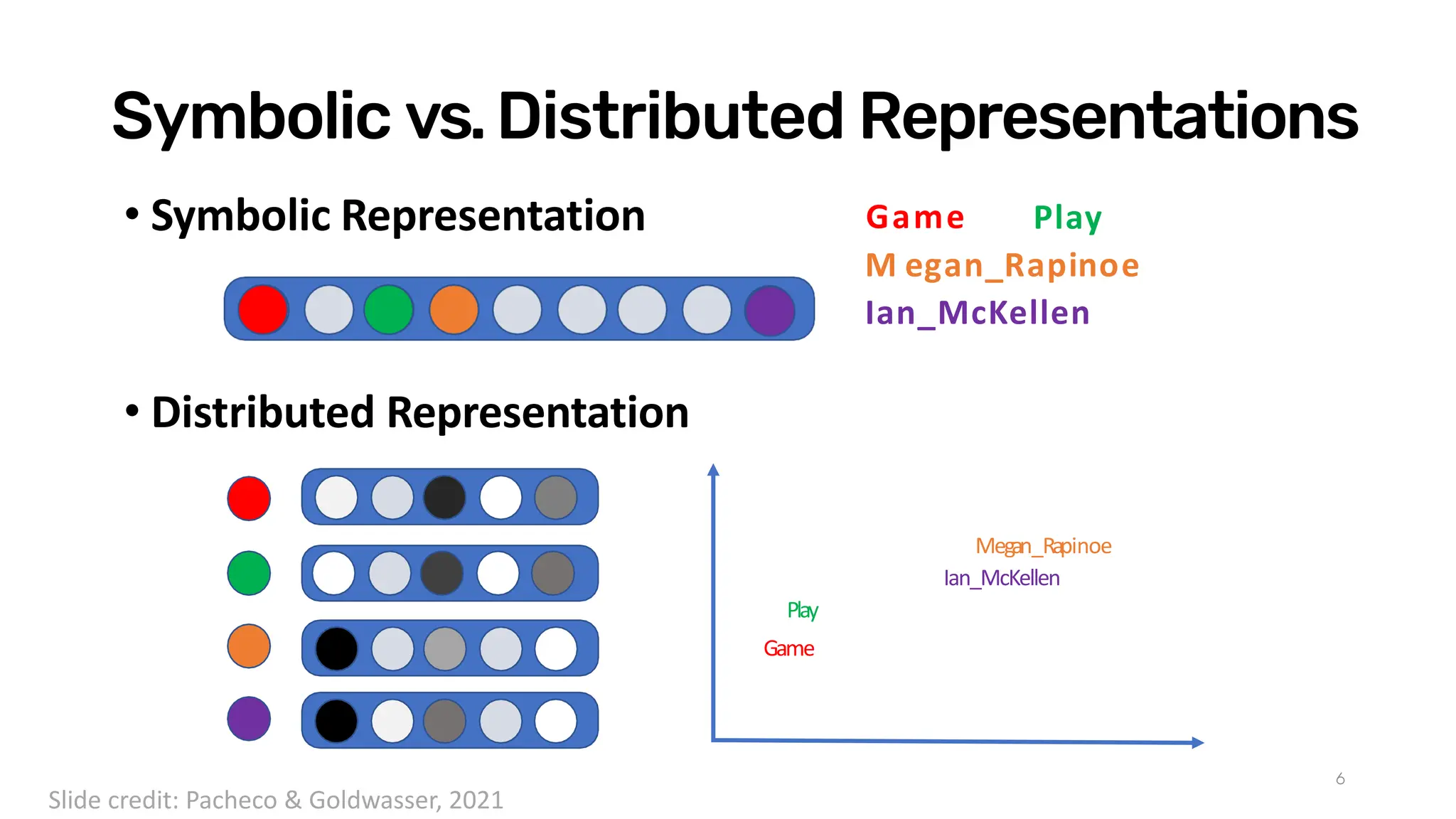
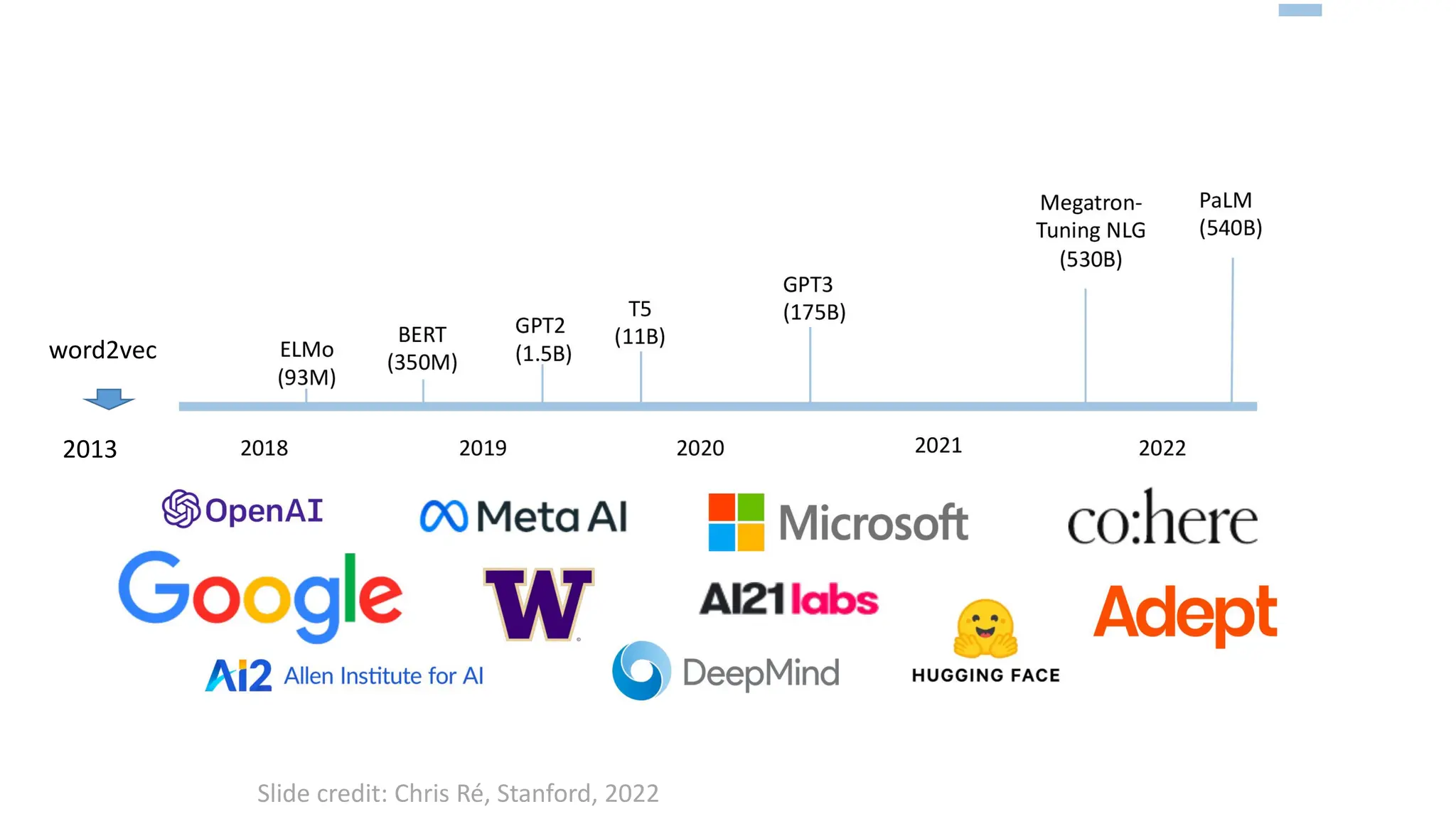
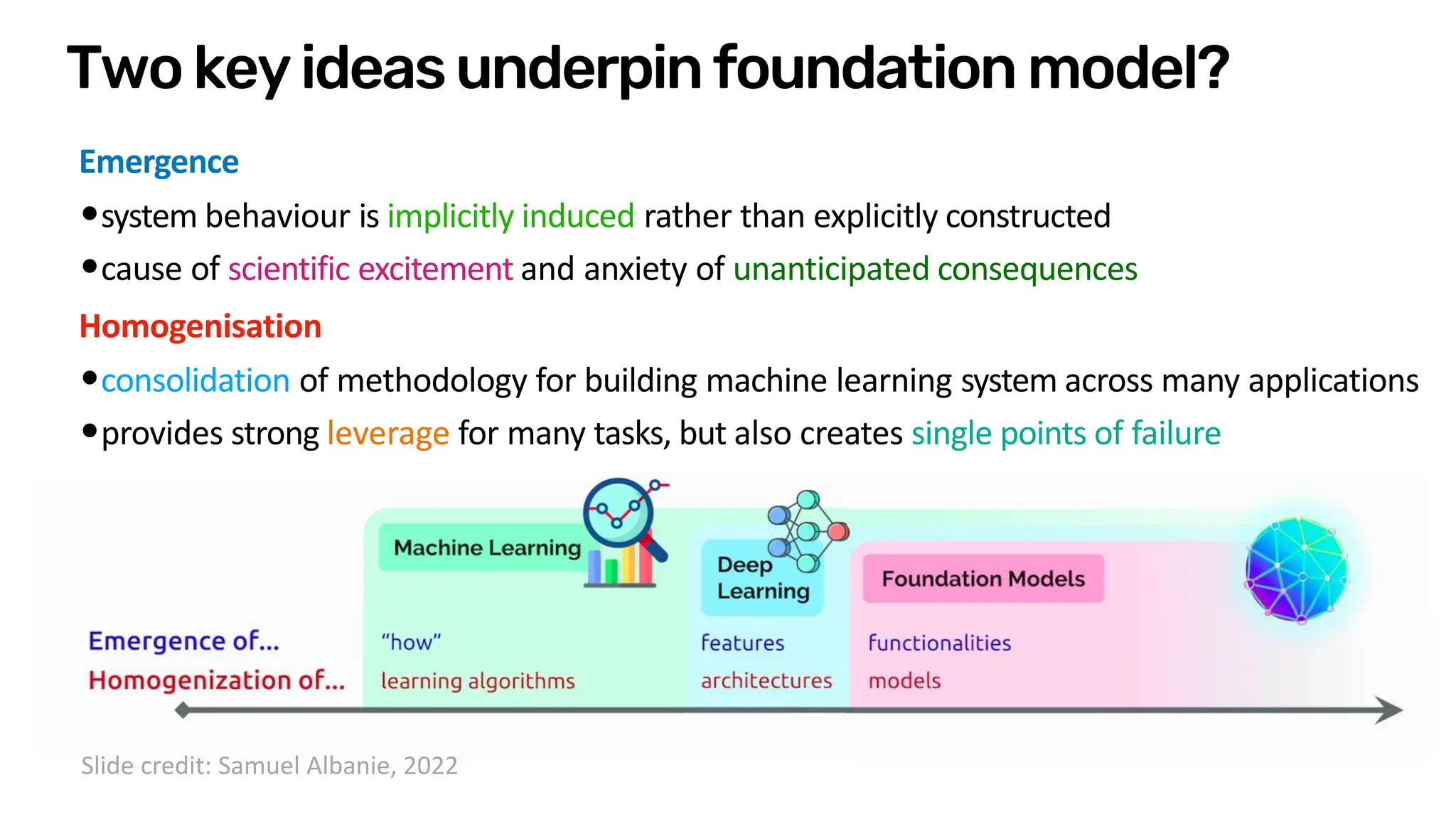
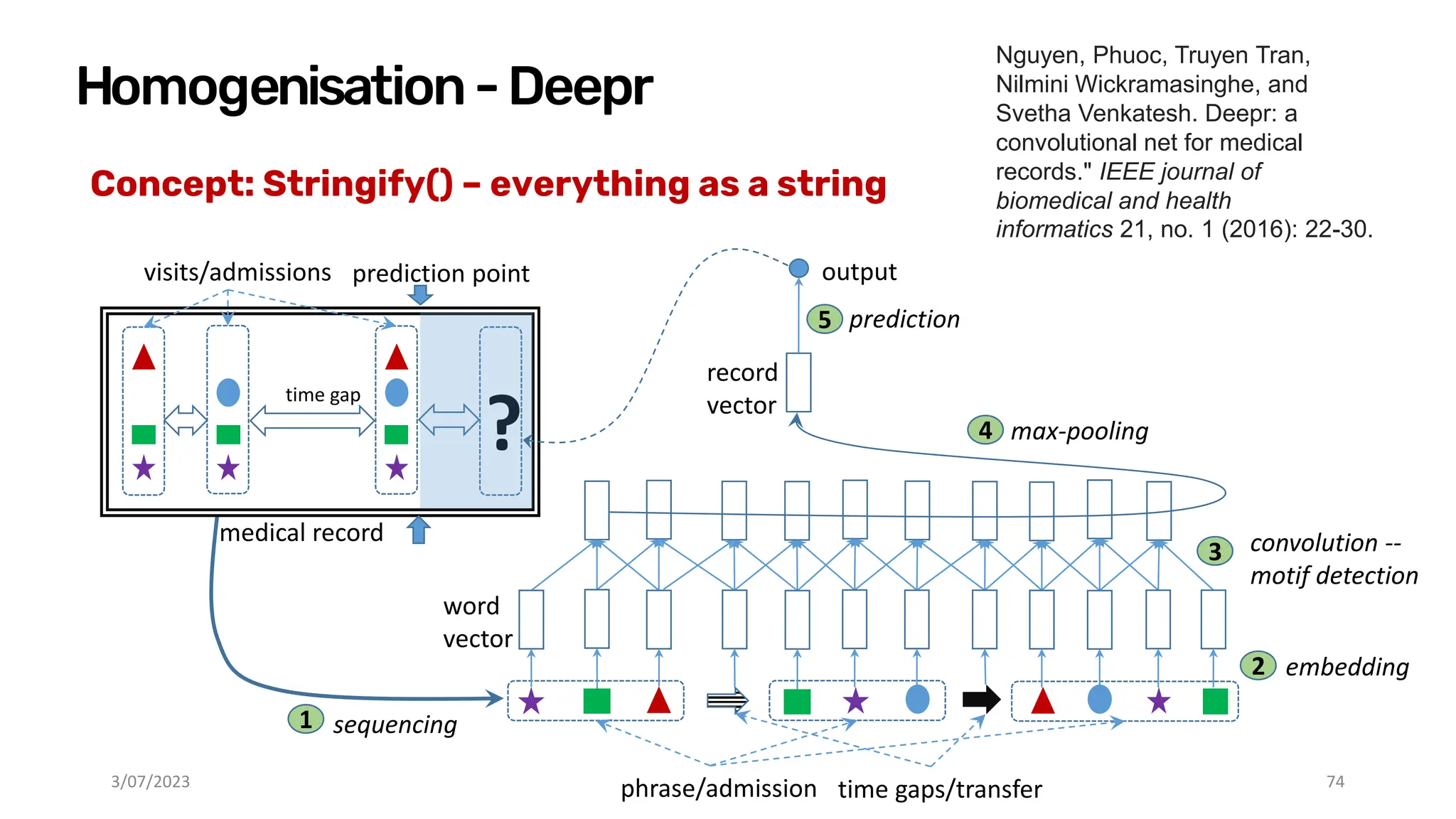
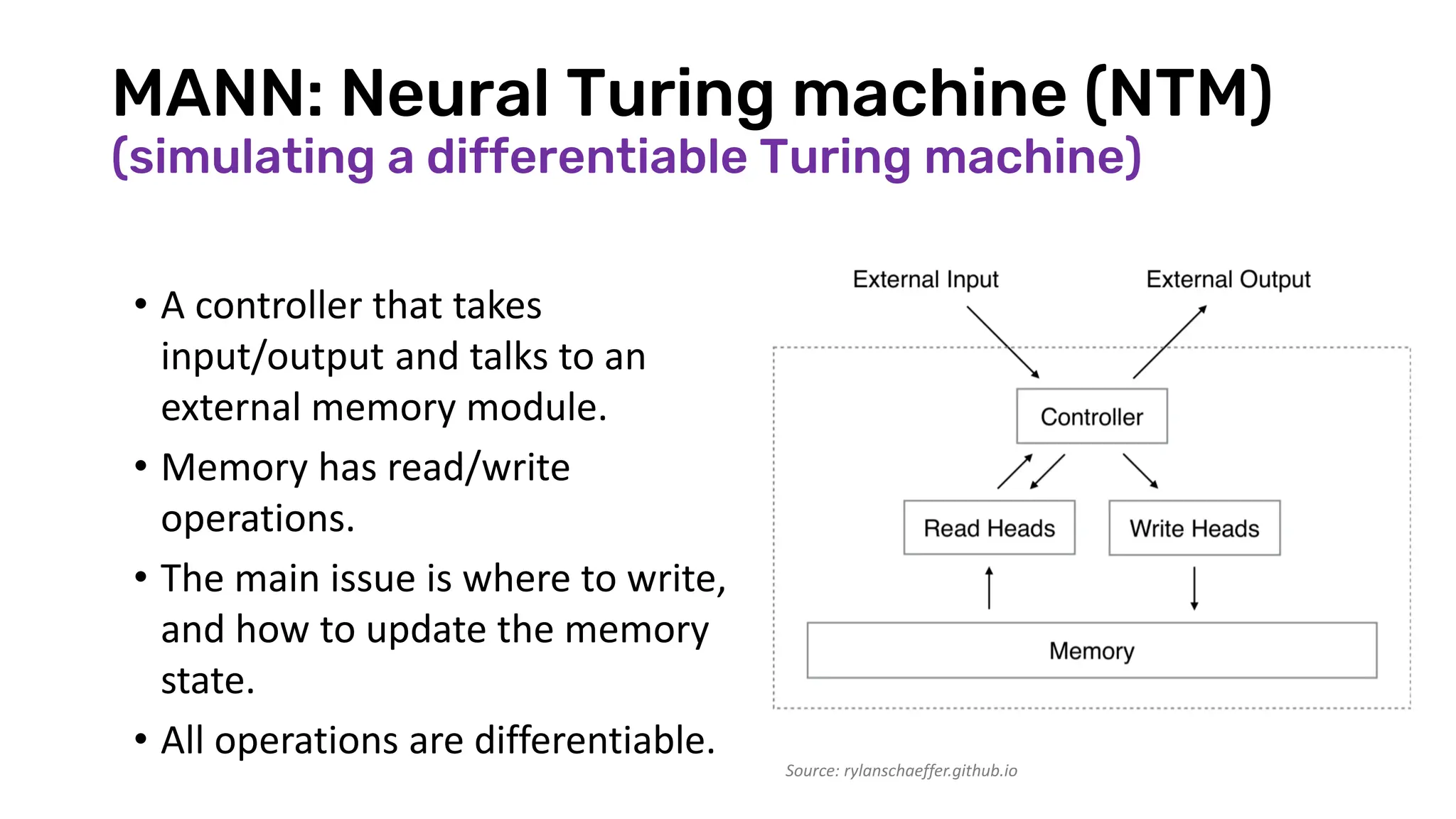
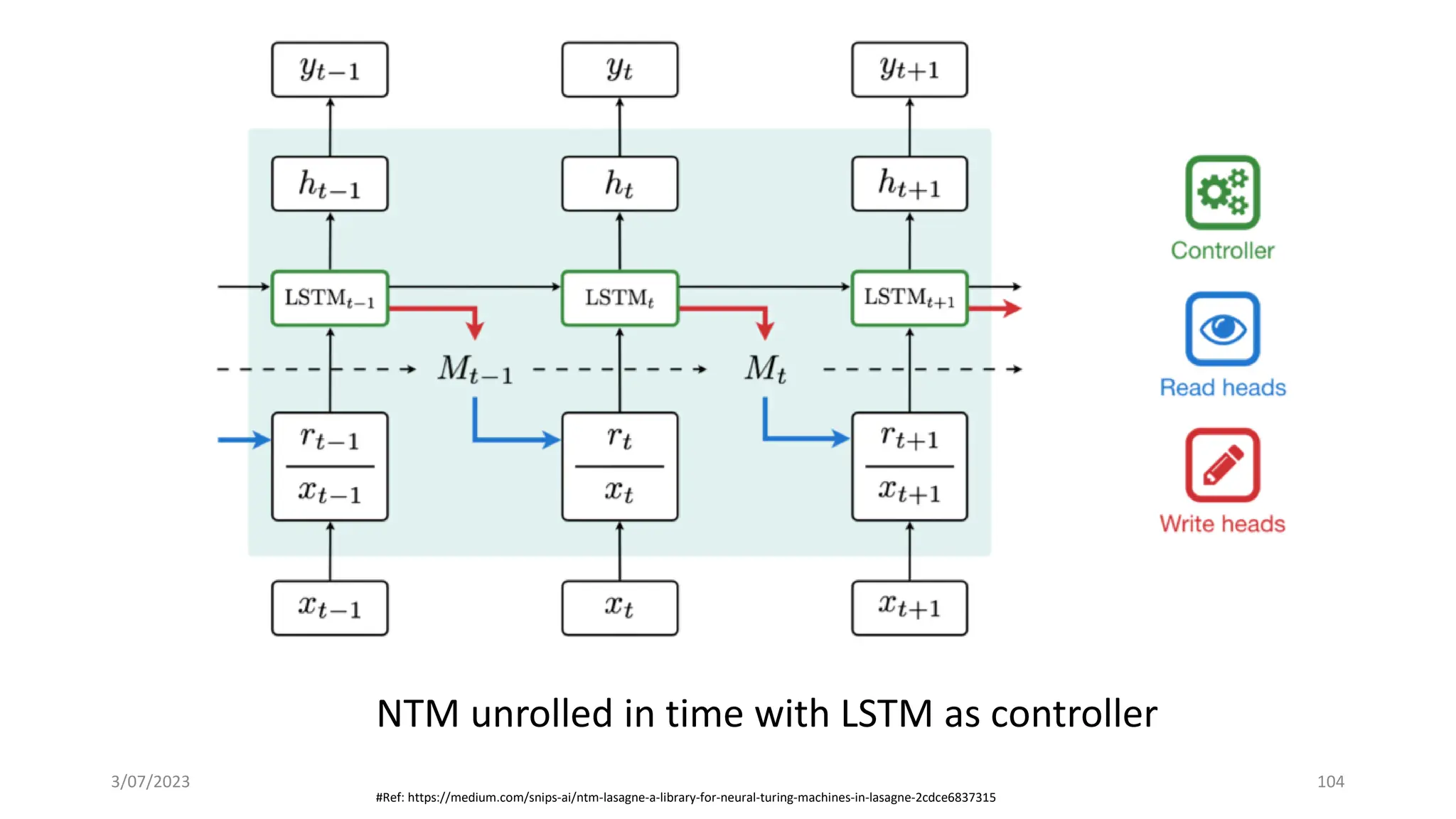
