Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Takeshi Akutsu
2,200 views
S01 t3 data_engineer
Python Learning Workshop: Session 1, Talk 3, "Data Science and Data Engineer"
Technology
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Downloaded 25 times
1
/ 34
2
/ 34
3
/ 34
4
/ 34
5
/ 34
6
/ 34
7
/ 34
8
/ 34
9
/ 34
10
/ 34
11
/ 34
12
/ 34
13
/ 34
14
/ 34
15
/ 34
16
/ 34
17
/ 34
18
/ 34
19
/ 34
20
/ 34
21
/ 34
22
/ 34
23
/ 34
24
/ 34
25
/ 34
26
/ 34
27
/ 34
28
/ 34
29
/ 34
30
/ 34
31
/ 34
32
/ 34
33
/ 34
34
/ 34
More Related Content
PDF
避けては通れないビッグデータ周辺の重要課題
by
kurikiyo
PDF
データ分析を支える技術 DWH再入門
by
Satoru Ishikawa
PDF
データウェアハウスモデリング入門(ダイジェスト版)(事前公開版)
by
Satoshi Nagayasu
PPTX
大規模分散システムの現在 -- GFS, MapReduce, BigTableはどう変化したか?
by
maruyama097
PPTX
Hadoop / Elastic MapReduceつまみ食い
by
Ryuji Tamagawa
PDF
世界一簡単なHadoopの話
by
Koichi Shimazaki
PDF
データ分析を支える技術 データ分析基盤再入門
by
Satoru Ishikawa
KEY
Strata conference 2012
by
Junya Yamaguchi
避けては通れないビッグデータ周辺の重要課題
by
kurikiyo
データ分析を支える技術 DWH再入門
by
Satoru Ishikawa
データウェアハウスモデリング入門(ダイジェスト版)(事前公開版)
by
Satoshi Nagayasu
大規模分散システムの現在 -- GFS, MapReduce, BigTableはどう変化したか?
by
maruyama097
Hadoop / Elastic MapReduceつまみ食い
by
Ryuji Tamagawa
世界一簡単なHadoopの話
by
Koichi Shimazaki
データ分析を支える技術 データ分析基盤再入門
by
Satoru Ishikawa
Strata conference 2012
by
Junya Yamaguchi
What's hot
PDF
初めてのデータ分析基盤構築をまかされた、その時何を考えておくと良いのか
by
Techon Organization
PDF
大規模サイトを支えるビッグデータプラットフォーム技術
by
Yahoo!デベロッパーネットワーク
PDF
ビッグデータとデータマート
by
株式会社オプト 仙台ラボラトリ
PDF
Smart data integration to hybrid data analysis infrastructure
by
DataWorks Summit
PDF
並列データベースシステムの概念と原理
by
Makoto Yui
PDF
Hadoop 基礎
by
hideaki honda
PDF
現場の”今”を知る、これからのビッグデータ分析・活用のすすめ
by
yuji suzuki
PDF
データマネジメント2014
by
Talend KK
PDF
ビックデータ分析基盤の成⻑の軌跡
by
Recruit Lifestyle Co., Ltd.
PDF
Hadoop Conference Japan 2013 Winter オープニングスライド
by
hamaken
PDF
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
PPTX
Use case and Live demo : Agile data integration from Legacy system to Hadoop ...
by
DataWorks Summit/Hadoop Summit
PDF
データ分析基盤について
by
Yuta Inamura
PDF
第一回IoT関連技術勉強会 分散処理編
by
tzm_freedom
PDF
ビジネスへの本格活用が始まったHadoopの今 ~MapRが選ばれる理由~ - ビッグデータEXPO東京 2014/02/26
by
MapR Technologies Japan
PDF
リクルートのビッグデータ活用基盤とビッグデータ活用のためのメタデータ管理Webのご紹介
by
Recruit Technologies
PDF
Apache Hadoopを利用したビッグデータ分析基盤
by
Hortonworks Japan
PDF
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
PDF
マップアールが考える企業システムにおける分析プラットフォームの進化 - 2014/06/27 Data Scientist Summit 2014
by
MapR Technologies Japan
PPTX
リクルートライフスタイルの考える ストリームデータの活かし方(Hadoop Spark Conference2016)
by
Atsushi Kurumada
初めてのデータ分析基盤構築をまかされた、その時何を考えておくと良いのか
by
Techon Organization
大規模サイトを支えるビッグデータプラットフォーム技術
by
Yahoo!デベロッパーネットワーク
ビッグデータとデータマート
by
株式会社オプト 仙台ラボラトリ
Smart data integration to hybrid data analysis infrastructure
by
DataWorks Summit
並列データベースシステムの概念と原理
by
Makoto Yui
Hadoop 基礎
by
hideaki honda
現場の”今”を知る、これからのビッグデータ分析・活用のすすめ
by
yuji suzuki
データマネジメント2014
by
Talend KK
ビックデータ分析基盤の成⻑の軌跡
by
Recruit Lifestyle Co., Ltd.
