Download to read offline
![Language Independent Methods of Clustering Similar Contexts (with applications) Ted Pedersen University of Minnesota, Duluth [email_address] http:// www.d.umn.edu/~tpederse/SCTutorial.html](https://image.slidesharecdn.com/aaai-2006-pedersen-091229133926-phpapp02/85/Aaai-2006-Pedersen-1-320.jpg)











































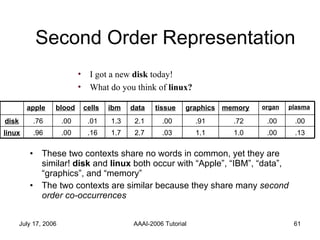
![Second Order Representation There was an [curse, child] curse of [magic, child] magic cast by that [might, child] child [curse, child] + [magic, child] + [might, child]](https://image.slidesharecdn.com/aaai-2006-pedersen-091229133926-phpapp02/85/Aaai-2006-Pedersen-49-320.jpg)






































![Thank you! Questions or comments on tutorial or SenseClusters are welcome at any time [email_address] SenseClusters is freely available via LIVE CD, the Web, and in source code form http://senseclusters.sourceforge.net SenseClusters papers available at: http://www.d.umn.edu/~tpederse/senseclusters-pubs.html](https://image.slidesharecdn.com/aaai-2006-pedersen-091229133926-phpapp02/85/Aaai-2006-Pedersen-100-320.jpg)

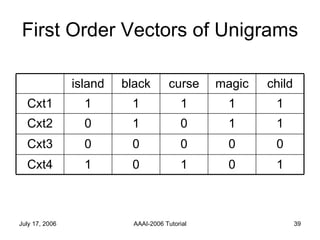
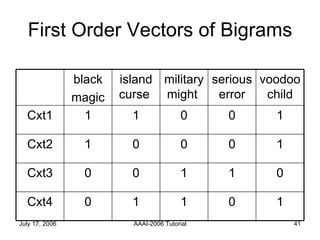
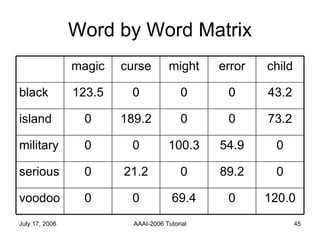
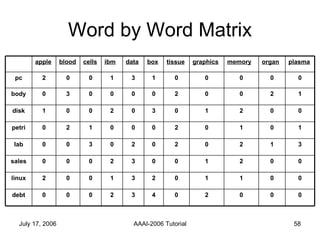
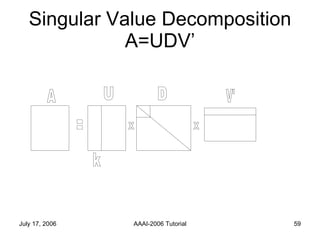
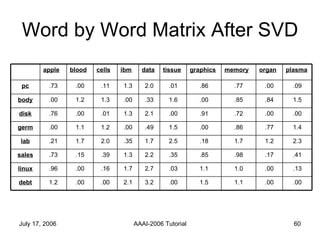
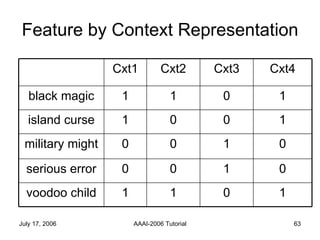
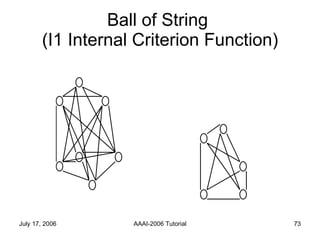
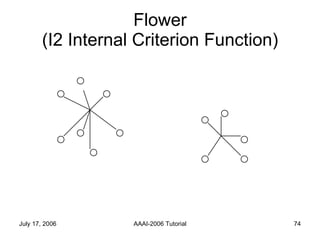
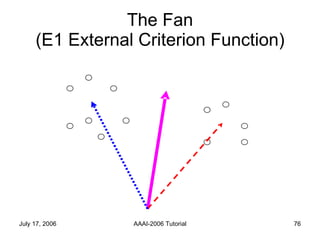
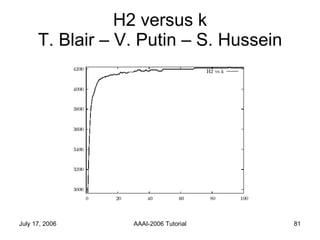
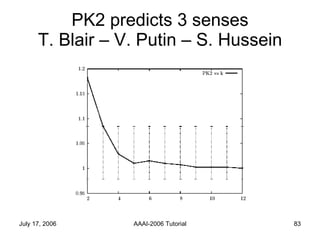
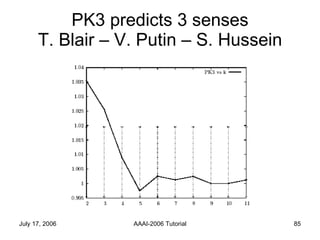
The document discusses language independent methods for clustering similar contexts without using syntactic or lexical resources. It describes representing contexts as vectors of lexical features, reducing dimensionality, and clustering the vectors. Key methods include identifying unigram, bigram and co-occurrence features from corpora using frequency counts and association measures, and representing contexts in first or second order vectors based on feature presence.























































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)













