Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Tetsutaro Watanabe
PPTX, PDF
37,173 views
MongoDBが遅いときの切り分け方法
MMAPv1, WiredTigerについても詳細に説明しています
Technology
◦
Read more
18
Save
Share
Embed
Embed presentation
Download
Downloaded 141 times
1
/ 46
2
/ 46
3
/ 46
4
/ 46
5
/ 46
6
/ 46
7
/ 46
8
/ 46
9
/ 46
10
/ 46
11
/ 46
12
/ 46
13
/ 46
14
/ 46
15
/ 46
16
/ 46
17
/ 46
18
/ 46
Most read
19
/ 46
20
/ 46
21
/ 46
22
/ 46
23
/ 46
24
/ 46
25
/ 46
26
/ 46
27
/ 46
28
/ 46
29
/ 46
30
/ 46
31
/ 46
32
/ 46
33
/ 46
34
/ 46
Most read
35
/ 46
36
/ 46
37
/ 46
38
/ 46
39
/ 46
40
/ 46
41
/ 46
42
/ 46
43
/ 46
44
/ 46
45
/ 46
46
/ 46
Most read
More Related Content
PPTX
初心者向けMongoDBのキホン!
by
Tetsutaro Watanabe
PDF
Serverless時代のJavaについて
by
Amazon Web Services Japan
PDF
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
PDF
マルチテナントのアプリケーション実装〜実践編〜
by
Yoshiki Nakagawa
PDF
AWS Black Belt Online Seminar 2018 Amazon DynamoDB Advanced Design Pattern
by
Amazon Web Services Japan
PDF
Google Cloud で実践する SRE
by
Google Cloud Platform - Japan
PDF
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
PPTX
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
初心者向けMongoDBのキホン!
by
Tetsutaro Watanabe
Serverless時代のJavaについて
by
Amazon Web Services Japan
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
マルチテナントのアプリケーション実装〜実践編〜
by
Yoshiki Nakagawa
AWS Black Belt Online Seminar 2018 Amazon DynamoDB Advanced Design Pattern
by
Amazon Web Services Japan
Google Cloud で実践する SRE
by
Google Cloud Platform - Japan
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
What's hot
PDF
Docker Compose 徹底解説
by
Masahito Zembutsu
PDF
webエンジニアのためのはじめてのredis
by
nasa9084
PDF
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
by
Recruit Technologies
PDF
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
PPTX
WiredTigerを詳しく説明
by
Tetsutaro Watanabe
PPTX
モノリスからマイクロサービスへの移行 ~ストラングラーパターンの検証~(Spring Fest 2020講演資料)
by
NTT DATA Technology & Innovation
PDF
Javaのログ出力: 道具と考え方
by
Taku Miyakawa
PDF
SQLアンチパターン 幻の第26章「とりあえず削除フラグ」
by
Takuto Wada
PDF
ツール比較しながら語る O/RマッパーとDBマイグレーションの実際のところ
by
Y Watanabe
PPTX
MongoDBの監視
by
Tetsutaro Watanabe
PPTX
今こそ知りたいSpring Batch(Spring Fest 2020講演資料)
by
NTT DATA Technology & Innovation
PPTX
SPAセキュリティ入門~PHP Conference Japan 2021
by
Hiroshi Tokumaru
PDF
ソーシャルゲーム案件におけるDB分割のPHP実装
by
infinite_loop
PDF
SQL大量発行処理をいかにして高速化するか
by
Shogo Wakayama
PDF
TLS, HTTP/2演習
by
shigeki_ohtsu
PDF
例外設計における大罪
by
Takuto Wada
PDF
Linux女子部 systemd徹底入門
by
Etsuji Nakai
PDF
REST API のコツ
by
pospome
PDF
マイクロにしすぎた結果がこれだよ!
by
mosa siru
PDF
Amazon Redshift パフォーマンスチューニングテクニックと最新アップデート
by
Amazon Web Services Japan
Docker Compose 徹底解説
by
Masahito Zembutsu
webエンジニアのためのはじめてのredis
by
nasa9084
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
by
Recruit Technologies
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
WiredTigerを詳しく説明
by
Tetsutaro Watanabe
モノリスからマイクロサービスへの移行 ~ストラングラーパターンの検証~(Spring Fest 2020講演資料)
by
NTT DATA Technology & Innovation
Javaのログ出力: 道具と考え方
by
Taku Miyakawa
SQLアンチパターン 幻の第26章「とりあえず削除フラグ」
by
Takuto Wada
ツール比較しながら語る O/RマッパーとDBマイグレーションの実際のところ
by
Y Watanabe
MongoDBの監視
by
Tetsutaro Watanabe
今こそ知りたいSpring Batch(Spring Fest 2020講演資料)
by
NTT DATA Technology & Innovation
SPAセキュリティ入門~PHP Conference Japan 2021
by
Hiroshi Tokumaru
ソーシャルゲーム案件におけるDB分割のPHP実装
by
infinite_loop
SQL大量発行処理をいかにして高速化するか
by
Shogo Wakayama
TLS, HTTP/2演習
by
shigeki_ohtsu
例外設計における大罪
by
Takuto Wada
Linux女子部 systemd徹底入門
by
Etsuji Nakai
REST API のコツ
by
pospome
マイクロにしすぎた結果がこれだよ!
