Download as ODP, PPTX
![Measuring Semantic Similarity and Relatedness in the Biomedical Domain : Methods and Applications Ted Pedersen, Ph.D. Department of Computer Science University of Minnesota, Duluth [email_address] http://www.d.umn.edu/~tpederse February 21, 2012](https://image.slidesharecdn.com/feb20-mayo-webinar-21feb2012-120220131555-phpapp02/85/Feb20-mayo-webinar-21feb2012-1-320.jpg)
![Measuring Semantic Similarity and Relatedness in the Biomedical Domain : Methods and Applications Ted Pedersen, Ph.D. Department of Computer Science University of Minnesota, Duluth [email_address] http://www.d.umn.edu/~tpederse February 21, 2012](https://image.slidesharecdn.com/feb20-mayo-webinar-21feb2012-120220131555-phpapp02/75/Feb20-mayo-webinar-21feb2012-1-2048.jpg)






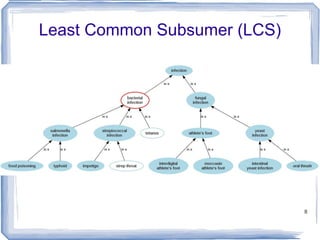






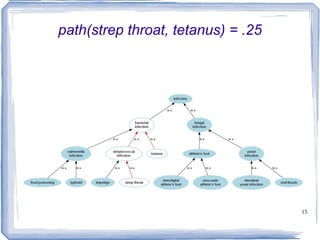
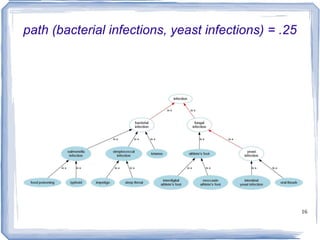



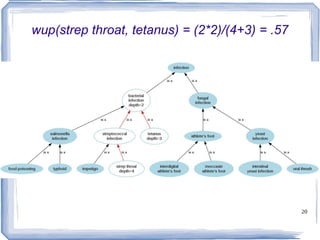
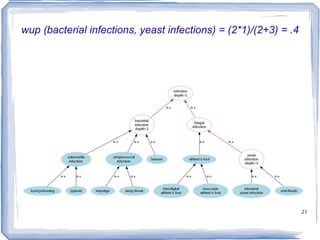


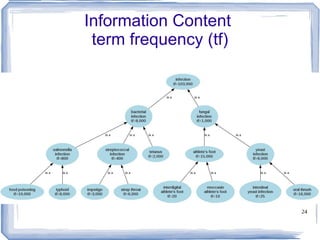
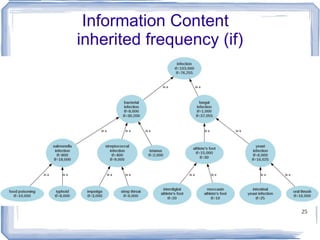
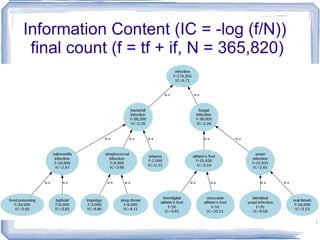

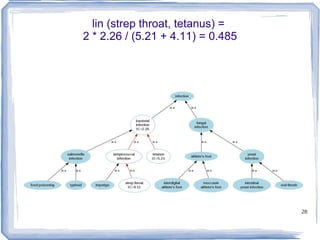
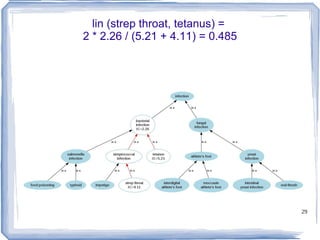
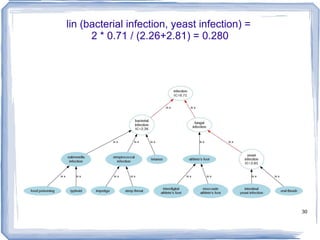





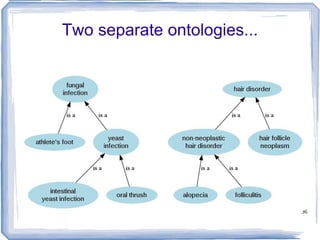
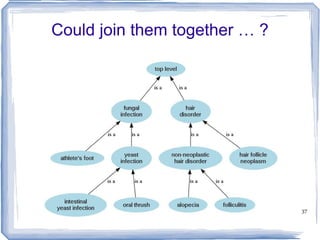
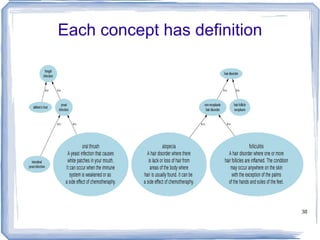
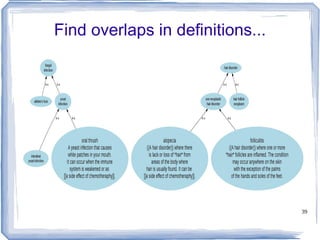











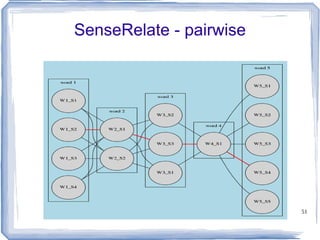
![Information Content ic(concept) = -log p(concept) [Resnik 1995] Need to count concepts](https://image.slidesharecdn.com/feb20-mayo-webinar-21feb2012-120220131555-phpapp02/85/Feb20-mayo-webinar-21feb2012-53-320.jpg)

















The document discusses methods for measuring semantic similarity and relatedness within the biomedical domain, supported by various sources of information such as ontologies, corpora, and definitions. It covers applications like word sense disambiguation and sentiment classification, and introduces several established measures and tools including WordNet and UMLS. Key findings highlight that semantic similarity can be quantified through different methodologies, and a variety of open-source software is available to aid in these assessments.













































































![CASE_PRESENTATION_ON_subdural_hematoma(SDH)[1 FINAL PPT]-1.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/casepresentationonsubduralhematomasdh1finalppt-1-260129172522-d405d375-thumbnail.jpg?width=640&height=640&fit=bounds)