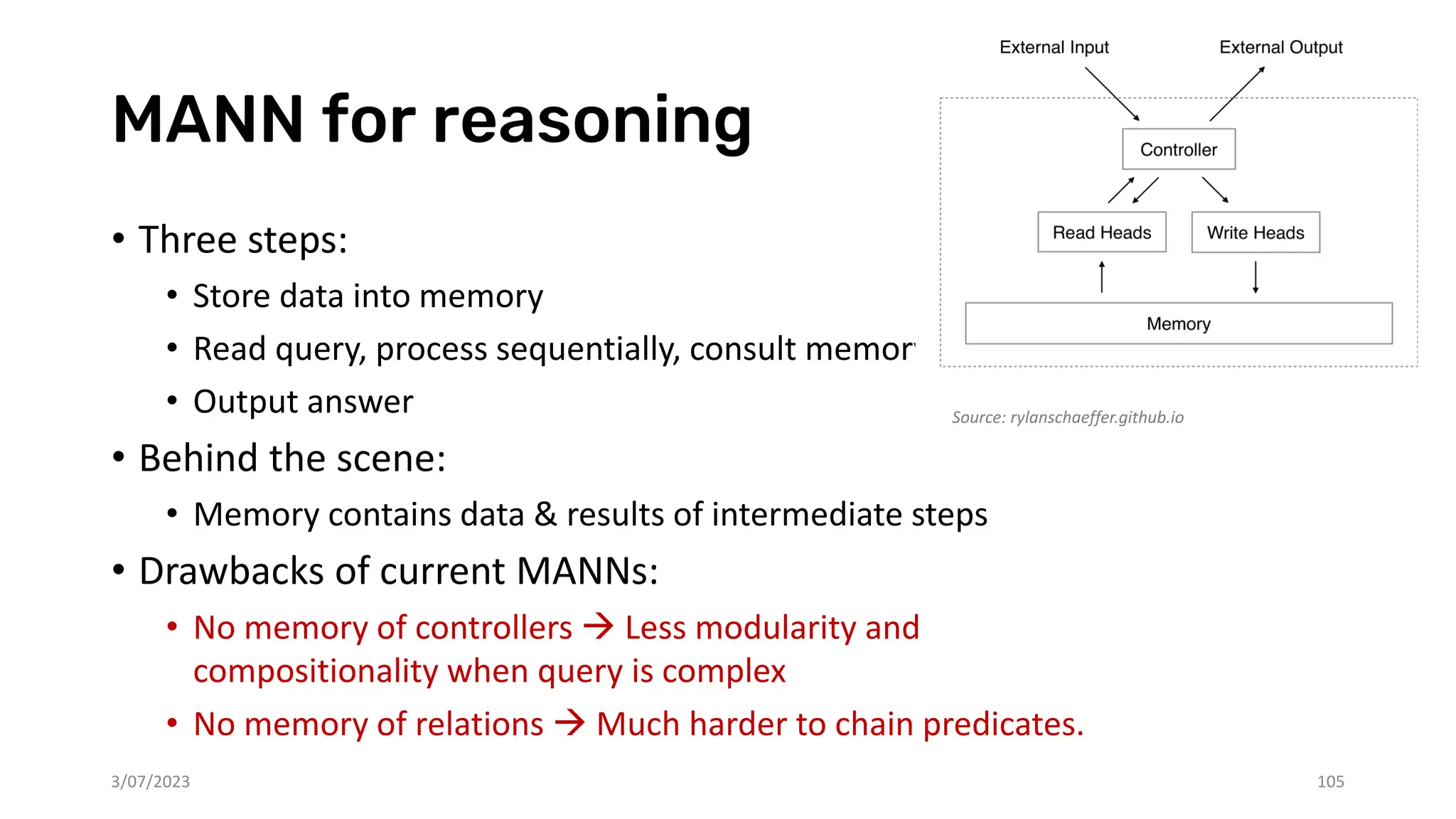
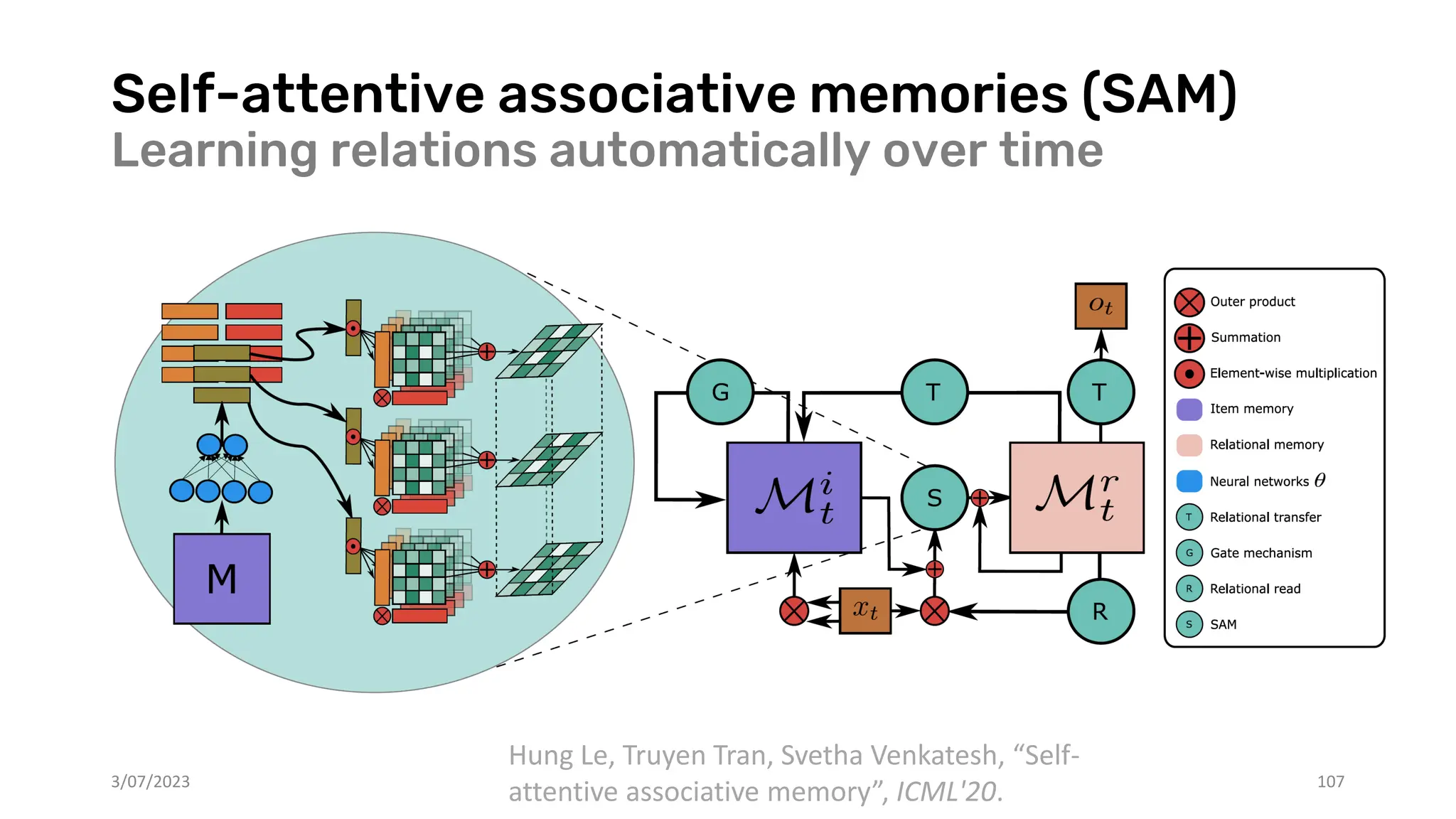
Download as PDF, PPTX



![3/07/2023 5
“[By 2023] …
Emergence of the
generally agreed upon
"next big thing" in AI
beyond deep learning.”
Rodney Brooks
rodneybrooks.com
“[…] general-purpose computer