by
mosa siru
Amazon Redshift パフォーマンスチューニングテクニックと最新アップデート
by
Amazon Web Services Japan
Viewers also liked
PDF
WiredTigerストレージエンジン楽しい
by
Akihiro Kuwano
PDF
20110514 mongo dbチューニング
by
Yuichi Matsuo
KEY
MongoDBを使用したモバイルゲーム開発
by
Genki Yamada
PPTX
QAアーキテクチャの設計による 説明責任の高いテスト・品質保証
by
Yasuharu Nishi
PDF
MongoDBのアレをアレする
by
Akihiro Kuwano
PDF
MongoDB全機能解説1
by
Takahiro Inoue
WiredTigerストレージエンジン楽しい
by
Akihiro Kuwano
20110514 mongo dbチューニング
by
Yuichi Matsuo
MongoDBを使用したモバイルゲーム開発
by
Genki Yamada
QAアーキテクチャの設計による 説明責任の高いテスト・品質保証
by
Yasuharu Nishi
MongoDBのアレをアレする
by
Akihiro Kuwano
MongoDB全機能解説1
by
Takahiro Inoue
Similar to MongoDBが遅いときの切り分け方法
PDF
はじめてのMongoDB
by
Keisuke Izumiya
PDF
MongoDB勉強会資料
by
Hiromune Shishido
PPT
Mongodb
by
Satoru Mikami
PPT
MongoDB
by
あしたのオープンソース研究所
PPTX
MongoDB: システム可用性を拡張するインデクス戦略
by
ippei_suzuki
PDF
月間10億pvを支えるmongo db
by
Yuji Isobe
PDF
データベース勉強会 In 広島 mongodb
by
Ryuji Tamagawa
PDF
Introduction to MongoDB
by
moai kids
PDF
CasualなMongoDBのサービス運用Tips
by
Naoki Sega
PDF
大規模化するピグライフを支えるインフラ ~MongoDBとChefについて~ (前編)
by
Akihiro Kuwano
PPTX
Mongo dbを知ろう
by
CROOZ, inc.
PDF
DB tech showcase: 噂のMongoDBその用途は?
by
Hiroaki Kubota
DOC
20110301 Mongo Tokyo
by
Kenichi Masuda
DOC
20110302 Mongo Tokyo
by
Kenichi Masuda
PDF
MongoDB社の製品紹介 2019-MongoDB EA&Atlas
by
昌桓 李
PPTX
Mongodb World 2014
by
Yoshihiro Iwanaga
PDF
MongoDBとAjaxで作る解析フロントエンド&GraphDBを用いたソーシャルデータ解析
by
Takahiro Inoue
PDF
MongoDBの脆弱性診断 - smarttechgeeks
by
tobaru_yuta
PPTX
日本語:Mongo dbに於けるシャーディングについて
by
ippei_suzuki
PDF
後悔しないもんごもんごの使い方 〜アプリ編〜
by
Masakazu Matsushita
はじめてのMongoDB
by
Keisuke Izumiya
MongoDB勉強会資料
by
Hiromune Shishido
Mongodb
by
Satoru Mikami
MongoDB
by
あしたのオープンソース研究所
MongoDB: システム可用性を拡張するインデクス戦略
by
ippei_suzuki
月間10億pvを支えるmongo db
by
Yuji Isobe
データベース勉強会 In 広島 mongodb
by
Ryuji Tamagawa
Introduction to MongoDB
by
moai kids
CasualなMongoDBのサービス運用Tips
by
Naoki Sega
大規模化するピグライフを支えるインフラ ~MongoDBとChefについて~ (前編)
by
Akihiro Kuwano
Mongo dbを知ろう
by
CROOZ, inc.
DB tech showcase: 噂のMongoDBその用途は?
by
Hiroaki Kubota
20110301 Mongo Tokyo
by
Kenichi Masuda
20110302 Mongo Tokyo
by
Kenichi Masuda
MongoDB社の製品紹介 2019-MongoDB EA&Atlas
by
昌桓 李
Mongodb World 2014
by
Yoshihiro Iwanaga
MongoDBとAjaxで作る解析フロントエンド&GraphDBを用いたソーシャルデータ解析
by
Takahiro Inoue
MongoDBの脆弱性診断 - smarttechgeeks
by
tobaru_yuta
日本語:Mongo dbに於けるシャーディングについて
by
ippei_suzuki
後悔しないもんごもんごの使い方 〜アプリ編〜
by
Masakazu Matsushita
More from Tetsutaro Watanabe
PPTX
データサイエンティスト向け性能問題対応の基礎
by
Tetsutaro Watanabe
PPTX
MLOpsはバズワード
by
Tetsutaro Watanabe
PPTX
ドライブレコーダの動画を使った道路情報の自動差分抽出
by
Tetsutaro Watanabe
PPTX
IoTデバイスデータ収集の難しい点
by
Tetsutaro Watanabe
PPTX
ドライブレコーダの画像認識による道路情報の自動差分抽出
by
Tetsutaro Watanabe
PPTX
先駆者に学ぶ MLOpsの実際
by
Tetsutaro Watanabe
PPTX
データ収集の基本と「JapanTaxi」アプリにおける実践例
by
Tetsutaro Watanabe
PPTX
ML Ops NYC 19 & Strata Data Conference 2019 NewYork 注目セッションまとめ
by
Tetsutaro Watanabe
PPTX
タクシードライブレコーダーの動画処理MLパイプラインにkubernetesを使ってみた
by
Tetsutaro Watanabe
PPTX
JapanTaxiにおけるSagemaker+αによる機械学習アプリケーションの本番運用
by
Tetsutaro Watanabe
PPTX
JapanTaxiにおけるML Ops 〜機械学習の開発運用プロセス〜
by
Tetsutaro Watanabe
PPTX
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
PPTX
Google Cloud Next '18 Recap/報告会 機械学習関連
by
Tetsutaro Watanabe
PPTX
巨大なサービスと膨大なデータを支えるプラットフォーム
by
Tetsutaro Watanabe
PPTX
リクルートを支える横断データ基盤と機械学習の適用事例
by
Tetsutaro Watanabe
PPTX
ビッグデータ処理データベースの全体像と使い分け - 2017年 Version -
by
Tetsutaro Watanabe
PPTX
リクルートテクノロジーズ における EMR の活用とコスト圧縮方法
by
Tetsutaro Watanabe
PPTX
ビックデータ処理技術の全体像とリクルートでの使い分け
by
Tetsutaro Watanabe
PPTX
MongoDB3.2の紹介
by
Tetsutaro Watanabe
PPTX
MongoDB World 2014に行ってきた!
