#3 If we can collectively execute as a group we will spark a data revolution.
We have seen this happen before. The industrial revolution was sparked by new manufacturing technology that allowed organizations to more efficiently produce products, in turn, offering a better more affordable product to consumers. This had a profound impact on not only the producer but also the consumers.
The same thing will happen with data.
If we can leverage data in a way that makes people more efficient at building better products we can in turn provide a better service to end users have a similar impact on the world around us.
Just like the industrial revolution started with the Textile industry the data revolution started with the technology sector. The Googles, Facebooks, Ubers of the world have already changed our lives, and in turn, have seen the data returns that we are all after.
#4 Key Takeaways: Industries are already beginning to transform. How can data help transform the way employees and customers interact with these industries.
#5 Key Takeaways: Employees are already asking the right questions, we just need to help them achieve their goals through the use of data.
#6 With maturity of the platform and technology ecosystem, and with enterprises better understanding not only the promise of the technology but also how to implement it, we are seeing a fundamental shift in the market…..
Hadoop and big data are no longer about technologies only, nor are they simply about cost reduction. In fact, there have been shifts towards aligning data to business objectives in order to derive even greater value out of big data.
The three areas of opportunities within businesses generally are:
Customer 360 - How do I understand my customers and my channel better to improve my topline?
Data-driven products - How do I create better and more products to satisfy the needs of my customers?
Risk - How do I make sure that the company complies to rules and regulations, protects customer and enterprise information, and minimize the risk factors?
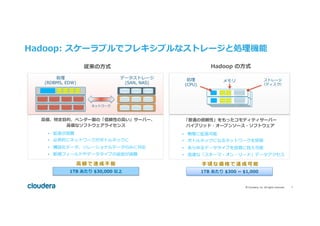
#8 Pricing Data: Cloudera: HW + SW per-year list prices for Basic thru EDH at various configs
Old Way: Various sources. One of note:
- Cowen / Goldmacher coverage initiation of Teradata, June 17, 2013
- List price of high-end appliance (which he thinks is more comparable to our solution) is $57K/TB + maintenance for an annual cost of $39K/TB
- Prices have likely decreased, but we estimate they are still in excess of $30K/TB/year
- List price of their low-end appliance is $12K/TB + maint or $8K per year
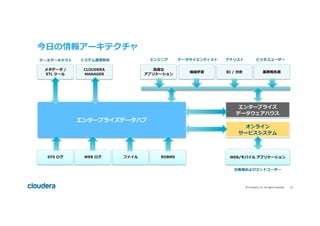
#9 Today we're in the middle of a shift in how businesses use information. In the past, you'd define a set of business processes, build applications around each of them, and then go about gathering, conforming, and merging the necessary data sets to support those applications. From an infrastructure perspective, you'd be bringing the data over to the compute, often in relational databases. But you'd be leaving quite a lot on the table.
The modern realities of business demand a new approach. Today companies need, more than ever, to become information-driven, but given the amount and diversity of information available, and the rate of change in business, it's simply unsustainable to keep moving around and transforming huge volumes of data.
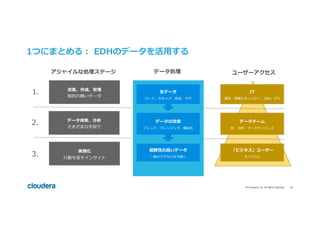
#10 We are in the middle of a shift in how businesses use information.
We want to use not just more data, but more kinds of data.
We need to combine old data with new, interact with data in multiple ways, and rapidly iterate on the results.
Several challenges:
A. Limited Data.
Faced with the tremendous growth in volume and variety of data, most existing systems aren’t positioned to meet the demand and require you to store data offline where it is inaccessible to users.
B. Limited Insights.
Analysts and data scientists struggle with the tools available to them.
SQL is only one way to interact with data, and often not the right tool for the job.
Without access to all the original data, it can take weeks or months to deploy new views.
If the tools your data team uses are limited to the expertise of that team then business user must rely on the stressed data teams.
C. Complex Architecture.
Managing multiple systems creates gaps in security, policy enforcement, and management capabilities.
Not to mention inflated costs and a decrease of ROI
In traditional architectures, it can be complex to secure all data for all users, so it’s often easier to simply leave data out of analysis, or lock users out of analytics
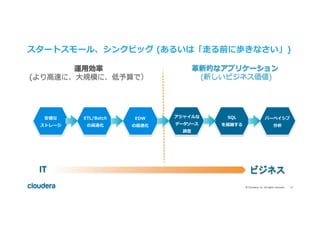
#11 The Journey is not easy
It takes time
We know, we have done this countless times before
New technology can seem complex
It can create operational complexity
Requires new skills and ongoing training
3 parts to the solution: architecture, team, process
#12 Assemble the right team and make sure the right players are part of the conversation.
Get the right architecture to provide your users the right framework and tools to do their jobs.
Adopt an agile approach, and never stop experimenting.
#13 Breakdown as more personas and not necessarily titles. And each think about different things.
IT – provides plumbing and data to business users.
Next we need to think about security.
Deliver self service where you can!
But don’t stop here!
Build a data team
The people that are tasked turning data into value.
Try many things quickly and they need good tools.
They also need high performance tools.
Business Users
One of the reasons big data projects fail is because business users are not brought into the conversation at the right time.
Seek executive sponsors and internal champions : These users care about results.
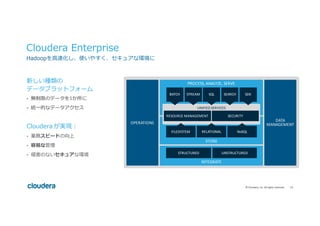
#14 Enter Apache Hadoop, I imagine that is why you all are here today?
Apache Hadoop is a community
Continues to grow as Hadoop continues to expand out of just batch storage and processing.
As more businesses adopt Hadoop, more use cases emerge.
With Hadoop, you don’t just get the code your team built, you get the code the community built.
#17 Hadoop does not need a schema to load and land data.
You can land any data in full fidelity.
Secure it and tag it, then make it available to your data team.
Leverage more types of data and future-proof your efforts as the business matures
#19 In Summary, In order to realize the dream of Pervasive Analytics
It’s a cultural shift as much as a technology shift
Start Small, and prepare for the next success
It takes time, start today
Lean on experts in the community, and never stop experimenting






















![JPC2017 [F2-2] オープンソースと検索可能暗号技術でSharePoint Onlineを秘匿化](https://cdn.slidesharecdn.com/ss_thumbnails/jpc2017f2sharepointonline-170911125913-thumbnail.jpg?width=640&height=640&fit=bounds)















![[Preview] MySQL session at Open Source Conference 2014 .Enterprise Osaka](https://cdn.slidesharecdn.com/ss_thumbnails/201409mysqlbizprev-140801204802-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[DI12] あらゆるデータをビジネスに活用! Azure Data Lake を中心としたビックデータ処理基盤のアーキテクチャと実装](https://cdn.slidesharecdn.com/ss_thumbnails/di12-170616053736-thumbnail.jpg?width=640&height=640&fit=bounds)




