programs, built on top of far richer
primitives than our current
differentiable layers—[…] we will
get to reasoning and abstraction,
the fundamental weakness of
current models.”
Francois Chollet
blog.keras.io
“Software 2.0 is written in
neural network weights”
Andrej Karpathy
medium.com/@karpathy](https://image.slidesharecdn.com/dl-2023-tt-truyen-231207060156-261341bc/75/Deep-learning-and-reasoning-Recent-advances-5-2048.jpg)








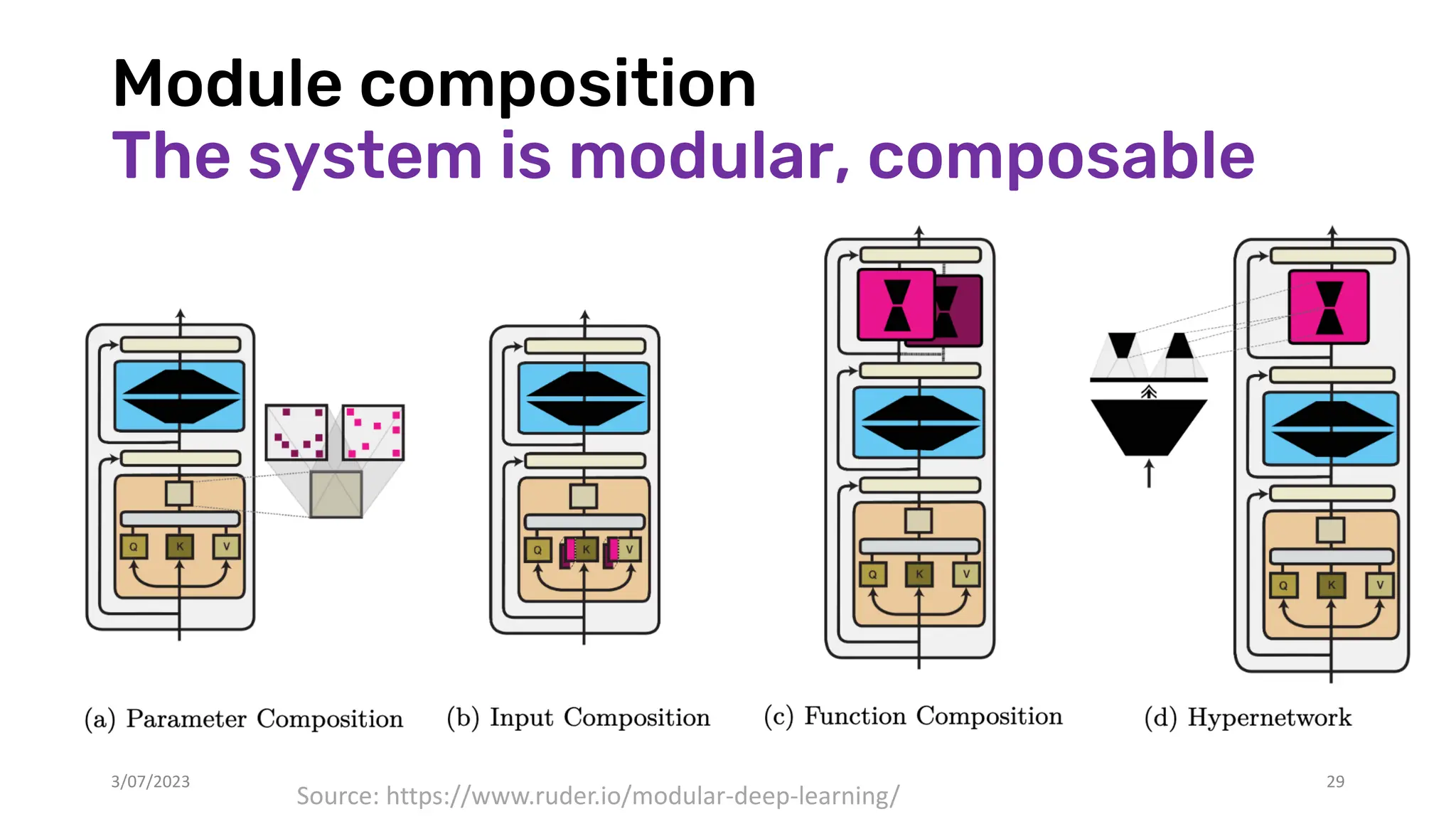
















![Why not just neural reasoning?
