Downloaded 41 times



















































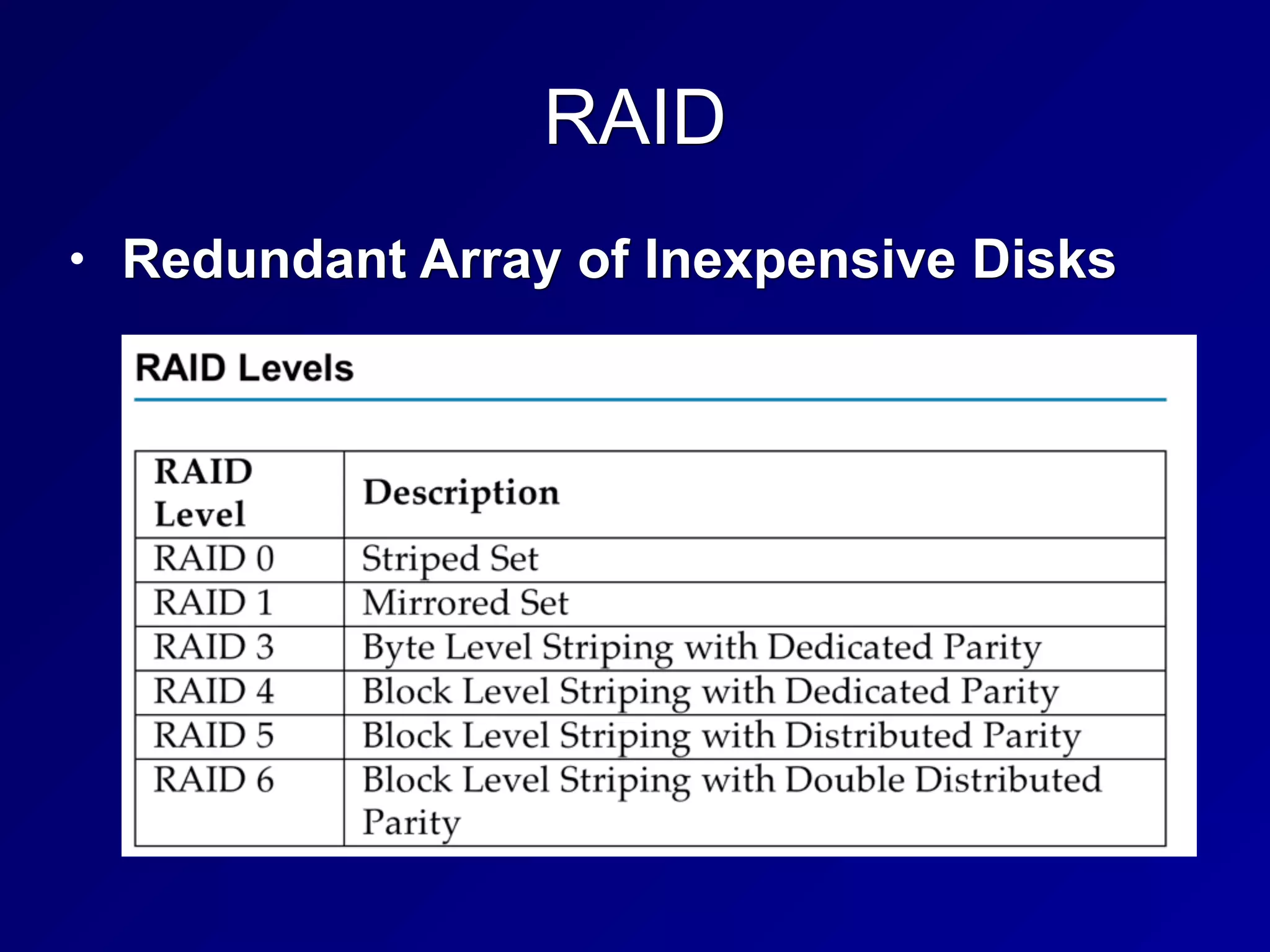
























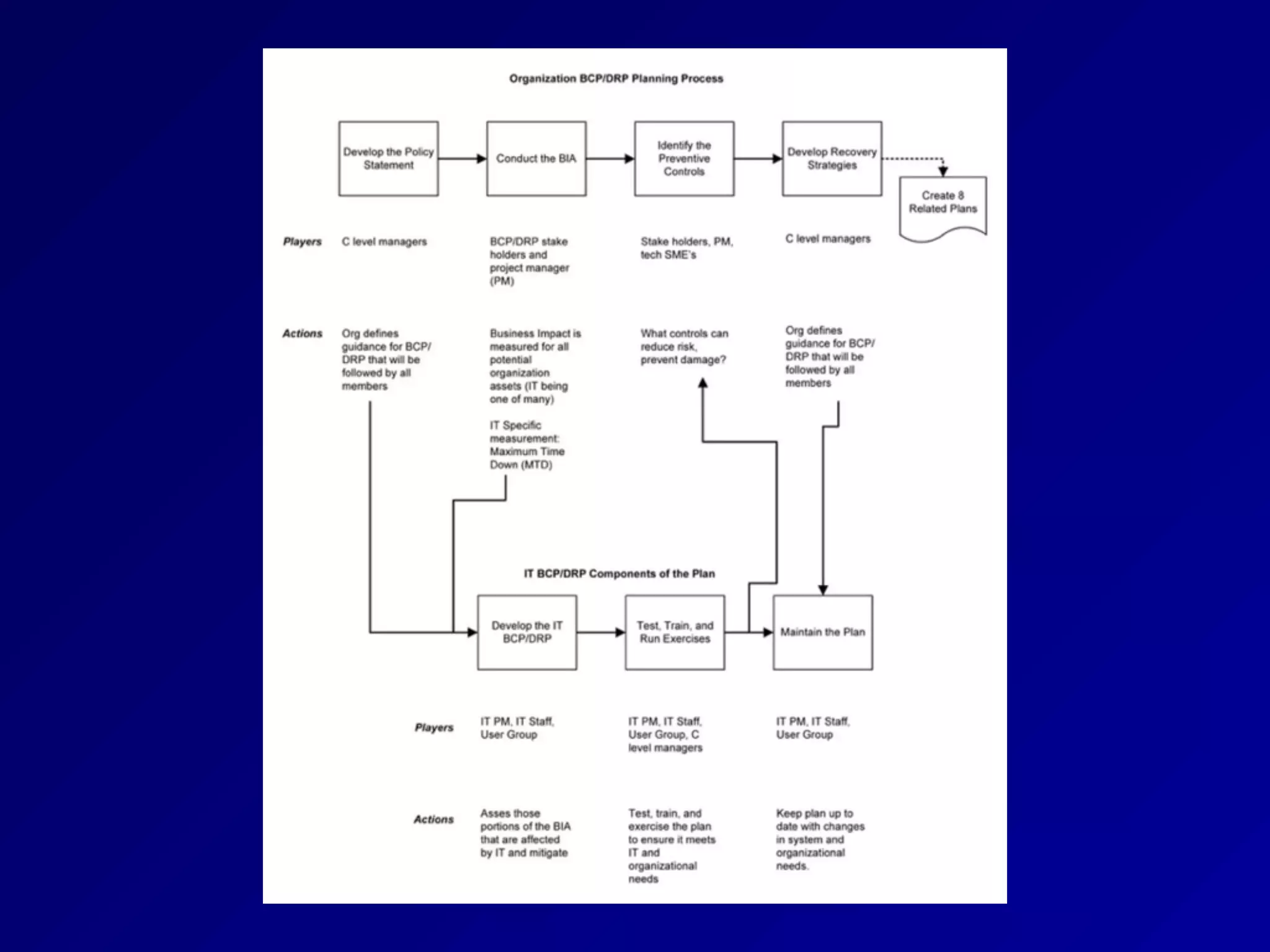









































Chapter 8 of CNIT 125 covers administrative security controls, forensic analysis, incident response management, and business continuity planning. Key topics include privilege management, forensic phases, incident response steps, and disaster recovery techniques to ensure system resilience and data recovery after incidents. It emphasizes the importance of risk assessment, continuous monitoring, and effective communication strategies during and after disruptive events.























































































