More Related Content

PPTX
BigDataUnivercity 2017年改めてApache Sparkとデータサイエンスの関係についてのまとめ 
PPTX
ApacheSparkを中心としたOSSビッグデータ活用と導入時の検討ポイント 
PPTX

PPTX
![SparkとJupyterNotebookを使った分析処理 [Html5 conference]](https://cdn.slidesharecdn.com/ss_thumbnails/html5conference-160903045852-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
SparkとJupyterNotebookを使った分析処理 [Html5 conference] 
PPTX

PPTX

PPTX
Devsumi 2016 b_4 KafkaとSparkを組み合わせたリアルタイム分析基盤の構築 What's hot

PPTX
初めてのSpark streaming 〜kafka+sparkstreamingの紹介〜 
PDF

PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料) 
PPTX

PPTX
Pythonで入門するApache Spark at PyCon2016 
PDF

PPSX
HBaseとSparkでセンサーデータを有効活用 #hbasejp 
PDF
データ活用をもっともっと円滑に!�~データ処理・分析基盤編を少しだけ~ 
PPTX

PPTX

PDF
ビッグデータ活用を加速する!分散SQLエンジン Spark SQL のご紹介 20161105 OSC Tokyo Fall 
PDF
15.05.21_ビッグデータ分析基盤Sparkの最新動向とその活用-Spark SUMMIT EAST 2015- 
PDF
データ分析に必要なスキルをつけるためのツール~Jupyter notebook、r連携、機械学習からsparkまで~ 
PDF
Spark勉強会_ibm_20151014-公開版 
PPTX
Apache cassandraと apache sparkで作るデータ解析プラットフォーム 
PDF

PDF
SparkやBigQueryなどを用いた�モバイルゲーム分析環境 
PDF
Spark MLlibではじめるスケーラブルな機械学習 
PDF
Spark Streamingを活用したシステムの検証結果と設計時のノウハウ 
PDF
Sparkを用いたビッグデータ解析 〜 前編 〜 Viewers also liked

PDF
Data Scientist Workbench 入門 
PDF

PDF
DMM.comにおけるビッグデータ処理のためのSQL活用術 
PPTX
Oracle Labs 発! Parallel Graph AnalytiX(PGX) 
PDF
Spark graph framesとopencypherによる分散グラフ処理の最新動向 
PDF

PDF

PDF
オープンデータを活用したアプリケーション開発セミナー 
PDF

PDF
クラウド、クラウドというけれどJavaのシステムにとってクラウドってメリットあるの? 
PDF
![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ... 
PDF

PDF
![[db tech showcase Tokyo 2016] D27: Next Generation Apache Cassandra by ヤフー株式会...](https://cdn.slidesharecdn.com/ss_thumbnails/6g0l8lpr6eqa08bnwkta-signature-9b274dcdb85a5eaa42259455c2cec526dc34c97173e0294f27c0fdabde43af57-poli-160719060716-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[db tech showcase Tokyo 2016] D27: Next Generation Apache Cassandra by ヤフー株式会... 
PDF

PDF

PPT

PDF
2016-06-15 Sparkの機械学習の開発と活用の動向 
PDF
Similar to Big datauniversity

PPTX
データサイエンティスト協会 セミナー2016 第2回 2016年7月19日 
PDF
Deep Dive into Spark SQL with Advanced Performance Tuning 
PDF
Data Scientist Workbench - dots0729 
PDF

PDF
ビッグじゃなくても使えるSpark Streaming 
PPTX
JP version - Beyond Shuffling - Apache Spark のスケールアップのためのヒントとコツ 
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門 - Open Source Conference2020 Online/Fukuoka... 
PDF
2019.03.19 Deep Dive into Spark SQL with Advanced Performance Tuning 
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料) 
PDF
Spark Analytics - スケーラブルな分散処理 
PPTX
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ... 
PDF
The Future of Apache Spark 
PDF

