Downloaded 11 times








![FS(A|T)
• Keys:
– byte[] – write-once
– Linear time build of min. automata
– Compression, Reverse lookups
– Weights (used for auto-suggest)
– Pluggable Algebra
• Uses:
– Term Dictionary, TokenStreams, Japanese, synonyms, spelling, others
– FuzzyQuery is 100x faster -- http://bit.ly/hgO65c
• More:
– http://slidesha.re/vKtpVA, http://bit.ly/Pkjyu0
– “Smaller Representation of Finite State Automata”
• Proc. of the 16th Inter. Conf. on Implementation and Application of Automata, CIAA'2011, vol. 6807,
2011, pp. 118—192.](https://image.slidesharecdn.com/whatsnewlucenesolr-grantingersoll-140422161935-phpapp02/75/What-s-New-in-Lucene-Solr-Presented-by-Grant-Ingersoll-at-SolrExchage-DC-11-2048.jpg)






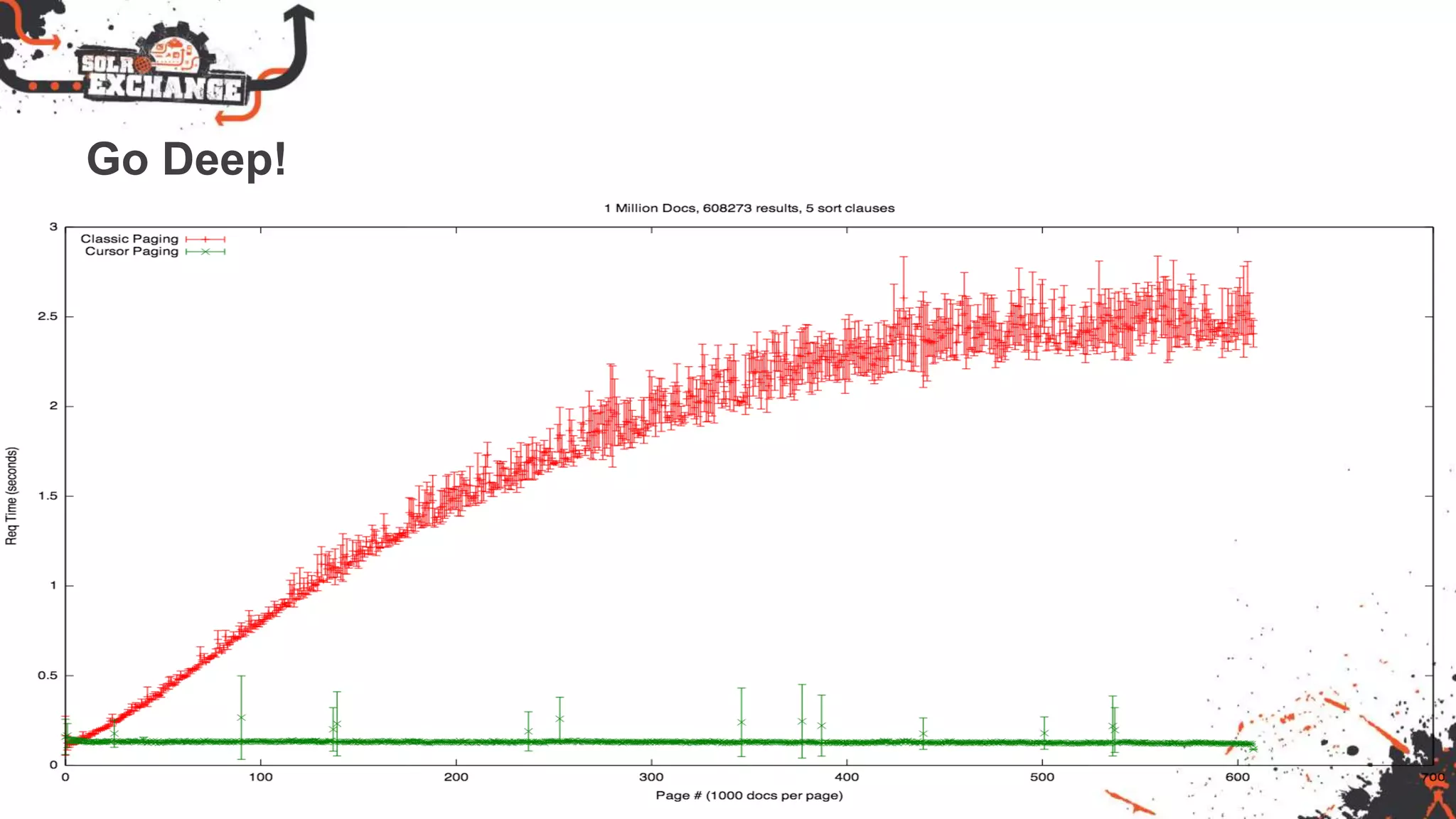