Central to reasoning is composition rules to guide the combinations of modules to
address new tasks
Bottou:
• Reasoning is not necessarily achieved by making logical inferences
• There is a continuity between [algebraically rich inference] and [connecting
together trainable learning systems]
→Neural networks are a plausible candidate!
→But still not natural to represent abstract discrete concepts and relations.
Hinton/Bengio/LeCun: Neural networks can do everything!
The rest: Not so fast! => Neurosymbolic systems!
3/07/2023 84
Bottou, Léon. "From machine learning to machine
reasoning." Machine learning 94.2 (2014): 133-149.](https://image.slidesharecdn.com/dl-2023-tt-truyen-231207060156-261341bc/75/Deep-learning-and-reasoning-Recent-advances-84-2048.jpg)















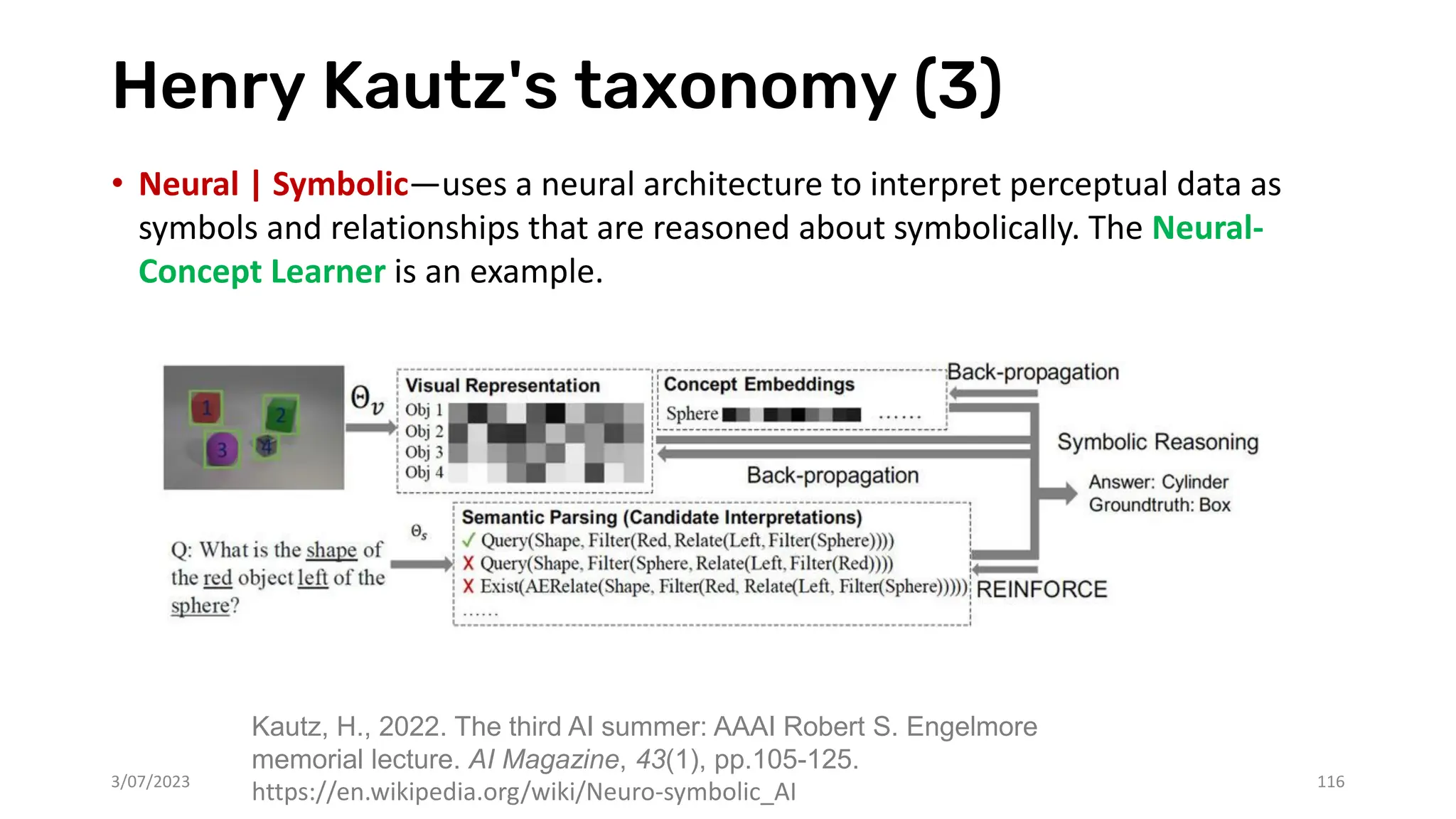
![Henry Kautz's taxonomy (2)
• Symbolic[Neural]—is exemplified by
AlphaGo, where symbolic techniques are
used to call neural techniques. In this case,
the symbolic approach is Monte Carlo tree
search and the neural techniques learn
how to evaluate game positions.
3/07/2023 115
Kautz, H., 2022. The third AI summer: AAAI Robert S. Engelmore
