Download to read offline
![Language Independent Methods of Clustering Similar Contexts (with applications) Ted Pedersen University of Minnesota, Duluth http://www.d.umn.edu/~tpederse [email_address]](https://image.slidesharecdn.com/eurolan-2005-pedersen-091229125522-phpapp02/85/Eurolan-2005-Pedersen-1-320.jpg)





























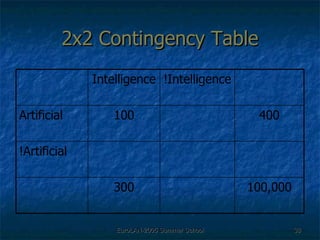
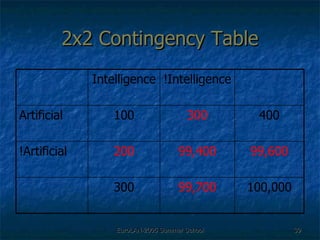
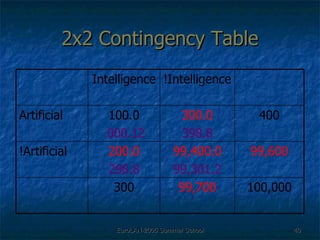



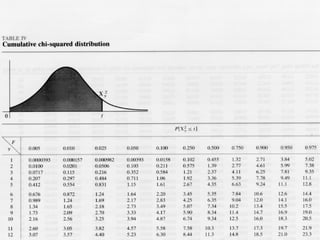











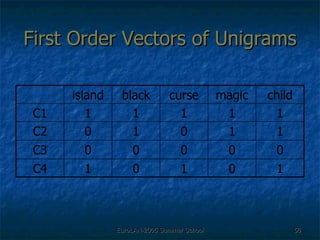




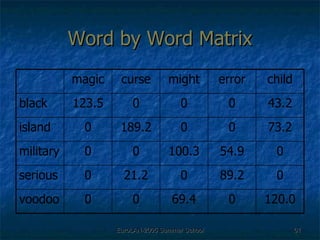


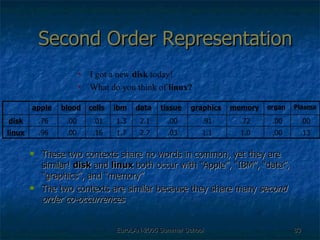
![Second Order Representation There was an [curse, child] curse of [magic, child] magic cast by that [might, child] child [curse, child] + [magic, child] + [might, child]](https://image.slidesharecdn.com/eurolan-2005-pedersen-091229125522-phpapp02/85/Eurolan-2005-Pedersen-64-320.jpg)













































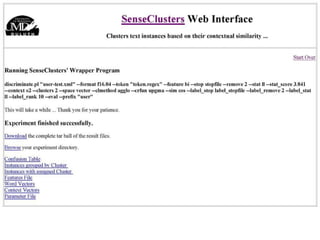


























![Thank you! Questions are welcome at any time. Feel free to contact me in person or via email ( [email_address] ) at any time! All of our software is free and open source, you are welcome to download, modify, redistribute, etc. http://www.d.umn.edu/~tpederse/code.html](https://image.slidesharecdn.com/eurolan-2005-pedersen-091229125522-phpapp02/85/Eurolan-2005-Pedersen-164-320.jpg)