Hadoop Conference Japan 2013 Winter オープニングスライド
by
hamaken
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
Use case and Live demo : Agile data integration from Legacy system to Hadoop ...
by
DataWorks Summit/Hadoop Summit
データ分析基盤について
by
Yuta Inamura
第一回IoT関連技術勉強会 分散処理編
by
tzm_freedom
ビジネスへの本格活用が始まったHadoopの今 ~MapRが選ばれる理由~ - ビッグデータEXPO東京 2014/02/26
by
MapR Technologies Japan
リクルートのビッグデータ活用基盤とビッグデータ活用のためのメタデータ管理Webのご紹介
by
Recruit Technologies
Apache Hadoopを利用したビッグデータ分析基盤
by
Hortonworks Japan
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
マップアールが考える企業システムにおける分析プラットフォームの進化 - 2014/06/27 Data Scientist Summit 2014
by
MapR Technologies Japan
リクルートライフスタイルの考える ストリームデータの活かし方(Hadoop Spark Conference2016)
by
Atsushi Kurumada
Similar to S01 t3 data_engineer
PDF
データサイエンスとデータエンジニア
by
nagix
PDF
Data Science on Hadoop
by
Yifeng Jiang
PDF
Open Cloud Innovation2016 day1(これからのデータ分析者とエンジニアに必要なdatascienceexperienceツールと...
by
Atsushi Tsuchiya
PPTX
1028 TECH & BRIDGE MEETING
by
健司 亀本
PDF
tut_pfi_2012
by
Preferred Networks
PDF
ビッグデータエコシステムとデータサイエンスのススメ
by
Yuki Asano
PDF
SparkMLlibで始めるビッグデータを対象とした機械学習入門
by
Takeshi Mikami
PDF
[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop
by
Insight Technology, Inc.
PPT
Big data解析ビジネス
by
Mie Mori
PDF
基本から学ぶ ビッグデータ / データ分析 / 機械学習 サービス群
by
Google Cloud Platform - Japan
PPTX
Bigdata 2012 06-03
by
Daisuke Ito
PDF
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平
by
Preferred Networks
PDF
オープンセミナー岡山 これから始めるデータ活用
by
syou6162
PDF
データサイエンティストとは? そのスキル/ナレッジレベル定義の必要性
by
BrainPad Inc.
PDF
Apache Drill Overview - Tokyo Apache Drill Meetup 2015/09/15
by
MapR Technologies Japan
PPTX
データサイエンティスト協会 セミナー2016 第2回 2016年7月19日
by
Atsushi Tsuchiya
PDF
2019.03.19 Deep Dive into Spark SQL with Advanced Performance Tuning
by
Takuya UESHIN
PDF
ビッグデータ革命 クラウドがコモデティ化する「奇跡」
by
Atsushi Nakada
PDF
(道具としての)データサイエンティストのつかい方
by
Shohei Hido
PDF
ビッグデータはバズワードか? (Cloudian Summit 2012)
by
CLOUDIAN KK
データサイエンスとデータエンジニア
by
nagix
Data Science on Hadoop
by
Yifeng Jiang
Open Cloud Innovation2016 day1(これからのデータ分析者とエンジニアに必要なdatascienceexperienceツールと...
by
Atsushi Tsuchiya
1028 TECH & BRIDGE MEETING
by
健司 亀本
tut_pfi_2012
by
Preferred Networks
ビッグデータエコシステムとデータサイエンスのススメ
by
Yuki Asano
SparkMLlibで始めるビッグデータを対象とした機械学習入門
by
Takeshi Mikami
[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop
by
Insight Technology, Inc.
