The document summarizes a research paper on facial landmark detection using deep multi-task learning. It proposes a Tasks-Constrained Deep Convolutional Network (TCDCN) that uses facial landmark detection as the main task and related auxiliary tasks like pose estimation and attribute inference to improve performance. The TCDCN learns shared representations across tasks using a deep convolutional network. It introduces task-wise early stopping to halt learning on auxiliary tasks that reach optimal performance early to avoid overfitting and improve convergence on the main task of landmark detection. Experimental results showed the proposed approach outperformed existing methods.








![Landmark detection by CNN
cascaded CNN [Sun et al. 2013]
¤ 顔を予め幾つかのパーツに分けてそれぞれCNNでlandmarkを推定し、最
後に平均をとって出⼒
¤ 元論⽂を読むと、段階ごとにCNNを適⽤してるっぽい
¤ 本研究に最も近い研究(本著者と同じ研究室)
Figure 2: Three-level cascaded convolutional networks. The input is the face region returned by a face detector. The three
networks at level 1 are denoted as F1, EN1, and NM1. Networks at level 2 are denoted as LE21, LE22, RE21, RE22, N21,
N22, LM21, LM22, RM21, and RM22. Both LE21 and LE22 predict the left eye center, and so forth. Networks at level 3](https://image.slidesharecdn.com/2015-07-02-suzuki-160226124454/85/Facial-Landmark-Detection-by-Deep-Multi-task-Learning-9-320.jpg)
![Multi-task learning
¤ deep learningとmulti-task learningは相性がいい
¤ あるタスクで学習した特徴量を他の特徴量でも利⽤できる
¤ 通常のマルチタスク学習では、それぞれのタスクが同じ難易度・収束
率と考えている
¤ 今回の問題は各タスクが平等ではないのでそのままでは利⽤できない
本研究ではタスクごとに早期終了(early-stopping)を設定
([Caruana et al. 1997]がヒント)](https://image.slidesharecdn.com/2015-07-02-suzuki-160226124454/85/Facial-Landmark-Detection-by-Deep-Multi-task-Learning-10-320.jpg)


![Proposed Formulation
¤ メインタスクが回帰問題、補助タスクがクラス分類なので、誤差関数
はそれぞれ2乗誤差、クロスエントロピー誤差となる
¤ 共有する画像の特徴量をDeep CNで学習
これら2つの式を合わせて学習する
メインタスク
補助タスク
can be combined, while existing methods [30] that employ Eq.(1) assume implic-
itly that the loss functions across all tasks are identical. Second, Eq.(1) allows
data xt
i in di↵erent tasks to have di↵erent input representations, while Eq.(2)
focuses on a shared input representation xi. The latter is more suitable for our
problem, since all tasks share similar facial representation.
In the following, we formulate our facial landmark detection model based on
Eq.(2). Suppose we have a set of feature vectors in a shared feature space across
tasks {xi}N
i=1 and their corresponding labels {yr
i , yp
i , yg
i , yw
i , ys
i }N
i=1, where yr
i is
the target of landmark detection and the remaining are the targets of auxiliary
tasks, including inferences of ‘pose’, ‘gender’, ‘wear glasses’, and ‘smiling’. More
specifically, yr
i 2 R10
is the 2D coordinates of the five landmarks (centers of the
eyes, nose, corners of the mouth), yp
i 2 {0, 1, .., 4} indicates five di↵erent poses
(0 , ±30 , ±60 ), and yg
i , yw
i , ys
i 2 {0, 1} are binary attributes. It is reasonable
to employ the least square and cross-entropy as the loss functions for the main
task (regression) and the auxiliary tasks (classification), respectively. Therefore,
the objective function can be rewritten as
argmin
Wr,{Wa}
1
2
NX
i=1
kyr
i f(xi; Wr
)k2
NX
i=1
X
a2A
a
ya
i log(p(ya
i |xi; Wa
))+
TX
t=1
kWk2
2,
(3)
where f(xi; Wr
) = (Wr
)
T
xi in the first term is a linear function. The second
term is a softmax function p(yi = m|xi) =
exp{(Wa
m)T
xi}
P
j exp{(Wa
j )T
xi}
, which models the
class posterior probability (Wa
j denotes the jth column of the matrix), and
the third term penalizes large weights (W = {Wr
, {Wa
}}). In this work, we
adopt the deep convolutional network (DCN) to jointly learn the share feature
space x, since the unique structure of DCN allows for multitask and shared
representation.
