⽂文法圧縮
l 圧縮対象⽂文字列列のみを⽣生成するCFGルールを求めて圧縮
l ルール集合が元の⽂文字列列より短く記述できれば圧縮可能
l 実は先程のRePairは⽂文法圧縮の⼀一種
l CFGルールの求め⽅方で様々な⼿手法が存在
l 最適なCFGルールを⾒見見つけるのはNP困難.近似解の世界で頑張る
l オンライン, ルール作業領領域のみで構築 [Maruyama+, CCP 11]
….
A → ba
D E D F
B → pa
C → ma
文法のみを保存
D → AA
E → BB
A A B B A A C C
F → CC
…
b a b a p a p a b a b a m a m a
14










![連⻑⾧長圧縮
RLE: Run Length Encoding
l 繰り返し⽂文字列列を、(⽂文字、繰り返し⻑⾧長)のペアで表す
l ヒャァァァァァァァアアアウウヴァアアアアアアアアイイイイ
↓
ヒ1ャ1ァ7ア3ウ2ヴ1ァ1ア8イ4
l ⽂文字が⼆二種類の場合は⽂文字は交互なので繰り返し⻑⾧長さだけでOK
0000111100011 → 4432 (例例えば⽩白⿊黒画像データなど)
l 繰り返し数が少ない場合⼤大きくなってしまうので、連⻑⾧長が多い場
合は連⻑⾧長圧縮モード、そうでない場合はそのままと切切り替える [1]
l ⼤大抵は何らかの処理理(BWT, 基底変換)の後に使う場合が多い
l 画像圧縮のDCT後の係数はRLEが使われる
[1] “Adaptive Run-Length / Golomb-Rice Encoding of Quantized Generalized
Gaussian Sources with Unknown Statistics”, H. S. Malvar DCC 06
12](https://image.slidesharecdn.com/okanoharacompression-120621070009-phpapp01/75/comp_pfiseminar-12-2048.jpg)
![RePair
l 最頻する2⽂文字を再帰的に他の⽂文字に置換し、全てが異異なる(か
適当なところまで)繰り返し、置換ルールと置換後⽂文字列列を出⼒力力
l うらにわにわにわにわにわにわにわとりうらうらら
↓にわ を Aに変換
うらAAAAAAAとりうらうらら
↓AA を Bに変換
うらBBBAとりうらうらら
↓うら を Cに変換
CBBBAとりCCら
(にわ, A) (AA, B) (うら, C)
l 実⽤用的にはうまくいくので昔から使われていたが、最近はいろい
ろ証明[1]が出たり、簡潔データ構造の圧縮[2]に使われている
[1] “Re-pair Achieves High-order Entropy”, 13
Navarro+, DCC 08]
[G.
[2] “Practical Compressed Document Retrieval”, [G. Navarro+, SEA 11]](https://image.slidesharecdn.com/okanoharacompression-120621070009-phpapp01/75/comp_pfiseminar-13-2048.jpg)
![⽂文法圧縮
l 圧縮対象⽂文字列列のみを⽣生成するCFGルールを求めて圧縮
l ルール集合が元の⽂文字列列より短く記述できれば圧縮可能
l 実は先程のRePairは⽂文法圧縮の⼀一種
l CFGルールの求め⽅方で様々な⼿手法が存在
l 最適なCFGルールを⾒見見つけるのはNP困難.近似解の世界で頑張る
l オンライン, ルール作業領領域のみで構築 [Maruyama+, CCP 11]
….
A → ba
D E D F
B → pa
C → ma
文法のみを保存
D → AA
E → BB
A A B B A A C C
F → CC
…
b a b a p a p a b a b a m a m a
14](https://image.slidesharecdn.com/okanoharacompression-120621070009-phpapp01/75/comp_pfiseminar-14-2048.jpg)

