














![May 22-25, 2017
San Francisco
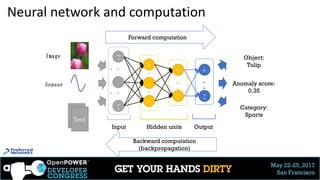
3 types of domain-specific language:
Network definition to computational graph construction
16
▶ Text DSL
▶ Ex. Caffe (prototxt)
▶ Ex. CNTK (NDL)
# Symbolic definition
A = Variable(‘A’)
B = Variable(‘B’)
C = B * A
D = C + Constant(1)
# Compile
f = compile(D)
d = f(A=np.ones(10),
B=np.ones(10) * 2)
# Imperative declaration
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1
%% Definition in text
f: {
“A”: “Variable”,
“B”: “Variable”,
“C”: [“B”, “*”, “A”],
“ret”: [“C”, “+”, 1]
}
# Compile
f = compile(“f.txt”)
d = f(A=np.ones(10),
B=np.ones(10) * 2)
▶ Symbolic program
▶ Operations on
symbols
▶ Ex.Theano
▶ Ex.TensorFlow
▶ Imperative program
▶ Direct computations
on raw data arrays
▶ Ex.Torch.nn
▶ Ex. Chainer
▶ Ex. MXNet](https://image.slidesharecdn.com/chainerdeepdiveopenpowerdevelopercongress20170522ota-170613052833/85/Chainer-OpenPOWER-developer-congress-HandsON-20170522_ota-16-320.jpg)









![May 22-25, 2017
San Francisco
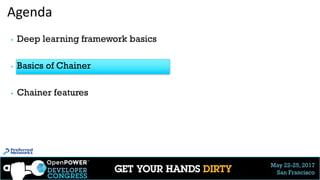
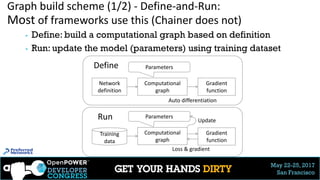
Code sample (3/3): Stochastic Residual Network
28
▶ A variant of Residual Net that skips connections stochastically
▶ Outperformed the original Residual Net (ImageNet 2015 winner, MSR)
▶ Stochastic skip:
Taken from http://arxiv.org/abs/1603.09382v2
G. Huang et al.
# Mock code in Chainer
class StochasticResNet(Chain):
def __init__(self, prob, size, …):
super(StochasticResNet, size, …).__init__(
## Define f[i] as same for Residual Net )
self.p = prob # Survival probabilities
def __call__(self, h):
for i in range(self.size):
b = numpy.random.binomial(1, self.p[i])
c = self.f[i](h) + h if b == 1 else h
h = F.relu(c)
return h
w/ survival probability:](https://image.slidesharecdn.com/chainerdeepdiveopenpowerdevelopercongress20170522ota-170613052833/85/Chainer-OpenPOWER-developer-congress-HandsON-20170522_ota-28-320.jpg)






The document is a presentation about complex neural networks given at the OpenPOWER Developer Congress from May 22-25, 2017 in San Francisco. It discusses Chainer, a deep learning framework that is well-suited for complex neural networks through its unique "define-by-run" approach. This allows computational graphs to be built dynamically during training, increasing flexibility for new algorithm development compared to other frameworks that define static graphs beforehand. Examples are given of convolutional and recurrent neural networks implemented in Chainer's imperative style.






![[html5jロボット部 第7回勉強会] Microsoft Cognitive Toolkit (CNTK) Overview](https://cdn.slidesharecdn.com/ss_thumbnails/20161130cognitivetoolkit-161130233503-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Thomas chamberlain] learning_om_ne_t++(z-lib.org)](https://cdn.slidesharecdn.com/ss_thumbnails/thomaschamberlainlearningomnetz-lib-211009220634-thumbnail.jpg?width=640&height=640&fit=bounds)













































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