by
Tetsutaro Watanabe
データサイエンティスト向け性能問題対応の基礎
by
Tetsutaro Watanabe
MLOpsはバズワード
by
Tetsutaro Watanabe
ドライブレコーダの動画を使った道路情報の自動差分抽出
by
Tetsutaro Watanabe
IoTデバイスデータ収集の難しい点
by
Tetsutaro Watanabe
ドライブレコーダの画像認識による道路情報の自動差分抽出
by
Tetsutaro Watanabe
先駆者に学ぶ MLOpsの実際
by
Tetsutaro Watanabe
データ収集の基本と「JapanTaxi」アプリにおける実践例
by
Tetsutaro Watanabe
ML Ops NYC 19 & Strata Data Conference 2019 NewYork 注目セッションまとめ
by
Tetsutaro Watanabe
タクシードライブレコーダーの動画処理MLパイプラインにkubernetesを使ってみた
by
Tetsutaro Watanabe
JapanTaxiにおけるSagemaker+αによる機械学習アプリケーションの本番運用
by
Tetsutaro Watanabe
JapanTaxiにおけるML Ops 〜機械学習の開発運用プロセス〜
by
Tetsutaro Watanabe
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
Google Cloud Next '18 Recap/報告会 機械学習関連
by
Tetsutaro Watanabe
巨大なサービスと膨大なデータを支えるプラットフォーム
by
Tetsutaro Watanabe
リクルートを支える横断データ基盤と機械学習の適用事例
by
Tetsutaro Watanabe
ビッグデータ処理データベースの全体像と使い分け - 2017年 Version -
by
Tetsutaro Watanabe
リクルートテクノロジーズ における EMR の活用とコスト圧縮方法
by
Tetsutaro Watanabe
ビックデータ処理技術の全体像とリクルートでの使い分け
by
Tetsutaro Watanabe
MongoDB3.2の紹介
by
Tetsutaro Watanabe
MongoDB World 2014に行ってきた!
by
Tetsutaro Watanabe
MongoDBが遅いときの切り分け方法
1.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved MongoDBが遅いときの切り分け方法 コンサルタント 渡部 徹太郎 1
2.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 自己紹介 2 {"ID" :"fetaro" "名前":"渡部 徹太郎" "研究":"東京工業大学でデータベースと情報検索の研究 (@日本データベース学会)" "仕事":{前職:["証券会社のオンライントレードシステムのWeb基盤", "オープンソースなら何でも。主にMongoDB,NoSQL"], 現職:["大手Web企業の横断分析基盤,Exadata,Hortonworks,EMR"] 副業:["MongoDBコンサルタント" ]} "エディタ":"emacs派", "趣味": ["自宅サーバ","麻雀"] }
3.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved はじめに MongoDBは速い? • MongoDBはNoSQLだからRDBより速い? • シャーディングすれば単体構成より速い? 3
4.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved はじめに MongoDBは速い?→ケースに依る • MongoDBはNoSQLだからRDBより速い わけではない – RDBとは提供している機能が違う • トランザクション、JOIN、副問合せ等のRDBで遅くなりがちな 複雑なクエリはMongoDBは提供していない • データモデルが違う、保証する整合性が違う – シンプルなクエリであればRDBとMongoDBでそれほど差はな い • MongoDBはオーバーヘッドが少ない分速いが • 結局はディスクIOをどれだけ減らせるか • シャーディングすれば単体構成より速い とは限らない – ボトルネックが分散するようにシャーディングを組まないとい けない – データだけ分散しても駄目。クエリの分散まで考える必要あり – クエリが分散してもボトルネックが解消しないと駄目。 • 例)ネットワークネックならばIOが減っても意味なし 4
5.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved はじめに MongoDBを速くしたければRDBを勉強すべき • MongoDBだから特別なことはほとんどない • MongoDBはRDBに似ている – CassandraやDynamoDB 等はRDBと大きく違う • 8割はRDBのパフォーマンスチューニングの知識でカバーで きる – インデックス、クエリ最適化、キャッシュ、データ圧縮、WAL、 リードレプリカ、パーティショニング • 残り2割はMongoDB特有 – データ構造(JSON)が性能に与える影響 – シャーディング 今回の発表は、RDBにも通用する一般的な話が多いです 5
6.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved アジェンダ • 性能問題との向き合い方 • 解くべき問題の明確化 • 根本原因の特定 • IOボトルネックの解消 – MMAPv1の場合 – WiredTigerの場合 6
7.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 性能問題との向き合い方 7
8.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 性能問題を考える場合の思考順序 1. 解くべき問題の明確化 – 本当にMongoDBが遅いのか? • アプリやネットワークに問題はないか – どのクエリが遅いのか? • 読み込み, 書き込み, 集計 – 何を改善したいのか(性能要件の明確化) • レスポンスタイム,スループット 2. 根本原因の特定 – リソースが枯渇しているのか? • CPU, メモリ/ディスク, NW帯域 – 非効率な処理をしていないか? • ロック開放待ち、フェッチ、NWラウンドトリップ 3. 根本原因の解消 – リソース枯渇の場合 1. 単体構成の性能を最大限まで上げる→ 8割これでいける! 2. リードレプリカ→おまけ 3. シャーディング→最後の手段 – 処理が非効率の場合 • アプリを見直す 8
9.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 性能問題調査でよくある間違い • よくある勘違い – CPU使用率が高すぎることが原因だ! • →いいことです – メモリ使用率が高すぎることが原因だ! • →溢れてIOが発生していなければ、いいことです • 全てのリソースを最大限まで使えたら完璧なチューニング • つまり – CPU使用率100% – メモリ使用率100% – ディスクI/O使用率100% – NW使用率100% を同時に見対している状態 9 考え方の整理はこの本がおすすめ
10.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 解くべき問題の明確化 10
11.