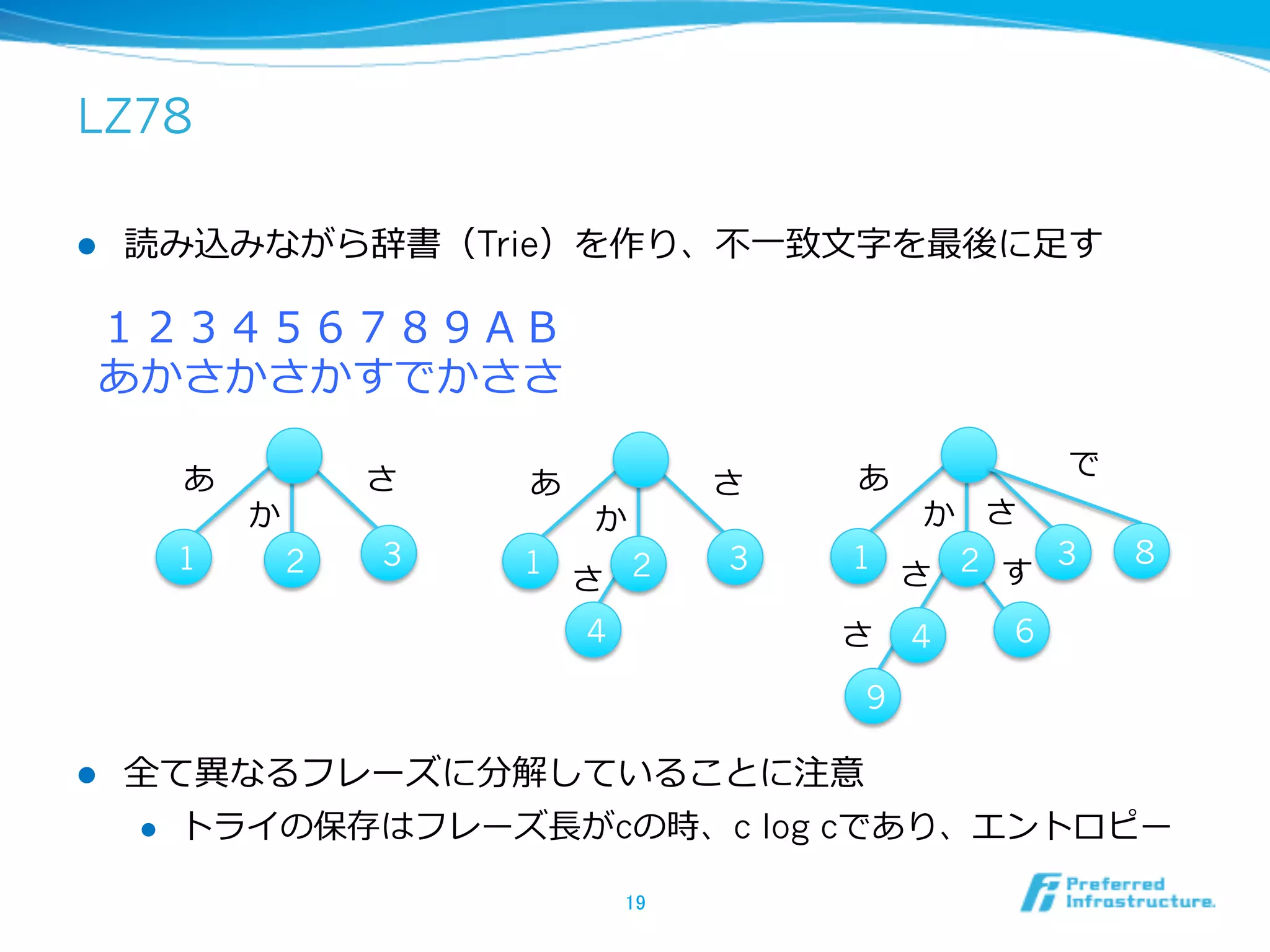
![LZ法これだけは知っといて
l 最適性の証明は⾯面⽩白いが、説明しきれないので分かる⼈人だけ
l ⼊入⼒力力系列列 X = x1x2…xn を分割しフレーズ列列 Y = y1y2…ymを得る
X = [x1x2x3][x4x5][x6x7x8][x9x10]
y1 y2 y3 y4
l この時、フレーズ列列のフレーズ {yi}i=1…m が全て異異なるならば、
c=|Y|とした時、clog2 c はXの情報源のエントロピーに漸近する
l clog2c は各フレーズをそのまま格納したサイズ
l Xのk次経験エントロピーでも成り⽴立立つ
l LZ78は⼊入⼒力力系列列を全て異異なるフレーズ列列に分解する⼀一⼿手法
l LZ77のエントロピー漸近性の証明は別⼿手法
l この証明はLZ以外のデータ構造のサイズ評価にも使われる
16](https://image.slidesharecdn.com/okanoharacompression-120621070009-phpapp01/75/comp_pfiseminar-16-2048.jpg)
![LZ77
l データを先頭から順番に次のように符号化していく.
l 現在位置から始まる記号列列が、過去に出現していれば、
l (出現相対位置, ⼀一致⻑⾧長, 次の不不⼀一致⽂文字)のtripleで置き換える
l していなければ空の⼀一致と次の不不⼀一致⽂文字で表す
l ⼊入⼒力力系列列を全て異異なるフレーズに分解していることに注意
あかさかさかすでかささすで。
あかさ[かさか]すで[かさ]さ[すで]。
(*, *, あ)(*, *, か) (*, *, さ)
(-2, 3,す) (*, *,で) (-5, 2,さ) (-5, 2, 。)
17](https://image.slidesharecdn.com/okanoharacompression-120621070009-phpapp01/75/comp_pfiseminar-17-2048.jpg)


















![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)






















![アルゴリズムのお勉強 アルゴリズムとデータ構造 [素数・文字列探索・簡単なソート]](https://cdn.slidesharecdn.com/ss_thumbnails/random-160606142552-thumbnail.jpg?width=640&height=640&fit=bounds)


