memorial lecture. AI Magazine, 43(1), pp.105-125.
https://en.wikipedia.org/wiki/Neuro-symbolic_AI](https://image.slidesharecdn.com/dl-2023-tt-truyen-231207060156-261341bc/75/Deep-learning-and-reasoning-Recent-advances-115-2048.jpg)
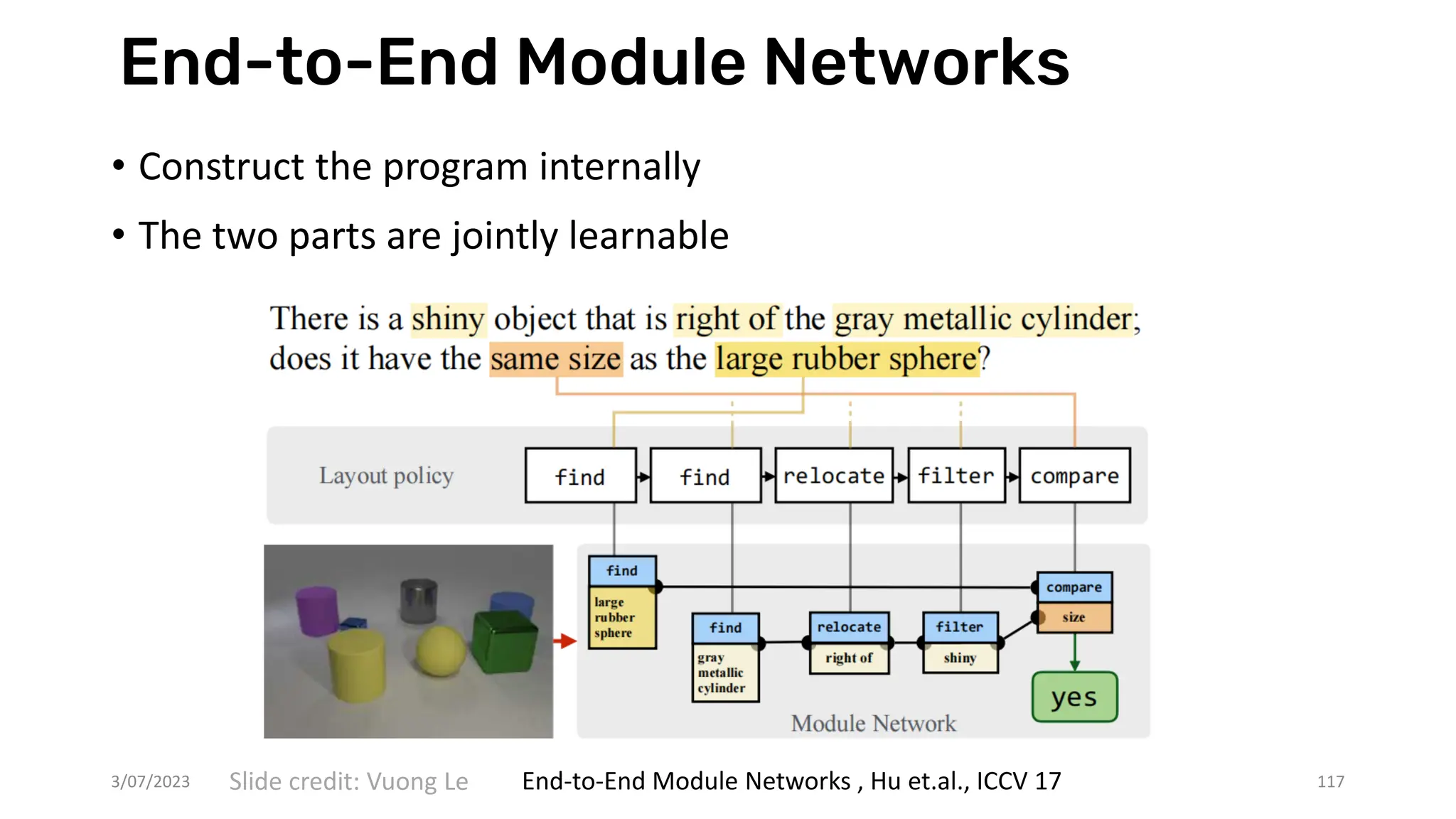

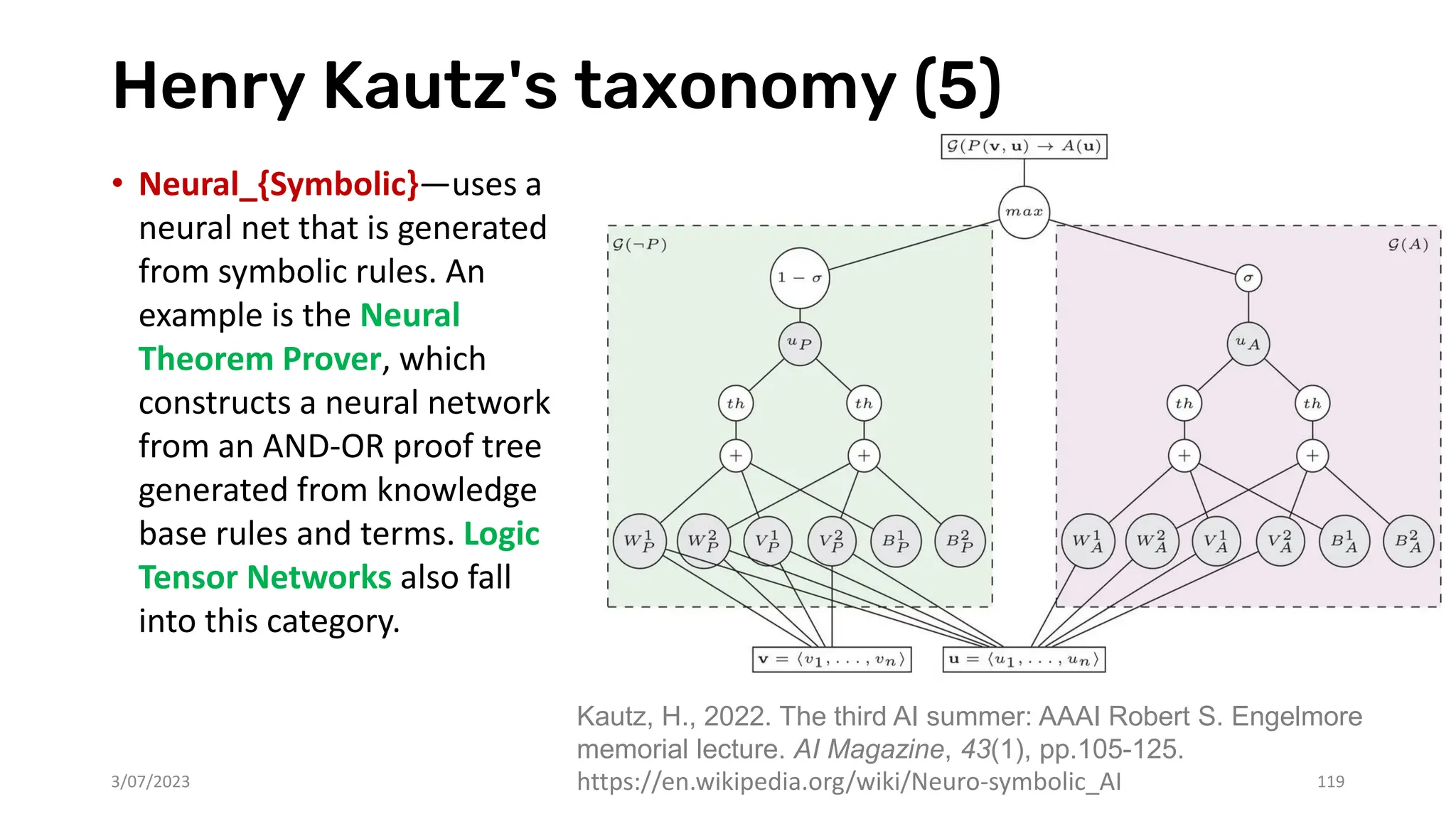
![Henry Kautz's taxonomy (6)
• Neural[Symbolic]—allows a
neural model to directly call a
symbolic reasoning engine, e.g.,
to perform an action or evaluate
a state. An example would be
ChatGPT using a plugin to query
Wolfram Alpha.
3/07/2023 120
Kautz, H., 2022. The third AI summer: AAAI Robert S. Engelmore
memorial lecture. AI Magazine, 43(1), pp.105-125.
https://en.wikipedia.org/wiki/Neuro-symbolic_AI](https://image.slidesharecdn.com/dl-2023-tt-truyen-231207060156-261341bc/75/Deep-learning-and-reasoning-Recent-advances-120-2048.jpg)
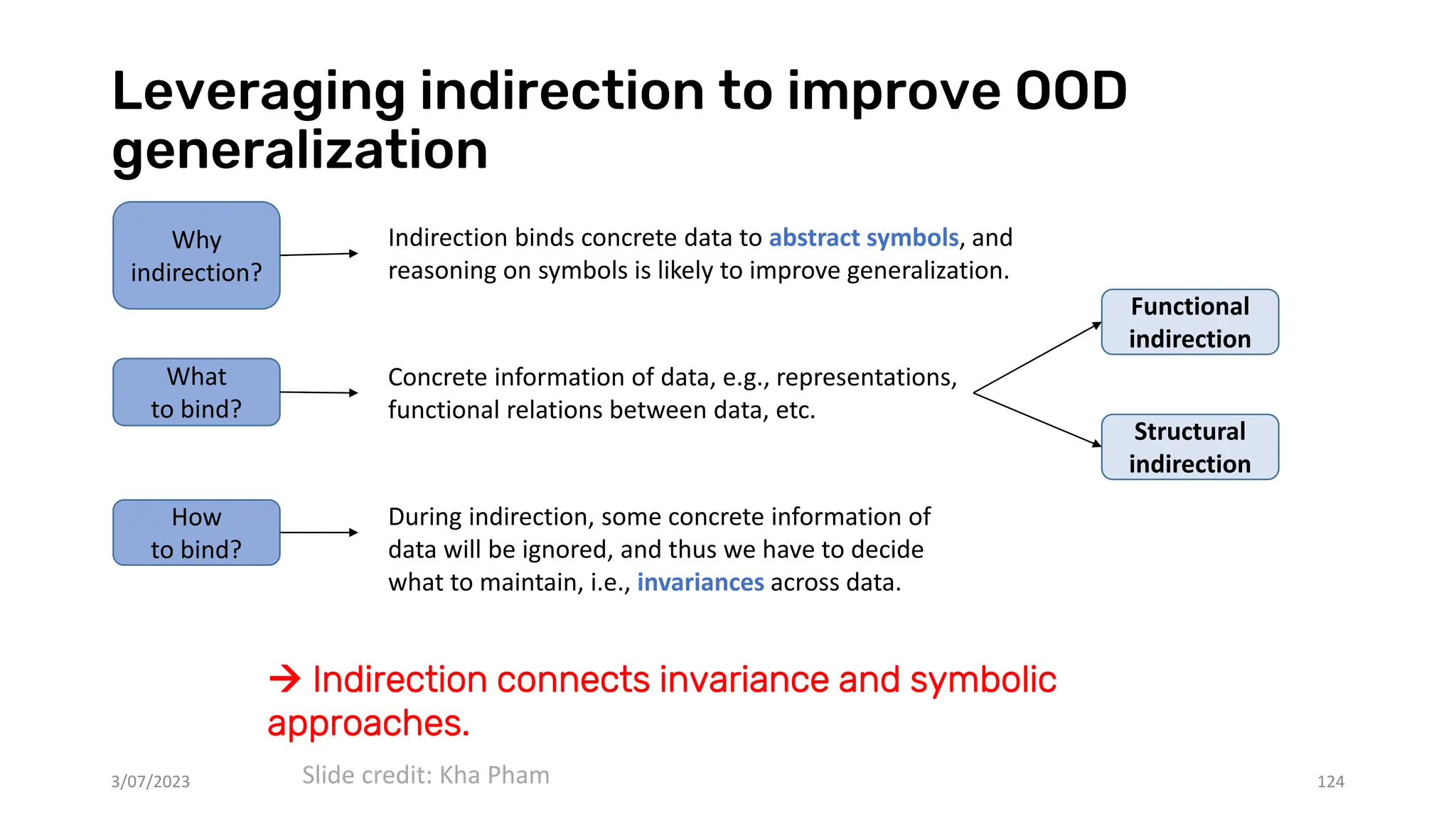

![Structure-Mapping Theory (SMT)
3/07/2023 126
• Improve previous theories of analogy, i.e. the
Tversky’s contrast theory, which assumed that an
analogy is stronger if the more attributes the base
and target share in common.