Copyright ⓒ2016 CREATIONLINE,
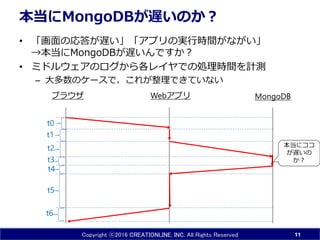
INC. All Rights Reserved 本当にMongoDBが遅いのか? • 「画面の応答が遅い」「アプリの実行時間がながい」 →本当にMongoDBが遅いんですか? • ミドルウェアのログから各レイヤでの処理時間を計測 – 大多数のケースで、これが整理できていない 11 ブラウザ Webアプリ MongoDB t0 t1 t2 t3 t4 t5 t6 本当にココ が遅いの か?
12.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved MongoDBの何が遅いのか • 何のクエリが遅いのか? – 読み取り、書き込み、集計 – 可能であればクエリを特定する • 何の指標が遅いのか? – レスポンスタイムが遅い • スロークエリログを見てクエリ応答時間をみる • プロファイラを有効にしてクエリの情報を見る – スループットが低い • mongostatを見て、単位時間あたりの処理量をみる • mongotopを見て、コレクションごとの処理量をみる 12
13.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 遅い箇所の調べ方 • スロークエリログ – 設定ファイルで起動前に指定する – デフォルトで100msを超えるクエリは、ログに出力される • プロファイラ – 起動後にMongoShellなどで接続して一時的にプロファイラを有効 にする 13 2015-07-10T04:09:01.113+0900 I COMMAND [conn1] command test.$cmd command: insert { insert: "mycol", documents: [ { _id: ObjectId('559ec6cd959e8f181ae68153'), name: "watanabe" } ], ordered: true } keyUpdates:0 writeConflicts:0 numYields:0 reslen:40 locks:{ Global: { acquireCount: { r: 2, w: 2 } }, Database: { acquireCount: { w: 2 } }, Collection: { acquireCount: { w: 2 } } } 120ms #プロファイラを有効にする > db.setProfilingLevel(1) { "was" : 0, "slowms" : 100, "ok" : 1 } #中身を見る > db.system.profile.find()
14.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 遅い箇所の調べ方 • mongostatコマンド • mongotopコマンド 14 $./bin/mongostat connected to: 127.0.0.1 insert query update delete getmore command flushes mapped vsize res ... 40 *0 *0 *0 0 1|0 1 12g 24.4g 51m ... 30 *0 *0 *0 0 1|0 0 12g 24.4g 52m ... 32 *0 *0 *0 0 1|0 0 12g 24.4g 53m ... $ ./bin/mongotop ns total read write 2015-07-10T04:56:52+09:00 mydb.mycol 6ms 6ms 0ms admin.system.roles 0ms 0ms 0ms admin.system.version 0ms 0ms 0ms ns total read write 2015-07-10T04:56:53+09:00 mydb.mycol 44ms 44ms 0ms admin.system.roles 0ms 0ms 0ms admin.system.version 0ms 0ms 0ms
15.
Copyright ⓒ2016 CREATIONLINE,
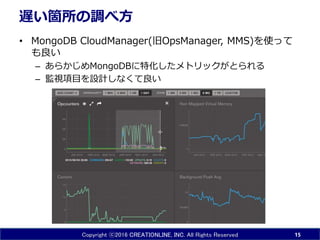
INC. All Rights Reserved 遅い箇所の調べ方 • MongoDB CloudManager(旧OpsManager, MMS)を使って も良い – あらかじめMongoDBに特化したメトリックがとられる – 監視項目を設計しなくて良い 15
16.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 根本原因の特定 16
17.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 根本原因の特定 • 結論は2種類 – ボトルネックが有る or – ボトルネックが無い • ボトルネックが有る – CPU 1core張り付き、高ロードアベレージ→1.CPUボトルネック – メモリ空き容量0、ディスクIO頻発→2.IOボトルネック – ネットワーク流量 逼迫(80%超え) →3.NWボトルネック • ボトルネックがない – MongoDBに本気を出させることが出来ていない→4.処理の非効率 17
18.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 根本原因の特定 1.CPUボトルネック • 概要 – Aggregationや算術演算で、CPUを使う処理が多い場合にボトルネックになるこ とがある。 – CPUボトルネックはIOやネットワークにボトルネックがない場合がおおいため、 どちらかといえば健全な状態。 • チェック方法 – 1コアに注目したとき、使用率のuserとsysの合計が100%になっていないか • 全体のCPU使用率50%、25%、12.5%は要注意 – 50%→2core中1つが100% – 25%→4core中1つが100% – 12.5%→8core中1つが100% • 例 ) $ dstat -c -C 0,1,2,3,total – ロードアベレージはコア数以上になっていないか • 解消方法 – 応答性能向上 • マルチスレッドで動作する演算ならばコア数を上げる • そうでないならCPUクロック数を上げる – スループット向上 • コア数を上げる 18