tasks, including inferences of ‘pose’, ‘gender’, ‘wear glasses’, and ‘smiling’. More
specifically, yr
i 2 R10
is the 2D coordinates of the five landmarks (centers of the
eyes, nose, corners of the mouth), yp
i 2 {0, 1, .., 4} indicates five di↵erent poses
(0 , ±30 , ±60 ), and yg
i , yw
i , ys
i 2 {0, 1} are binary attributes. It is reasonable
to employ the least square and cross-entropy as the loss functions for the main
task (regression) and the auxiliary tasks (classification), respectively. Therefore,
the objective function can be rewritten as
argmin
Wr,{Wa}
1
2
NX
i=1
kyr
i f(xi; Wr
)k2
NX
i=1
X
a2A
a
ya
i log(p(ya
i |xi; Wa
))+
TX
t=1
kWk2
2,
(3)
where f(xi; Wr
) = (Wr
)
T
xi in the first term is a linear function. The second
term is a softmax function p(yi = m|xi) =
exp{(Wa
m)T
xi}
P
j exp{(Wa
j )T
xi}
, which models the
class posterior probability (Wa
j denotes the jth column of the matrix), and
the third term penalizes large weights (W = {Wr
, {Wa
}}). In this work, we
adopt the deep convolutional network (DCN) to jointly learn the share feature
space x, since the unique structure of DCN allows for multitask and shared
representation.
In particular, given a face image x0
, the DCN projects it to higher level
representation gradually by learning a sequence of non-linear mappings
x0 ((Ws1 )T
x0
)
! x1 ((Ws2 )T
x1
)
! ...
((Wsl )T
xl 1
)
! xl
. (4)
Here, (·) and Wsl
indicate the non-linear activation function and the filters
needed to be learned in the layer l of DCN. For instance, xl
=
⇣
(Wsl
)
T
xl 1
⌘
.
Note that xl
is the shared representation between the main task r, and related](https://image.slidesharecdn.com/2015-07-02-suzuki-160226124454/85/Facial-Landmark-Detection-by-Deep-Multi-task-Learning-13-320.jpg)


![Learning procedure
¤ 最急降下法で求める
is the importance coe cient of a-th task’s er
gradient descent. Its magnitude reveals that m
longer impact. This strategy achieves satisfac
volution network given multiple tasks. Its sup
in Section 4.2.
Learning procedure: We have discussed w
iliary task during training before it over-fit
stochastic gradient descent to update the w
the network. For example, the weight matri
Wr
= ⌘ @Er
@Wr with ⌘ being the learning ra
tion), and @Er
@Wr = (yr
i (Wr
)
T
xi)xT
i . Also, th
weights can be calculated in a similar manne
For the filters in the lower layer, we compute
loss error back following the back-propagatio
"1
(Ws2 )T
"2 @ (u1)
@u1
"2
(Ws3 )T
"3 @ (u2
@u2
where "l
is the error at the shared represent
(Wr
)T
xi] +
P
a2A(p(ya
i |xi; Wa
) ya
i )Wa
, w
derivatives. The errors of the lower layers a
instance, "l 1
= (Wsl
)T
"l @ (ul 1
)
@ul 1 , where @ (
@u
function. Then, the gradient of the filter is o
⌦ represents the receptive field of the filter.
ing an auxiliary task. Let Ea
val and Ea
tr be the values of the loss function of task
a on the validation set and training set, respectively. We stop the task if its
measure exceeds a threshold ✏ as below
k · medt
j=t kEa
tr(j)
Pt
j=t k Ea
tr(j) k · medt
j=t kEa
tr(j)
·
Ea
val(t) minj=1..t Ea
tr(j)
a · minj=1..t Ea
tr(j)
> ✏, (5)
where t denotes the current iteration and k controls a training strip of length
k. The ‘med’ denotes the function for calculating median value. The first ter-
m in Eq.(5) represents the tendency of the training error. If the training error
drops rapidly within a period of length k, the value of the first term is small,
indicating that training can be continued as the task is still valuable; otherwise,
the first term is large, then the task is more likely to be stopped. The second
term measures the generalization error compared to the training error. The a
is the importance coe cient of a-th task’s error, which can be learned through
gradient descent. Its magnitude reveals that more important task tends to have
longer impact. This strategy achieves satisfactory results for learning deep con-
volution network given multiple tasks. Its superior performance is demonstrated
in Section 4.2.
