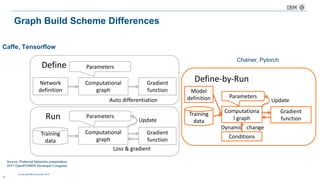
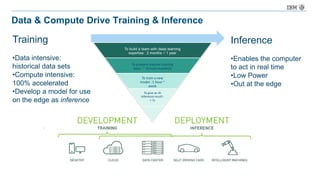
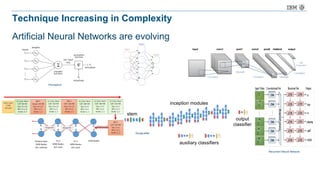
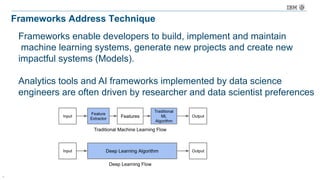
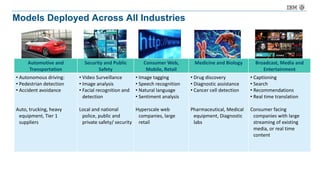
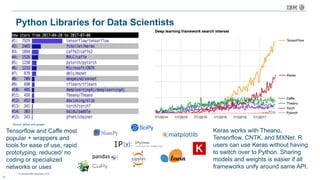
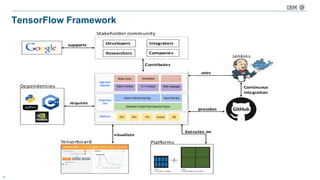
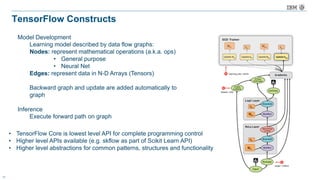
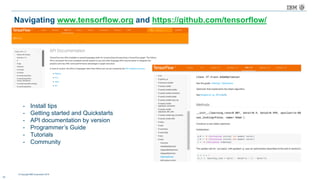
The document discusses a deep learning lecture by IBM, focusing on the TensorFlow framework and its growing popularity among data scientists due to its capabilities and extensive community support. It covers various frameworks, comparing their features and use cases, highlighting the significant impact of AI across multiple industries. Additionally, it addresses challenges in deep learning scalability and flexibility, emphasizing the need for effective distributed systems for optimal performance.











![© Copyright IBM Corporation 2016
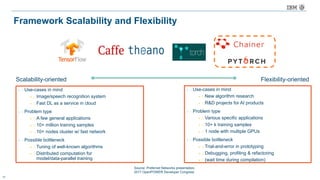
Flexibility: Comparison of Domain Specific Language type
21
DSL type Example Pros. Cons.
Text DSL
Caffe (prototext), CNTK (NDL)
f: {
“A”: “Variable”,
“B”: “Variable”,
“C”: [“B”, “*”, “A”],
“ret”: [“C”, “+”, 1]
}
• Human-readable definition
• Non-programmer can easily
edit the network
• Users must study the format
• Format might have to be
extended for new algorithms
Internal DSL
Symbolic
Tensorflow, Theano
A = Variable(‘A’)
B = Variable(‘B’)
C = B * A
D = C + Constant(1)
• Static analysis at compile
• Optimization before training
• Easy to parallelize
• Users must study special
syntax
• May need more efforts to
implement new algorithms
Imperative
Torch, Chainer
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1
• Less efforts to learn syntax
• Easy debugging and profiling
• Suitable for new algorithms
with complex logic
• Hard to optimize in advance
• Less efficient in memory
allocation and parallelization
Source: Preferred Networks presentation,
2017 OpenPOWER Developer Congress](https://image.slidesharecdn.com/meetuppresentationtensorflowfinaloct262017-171101201124/85/Austin-TX-Meetup-presentation-tensorflow-final-oct-26-2017-22-320.jpg)