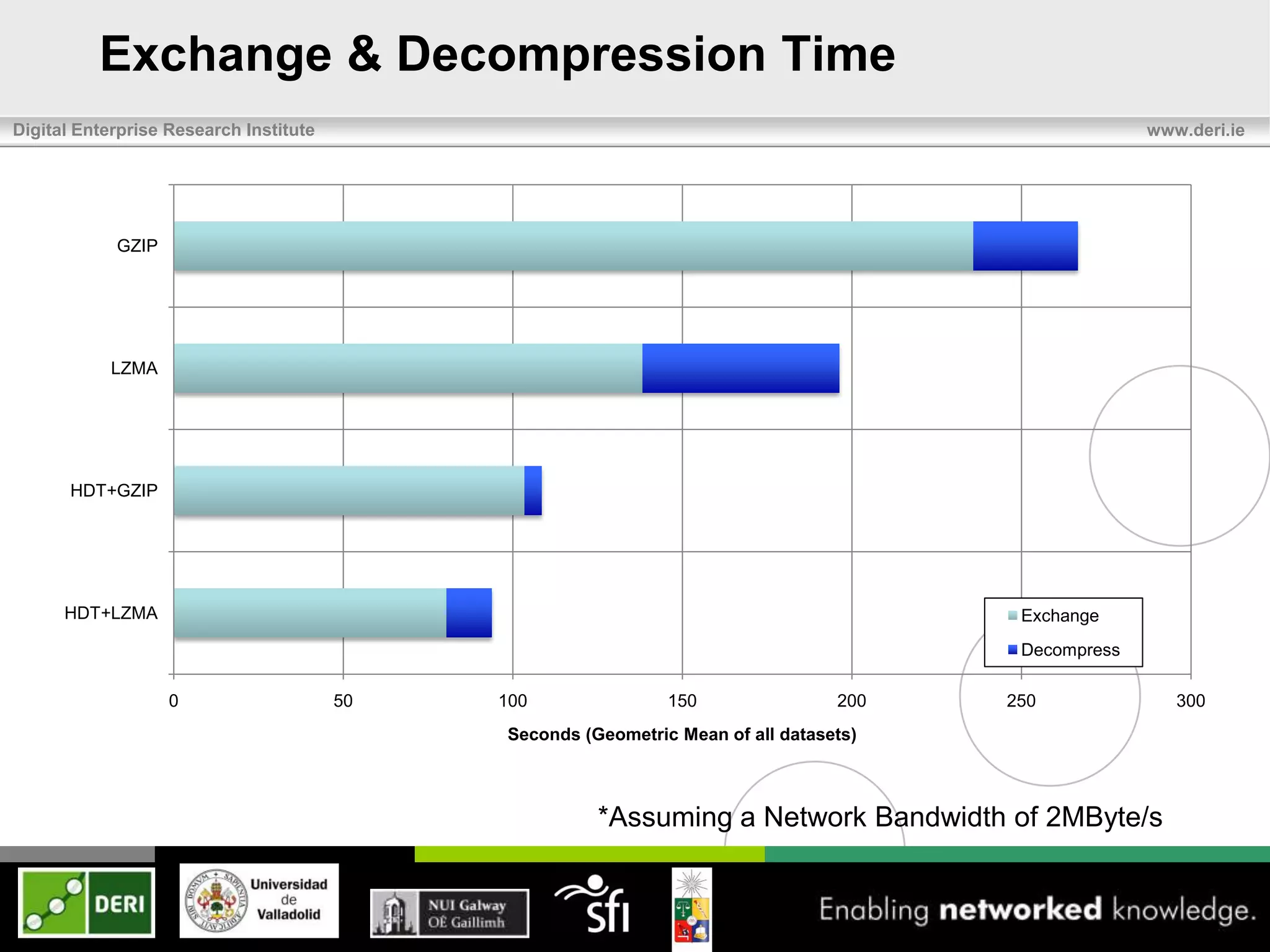
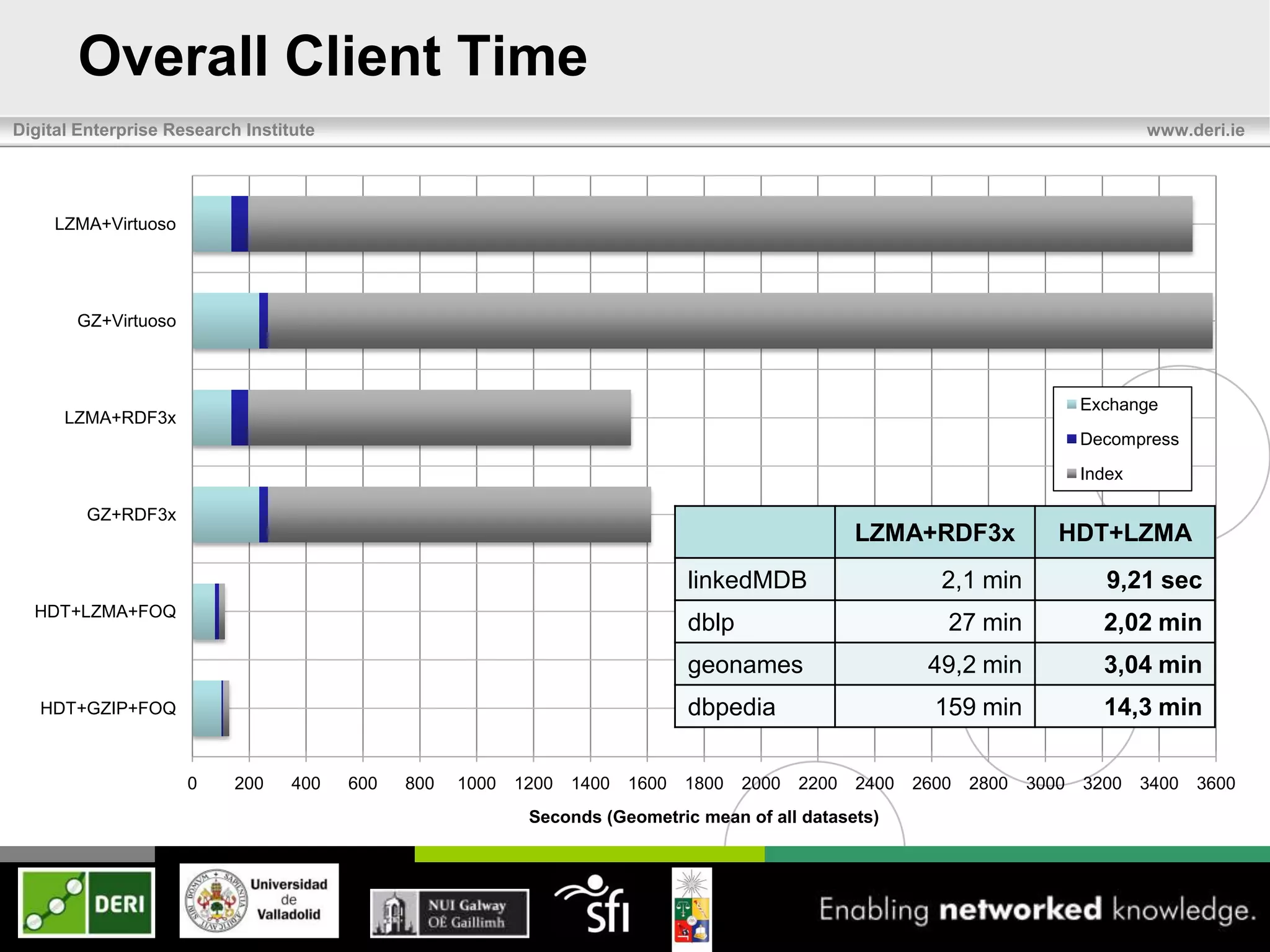
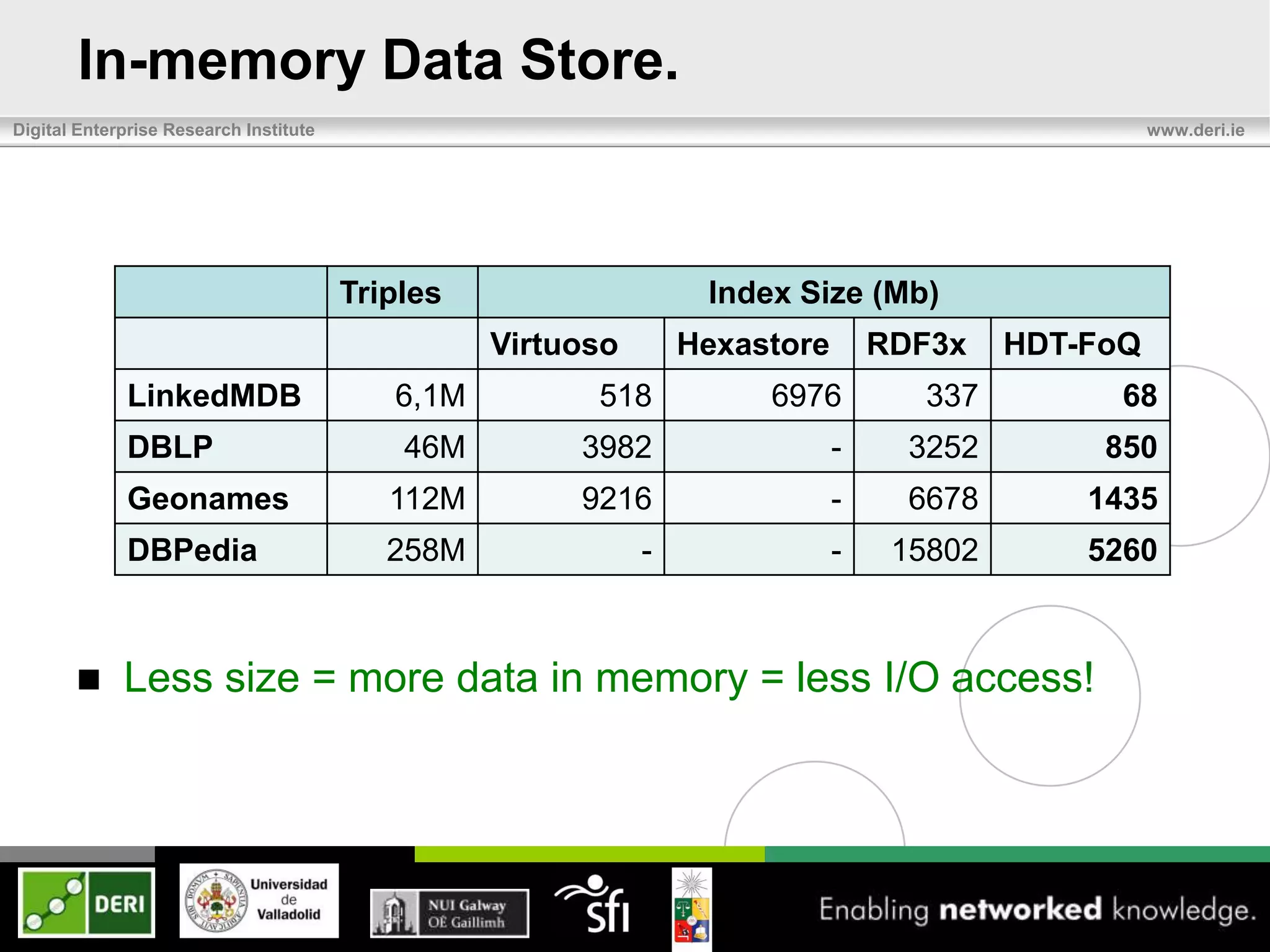