• SMT [1] argued that it is not object attributes
which are mapped in an analogy, but relationships
between objects. X12 star system Solar system
similarity
Hydrogen atom
analogy
Rutherford’s analogy
No.
attributes
mapped
No.
relations
mapped
Literal
similarity
Many Many
Analogy Few Many
[1] Gentner, Dedre. "Structure-mapping: A theoretical framework for analogy." Cognitive science 7.2 (1983): 155-170.
Slide credit: Kha Pham](https://image.slidesharecdn.com/dl-2023-tt-truyen-231207060156-261341bc/75/Deep-learning-and-reasoning-Recent-advances-126-2048.jpg)
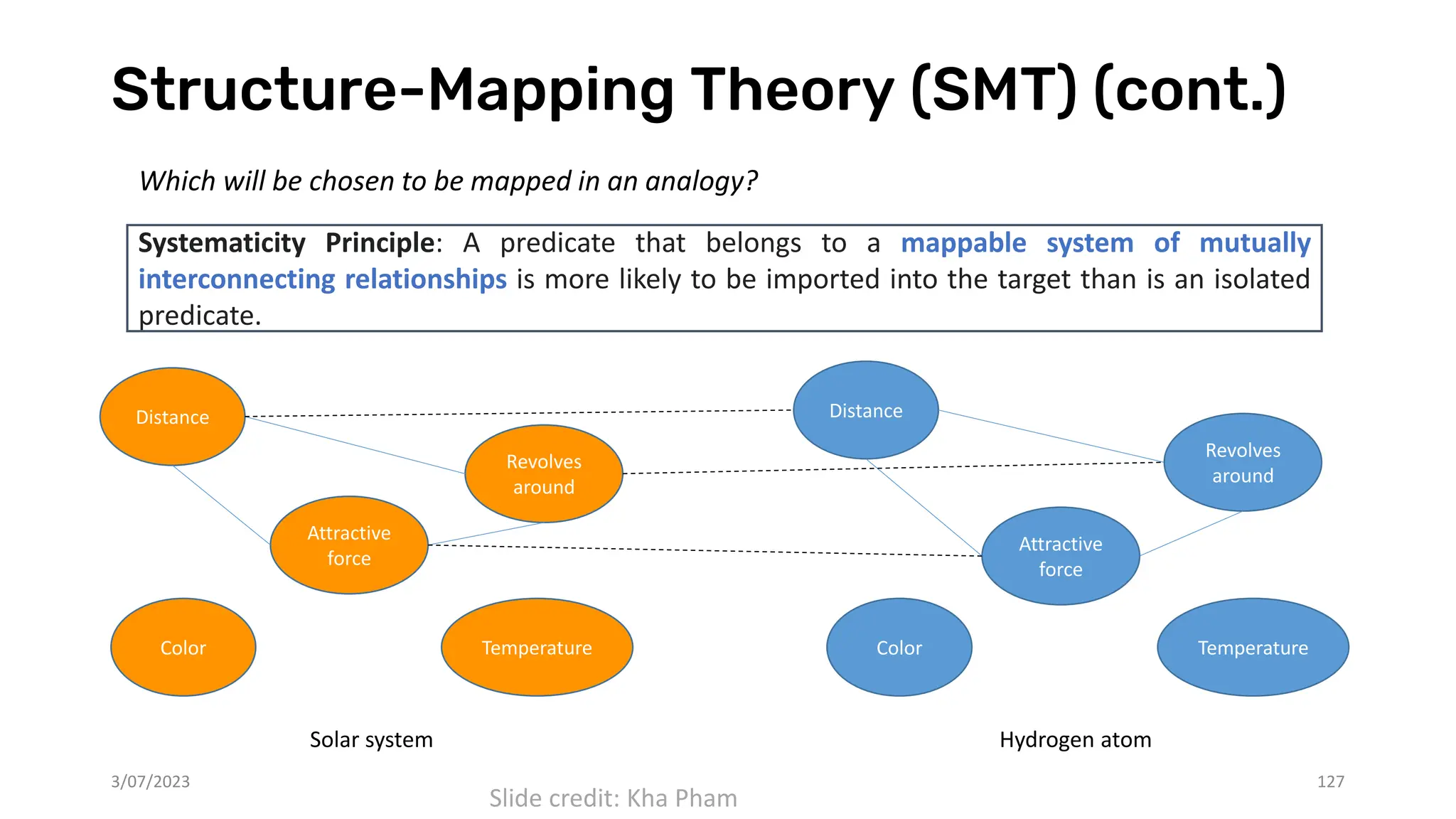
![Experiments on IQ datasets – RAVEN dataset
3/07/2023 129
An IQ problem in RAVEN [1] dataset
Model Accuracy
LSTM 30.1/39.2
Transformers 15.1/42.5
RelationNet 12.5/46.4
PrediNet 13.8/15.6
Average test accuracies (%) without/with InLay in
different OOD testing scenarios on RAVEN
[1] Zhang, Chi, et al. "Raven: A dataset for relational and analogical visual reasoning."
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
• The original paper of RAVEN dataset proposes
different OOD testing scenarios, in which models
are trained on one configuration and tested on