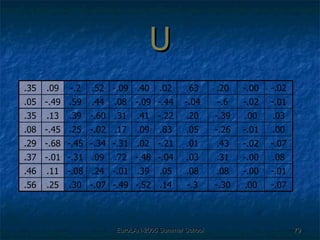
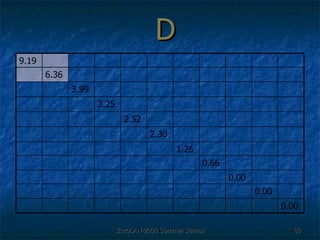
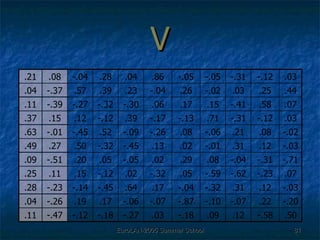
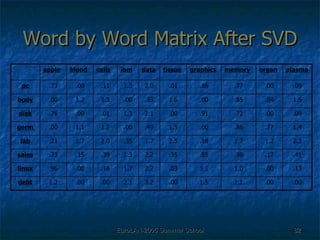
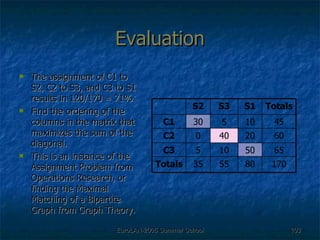
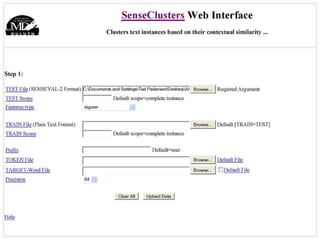
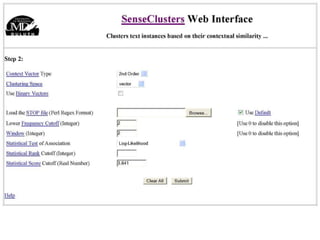
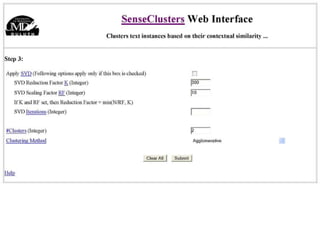
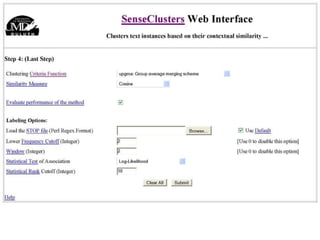
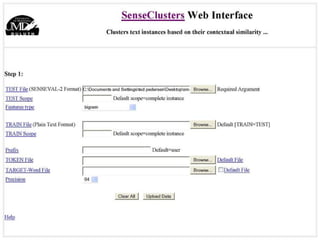
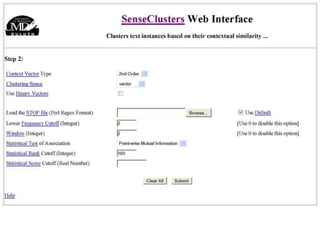
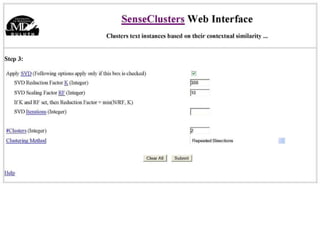
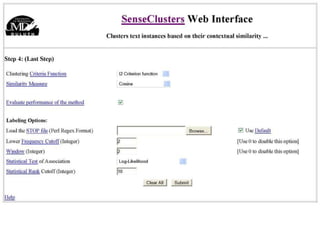
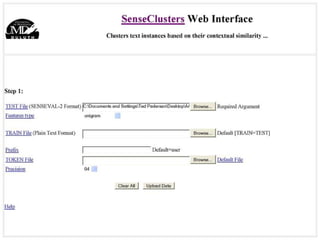
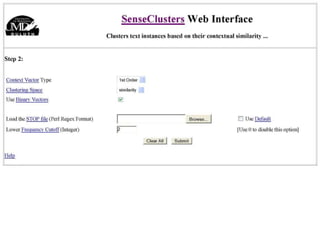
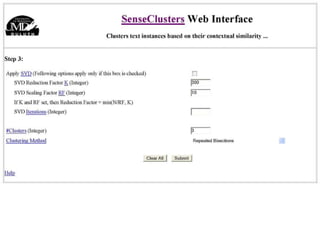
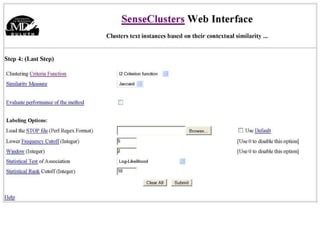
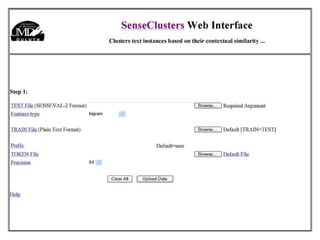
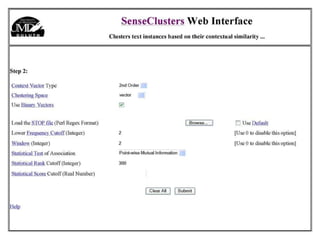
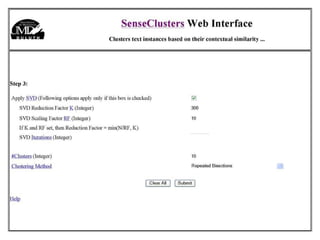
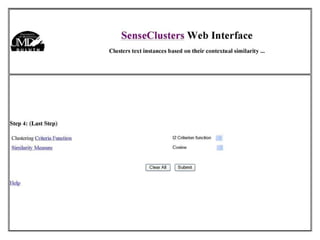
The document discusses language-independent methods for clustering similar contexts without using syntactic information or manually annotated data. It describes representing contexts as vectors of lexical features like unigrams and bigrams. First-order representations use features directly present in contexts, while second-order incorporates related words via co-occurrence networks. Measures like log-likelihood help identify meaningful word associations as features. The goal is to cluster contexts based on their feature vectors, as implemented in the SenseClusters software.


























































































