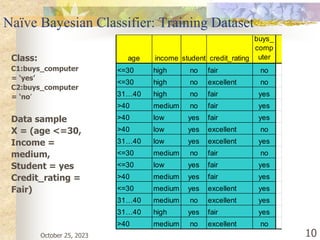
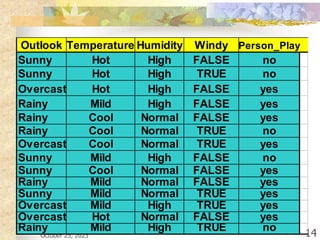
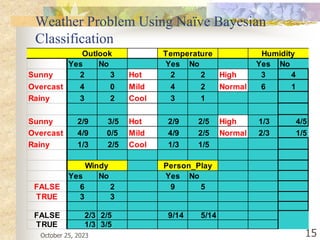
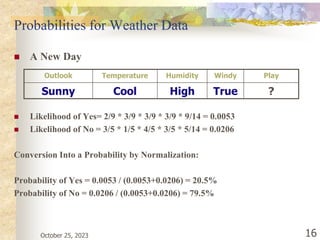
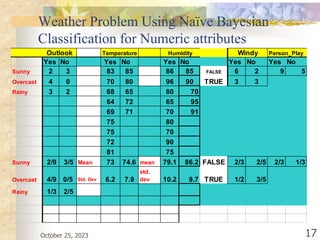
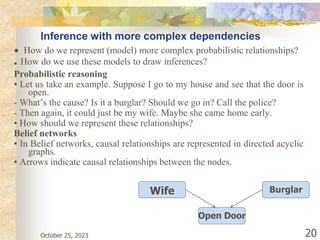
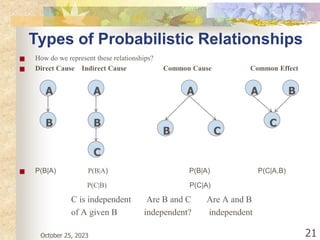
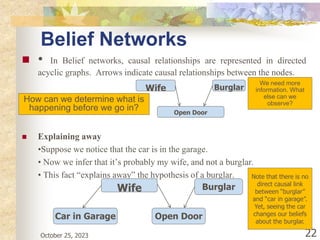
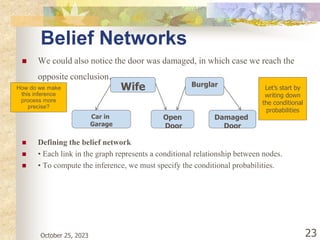
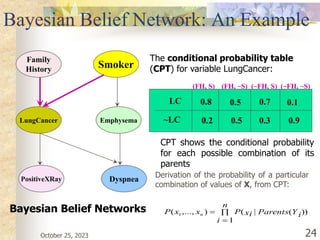
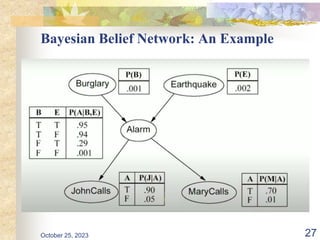
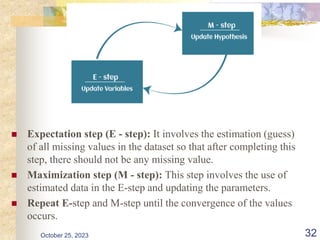
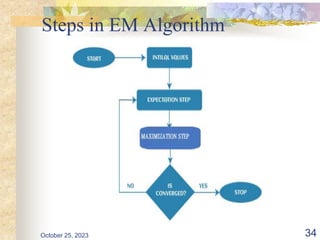
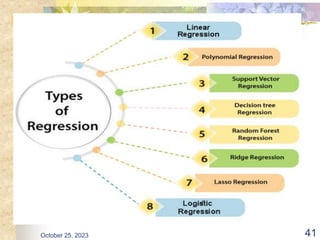
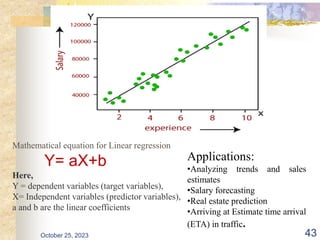
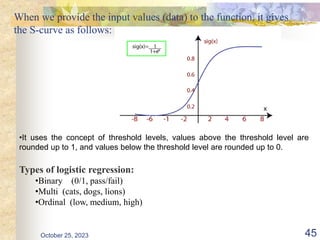
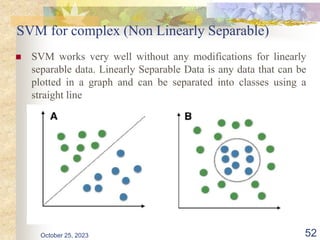
The document discusses Naive Bayesian classification and its use in machine learning. It begins by defining Bayesian classification and how it uses probability to represent uncertainty in learning relationships from data. It then describes the key assumptions of naive Bayesian classifiers, including class conditional independence. The document provides an example of how a naive Bayesian classifier would work on a weather dataset to predict if someone will play or not play based on weather attributes. It concludes by discussing some advantages and disadvantages of the naive Bayesian approach.