Downloaded 11 times




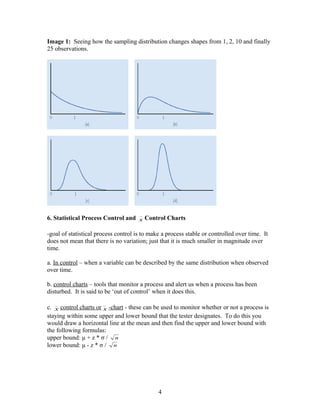



1) This document discusses sampling and sampling distributions, including key terms like population, sample, parameter, statistic, and point estimation. 2) It describes simple random sampling for both finite and infinite populations and introduces the concept of sampling distributions - the probability distributions of sample statistics. 3) The sampling distribution of the mean is discussed, including how it approaches a normal distribution as sample size increases due to the central limit theorem.



































