PDF

PDF
Big Data University Tokyo Meetup #6 (mlwith_spark) 配布資料 
PDF

PPTX
G-Tech2015 Hadoop/Sparkを中核としたビッグデータ基盤_20151006 
PDF
Yifeng spark-final-public 
PDF
20190517 Spark+AI Summit2019最新レポート 
PDF
QConTokyo2015「Sparkを用いたビッグデータ解析 〜後編〜」 Big datauniversity
- 1.
© 2016 IBMCorporation
データサイエンティストのための Spark 入門
Tanaka Y.P
2016-05-14
- 2.
- 3.
© 2016 IBMCorporation3
自己紹介
田中裕一(yuichi tanaka)
主にアーキテクチャとサーバーサイドプログラムを担当
することが多い。Hadoop/Spark周りをよく触ります。
Node.js、Python、最近はSpark周りの仕事でScalaを書く
ことが多い気がします。
休日はOSS周りで遊んだり。
詳解 Apache Spark
- 4.
© 2016 IBMCorporation4
アジェンダ
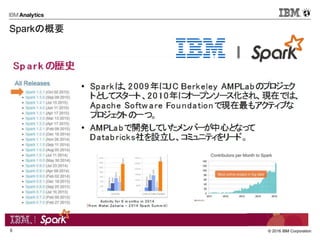
Sparkの概要
Sparkのテクノロジースタック
データサイエンスにおけるSparkの意義
分析のおさらい
なぜSparkが重要なのか
DataScientistWorkBenchでSparkRを使ってみよう
- 5.
- 6.
© 2016 IBMCorporation6
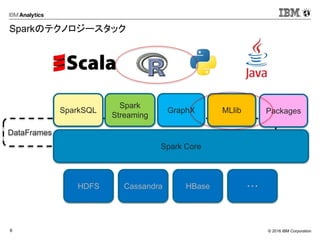
DataFrames
Sparkのテクノロジースタック
Spark Core
SparkSQL
Spark
Streaming
GraphX MLlib
HDFS Cassandra HBase ・・・
Packages
- 7.
© 2016 IBMCorporation7
Spark Mllibでサポートされるアルゴリズム
Spark MllibとSparkML
SparkMLlibはMllibとSparkmlの2つの実装に分かれている
• 現在は双方に個別の実装がなされている
• Versionによって実装状況が異なるので注意
アルゴリズムは別紙説明
- 8.
© 2016 IBMCorporation8
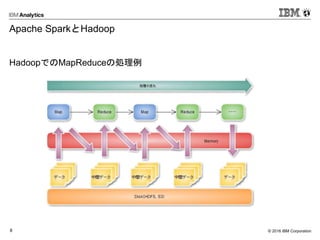
Apache SparkとHadoop
HadoopでのMapReduceの処理例
- 9.
© 2016 IBMCorporation9
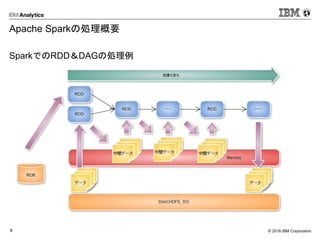
Apache Sparkの処理概要
SparkでのRDD&DAGの処理例
- 10.
© 2016 IBMCorporation10
データサイエンスにおけるSparkの意義
なぜSparkか?
Python,RのInterfaceが用意されている
• ー>DataScientistが分析に集中できる
RのDataFrameに似たインタフェース
• ー>DataFramesの考え方操作はRに類似
分散処理を意識することなく分析可能
• 大規模なデータセットを扱うことが可能 ー>Rの欠点の解決
• より高速な処理が可能
• 分散データストアとの親和性の高さ
• ー>データの場所の問題の解決
- 11.
© 2016 IBMCorporation11
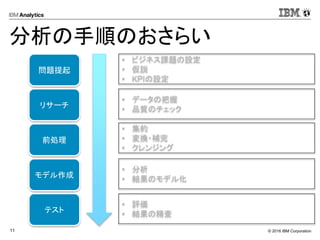
分析の手順のおさらい
問題提起
リサーチ
前処理
モデル作成
テスト
• ビジネス課題の設定
• 仮説
• KPIの設定
• データの把握
• 品質のチェック
• 集約
• 変換・補完
• クレンジング
• 分析
• 結果のモデル化
• 評価
• 結果の精査
- 12.
© 2016 IBMCorporation12
Sparkがなぜ重要なのか?
実業務において解析に使えるデータがそのまま格納されていることは稀
値がない場合
• テーブル定義と実際のデータが違う
• そもそも入ってない
変換が必要な場合
• 順序・名義
• 男女やそう思うなど
エラーデータや著しく外れたデータ
• クレンジングが必要なケース
データ量が少ない
- 13.
© 2016 IBMCorporation13
閑話休題
どのくらいのデータがあればいいのか?
データエンジニアとデータサイエンティストのコミュニケーション
ミスに気をつける
• 双方でデータに対する認識が違うとキャパシティプランニン
グに失敗します。
- 14.
© 2016 IBMCorporation14
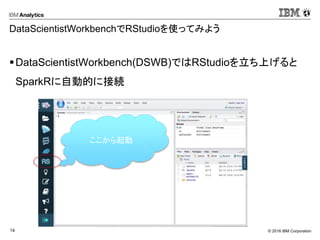
DataScientistWorkbenchでRStudioを使ってみよう
DataScientistWorkbench(DSWB)ではRStudioを立ち上げると
SparkRに自動的に接続
ここから起動
- 15.
© 2016 IBMCorporation15
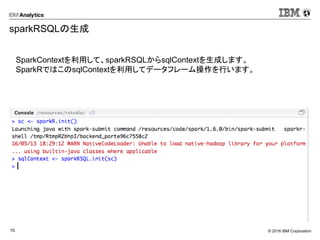
sparkRSQLの生成
SparkContextを利用して、sparkRSQLからsqlContextを生成します。
SparkRではこのsqlContextを利用してデータフレーム操作を行います。
- 16.
© 2016 IBMCorporation16
Rのデータセットからデータフレームの作成
RのfaithfulをもとにcreateDataFrameでデータフレームを作成します。