19.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 根本原因の特定 2.ネットワークボトルネック • 概要 – アプリケーションに対してMongoDBが大量のデータを返す場合に 多い。 – 他には、レプリケーションのoplog転送量が想定以上に肥大化し、 ネットワークを圧迫している場合もある • チェック方法 – mongostatやOSのdstatコマンドにより、ネットワークの流量を監 視し、ネットワークのキャパシティ(1Gbit, 10GBit等)に対して流 れている流量が限界に達していないか? – 1Gbit/sの設定であれば800Mbit/sあたりで限界 • 解消方法 – ネットワークを太くする – 射影してアプリケーションで受け取るデータを減らす – oplogが肥大化が原因の場合は、肥大化を引き起こすオペレーショ ンに注意する • multi updateやremove、配列の$popや$pullなど 詳細は https://enterprisezine.jp/dbonline/detail/8095 19
20.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 根本原因の特定 3.IOボトルネック • 概要 – メモリ上にデータがなく、ディスクにデータを読みに行くことが頻発 すると、ディスクはメモリに対して100倍程度遅いため、全体として処 理速度が低下する。 – MongoDB(というかDB全般)では大半がこのケース • チェック方法 – OSのiostatコマンドで、 avgqusz, await, %util が高い。 rMB/s、 wMB/sがいつもより多い。CPUのiowaitが多い – キャッシュが溢れている • MMAPv1の場合、mongostatのページフォルトが多い • WiredTigerの場合、キャッシュへの読み込み累積値(bytes read into cache)が物理メモリ量を超えて増え続けている • 解消方法 – 次ページで説明 20
21.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 根本原因の特定 3.IOボトルネック - 解消方法 1. インデックス – RDBと同じB-Treeでインデックスがあるので、同じ考え方でインデックスを設 計すれば良い – 実行計画の見方 • db.mycol.find().explain() →実行はしないで計画を表示 • db.mycol.find().explain("executionStats") →実際に実行する 2. メモリキャッシュ – メモリを駆使してIOボトルネックを解消するには MongoDBのアーキテクチャの理解が必須 – ストレージエンジンによって全く違う • MMAPv1 : メモリ管理をOSまかせ • WiredTiger : MongoDBが買収した最先端のストレージ – →後半でガッツリ説明 21
22.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 根本原因の特定 4. 処理の非効率 • 書き込みが遅い – ロック開放待ちになっている(MMAP限定) – バッチインサートしていない – Write Concernの値が必要以上に大きい – WiredTigerの場合は同時に実行できるクエリ数にそれぞれ128 の制限(Ticketsという)があり、それに引っかかっていないか • db.serverStatus().wiredTiger.concurrentTransactions • 読み込みが遅い – フェッチが細かすぎる – 同時実行 – 同時実行クエリ数制限 22
23.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved IOボトルネックの解消 MMAPv1の場合 23
24.
Copyright ⓒ2016 CREATIONLINE,
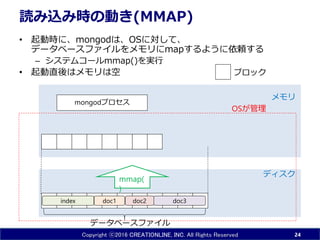
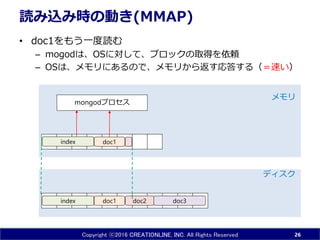
INC. All Rights Reserved 読み込み時の動き(MMAP) • 起動時に、mongodは、OSに対して、 データベースファイルをメモリにmapするように依頼する – システムコールmmap()を実行 • 起動直後はメモリは空 24 doc1 doc3index doc2 ディスク メモリ mongodプロセス OSが管理 ブロック データベースファイル mmap( )
25.
Copyright ⓒ2016 CREATIONLINE,
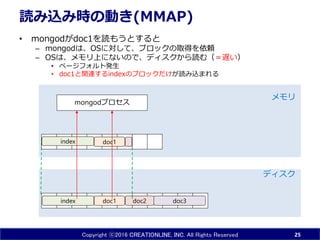
INC. All Rights Reserved 読み込み時の動き(MMAP) • mongodがdoc1を読もうとすると – mongodは、OSに対して、ブロックの取得を依頼 – OSは、メモリ上にないので、ディスクから読む(=遅い) • ページフォルト発生 • doc1と関連するindexのブロックだけが読み込まれる 25 doc1 doc3index doc2 ディスク メモリ doc1 mongodプロセス index
26.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 読み込み時の動き(MMAP) • doc1をもう一度読む – mogodは、OSに対して、ブロックの取得を依頼 – OSは、メモリにあるので、メモリから返す応答する(=速い) 26 doc1 doc3index doc2 ディスク メモリ doc1 mongodプロセス index
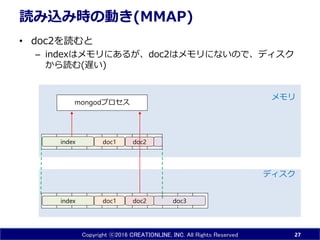
27.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 読み込み時の動き(MMAP) • doc2を読むと – indexはメモリにあるが、doc2はメモリにないので、ディスク から読む(遅い) 27 doc1 doc3index doc2 ディスク メモリ doc1 mongodプロセス doc2index
28.
