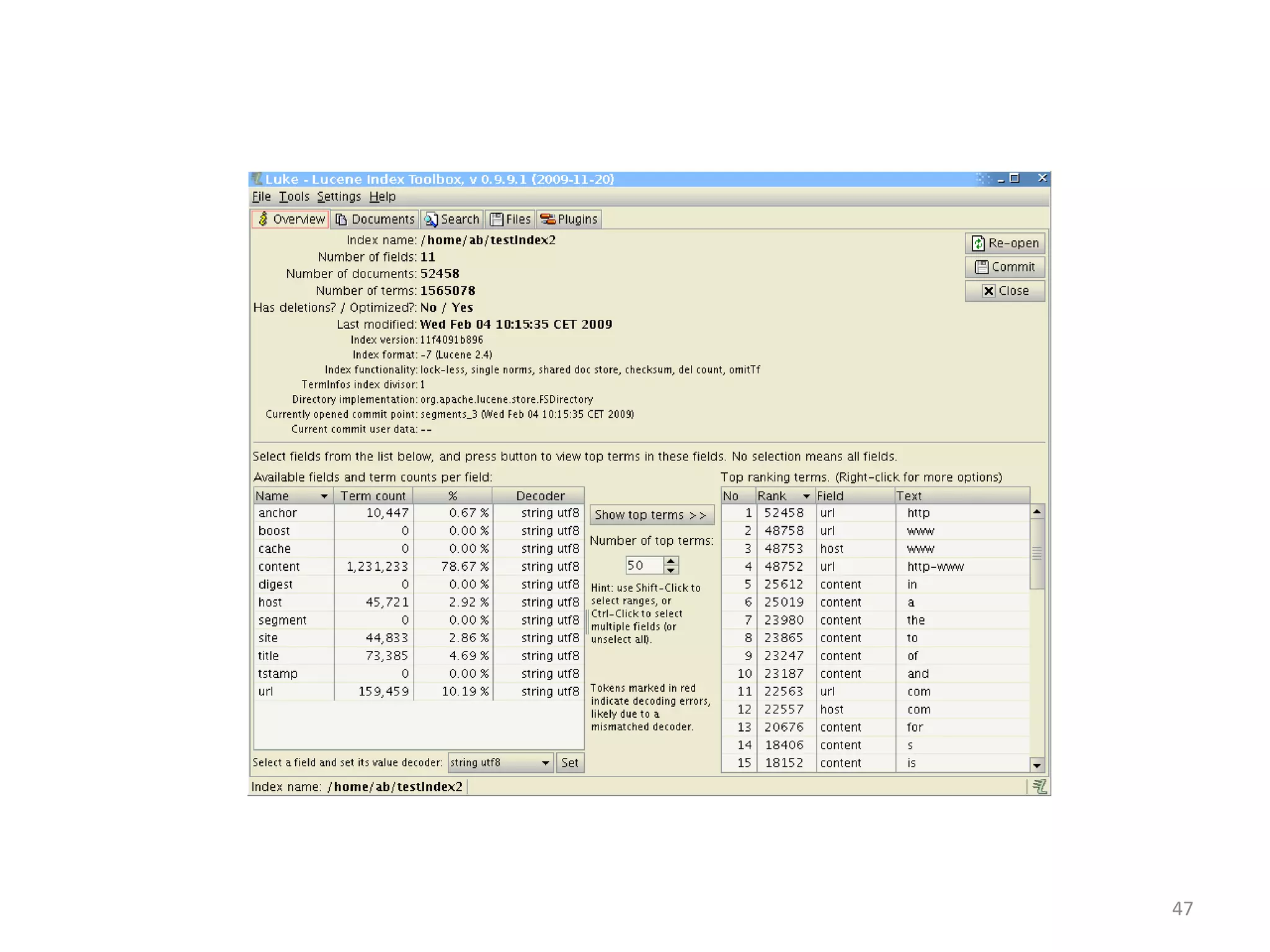
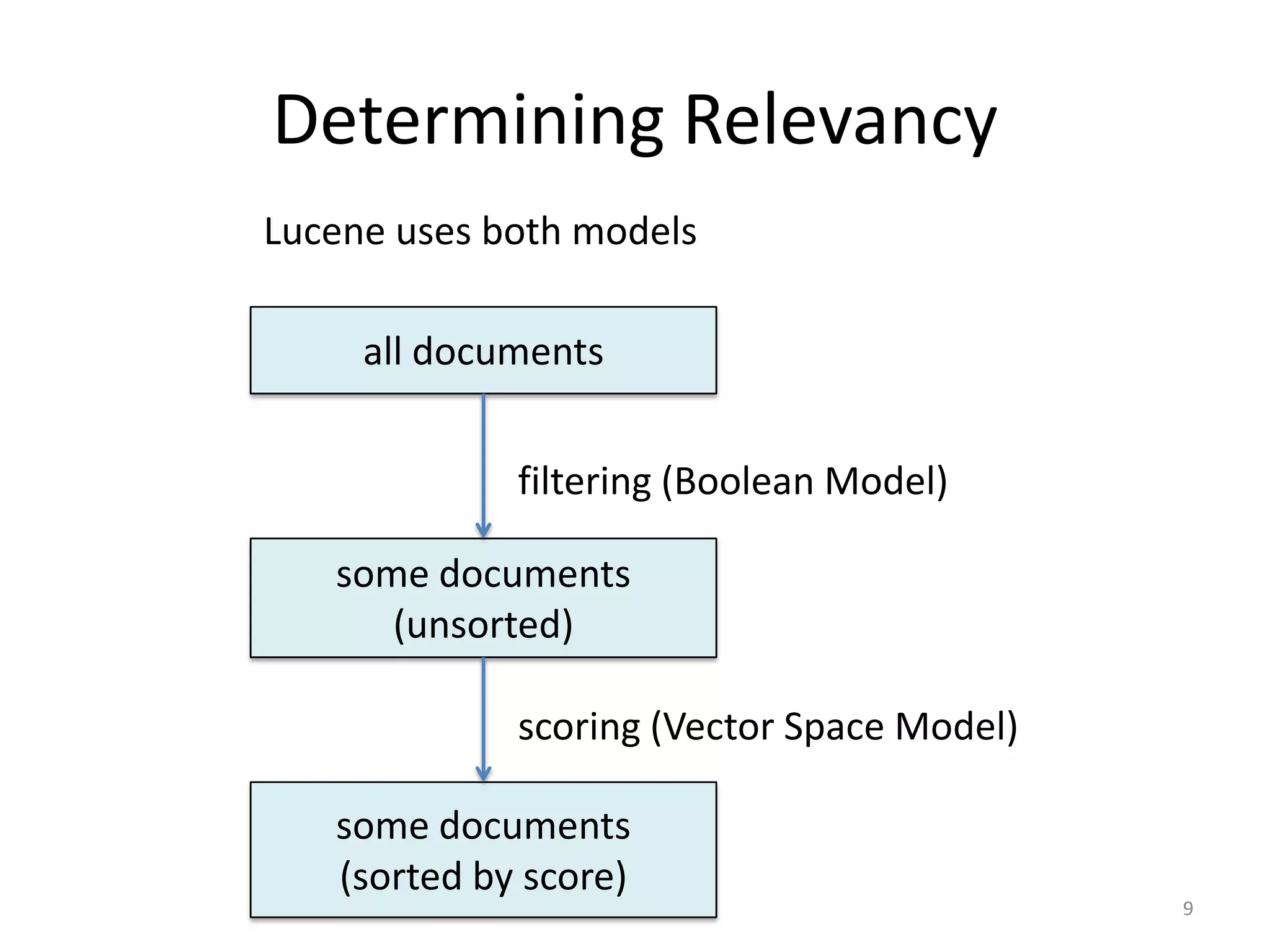
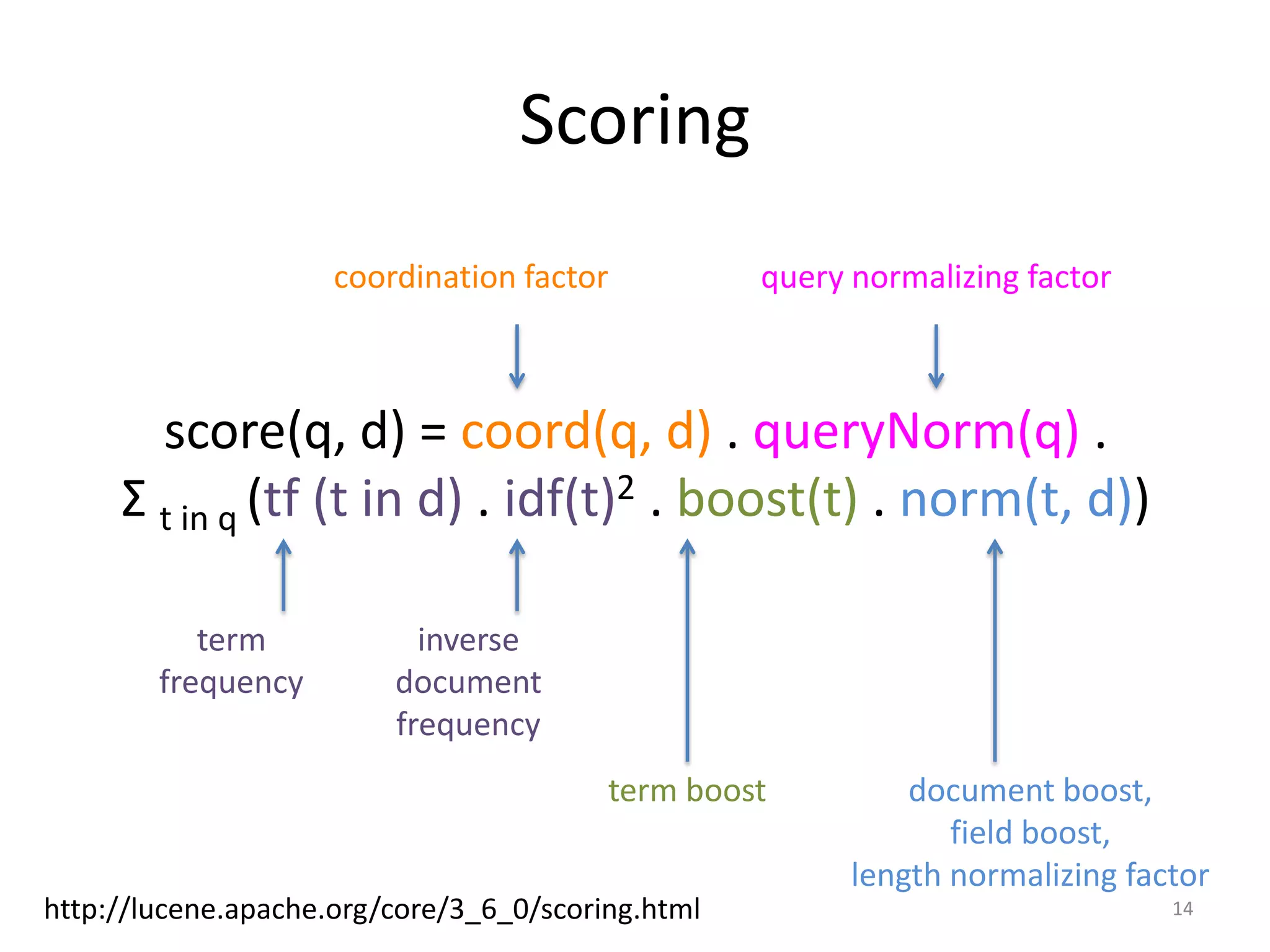
The document provides an overview of building search engines using Lucene, detailing approaches to searching, the structure and advantages of inverted indexes, and methods for determining document relevance. It explains essential concepts such as scoring, query formation, and filtering, highlighting the functionality of different query types and analysis during indexing and querying processes. Additionally, it offers resources for further reading and guidance on getting started with Lucene.

















![Text:
San Franciso, the Bay Area’s city-county
