Downloaded 11 times
![Collaborative Ontology Building Project - a multiagent-based ontology editing and discovery environment Jie Bao Artificial Intelligence Research Laboratory Dept of Computer Science Iowa State University Ames IA 50010 [email_address] http://www.cs.iastate.edu/~baojie Project homepage: http://boole.cs.iastate.edu:9090/COB/ A Research proposal Dec 02, 2003](https://image.slidesharecdn.com/2003-12-04cobproposal-100706164022-phpapp01/85/Collaborative-Ontology-Building-Project-1-320.jpg)
![Collaborative Ontology Building Project - a multiagent-based ontology editing and discovery environment Jie Bao Artificial Intelligence Research Laboratory Dept of Computer Science Iowa State University Ames IA 50010 [email_address] http://www.cs.iastate.edu/~baojie Project homepage: http://boole.cs.iastate.edu:9090/COB/ A Research proposal Dec 02, 2003](https://image.slidesharecdn.com/2003-12-04cobproposal-100706164022-phpapp01/75/Collaborative-Ontology-Building-Project-1-2048.jpg)






![A Desirable Case -- Pop Music Ontology (1) Suppose we want to build an ontology and knowledge base about pop music called PopOnt Even kids know John is a teenager student and knows nothing about ontology. But he knows much about pop music. He’d like to share his knowledge to PopOnt. I’m willing to spend 5 minutes for you There are millions of pop music fans like John, their knowledge is complementary each other. Some of them may go to the website of PopOnt and write one or two pieces of simple sentences, like [ M. Jackson] [isn’t] a [country music artist]. They may also correct others’ mistakes](https://image.slidesharecdn.com/2003-12-04cobproposal-100706164022-phpapp01/85/Collaborative-Ontology-Building-Project-8-320.jpg)
![A Desirable Case -- Pop Music Ontology (2) You even don’t need to go to the website There are also mailing lists, newsgroups, weblogs, p2p applications and websites about pop music, which can be used for validation or mining. For example, if [M. Jackson] hardly coincides with [country music], it’s more possible [ M. Jackson] [isn’t] a [country music artist] is true Agent can be expert, too. It will be more desirable if those articles have subject, abstract, or even keywords, which can be used as labeled instances for machine learning. New concepts can be mined and cross-validated by people, too. Finally, PopOnt is built in a couple of months and free to use for everyone.](https://image.slidesharecdn.com/2003-12-04cobproposal-100706164022-phpapp01/85/Collaborative-Ontology-Building-Project-9-320.jpg)

![Key Difficulties 1 : Logic breakdown How to make ontology editing as easy as writing diary? Ontology [subject][predicate][object] [subject][predicate][object] [subject][predicate][object] [subject][predicate][object] Class SubClass SubSubClass SubSubClass SubClass SubSubClass SubSubClass Classes and Slots Instances Can complex ontology be broken down into group of single sentences? Or say, how to decompose complex description logic statement into very simple FOPL sentences? And inverse composition is also needed. Each single sentences is as simple as A is B , A has B](https://image.slidesharecdn.com/2003-12-04cobproposal-100706164022-phpapp01/85/Collaborative-Ontology-Building-Project-11-320.jpg)