Copyright ⓒ2016 CREATIONLINE,
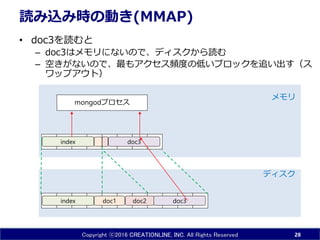
INC. All Rights Reserved 読み込み時の動き(MMAP) • doc3を読むと – doc3はメモリにないので、ディスクから読む – 空きがないので、最もアクセス頻度の低いブロックを追い出す(ス ワップアウト) 28 doc1 doc3index doc2 ディスク メモリ mongodプロセス index doc3
29.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved MMAPで、IOネックで、読み込みが遅いときの原因候補 • インデックス – インデックスが使われていない – インデックスが有効ではない • フルスキャンの方が効率が良い • hint()の利用を検討 • キャッシュ – 起動直後でキャッシュが空 – ワーキングセット(インデックスと使うデータ)がメモリに対して大す ぎる – OSにメモリの空きがなく、mongodがメモリをもらえていない – 射影してもメモリにはドキュメント全体がのるが、その動きを知らない • db.mycol.find({},{"name":1}) としてもname以外のデータもメモリに 乗る – ブロックサイズがドキュメントに対して大きすぎて無駄が多い 29 doc1 無駄
30.
Copyright ⓒ2016 CREATIONLINE,
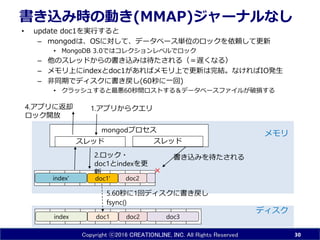
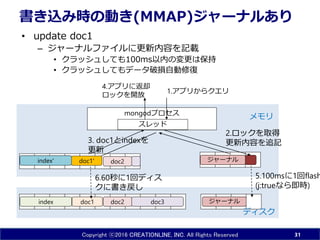
INC. All Rights Reserved 書き込み時の動き(MMAP)ジャーナルなし • update doc1を実行すると – mongodは、OSに対して、データベース単位のロックを依頼して更新 • MongoDB 3.0ではコレクションレベルでロック – 他のスレッドからの書き込みは待たされる(=遅くなる) – メモリ上にindexとdoc1があればメモリ上で更新は完結。なければIO発生 – 非同期でディスクに書き戻し(60秒に一回) • クラッシュすると最悪60秒間ロストする&データベースファイルが破損する 30 doc1 doc3index doc2 ディスク メモリmongodプロセス doc2index' スレッド スレッド 書き込みを待たされる2.ロック・ doc1とindexを更 新 × 1.アプリからクエリ4.アプリに返却 ロック開放 5.60秒に1回ディスクに書き戻し fsync() doc1'
31.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 書き込み時の動き(MMAP)ジャーナルあり • update doc1 – ジャーナルファイルに更新内容を記載 • クラッシュしても100ms以内の変更は保持 • クラッシュしてもデータ破損自動修復 31 doc1 doc3index doc2 ディスク メモリmongodプロセス doc2 スレッド 2.ロックを取得 更新内容を追記 ジャーナル ジャーナル 5.100msに1回flash (j:trueなら即時) 4.アプリに返却 ロックを開放 1.アプリからクエリ 3. doc1とindexを 更新 6.60秒に1回ディス クに書き戻し doc1'index'
32.
Copyright ⓒ2016 CREATIONLINE,
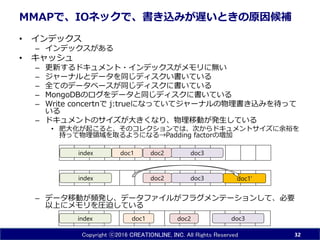
INC. All Rights Reserved MMAPで、IOネックで、書き込みが遅いときの原因候補 • インデックス – インデックスがある • キャッシュ – 更新するドキュメント・インデックスがメモリに無い – ジャーナルとデータを同じディスクい書いている – 全てのデータベースが同じディスクに書いている – MongoDBのログをデータと同じディスクに書いている – Write concertnで j:trueになっていてジャーナルの物理書き込みを待って いる – ドキュメントのサイズが大きくなり、物理移動が発生している • 肥大化が起こると、そのコレクションでは、次からドキュメントサイズに余裕を 持って物理領域を取るようになる→Padding factorの増加 – データ移動が頻発し、データファイルがフラグメンテーションして、必要 以上にメモリを利用しなくてはならない 32 doc1 doc3index doc2 doc3index doc2 doc1' doc1index doc2 doc3
33.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved IOボトルネックの解消 WiredTigerの場合 33
34.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved WiredTigerの基本 • WiredTigerとは – MongoDB,Incが買収したストレージ – MMAPv1を差し替えることができる • MMAPv1との違い – OS任せだったメモリキャッシュを、ある程度制御するようになっ た – 更新は、その場(in place)ではなく、新しいバージョンのドキュメ ントを挿入して、ポインタを張り替えようになった(MVCC,CAS) • ロックが無くなった(事実上ドキュメントレベルロックと同じ) • データファイルのフラグメンテーションがなくなった • データの肥大化による移動がなくなった • 裏で、古いバージョンをマージする動作(eviction)をするようになった • これらにより、複数スレッドでマルチコアを有効に使って、スルー プットをあげられるようになった – インデックスとデータが別ファイルになった – データの圧縮ができるようになった(メモリ量は圧縮できない) 34
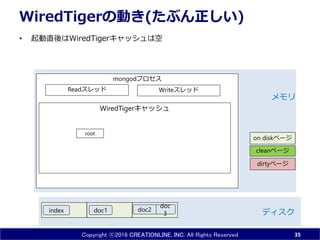
35.