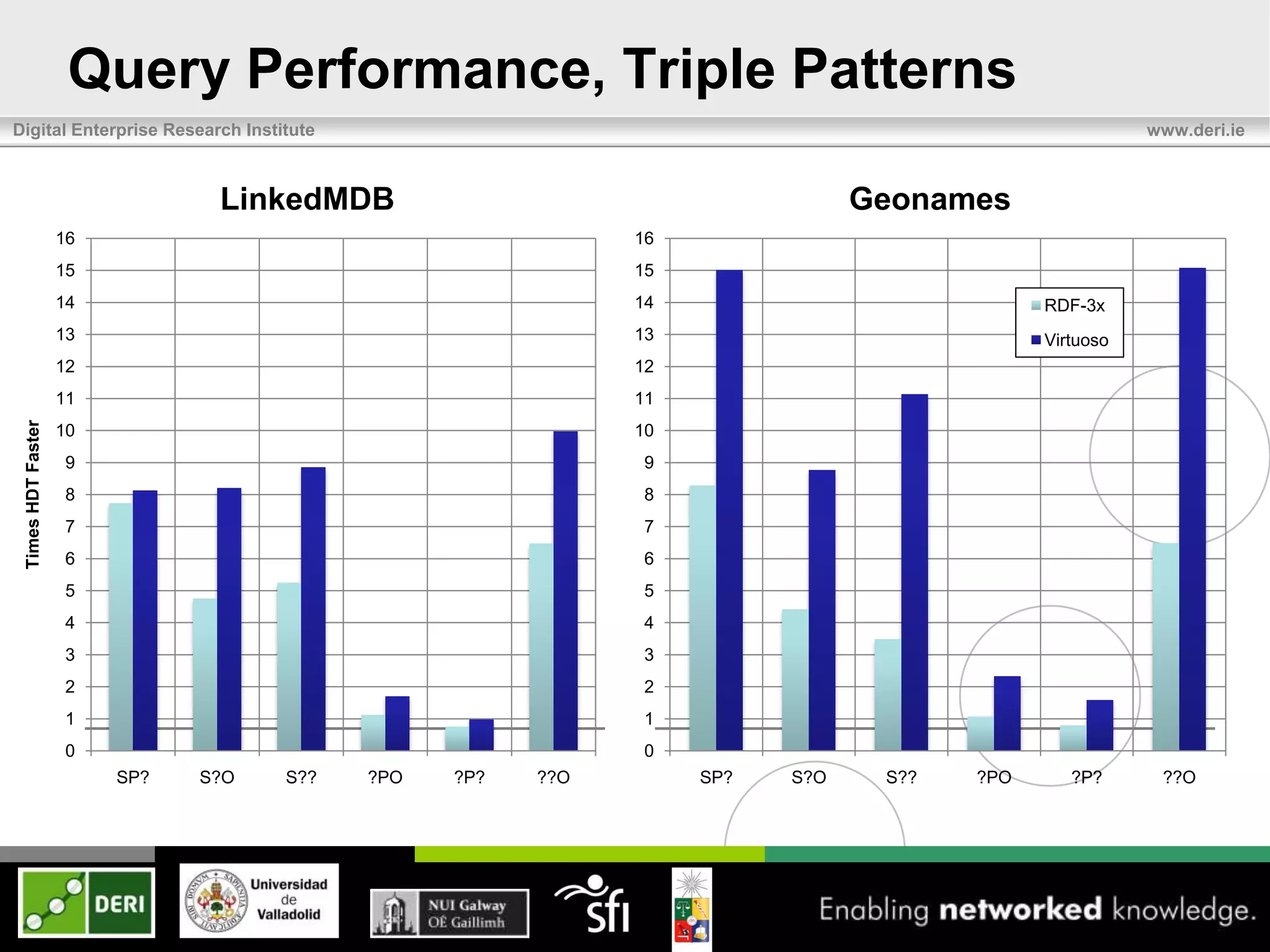
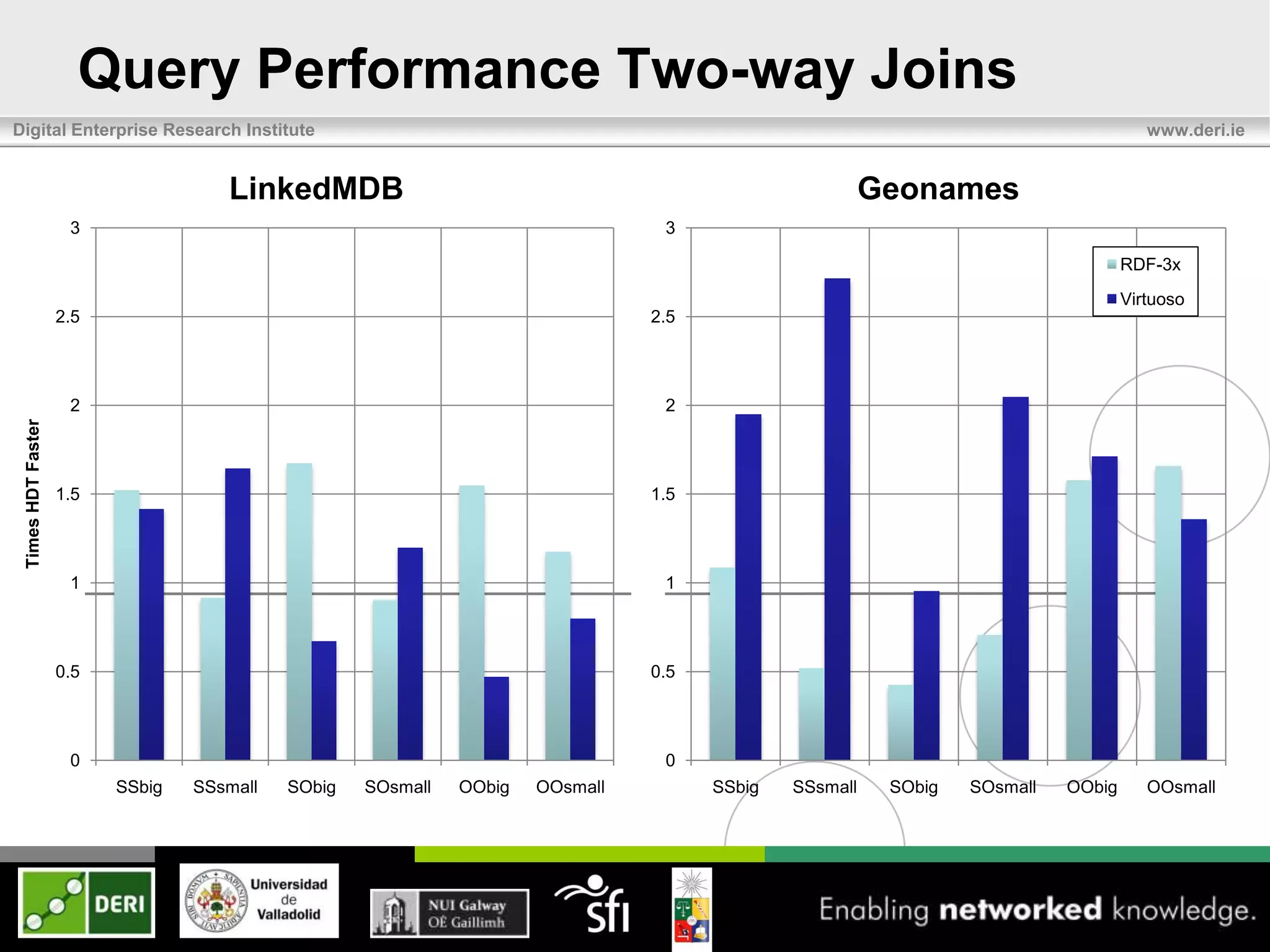


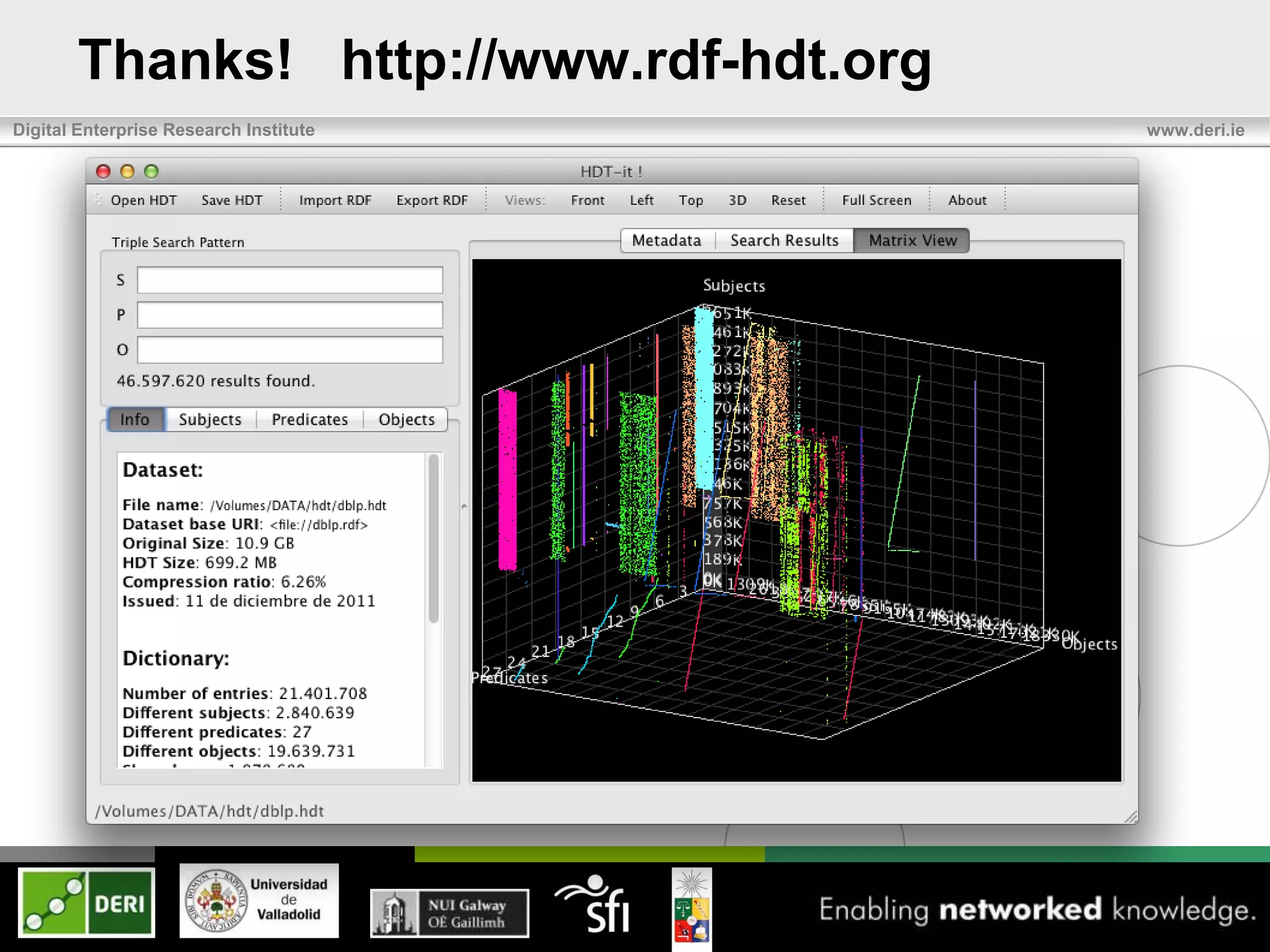

The document discusses the development of HDT (Header, Dictionary, Triples) as a compact binary format for RDF data, enhancing query and indexing performance. It presents an analysis of data exchange, compression, and the efficiency of HDT compared to traditional RDF formats, demonstrating significant improvements in data handling speed and reduced server burdens. Future work includes expanding support for SPARQL and integrating with additional platforms to increase accessibility and usability.




















































