Download as ODP, PPTX















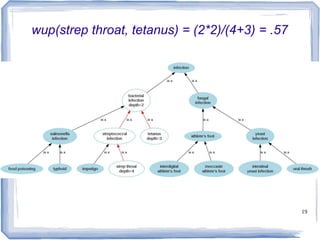
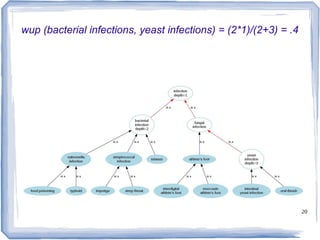

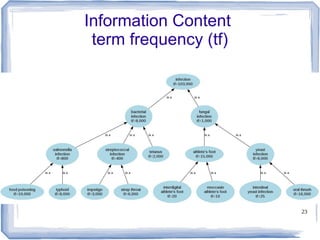
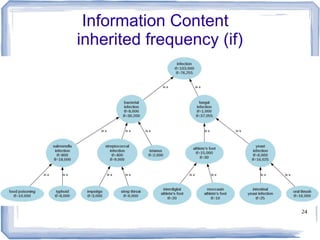
![22
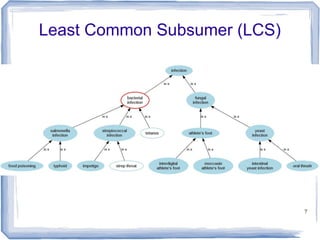
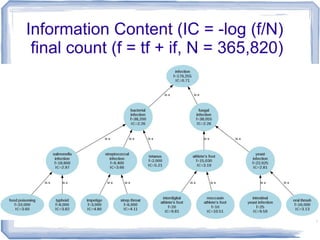
Information Content
● ic(concept) = -log p(concept) [Resnik 1995]
– Need to count concepts
– Term frequency +Inherited frequency
– p(concept) = tf + if / N
● Depth shows specificity but not frequency
● Low frequency concepts often much more
specific than high frequency ones
– Related to Zipf's Law of Meaning? (more
frequent word have more senses)](https://image.slidesharecdn.com/uab-19apr2013-130421173716-phpapp01/85/Talk-at-UAB-April-12-2013-22-320.jpg)







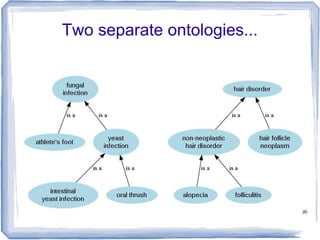
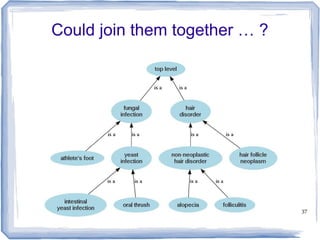
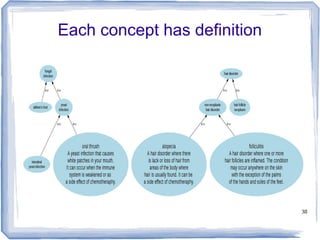
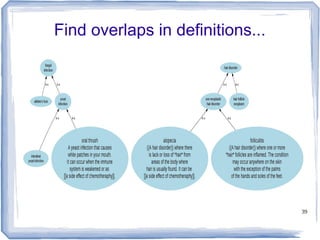











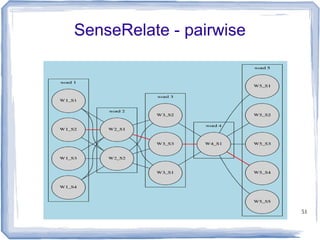
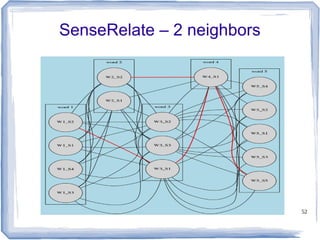



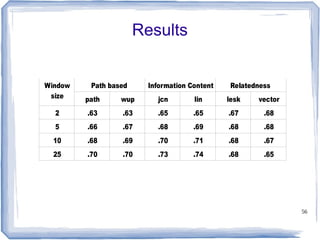

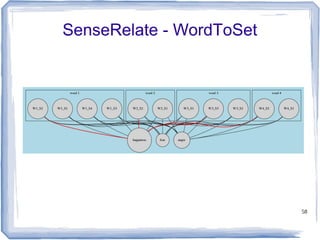











The document discusses methods for measuring semantic similarity and relatedness in the biomedical domain, focusing on concepts rather than words. It covers various techniques using ontologies and corpora, as well as applications like word sense disambiguation and sentiment classification. Additionally, it highlights the availability of free open-source software to facilitate these measurements.



































