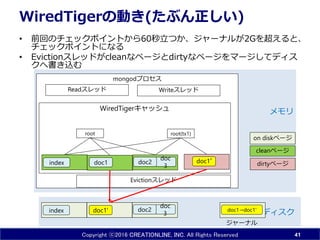
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved mongodプロセス WiredTigerキャッシュ WiredTigerの動き(たぶん正しい) • 起動直後はWiredTigerキャッシュは空 35 doc1 doc 3index ディスク メモリ doc2 Readスレッド Writeスレッド dirtyページ cleanページ on diskページ root
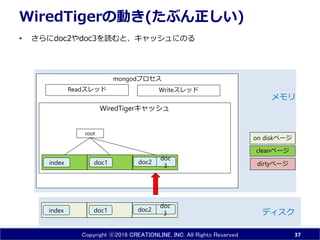
36.
Copyright ⓒ2016 CREATIONLINE,
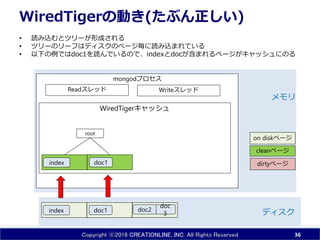
INC. All Rights Reserved mongodプロセス WiredTigerキャッシュ WiredTigerの動き(たぶん正しい) • 読み込むとツリーが形成される • ツリーのリーフはディスクのページ毎に読み込まれている • 以下の例ではdoc1を読んでいるので、indexとdocが含まれるページがキャッシュにのる 36 doc1 doc 3index ディスク メモリ doc2 Readスレッド Writeスレッド doc1index root dirtyページ cleanページ on diskページ
37.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved mongodプロセス WiredTigerキャッシュ WiredTigerの動き(たぶん正しい) • さらにdoc2やdoc3を読むと、キャッシュにのる 37 doc1 doc 3index ディスク メモリ doc2 Readスレッド Writeスレッド doc1index root doc 3 doc2 dirtyページ cleanページ on diskページ
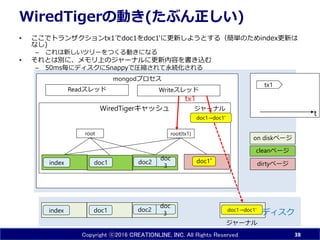
38.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved mongodプロセス WiredTigerキャッシュ WiredTigerの動き(たぶん正しい) • ここでトランザクションtx1でdoc1をdoc1'に更新しようとする (説明を簡単にするため、index更新は図から省略) – これは新しいツリーをつくる動きになる • それとは別に、メモリ上のジャーナルに更新内容を書き込む – 50ms毎にディスクにSnappyで圧縮されて永続化される 38 doc1 doc 3index ディスク メモリ doc2 Readスレッド Writeスレッド doc1index root doc 3 doc2 doc1’ root(tx1) dirtyページ cleanページ on diskページ tx1 tx1 tdoc1→doc1' ジャーナル ジャーナル doc1→doc1'
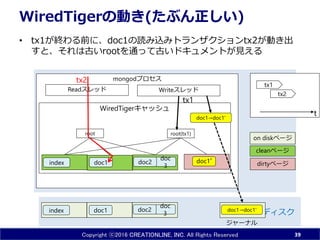
39.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved mongodプロセス WiredTigerキャッシュ WiredTigerの動き(たぶん正しい) • tx1が終わる前に、doc1の読み込みトランザクションtx2が動き出 すと、古いドキュメントが見える 39 doc1 doc 3index ディスク メモリ doc2 Readスレッド Writeスレッド doc1index root doc 3 doc2 doc1’ root(tx1) dirtyページ cleanページ on diskページ tx1 tx2 tx2 tx1 tdoc1→doc1' doc1→doc1' ジャーナル
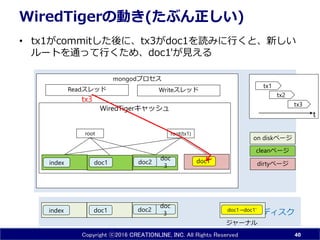
40.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved mongodプロセス WiredTigerキャッシュ WiredTigerの動き(たぶん正しい) • tx1がcommitした後に、tx3がdoc1を読みに行くと、 新しいdoc1' が見える 40 doc1 doc 3index ディスク メモリ doc2 Readスレッド Writeスレッド doc1index root doc 3 doc2 doc1’ root(tx1) dirtyページ cleanページ on diskページ tx3 tx2 tx1 tx3 t doc1→doc1' ジャーナル
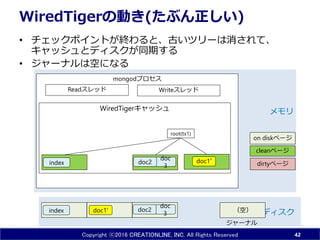
41.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved mongodプロセス WiredTigerキャッシュ WiredTigerの動き(たぶん正しい) • 前回のチェックポイントから60秒経過するか、 ジャーナルが2GBを超えると、チェックポイントになる • Evictionスレッドがcleanなページとdirtyなページをマージしてディス クへ書き込む 41 doc1' doc 3index ディスク メモリ doc2 Readスレッド Writeスレッド doc1index root doc 3 doc2 Evictionスレッド doc1’ root(tx1) dirtyページ cleanページ on diskページ doc1→doc1' ジャーナル
42.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved mongodプロセス WiredTigerキャッシュ WiredTigerの動き(たぶん正しい) • チェックポイントが終わると、古いツリーは消されて、 キャッシュとディスクが同期する • ジャーナルは空になる 42 doc1' doc 3index ディスク メモリ doc2 Readスレッド Writeスレッド index doc 3 doc2 doc1’ root(tx1) dirtyページ cleanページ on diskページ ジャーナル (空)
43.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved WiredTigerで、IOネックで、書き込みが遅いときの原因候補 • インデックス – インデックスがある • キャッシュ – 更新するドキュメント・インデックスがメモリに無い – ジャーナルとデータを同じディスクい書いている – 全てのデータベースが同じディスクに書いている – MongoDBのログをデータと同じディスクに書いている – Write concertnで j:trueになっていてジャーナルの物理書き込みを 待っている – ドキュメントのサイズが大きくなり、物理移動が発生している – データ移動が頻発し、データファイルがフラグメンテーションして、 必要以上にメモリを圧迫している 43
