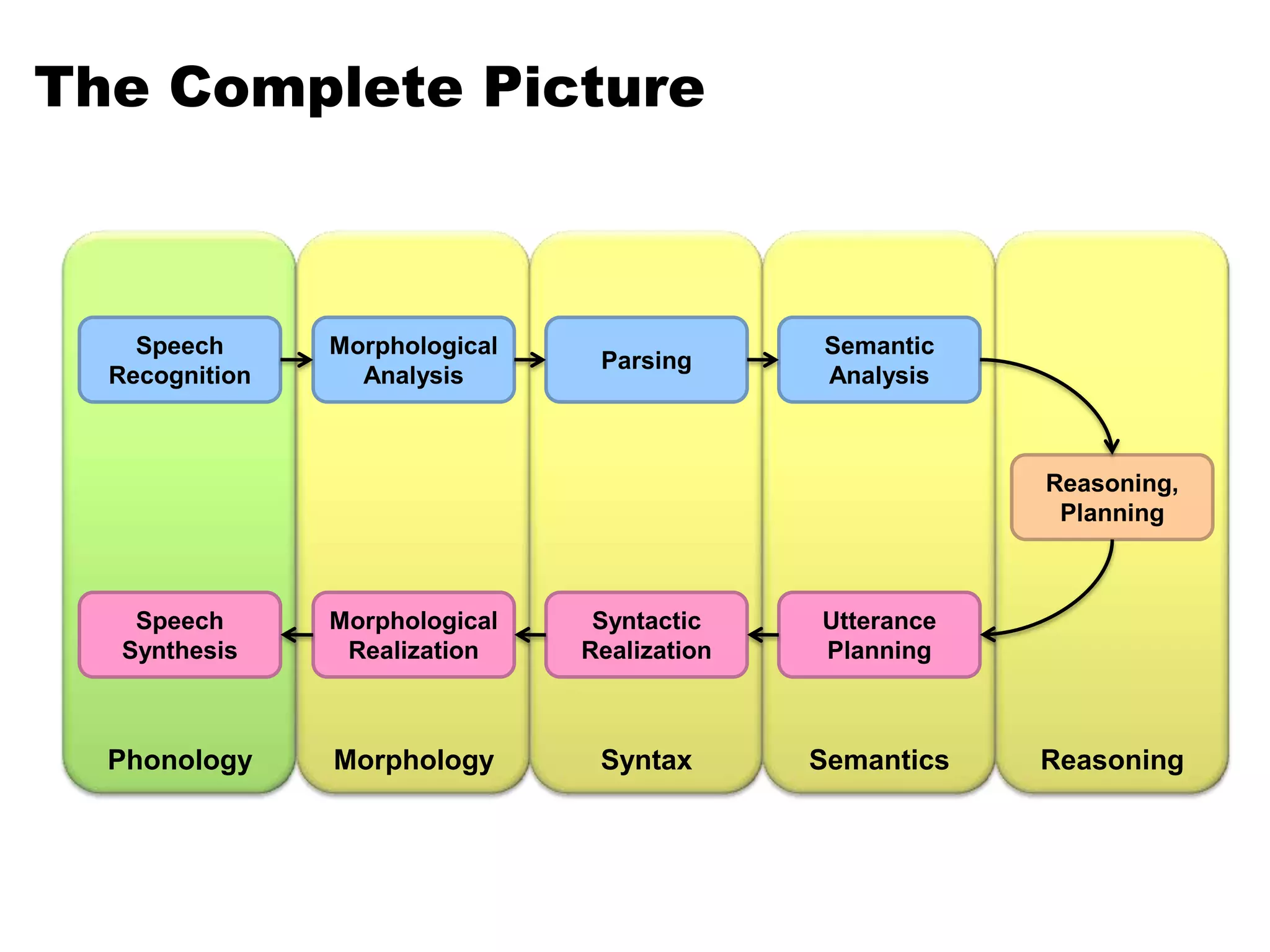
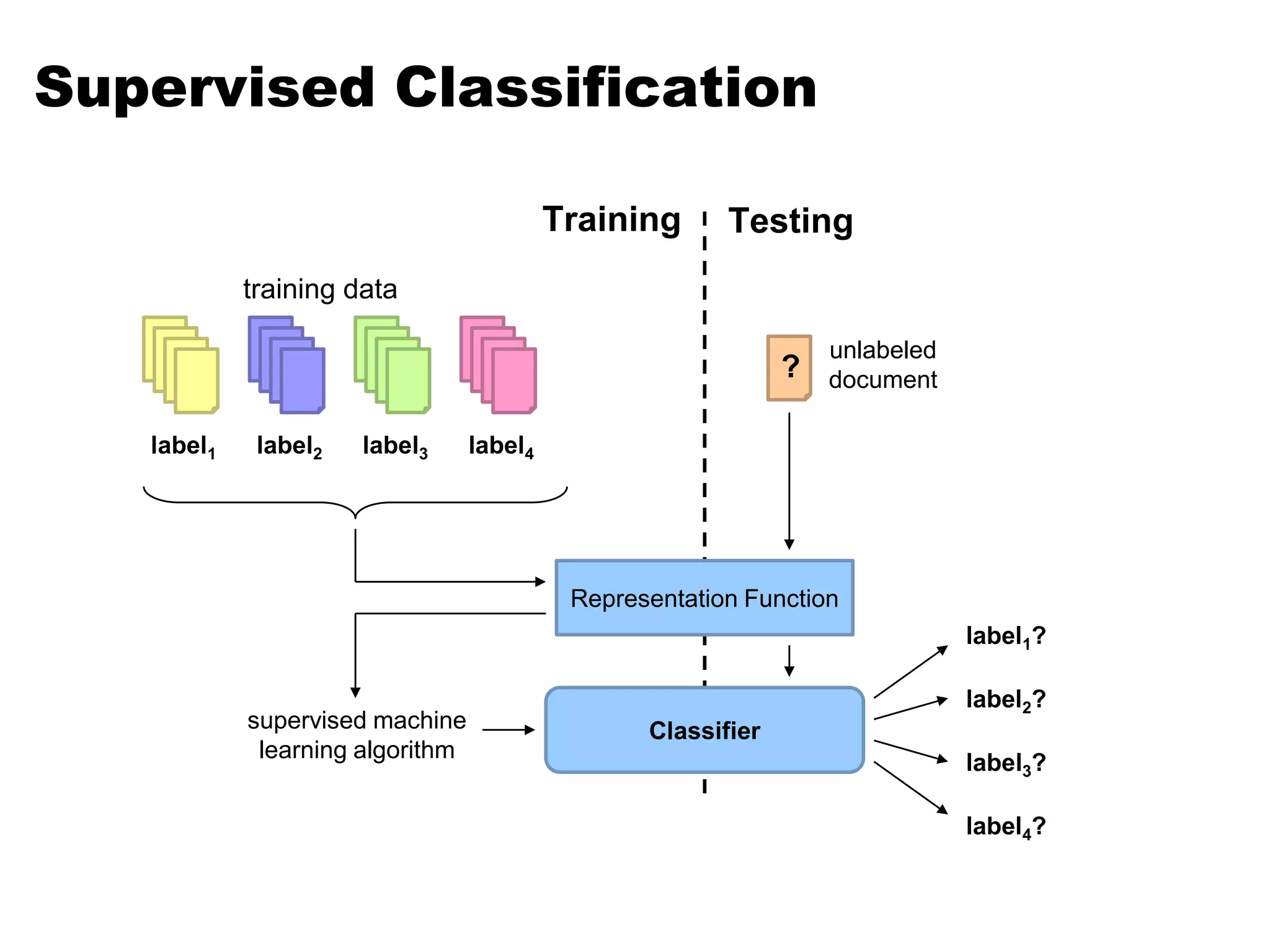
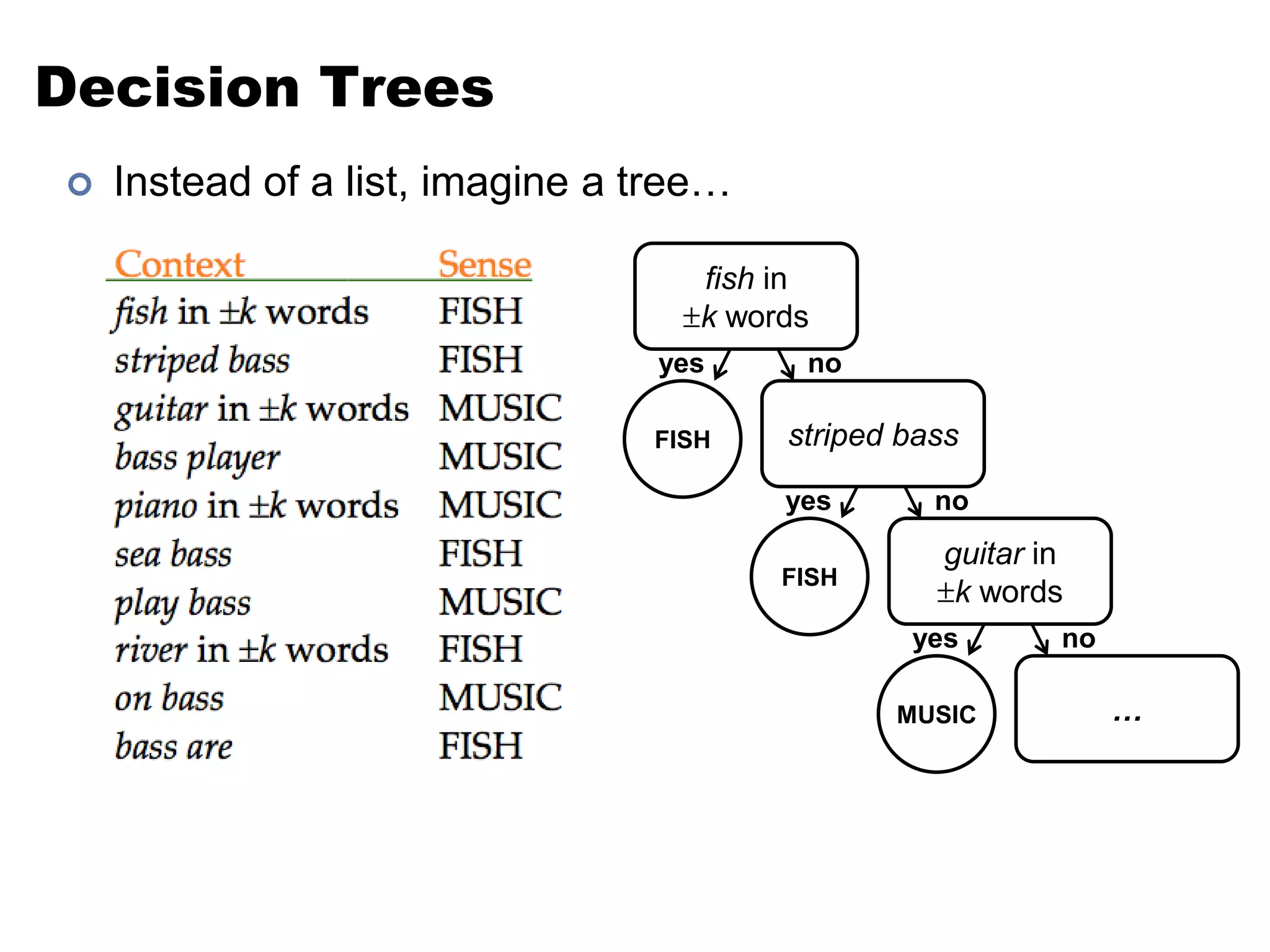
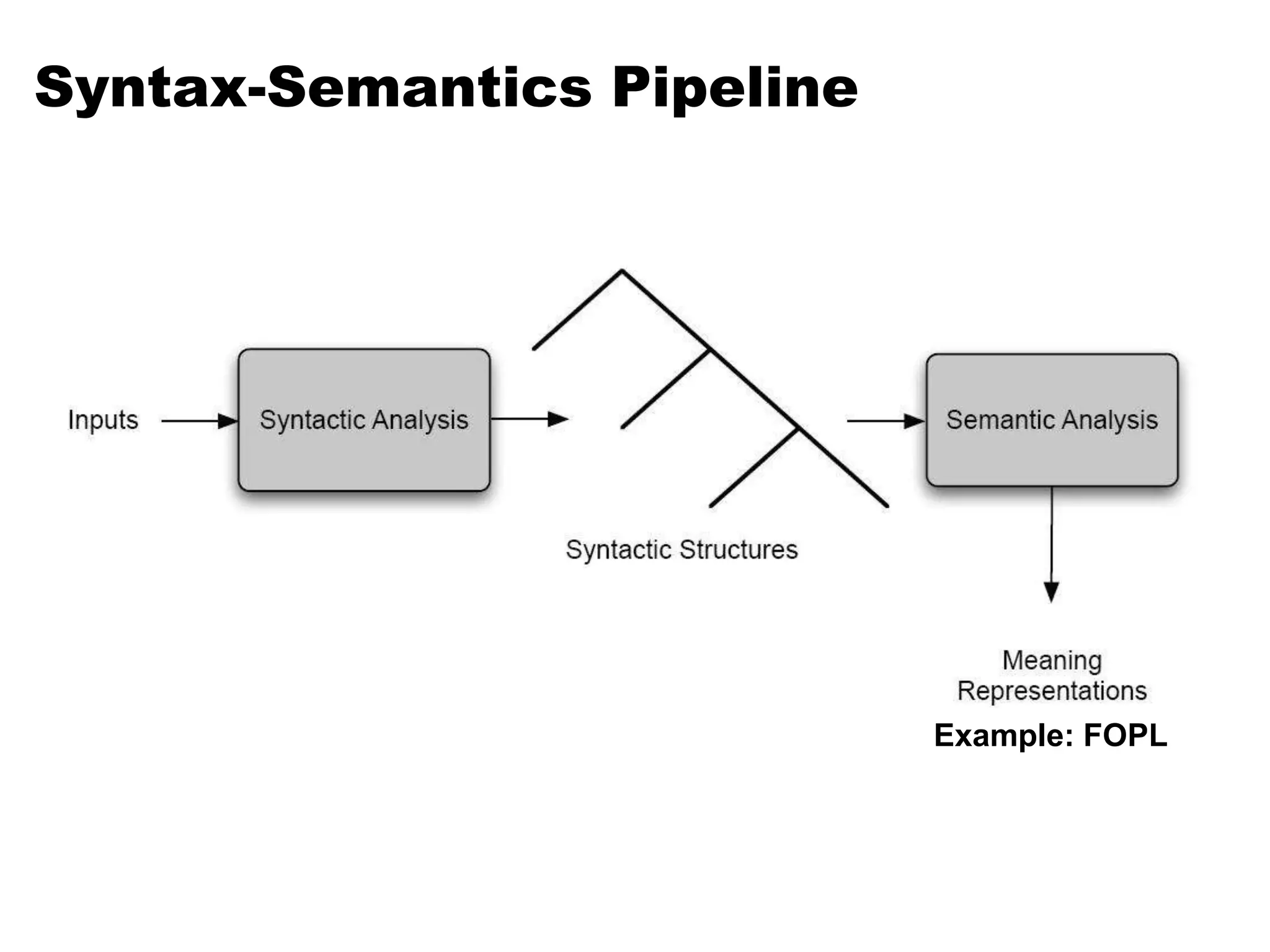
This document summarizes a lecture on word sense disambiguation and shallow semantics. It discusses word sense ambiguity and common approaches to word sense disambiguation, including knowledge-based methods like Lesk's algorithm and supervised machine learning methods. It also covers semantic analysis techniques like augmenting syntactic rules with semantic attachments and representing verb semantics using frames and semantic roles. Finally, it provides an overview of the PropBank corpus for semantic role labeling.











































![PropBank: Two Examplesagree.01Arg0: AgreerArg1: PropositionArg2: Other entity agreeingExample: [Arg0 John] agrees [Arg2 with Mary] [Arg1 on everything]fall.01Arg1: Logical subject, patient, thing fallingArg2: Extent, amount fallenArg3: Start pointArg4: End pointExample: [Arg1 Sales] fell [Arg4 to $251.2 million] [Arg3 from $278.7 million]](https://image.slidesharecdn.com/cmsc-723-computational-linguistics-i4169/75/CMSC-723-Computational-Linguistics-I-50-2048.jpg)