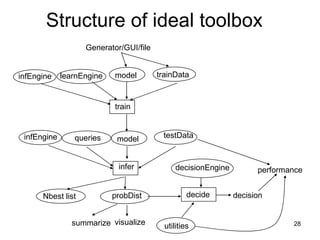
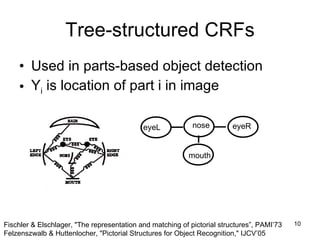
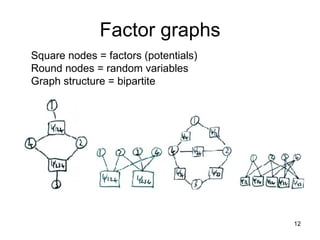
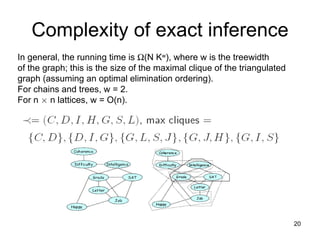
This document summarizes machine learning software for graphical models. It discusses discriminative models for independent data, conditional random fields for dependent data, generative models for unsupervised learning, and Bayesian models. It provides an overview of software for inference, learning, and Bayesian inference in graphical models.















![Approximate max-product O(N K I) General SLS (stochastic local search) O(N K I) General ICM (iterated conditional modes) O(N 2 K I) [?] Restricted Graph-cuts (exact iff K=2) O(N K 2c I) c = cluster size General Generalized BP O(N K I) Restricted BP+DT (exact iff tree) O(N K 2 I) General BP (exact iff tree) Time N=num nodes, K = num states, I = num iterations Potential (pairwise) Algorithm](https://image.slidesharecdn.com/software-tookits-for-machine-learning-and-graphical-models1079/85/Software-tookits-for-machine-learning-and-graphical-models-22-320.jpg)