- 17.
© 2016 IBMCorporation17
スキーマの確認
printSchemaを使ってスキーマを表示させます。
- 18.
© 2016 IBMCorporation18
Columnの選択
Selectを使ってcolumnを絞ってみます。
- 19.
© 2016 IBMCorporation19
データのフィルタリング
filterを使ってデータのフィルタリングを行います
- 20.
© 2016 IBMCorporation20
データのグルーピング
groupByを使ってデータのグルーピングを行います
- 21.
- 22.
© 2016 IBMCorporation22
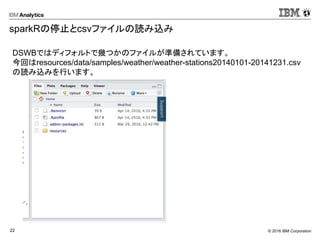
sparkRの停止とcsvファイルの読み込み
DSWBではディフォルトで幾つかのファイルが準備されています。
今回はresources/data/samples/weather/weather-stations20140101-20141231.csv
の読み込みを行います。
- 23.
© 2016 IBMCorporation23
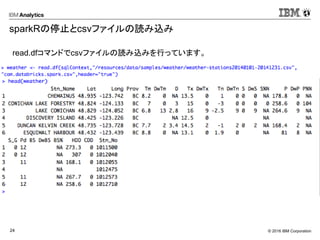
sparkRroの停止とcsvファイルの読み込み
SparkRではread.dfでファイルの読み込みを行うことが可能ですが、
read.dfはjson、parquetの形式をディフォルトでサポートします。
csvファイルを読み込むため、spark-packageからcsv用のpackageを
SparkContextにロードする必要があります。
- 24.
© 2016 IBMCorporation24
sparkRの停止とcsvファイルの読み込み
read.dfコマンドでcsvファイルの読み込みを行っています。
- 25.
© 2016 IBMCorporation25
ファイルへの出力
先ほどのweatherをProvでfilterし、write.dfを用いてparquet形式で出力します。
- 26.
© 2016 IBMCorporation26
SQLとRの複合的な利用
registerTempTableをりようしたSparkSQLとSparkRの利用
- 27.
© 2016 IBMCorporation27
Appendix
DataPaloozaを日本でもやります!
- 28.
© 2016 IBMCorporation28
ワークショップ、セッション、および資料は、IBMまたはセッション発表者によって準備され、それぞれ独自の見解を反映したものです。
それらは情報提供の目的のみで提供されており、いかなる参加者に対しても法律的またはその他の指導や助言を意図したものではなく、
またそのような結果を生むものでもありません。本講演資料に含まれている情報については、完全性と正確性を期するよう努力しましたが
「現状のまま」提供され、明示または暗示にかかわらずいかなる保証も伴わないものとします。本講演資料またはその他の資料の使用によ
って、あるいはその他の関連によって、いかなる損害が生じた場合も、IBMは責任を負わないものとします。 本講演資料に含まれている内
容は、IBMまたはそのサプライヤーやライセンス交付者からいかなる保証または表明を引きだすことを意図したものでも、IBMソフトウェ
アの使用を規定する適用ライセンス契約の条項を変更することを意図したものでもなく、またそのような結果を生むものでもありません。
本講演資料でIBM製品、プログラム、またはサービスに言及していても、IBMが営業活動を行っているすべての国でそれらが使用可能であ
ることを暗示するものではありません。本講演資料で言及している製品リリース日付や製品機能は、市場機会またはその他の要因に基づい
てIBM独自の決定権をもっていつでも変更できるものとし、いかなる方法においても将来の製品または機能が使用可能になると確約するこ
とを意図したものではありません。本講演資料に含まれている内容は、参加者が開始する活動によって特定の販売、売上高の向上、または
その他の結果が生じると述べる、または暗示することを意図したものでも、またそのような結果を生むものでもありません。 パフォーマン
スは、管理された環境において標準的なIBMベンチマークを使用した測定と予測に基づいています。ユーザーが経験する実際のスループッ
トやパフォーマンスは、ユーザーのジョブ・ストリームにおけるマルチプログラミングの量、入出力構成、ストレージ構成、および処理さ
れるワークロードなどの考慮事項を含む、数多くの要因に応じて変化します。したがって、個々のユーザーがここで述べられているものと
同様の結果を得られると確約するものではありません。
記述されているすべてのお客様事例は、それらのお客様がどのようにIBM製品を使用したか、またそれらのお客様が達成した結果の実例と
して示されたものです。実際の環境コストおよびパフォーマンス特性は、お客様ごとに異なる場合があります。
IBM、IBM ロゴ、ibm.comは、世界の多くの国で登録されたInternational Business Machines Corporationの商標です。
他の製品名およびサービス名等は、それぞれIBMまたは各社の商標である場合があります。
現時点での IBM の商標リストについては、www.ibm.com/legal/copytrade.shtmlをご覧ください。
Apache Hadoop、Hadoop、Apache Spark、Spark、Apache Kafka、Kafka、 Apache、は、Apache Software Foundationの米国およびその他の国
における登録商標、または商標です。