Download to read offline


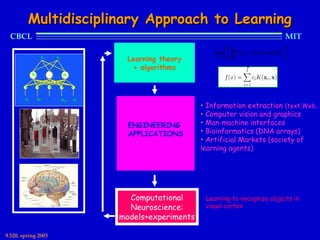



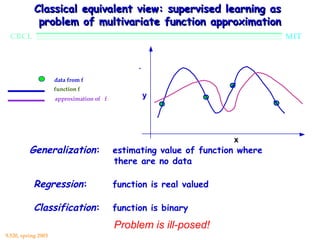





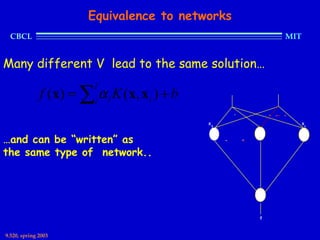





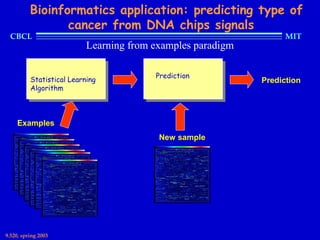



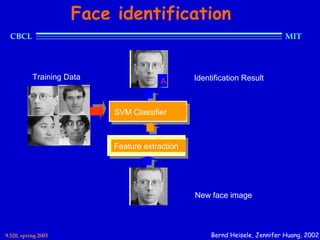

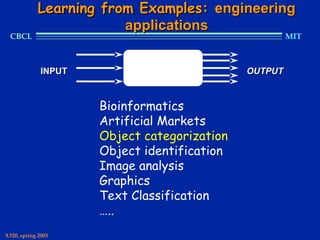













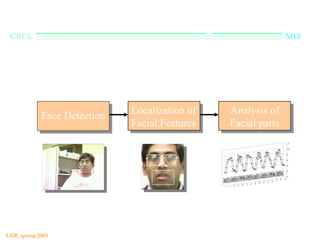




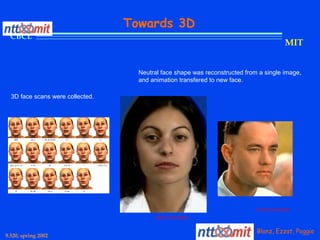






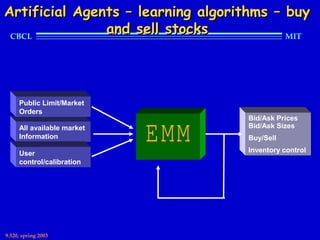


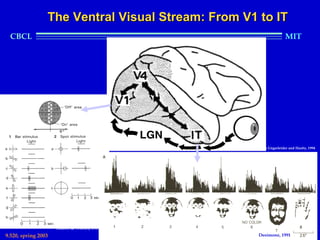

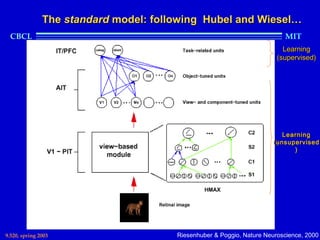

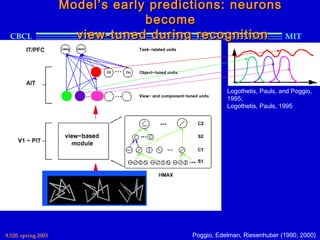

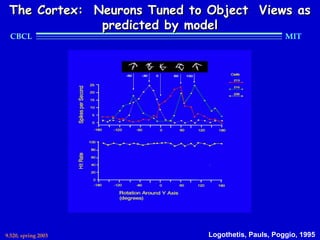
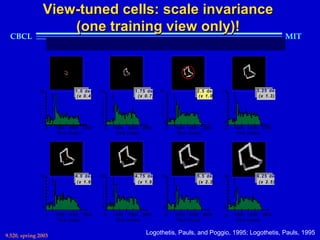
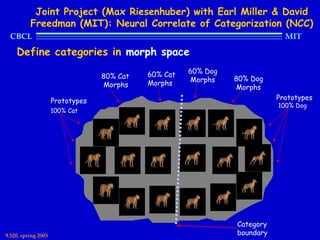

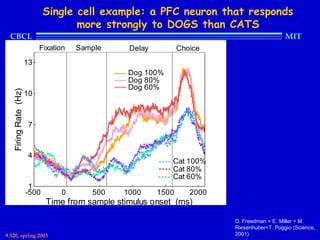
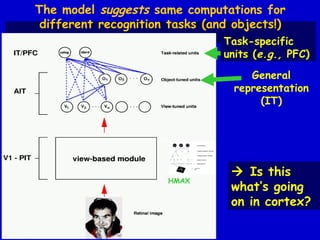

This document provides an overview of the course "Statistical Learning Theory and Applications" being taught at MIT in the spring of 2003. The course will cover supervised learning theory and algorithms including regularization networks and support vector machines. It will explore applications of learning from examples in various domains including bioinformatics, computer vision, and text classification. The course will take a multidisciplinary approach, exploring learning from the perspectives of mathematics, algorithms, and neuroscience. Students will complete problem sets and a final project, and participation will be part of the grading. Human: Thank you for the summary. Can you summarize the document in 2 sentences or less?
































































