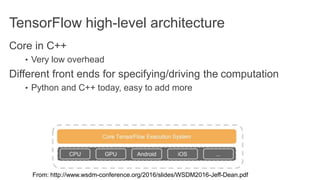
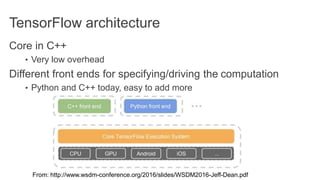
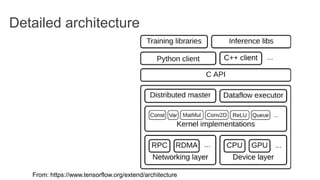
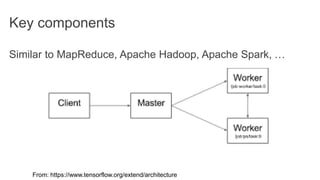
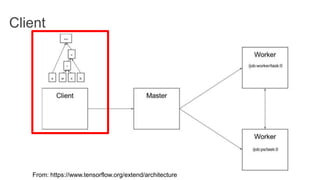
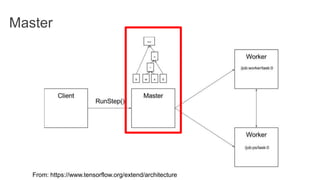
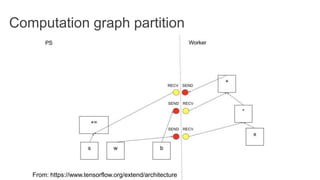
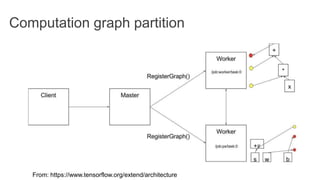
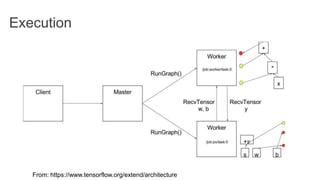
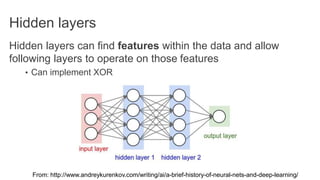
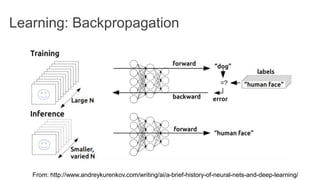
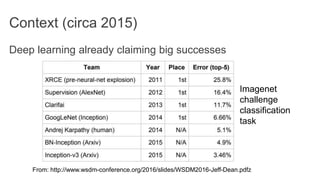
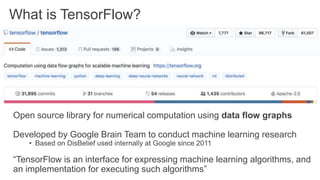
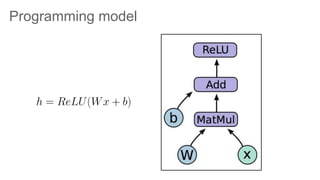
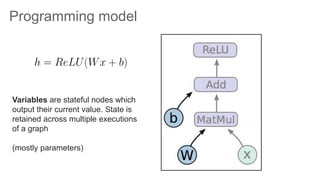
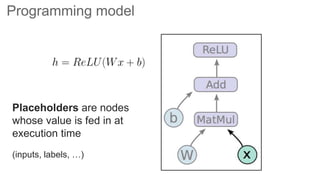
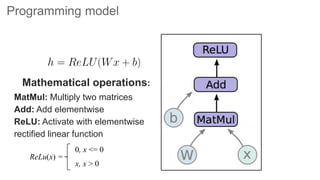
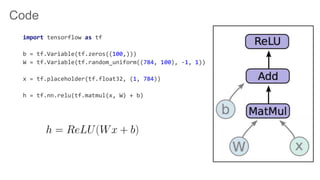
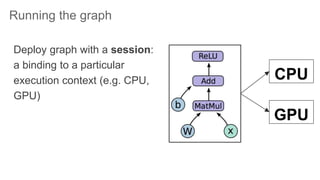
TensorFlow is an open source library for numerical computation using data flow graphs. It allows expressing machine learning algorithms as graphs with nodes representing operations and edges representing the flow of data between nodes. The graphs can then be executed across multiple CPUs and GPUs. Clipper is a system for low latency online prediction serving built using TensorFlow. It aims to handle high query volumes for complex machine learning models.








![Defining loss
Use placeholder for labels
Build loss node using labels and prediction
prediction = tf.nn.softmax(...) #Output of neural network
label = tf.placeholder(tf.float32, [100, 10])
cross_entropy = -tf.reduce_sum(label * tf.log(prediction), axis=1)](https://image.slidesharecdn.com/24-tensorflow-clipper-240214134225-d912f07e/85/24-TensorFlow-Clipper-pptxnjjjjnjjjjjjmm-20-320.jpg)