Learning procedure: We have discussed when and how to switch o↵ an aux-
iliary task during training before it over-fits. For each iteration, we perform
stochastic gradient descent to update the weights of the tasks and filters of
the network. For example, the weight matrix of the main task is updated by
Wr
= ⌘ @Er
@Wr with ⌘ being the learning rate (⌘ = 0.003 in our implementa-
tion), and @Er
@Wr = (yr
i (Wr
)
T
xi)xT
i . Also, the derivative of the auxiliary task’s
weights can be calculated in a similar manner as @Ea
@Wa = (p(ya
i |xi; Wa
) ya
i )xi.
For the filters in the lower layer, we compute the gradients by propagating the
loss error back following the back-propagation strategy as
"1
(Ws2 )T
"2 @ (u1)
@u1
"2
(Ws3 )T
"3 @ (u2)
@u2
...
(Wsl )T
"l @ (ul 1)
@ul 1
"l
, (6)
where "l
is the error at the shared representation layer and "l
= (Wr
)T
[yr
i
(Wr
)T
xi] +
P
a2A(p(ya
i |xi; Wa
) ya
i )Wa
, which is the integration of all tasks’
derivatives. The errors of the lower layers are computed following Eq.(6). For
instance, "l 1
= (Wsl
)T
"l @ (ul 1
)
@ul 1 , where @ (u)
@u is the gradient of the activation
function. Then, the gradient of the filter is obtained by @E
@Wsl
= "l
xl 1
⌦ , where
⌦ represents the receptive field of the filter.
メインタスク
補助タスク
ts magnitude reveals that more important task tends to have
is strategy achieves satisfactory results for learning deep con-
given multiple tasks. Its superior performance is demonstrated
dure: We have discussed when and how to switch o↵ an aux-
training before it over-fits. For each iteration, we perform
t descent to update the weights of the tasks and filters of
example, the weight matrix of the main task is updated by
with ⌘ being the learning rate (⌘ = 0.003 in our implementa-
(yr
i (Wr
)
T
xi)xT
i . Also, the derivative of the auxiliary task’s
culated in a similar manner as @Ea
@Wa = (p(ya
i |xi; Wa
) ya
i )xi.
he lower layer, we compute the gradients by propagating the
owing the back-propagation strategy as
)T
"2 @ (u1)
@u1
"2
(Ws3 )T
"3 @ (u2)
@u2
...
(Wsl )T
"l @ (ul 1)
@ul 1
"l
, (6)
ror at the shared representation layer and "l
= (Wr
)T
[yr
i
(p(ya
i |xi; Wa
) ya
i )Wa
, which is the integration of all tasks’
rrors of the lower layers are computed following Eq.(6). For
Wsl
)T
"l @ (ul 1
)
@ul 1 , where @ (u)
@u is the gradient of the activation
he gradient of the filter is obtained by @E
@Wsl
= "l
xl 1
⌦ , where
volution network
in Section 4.2.
Learning proce
iliary task during
stochastic gradien
the network. For
Wr
= ⌘ @Er
@Wr
tion), and @Er
@Wr =
weights can be ca
For the filters in
loss error back fo
"1
(Ws
where "l
is the er
(Wr
)T
xi] +
P
a2A
derivatives. The
instance, "l 1
= (
function. Then, t
⌦ represents the
gradient descent. Its magnitude reveals tha
longer impact. This strategy achieves satis
volution network given multiple tasks. Its s
in Section 4.2.
Learning procedure: We have discussed
iliary task during training before it over-
stochastic gradient descent to update the
the network. For example, the weight ma
Wr
= ⌘ @Er
@Wr with ⌘ being the learning
tion), and @Er
@Wr = (yr
i (Wr
)
T
xi)xT
i . Also,
weights can be calculated in a similar man
For the filters in the lower layer, we compu
loss error back following the back-propagat
"1
(Ws2 )T
"2 @ (u1)
@u1
"2
(Ws3 )T
"3 @
@
where "l
is the error at the shared represe
(Wr
)T
xi] +
P
a2A(p(ya
i |xi; Wa
) ya
i )Wa
,
derivatives. The errors of the lower layers
instance, "l 1
= (Wsl
)T
"l @ (ul 1
)
@ul 1 , where @
バックプロパゲーション
reveals that more important task tends to have
ieves satisfactory results for learning deep con-
tasks. Its superior performance is demonstrated
discussed when and how to switch o↵ an aux-
re it over-fits. For each iteration, we perform
update the weights of the tasks and filters of
weight matrix of the main task is updated by
he learning rate (⌘ = 0.003 in our implementa-
i)xT
i . Also, the derivative of the auxiliary task’s
milar manner as @Ea
@Wa = (p(ya
i |xi; Wa
) ya
i )xi.
we compute the gradients by propagating the
k-propagation strategy as
(Ws3 )T
"3 @ (u2)
@u2
...