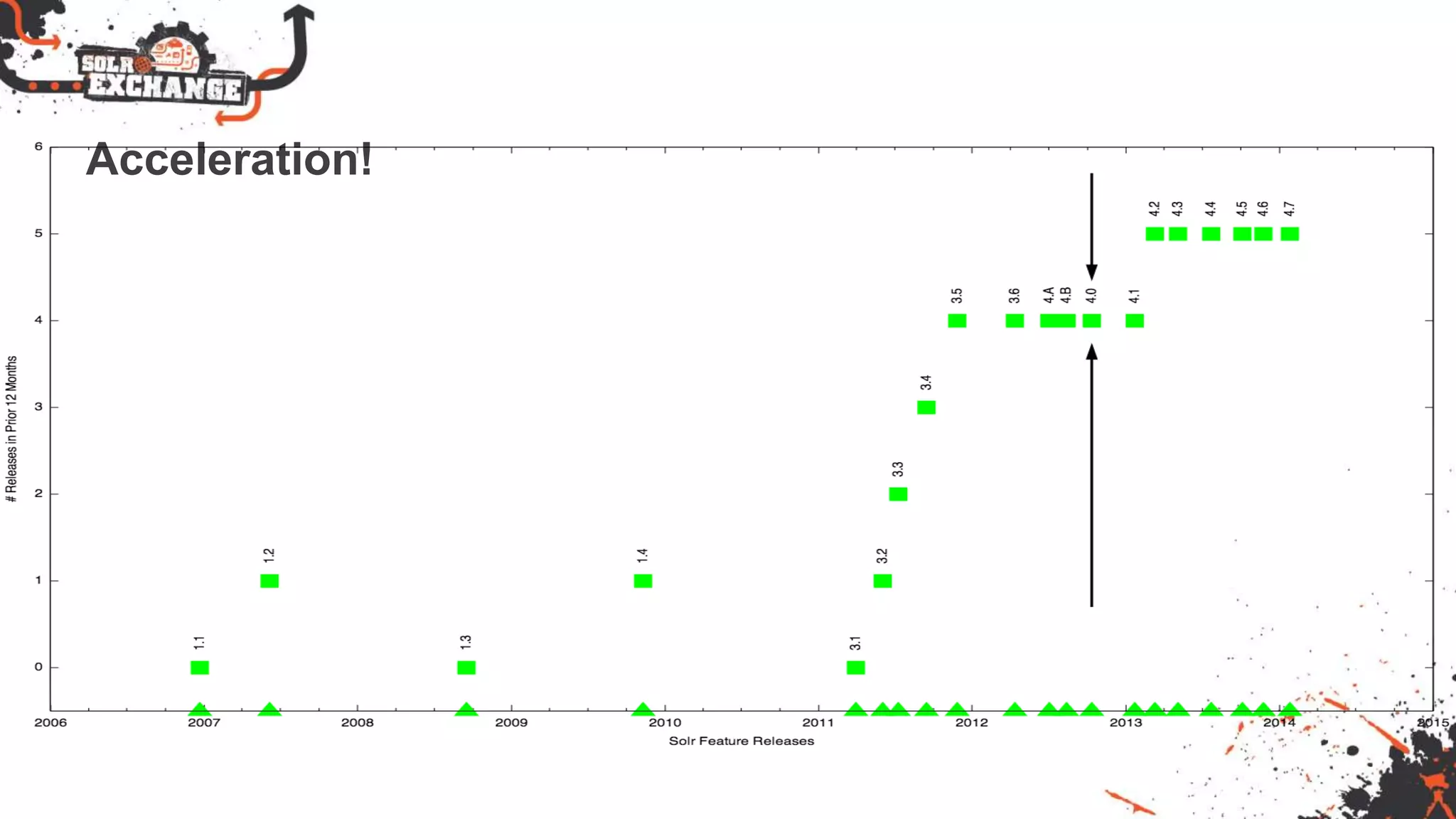
Lucene and Solr 4.8 include improvements to speed, flexibility, and scalability. Key updates include native near real-time support in Lucene, faster indexing with document writer per thread, and improved fuzzy and wildcard query processing. Solr 4 offers new faceting, geospatial, and distributed capabilities. Both projects provide easier configuration and more pluggable scoring and indexing options to improve search relevance and performance.































![Lucy in the sky[1]](https://cdn.slidesharecdn.com/ss_thumbnails/lucyinthesky1-101019194102-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











































