44.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved WiredTigerで、IOネックで、読み込みが遅いときの原因候補 • インデックス – インデックスが使われていない – インデックスが有効ではない • キャッシュ – 起動直後でキャッシュが空 – ワーキングセット(インデックスと使うデータ)がメモリに対して 大すぎる • メモリ上は圧縮されないので注意! – 射影してもメモリにはドキュメント全体がのるが、その動きを知ら ない – ブロックサイズがドキュメントに対して大きすぎて無駄が多い – OSにメモリの空きがなく、mongodがメモリをもらえていない – WiredTigerだからおそい。MMAPv1よりやることが多い。 – WiredTigerのキャッシュを割り当てすぎてファイルキャッシュに使 えない(次ページで詳細) 44
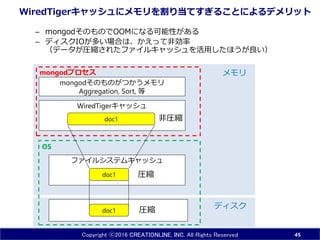
45.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved WiredTigerキャッシュにメモリを割り当てすぎることによるデメリット – mongodそのものでOOMになる可能性がある – リードが多い場合は、Wiredキャッシュよりも、データが圧縮されている ファイルキャッシュに多くのドキュメントを載せたほうが効率が良い事がある 45 mongodプロセス WiredTigerキャッシュ ディスク メモリ mongodそのものがつかうメモリ Aggregation, Sort, 等 OS OSのファイルシステムキャッシュ doc1 doc1 doc1 圧縮 圧縮 非圧縮 mongodの実メモリ 量 設定できるのは ココだけ 空きメモリから 自動的に確保 2017/2/20更新: 「MongoDBのファイルキャッシュ」は存在しないため図から削 除
46.
Copyright ⓒ2016 CREATIONLINE,
INC. All Rights Reserved 参考にした資料 • ちょっと古い公式説明資料。だいたい同じスライド – http://www.slideshare.net/mongodb/mongo-db- wiredtigerwebinar?ref=https%3A%2F%2Fwww.mongodb.co m%2Fpresentations%2Fwebinar-a-technical-introduction-to- wiredtiger – http://www.slideshare.net/NorbertoLeite/mongodb- wiredtiger-internals – https://scs.hosted.panopto.com/Panopto/Pages/Viewer.aspx ?id=9a55027f-2b6c-48f4-86f6-73cc167619d0 • 新しい公式セミナ。WiredTigerで使っている様々な工夫を詳細に 説明している。 – https://www.mongodb.com/presentations/mongodb-europe- 2016-building-wiredtiger • ブログ。WiredTigerのstatの見方や、パフォーマンスチューニング について解説している – http://www.developer.com/db/tips-for-mongodb-wiredtiger- performance-tuning.html 46
Download


![Copyright ⓒ2016 CREATIONLINE, INC. All Rights Reserved
自己紹介
2
{"ID" :"fetaro"
"名前":"渡部 徹太郎"
"研究":"東京工業大学でデータベースと情報検索の研究
(@日本データベース学会)"
"仕事":{前職:["証券会社のオンライントレードシステムのWeb基盤",
"オープンソースなら何でも。主にMongoDB,NoSQL"],
現職:["大手Web企業の横断分析基盤,Exadata,Hortonworks,EMR"]
副業:["MongoDBコンサルタント" ]}
"エディタ":"emacs派",
"趣味": ["自宅サーバ","麻雀"]
}](https://image.slidesharecdn.com/mongodb-161215011230/85/MongoDB-2-320.jpg)









![Copyright ⓒ2016 CREATIONLINE, INC. All Rights Reserved
遅い箇所の調べ方
• スロークエリログ
– 設定ファイルで起動前に指定する
– デフォルトで100msを超えるクエリは、ログに出力される
• プロファイラ
– 起動後にMongoShellなどで接続して一時的にプロファイラを有効
にする
13
2015-07-10T04:09:01.113+0900 I COMMAND [conn1] command test.$cmd command: insert
{ insert: "mycol", documents: [ { _id: ObjectId('559ec6cd959e8f181ae68153'), name:
"watanabe" } ], ordered: true } keyUpdates:0 writeConflicts:0 numYields:0
reslen:40 locks:{ Global: { acquireCount: { r: 2, w: 2 } }, Database:
{ acquireCount: { w: 2 } }, Collection: { acquireCount: { w: 2 } } } 120ms
#プロファイラを有効にする
> db.setProfilingLevel(1) { "was" : 0, "slowms" : 100, "ok" : 1 }
#中身を見る
> db.system.profile.find()](https://image.slidesharecdn.com/mongodb-161215011230/85/MongoDB-13-320.jpg)





















![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)


































