Big data解析ビジネス
by
Mie Mori
基本から学ぶ ビッグデータ / データ分析 / 機械学習 サービス群
by
Google Cloud Platform - Japan
Bigdata 2012 06-03
by
Daisuke Ito
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平
by
Preferred Networks
オープンセミナー岡山 これから始めるデータ活用
by
syou6162
データサイエンティストとは? そのスキル/ナレッジレベル定義の必要性
by
BrainPad Inc.
Apache Drill Overview - Tokyo Apache Drill Meetup 2015/09/15
by
MapR Technologies Japan
データサイエンティスト協会 セミナー2016 第2回 2016年7月19日
by
Atsushi Tsuchiya
2019.03.19 Deep Dive into Spark SQL with Advanced Performance Tuning
by
Takuya UESHIN
ビッグデータ革命 クラウドがコモデティ化する「奇跡」
by
Atsushi Nakada
(道具としての)データサイエンティストのつかい方
by
Shohei Hido
ビッグデータはバズワードか? (Cloudian Summit 2012)
by
CLOUDIAN KK
More from Takeshi Akutsu
PDF
みんなのPython勉強会#111 LT資料 "AIとサステナビリティについて"
by
Takeshi Akutsu
PDF
万年ビギナーによるPythonプログラミングのリハビリ計画
by
Takeshi Akutsu
PPTX
Stapyの6年~本との出会いから生まれた技術コミュニティ~
by
Takeshi Akutsu
PPTX
Start Python Club 2020年活動報告
by
Takeshi Akutsu
PPTX
みんなのPython勉強会#59 Intro
by
Takeshi Akutsu
PDF
On the Necessity and Inapplicability of Python
by
Takeshi Akutsu
PDF
Stapyユーザーガイド
by
Takeshi Akutsu
PDF
stapy_fukuoka_01_akutsu
by
Takeshi Akutsu
PDF
Python初心者が4年で5000人のコミュニティに作ったエモい話
by
Takeshi Akutsu
PDF
Scipy Japan 2019参加レポート
by
Takeshi Akutsu
PDF
Scipy Japan 2019の紹介
by
Takeshi Akutsu
PDF
みんなのPython勉強会 in 長野 #3, Intro
by
Takeshi Akutsu
PDF
Introduction
by
Takeshi Akutsu
PPTX
みんなのPython勉強会#35 まとめ
by
Takeshi Akutsu
PDF
モダンな独学の道。そうだ、オープンソースでいこう!
by
Takeshi Akutsu
PDF
LT_by_Takeshi
by
Takeshi Akutsu
PDF
Orientation
by
Takeshi Akutsu
PDF
Introduction
by
Takeshi Akutsu
PDF
プログラミング『超入門書』から見るPythonと解説テクニック
by
Takeshi Akutsu
PPTX
We are OSS Communities: Introduction of Start Python Club
by
Takeshi Akutsu
みんなのPython勉強会#111 LT資料 "AIとサステナビリティについて"
by
Takeshi Akutsu
万年ビギナーによるPythonプログラミングのリハビリ計画
by
Takeshi Akutsu
Stapyの6年~本との出会いから生まれた技術コミュニティ~
by
Takeshi Akutsu
Start Python Club 2020年活動報告
by
Takeshi Akutsu
みんなのPython勉強会#59 Intro
by
Takeshi Akutsu
On the Necessity and Inapplicability of Python
by
Takeshi Akutsu
Stapyユーザーガイド
by
Takeshi Akutsu
stapy_fukuoka_01_akutsu
by
Takeshi Akutsu
Python初心者が4年で5000人のコミュニティに作ったエモい話
by
Takeshi Akutsu
Scipy Japan 2019参加レポート
by
Takeshi Akutsu
Scipy Japan 2019の紹介
by
Takeshi Akutsu
みんなのPython勉強会 in 長野 #3, Intro
by
Takeshi Akutsu
Introduction
by
Takeshi Akutsu
みんなのPython勉強会#35 まとめ
by
Takeshi Akutsu
モダンな独学の道。そうだ、オープンソースでいこう!
by
Takeshi Akutsu
LT_by_Takeshi
by
Takeshi Akutsu
Orientation
by
Takeshi Akutsu
Introduction
by
Takeshi Akutsu
プログラミング『超入門書』から見るPythonと解説テクニック
by
Takeshi Akutsu
We are OSS Communities: Introduction of Start Python Club
by
Takeshi Akutsu
S01 t3 data_engineer
1.