(Wsl )T
"l @ (ul 1)
@ul 1
"l
, (6)
red representation layer and "l
= (Wr
)T
[yr
i
ya
i )Wa
, which is the integration of all tasks’
wer layers are computed following Eq.(6). For
)
, where @ (u)
@u is the gradient of the activation](https://image.slidesharecdn.com/2015-07-02-suzuki-160226124454/85/Facial-Landmark-Detection-by-Deep-Multi-task-Learning-16-320.jpg)

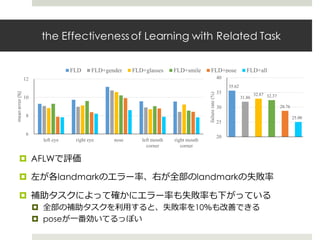


![The Benefits of Task-wise Early Stopping
(a):task-wise early stoppingでかなりエラーが落ちている
(b):訓練誤差・汎化誤差がearly stoppingで⼩さくなっている
Facial Landmark Detection by Deep Multi-
stop ‘glasses’
stop ‘gender’
stop ‘smile’
stop ‘pose’6
8
10
12
14
16
left eye right eye nose left mouth
corner
right mouth
corner
meanerror(%)
FLD+all
FLD+all with task-wise early-stopping
Fig. 7. (a) Task-wise early stopping leads to substantially lower
di↵erent landmarks. (b) Its benefit is also reflected on the trainin
convergence rate. The error is measured in L2-norm with respec
of the 10 coordinates values (normalized to [0,1]) for the 5 landm
4.3 Comparison with the Cascaded CNN [21]
Although both the TCDCN and the cascaded CNN [21] a
we show that the proposed model can achieve better detect
significantly lower computational cost. We use the full mo
the publicly available binary code of the cascaded CNN in t
Landmark localization accuracy: Similar to Section 4.1](https://image.slidesharecdn.com/2015-07-02-suzuki-160226124454/85/Facial-Landmark-Detection-by-Deep-Multi-task-Learning-21-320.jpg)
![Comparison with the Cascaded CNN
¤ 訓練データを同じにしてAFLWでテスト
¤ 異なる点は、マルチタスク学習を利⽤しているかどうかという点
¤ 4つのlandmarkでcascaded CNNを上回る
¤ 全体的にはcascaded CNNに勝っている
that we use the same 10,000 training faces as in the cascaded CNN method.
Thus the only di↵erence is that we exploit a multi-task learning approach. It
is observed from Figure 8 that our method performs better in four out of five
landmarks, and the overall accuracy is superior to that of cascaded CNN.
(a) (b)
7
8
9
10
11
left eye right eye nose left mouth
corner
right mouth
corner
meanerror(%)
cascaded CNN Ours
10
20
30
40
50
left eye right eye nose left mouth
corner
right mouth
corner
failurerate(%)
Fig. 8. The proposed TCDCN vs. cascaded CNN [21]: (a) mean error over di↵erent
landmarks and (b) the overall failure rate.
Computational e ciency: Suppose the computation time of a 2D-convolution
operation is ⌧, the total time cost for a CNN with L layers can be approximated
by
PL
l=1 s2
l qlql 1⌧, where s2
is the 2D size of the input feature map for l-th
layer, and q is the number of filters. The algorithm complexity of a CNN is thus
O(s2
q2
), directly related to the input image size and number of filters. Note that](https://image.slidesharecdn.com/2015-07-02-suzuki-160226124454/85/Facial-Landmark-Detection-by-Deep-Multi-task-Learning-22-320.jpg)
![Comparison with other State-of-the-art Methods
¤ AFLWでの結果
¤ 他の既存研究の結果を全て上回っている
¤ AFWでの結果
¤ AFLWと同様
12 Z. Zhang, P. Luo, C. C. Loy, and X. Tang
5
10
15
20
25
left eye right eye nose left mouth
corner
right mouth
corner
meanerror(%)
TSPM ESR CDM Luxand RCPR SDM Ours
15.9
13.0 13.1
12.4
11.6
8.5 8.0
5
10
15
20
meanerror(%)
5
10
15
20
25
left eye right eye nose left mouth
corner
right mouth
corner
meanerror(%)
14.3
12.2
11.1
10.4
9.3
8.8 8.2
5
10
15
20
meanerror(%)
AFLWAFW
Fig. 9. Comparison with RCPR [3], TSPM [32], CDM [27], Luxand [18], and SDM [25]
on AFLW [11] (the first row) and AFW [32] (the second row) datasets. The left sub-
figures show the mean errors on di↵erent landmarks, while the right subfigures show
the overall errors.
multiple CNNs in di↵erent cascaded layers (23 CNNs in its implementation).