http://www.ci.sf.ca.us controller@sfgov.org
WhitespaceAnalyzer:
[San] [Francisco,] [the] [Bay] [Area’s]
[city-county] [http://www.ci.sf.ca.us/]
[controller@sfgov.org]
StopAnalyzer:
[san] [francisco] [bay] [area] [s] [city] [county]
[http] [www] [ci] [sf] [ca] [us] [controller]
[sfgov] [org]
StandardAnalyzer:
[san] [francisco] [bay] [area's] [city] [county]
[http] [www.ci.fs.ca.us] [controller] [sfgov.org]
19](https://image.slidesharecdn.com/introductiontosearchengine-buildingwithlucene-121014220929-phpapp01/75/Introduction-to-search-engine-building-with-Lucene-20-2048.jpg)

















![spanTerm(apple) spanOr([apple, orange])
apple orange apple orange
spanTerm(orange) spanNot(apple, orange)
37](https://image.slidesharecdn.com/introductiontosearchengine-buildingwithlucene-121014220929-phpapp01/75/Introduction-to-search-engine-building-with-Lucene-38-2048.jpg)

![the quick brown fox
2 1 0
1. spanNear([brown, fox, the, quick], slop = 4, inOrder = false) ✔
2. spanNear([brown, fox, the, quick], slop = 3, inOrder = false) ✔
3. spanNear([brown, fox, the, quick], slop = 2, inOrder = false) ✖
4. spanNear([brown, fox, the, quick], slop = 3, inOrder = true) ✖
5. spanNear([the, quick, brown, fox], slop = 3, inOrder = true) ✔
39](https://image.slidesharecdn.com/introductiontosearchengine-buildingwithlucene-121014220929-phpapp01/75/Introduction-to-search-engine-building-with-Lucene-40-2048.jpg)