データサイエンスと データエンジニア 草薙
昭彦 (@nagix) MapR Technologies
2.
自己紹介 • 草薙
昭彦 (@nagix) • MapR Technologies データエンジニア NS-‐SHAFT 無料!
3.
業界の話
4.
IT業界のトレンド • ビッグデータ、クラウド、IoT/M2M
• データ活用の位置付けの変化 – 分析が企業の競争力に – リアルタイムなデータそのものがビジネス価値に
5.
なぜ今データサイエンスか • 深い顧客の理解なしではビジネスは難しく なってきている
– Web、モバイル、SNS、センサーなど、顧客に関す るあらゆるデータ • 人材の不足 – 個人の勘と経験ではなく、学術として整備 – 米国の大学ではコースが充実
6.
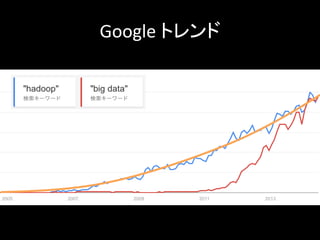
Google トレンド
7.
で、なぜ今? • なぜ大きな会社も小さな会社も?
– 巨大銀行からスタートアップまで • なぜいろいろな業界で? – 金融、Web、製造、セキュリティ、・・・ • なぜいろいろなアプリケーションで? – 広告ターゲティング、不正検知、故障予測、・・・ • なぜ同じタイミングで?
8.
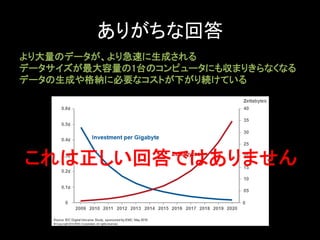
ありがちな回答 より大量のデータが、より急速に生成される データサイズが最大容量の1台のコンピュータにも収まりきらなくなる データの生成や格納に必要なコストが下がり続けている これは正しい回答ではありません
9.
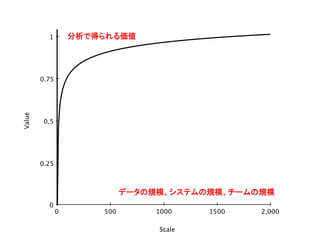
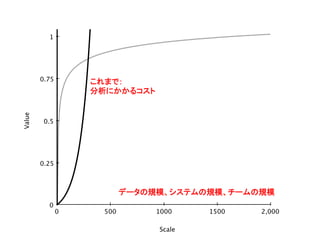
分析のスケーリングの法則 • 80:20
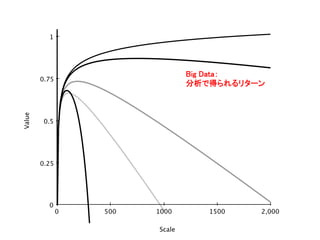
ルール – はじめはわずかな努力で大きな成果が得られる – ところが急激にリターンが減っていく • 一方、分析に必要なコストは – これまで: 規模を増やすとコストは指数関数的に 増加 – Big Data: コストの増加は直線的 • 分析のROIの構造が根本的に変わった!
10.
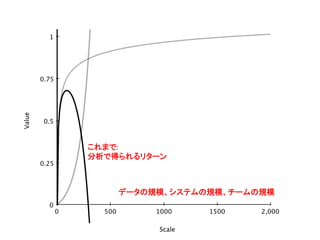
2,0000 500 1000
1500 1 0 0.25 0.5 0.75 Scale Value データの規模、システムの規模、チームの規模 分析で得られる価値
11.