Hence, TCDCN has much lower computational cost. The cascaded CNN requires](https://image.slidesharecdn.com/2015-07-02-suzuki-160226124454/85/Facial-Landmark-Detection-by-Deep-Multi-task-Learning-23-320.jpg)
![Comparison with other State-of-the-art Methods
⾊々な画像の結果
¤ 1⾏⽬:メガネかけてる
¤ 2⾏⽬:ポーズのバリエーション
¤ 3⾏⽬:
¤ 1,2列⽬:光の当たり⽅が違う
¤ 3列⽬:画像の質が悪い
¤ 4,5列⽬:異なる表情
¤ 6~8列⽬:間違った例(⾚が間違った部分)
Facial Landmark Detection by Deep Multi-task Learning 13
0’ NS NG F30’ NS G F
60’ NS NG F 30’ S NG F-30’ NS NG F
0’ NS G M
60’ NS NG F
-30’ NS G M-30’ S G M
-30’ S NG F
0’ NS NG F 0’ S NG F
-30’ NS NG M60’ S NG M60’ NS NG M
0’ NS NG M0’ S NG F
0’ S NG M
0’ NS NG M0’ NS NG M 0’ NS NG M -30’ NS NG F 0’ S NG F0’ NS NG F
Fig. 10. Example detections by the proposed model on AFLW [11] and AFW [32]
images. The labels below each image denote the tagging results for the related tasks:
(0 , ±30 , ±60 ) for pose; S/NS = smiling/not-smiling; G/NG = with-glasses/without-
glasses; M/F = male/female. Red rectangles indicate wrong tagging.
4.5 TCDCN for Robust Initialization
This section shows that the TCDCN can be used to generate a good initialization
to improve the state-of-the-art method, owing to its accuracy and e ciency. We
take RCPR [3] as an example. Instead of drawing training samples randomly as
initialization as did in [3], we initialize RCPR by first applying TCDCN on the](https://image.slidesharecdn.com/2015-07-02-suzuki-160226124454/85/Facial-Landmark-Detection-by-Deep-Multi-task-Learning-24-320.jpg)
![TCDCN for Robust Initialization
¤ TCDCNはよい初期化を得る⼿法としても利⽤できる
¤ 既存研究であるRCPRについて、TCDCNでの初期化をしたものとしな
かったもので⽐較
(a):相対的な改善(改善後のエラー/元のエラー)
(b):改善の可視化(上が普通のRCPR、下がTCDCNで初期化したRCPR)
14 Z. Zhang, P. Luo, C. C. Loy, and X. Tang
1
23 4
5
6
7
8
9 10
11 12
13
14
15
16
17 18
19 20
21
22
23 24
25
26
27
28
29 0
5
10
15
20
1 6 11 16 21 26
relativeimprovment(%)
landmarks
(a) (b)
Fig. 11. Initialization with our five-landmark estimation for RCPR [3] on
COFW dataset [3]. (a) shows the relative improvement on each landmark
(relative improvement = reduced error
original error
). (b) visualizes the improvement. The upper row
depicts the results of RCPR [3], while the lower row shows the improved results by our
initialization.
heterogeneous but subtly correlated tasks, such as appearance attribute, expres-
sion, demographic, and head pose. The proposed Tasks-Constrained DCN allows
errors of related tasks to be back-propagated in deep hidden layers for construct-
ing a shared representation to be relevant to the main task. We have shown that](https://image.slidesharecdn.com/2015-07-02-suzuki-160226124454/85/Facial-Landmark-Detection-by-Deep-Multi-task-Learning-25-320.jpg)



![[DL輪読会]Hindsight Experience Replay](https://cdn.slidesharecdn.com/ss_thumbnails/her-180105002310-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Learning to Generalize: Meta-Learning for Domain Generalization](https://cdn.slidesharecdn.com/ss_thumbnails/20180208-180209000942-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[DL輪読会]Generative Models of Visually Grounded Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20170602-170602005505-thumbnail.jpg?width=640&height=640&fit=bounds)












































