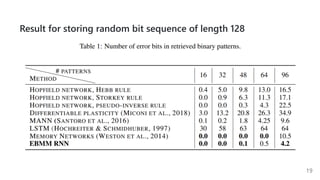
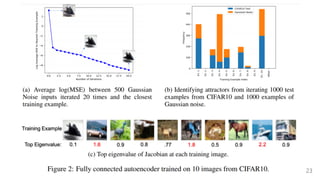
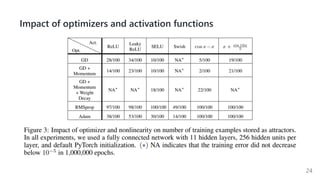
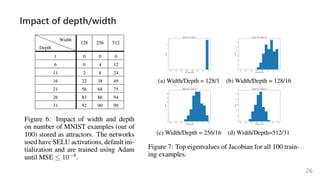
This document summarizes several papers on associative memory models. It discusses Hopfield networks, energy-based deep learning models, and how overparameterized neural networks can implement associative memory through their dynamics. Key points include: Hopfield networks use binary neurons and symmetric weights to retrieve stored patterns via network dynamics; energy-based models aim to store patterns as local minima and retrieve them through energy minimization; overparameterized autoencoders can exhibit associative memory properties without explicit energy functions through their iterative dynamics.






















































































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)