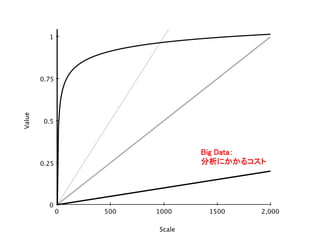
2,0000 500 1000
1500 1 0 0.25 0.5 0.75 Scale Value データの規模、システムの規模、チームの規模 これまで: 分析にかかるコスト
12.
2,0000 500 1000
1500 1 0 0.25 0.5 0.75 Scale Value データの規模、システムの規模、チームの規模 これまで: 分析で得られるリターン
13.
2,0000 500 1000
1500 1 0 0.25 0.5 0.75 Scale Value Big Data: 分析にかかるコスト
14.
2,0000 500 1000
1500 1 0 0.25 0.5 0.75 Scale Value Big Data: 分析で得られるリターン
15.
データサイエンティストって どういう職業? •
ゴール – データに価値を見いだし – データに関するストーリーを伝えること • そのために – 必要なデータを引き出し – 統計や機械学習の知識を駆使してモデルを作り – 結果を生成 – 顧客や経営層とのコミュニケーションを行う
16.
データエンジニアってどういう職業? • ゴール
– データを適切な場所に適切な形式で格納し – 利用者がアクセスできるように整備する • そのために – データ処理のニーズを明確化し – ニーズを満たすストレージ基盤を設計構築し – データフローやアクセスアプリケーションを整備 • Big Data の 3V を扱えるシステムを構築する
17.
技術の話
18.
データサイエンティストに 求められるスキル •
統計学、機械学習 – R, SPSS, SAS, Knime, Weka, RapidMiner, SciPy, … • データの整形・フィルタリング・正規化・加工 – Python, Java, Hadoop, Hive, SQL, Spark, Excel, … • 可視化、プレゼンテーション • 貼っておきます – データサイエンティストというかデータ分析職に就くための最低限のスキル要件とは hYp://tjo.hatenablog.com/entry/2015/03/13/190000 – データサイエンティスト養成読本 hYp://www.amazon.co.jp/dp/4774158968
19.
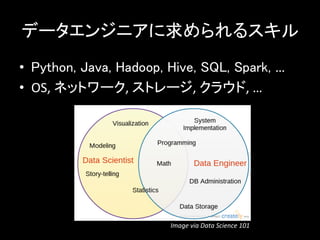
データエンジニアに求められるスキル • Python,
Java, Hadoop, Hive, SQL, Spark, … • OS, ネットワーク, ストレージ, クラウド, … Image via Data Science 101
20.
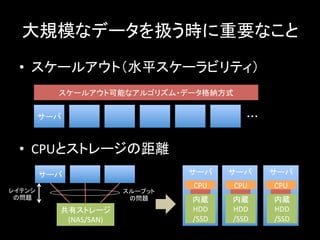
大規模なデータを扱う時に重要なこと • スケールアウト(水平スケーラビリティ)
• CPUとストレージの距離 サーバ ・・・ スケールアウト可能なアルゴリズム・データ格納方式 共有ストレージ (NAS/SAN) サーバ レイテンシ の問題 スループット の問題 サーバ サーバ サーバ 内蔵 HDD /SSD 内蔵 HDD /SSD 内蔵 HDD /SSD CPU CPU CPU
21.
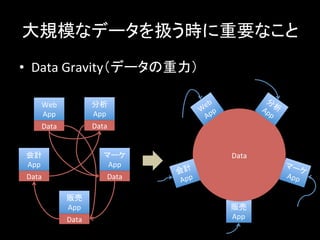
大規模なデータを扱う時に重要なこと • Data
Gravity(データの重力) Web App Data 分析 App Data 会計 App Data マーケ App Data 販売 App Data 販売 App Data 会計 App マーケ App
22.
Hadoopって? サーバ サーバ
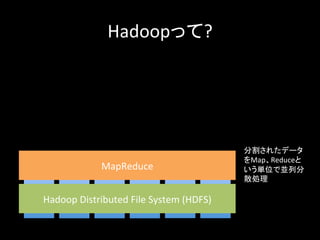
サーバ サーバ サーバ サーバ
23.