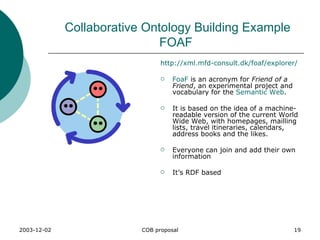

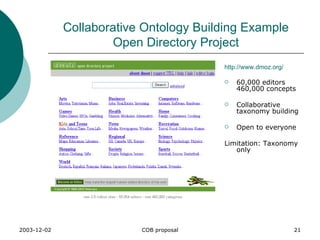


![Part A (2): OWL-like syntax // COB terms cob:equals cob:documentation // OWL terms owl:AllDifferent owl:allValuesFrom owl:backwardCompatibleWith owl:cardinality owl:Class owl:complementOf owl:DatatypeProperty owl:DeprecatedClass owl:DeprecatedProperty owl:differentFrom owl:disjointWith owl:distinctMembers owl:equivalentClass owl:equivalentProperty owl:FunctionalProperty owl:hasValue owl:imports owl:incompatibleWith owl:intersectionOf owl:InverseFunctionalProperty owl:inverseOf owl:maxCardinality owl:minCardinality owl:Nothing owl:ObjectProperty owl:oneOf owl:onProperty owl:Ontology owl:priorVersion owl:Restriction owl:sameAs owl:someValuesFrom owl:SymmetricProperty owl:Thing owl:TransitiveProperty owl:unionOf owl:versionInfo rdf:List rdf:nil rdf:type rdfs:comment rdfs:Datatype rdfs:domain rdfs:label rdfs:Literal rdfs:Literal rdfs:range rdfs:subClassOf rdfs:subPropertyOf A subset of OWL is used Single statement are RDF-like triple [subject] [predicate] [object] Name Space are used cob:instanceOf owl:Class rdfs:subClassOf Core COB language is defined in it’s own namespace (see right)](https://image.slidesharecdn.com/2003-12-04cobproposal-100706164022-phpapp01/85/Collaborative-Ontology-Building-Project-25-320.jpg)
![Part A (3): Instance Example # [cob:Instance] # [cob:instanceOf] [Student] # [cob:instanceOf] [Chinese] # [cob:equals][ 鲍捷 ] # [hasSurname] Bao # [hasFirstname] Jie # [worksOn] [semanticWeb] # [worksOn] [MAS] # [worksOn] [complexSystem] # [advisedBy] [Honavar] # [memberOf] [aiLab] # [hasEmail] baojie@cs.iastate.edu # [hasHomepage] http://www.cs.iastate.edu/~baojie # [cob:documentation] Hi, I love cats BaoJie cob:Instance cob:instanceOf Student ? cob:instanceOf Chinese ? cob:equals 鲍捷 hasSurname Bao hasFirstname Jie worksOn semanticWeb ? worksOn MAS ? worksOn complexSystem ? advisedBy Honavar ? memberOf aiLab ? hasEmail baojie@cs.iastate.edu hasHomepage http://www.cs.iastate.edu/~baojie cob:documentation Hi, I love cats Edit this page More info... Attach file... Source Screen shows](https://image.slidesharecdn.com/2003-12-04cobproposal-100706164022-phpapp01/85/Collaborative-Ontology-Building-Project-26-320.jpg)
![Part A (4): Name Space Java-like package naming, which shows the relatedness of concepts even when they don’t inherit from the same concept. Packages are in DAG Internationalization is enabled //cob:Thing.Country.US.Iowa.Ames.ISU //cob:Thing.Education.University.Iowa.ISU [cob:instanceOf] [PublicUniversity] [cob:instanceOf] [dmoz:University] [cob:equals] [Iowa State University] // cobZH: 事物 . 美国大学 . 艾奥瓦州立大学 [cob:language] zh // Chinese [cob:equals] [cob:Thing.Country.US.Iowa.Ames.ISU] //cob:Thing.Education.University.Idaho.ISU [cob:instanceOf] [PublicUniversity] [cob:instanceOf] [dmoz:University] [cob:equals] [Idaho State University]](https://image.slidesharecdn.com/2003-12-04cobproposal-100706164022-phpapp01/85/Collaborative-Ontology-Building-Project-27-320.jpg)

![Part C (1): Agent Each agent does Trace back information source and check its credibility. Do filtering and text normalization Extract new concept from instances Extract possible general relationship (like [cob:alsoSee]) between concepts And they may differs Not necessarily should use the same learning algorithm Learning from email header are different from learning from free text content Dialect Agent 1: I listens to Idaho S.U. maillist and know ISU = Idaho State University Agent 2: I watch a blog in Iowa and know ISU = Iowa State University Communication helps Agent 1: P([M. Jackson]^[CountryMusic])=0.1 Agent 2: P([M. Jackson]^[CountryMusic])=0.03](https://image.slidesharecdn.com/2003-12-04cobproposal-100706164022-phpapp01/85/Collaborative-Ontology-Building-Project-29-320.jpg)

![Part D : Ontology Repository Version control Keep version for each concept, lock mature concepts, detect malicious changes Redundancy check [I.S.U] [cob:instanceOf] [University] [I.S.U] [cob:alsoSee] [Cyclone] [Iowa Stete University] [cob:instanceOf] [PublicUniversity] [Iowa Stete University] [cob:alsoSee] [Cyclone] [PublicUniversity] [cob:subClassOf][University] Conflict check [ISU] [locatedIn] [Ames] [ISU] [locatedIn] [Des Moines] Cross validation Score agent and expert for it’s credibility Check soundness of inputs from it’s peer inputs. Refactoring (rename, remove, merge)](https://image.slidesharecdn.com/2003-12-04cobproposal-100706164022-phpapp01/85/Collaborative-Ontology-Building-Project-31-320.jpg)


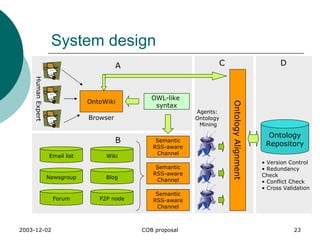
The document proposes a collaborative ontology building project (COB) that uses a multi-agent approach to facilitate distributed ontology editing and discovery. Key challenges addressed include making ontology editing easy for non-experts, enabling iterative ontology evolution through expert and agent cooperation, and facilitating ontology mining from distributed and dynamic data sources on the web. The proposed system design involves an ontology repository, various human and software agents that contribute to and validate ontologies, and techniques for tasks like ontology alignment and redundancy/conflict checking.





































































































