Downloaded 12 times











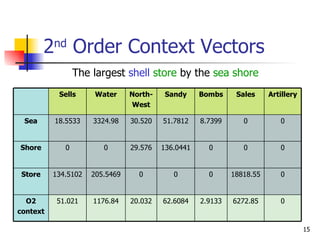
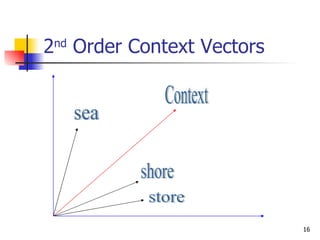

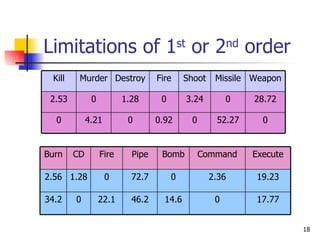



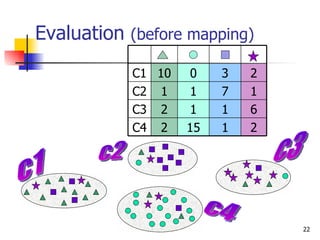
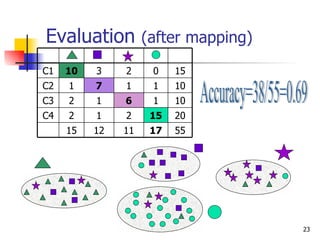
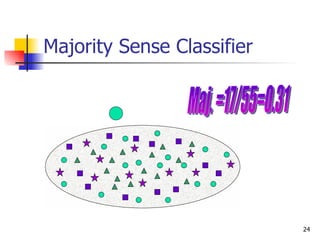

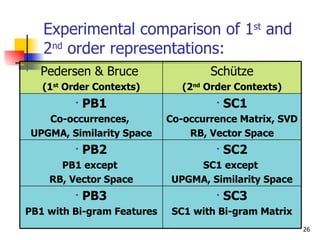
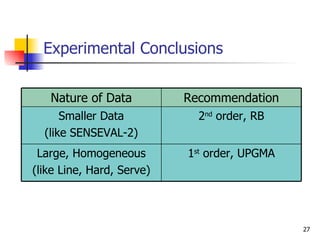


The document discusses techniques for discriminating between different meanings (senses) of words based on their usage context. It presents a methodology that clusters similar contexts of a target word based on lexical features. Contexts are represented as vectors, and similarities are measured to group contexts and label clusters. Experimental results show second-order representations that capture indirect relationships generally perform better, while first-order may be better for larger, more homogeneous data. Software tools described implement various natural language processing and word sense discrimination techniques.



















![[ACM-ICPC] Tree Isomorphism](https://cdn.slidesharecdn.com/ss_thumbnails/acm-icpctreeisomorphism-130502173609-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

