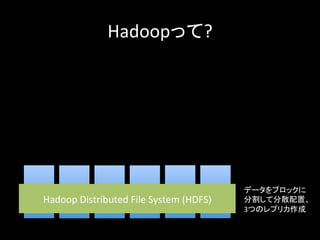
Hadoopって? サーバ Hadoop Distributed
File System (HDFS) データをブロックに 分割して分散配置、 3つのレプリカ作成
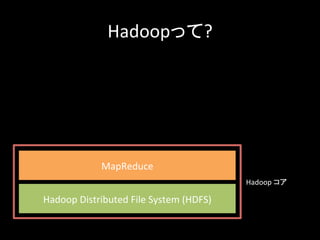
24.
Hadoopって? サーバ Hadoop Distributed
File System (HDFS) 分割されたデータ をMap、Reduceと いう単位で並列分 散処理 MapReduce
25.
Hadoopって? Hadoop Distributed
File System (HDFS) MapReduce Hadoop コア
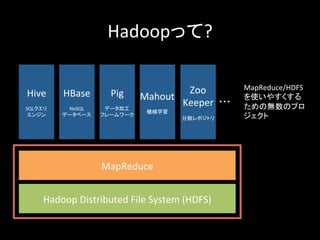
26.
Hadoopって? Hadoop Distributed
File System (HDFS) MapReduce Hive SQLクエリ エンジン HBase NoSQL データベース Pig データ加工 フレームワーク Mahout 機械学習 Zoo Keeper 分散レポジトリ ・・・ MapReduce/HDFS を使いやすくする ための無数のプロ ジェクト
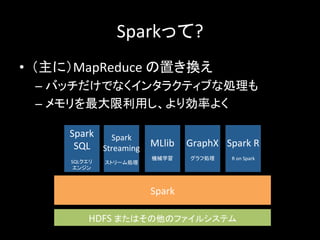
27.
Sparkって? • (主に)MapReduce
の置き換え – バッチだけでなくインタラクティブな処理も – メモリを最大限利用し、より効率よく Spark Spark SQL SQLクエリ エンジン Spark Streaming ストリーム処理 MLlib 機械学習 GraphX グラフ処理 Spark R R on Spark HDFS またはその他のファイルシステム
28.
分析と機械学習 • 従来からの分析
– 集計、レポート、見える化、ルールベース処理 • 機械学習による応用 – 予測、カテゴリ分類、レコメンド、異常検知 • データ分析のステップ 1. ビジネスとデータの理解 2. データの準備 3. モデルの作成 4. モデルの評価 5. モデルの展開
29.
Python と Hadoop/Spark
• MapReduce を Python で – mrjob, Pydoop • Pig – Jython, cpython でユーザー定義関数を書く • Hadoop を管理する – snakebite • Spark を Python で – PySpark Hadoop with Python hYp://www.slideshare.net/DonaldMiner/hadoop-‐with-‐python
30.
ビジネスの話
31.
よくある悩み • どこにデータがあるか分からない
• 効果がわからないものに予算がつかない • 分析のスキルが足りない • 分析はできてもビジネスに結びつかない
32.
ビジネスに分析を生かしている企業 hYp://itpro.nikkeibp.co.jp/atcl/column/ 14/122600137/122600002/
「我々の仕事は、対話(アナログ)と データ分析(デジタル)の比率がそれ ぞれ50%ずつ。これが理想」 花王・石黒勲氏 hYp://special.nikkeibp.co.jp/ts/aricle/ae0d/ 180043/ 「スキルが高いデータサイエンティストよ り問題解決ができる人材」「高度な分析 技術はまず要らない」 リコー・佐藤敏明氏
33.
分析をビジネスに活用するために 重要なこと •
分析の8割は基本的なスキルでカバーできる • 分析には業務知識が必須 • 「データを中心に考える」文化の醸成 • ステップを踏んで少しずつ成果を出す • コミュニケーション
34.
ありがとうございました
Download






















































![[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop](https://cdn.slidesharecdn.com/ss_thumbnails/insightout2011b21part2nosqlhadoop-111114020909-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)