another (but related) configuration.
Slide credit: Kha Pham](https://image.slidesharecdn.com/dl-2023-tt-truyen-231207060156-261341bc/75/Deep-learning-and-reasoning-Recent-advances-129-2048.jpg)
![Experiments on OOD image classification tasks
3/07/2023 130
Dog Dog?
OOD image classification,
in which test images are distorted.
• When test images are injected with different kinds
of distortions other than ones in training, deep
neural networks may fail drastically in image
classification tasks. [1]
[1] Robert Geirhos, Carlos RM Temme, Jonas Rauber, Heiko H Schütt, Matthias Bethge, and
Felix A Wichmann. Generalisation in humans and deep neural networks. Advances in neural
information processing systems, 31, 2018.
Dataset ViT accuracy
SVHN 65.9/68.8
CIFAR10 38.2/43.1
CIFAR100 17.1/20.4
Average test accuracies (%) without/with InLay of Vision
Transformers (ViT) on different types of distortions
Slide credit: Kha Pham](https://image.slidesharecdn.com/dl-2023-tt-truyen-231207060156-261341bc/75/Deep-learning-and-reasoning-Recent-advances-130-2048.jpg)
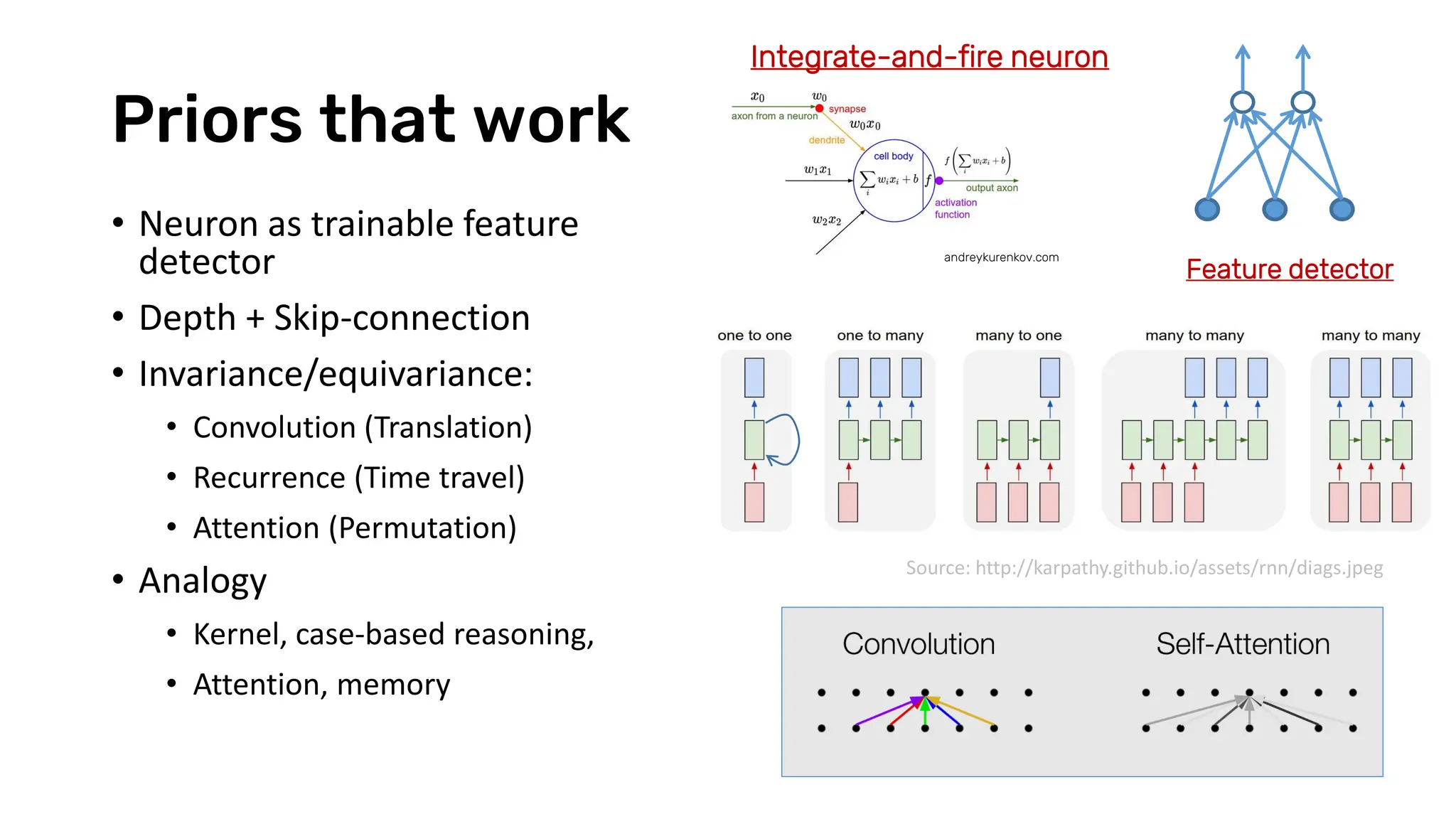



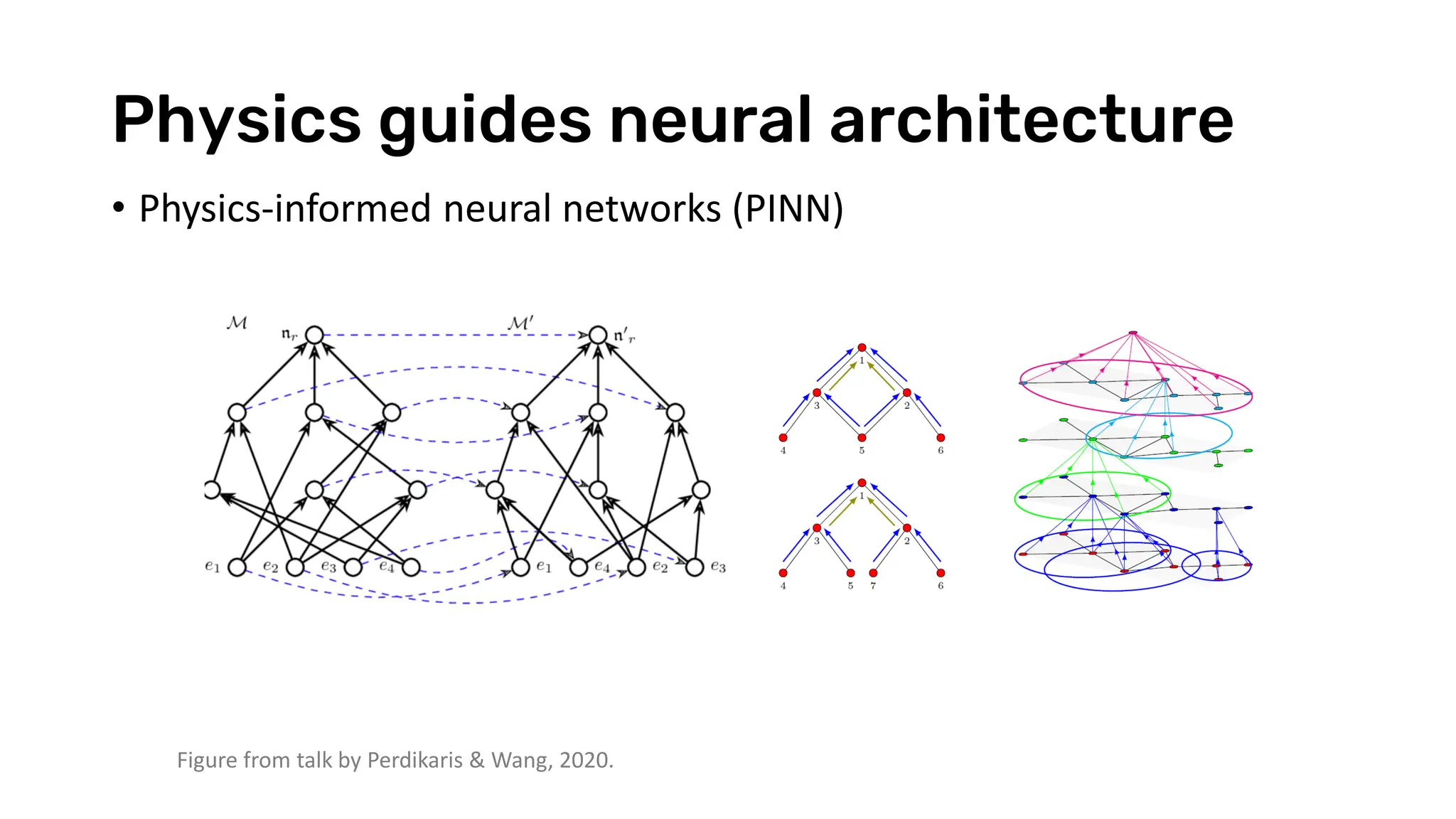
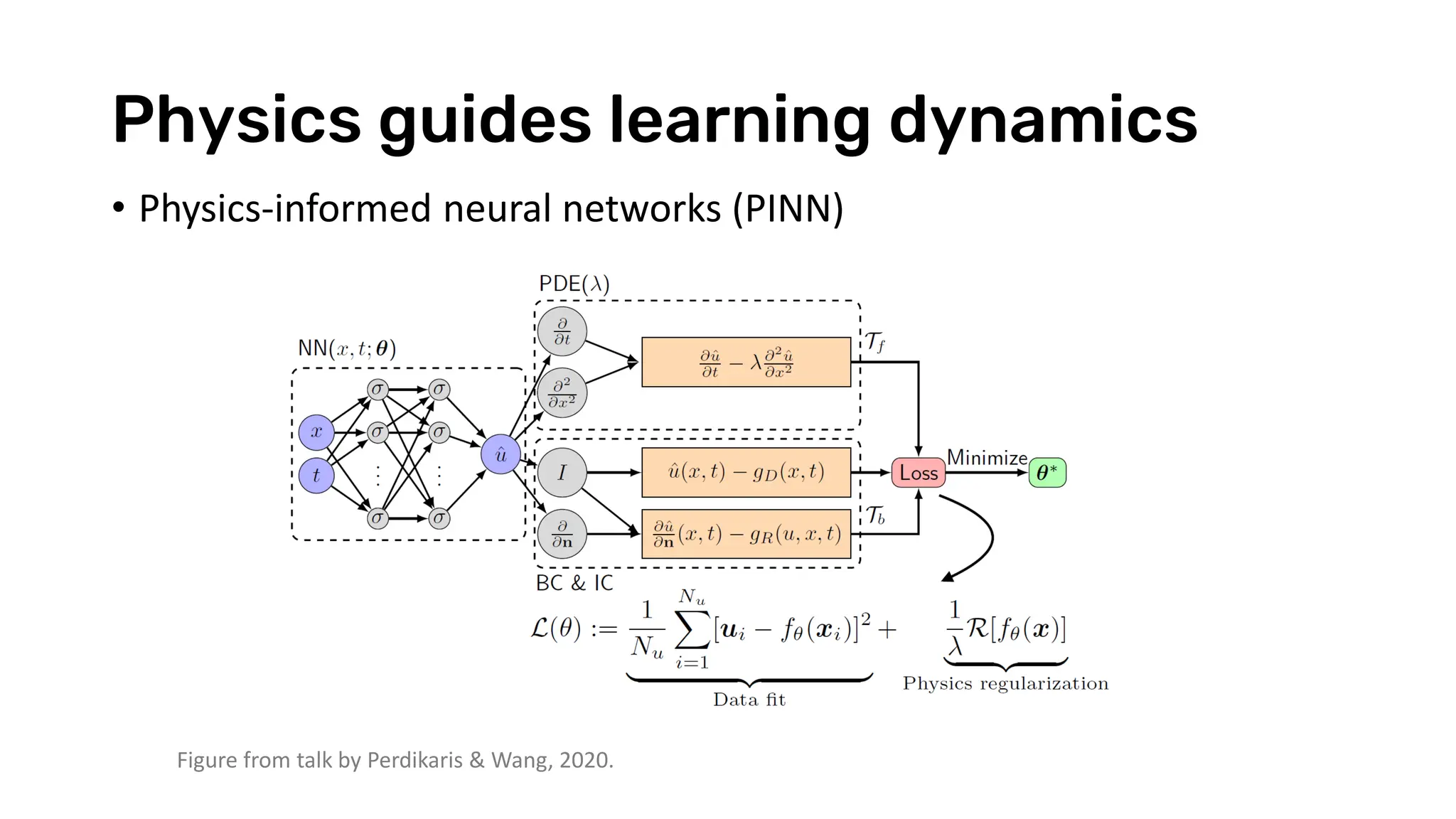
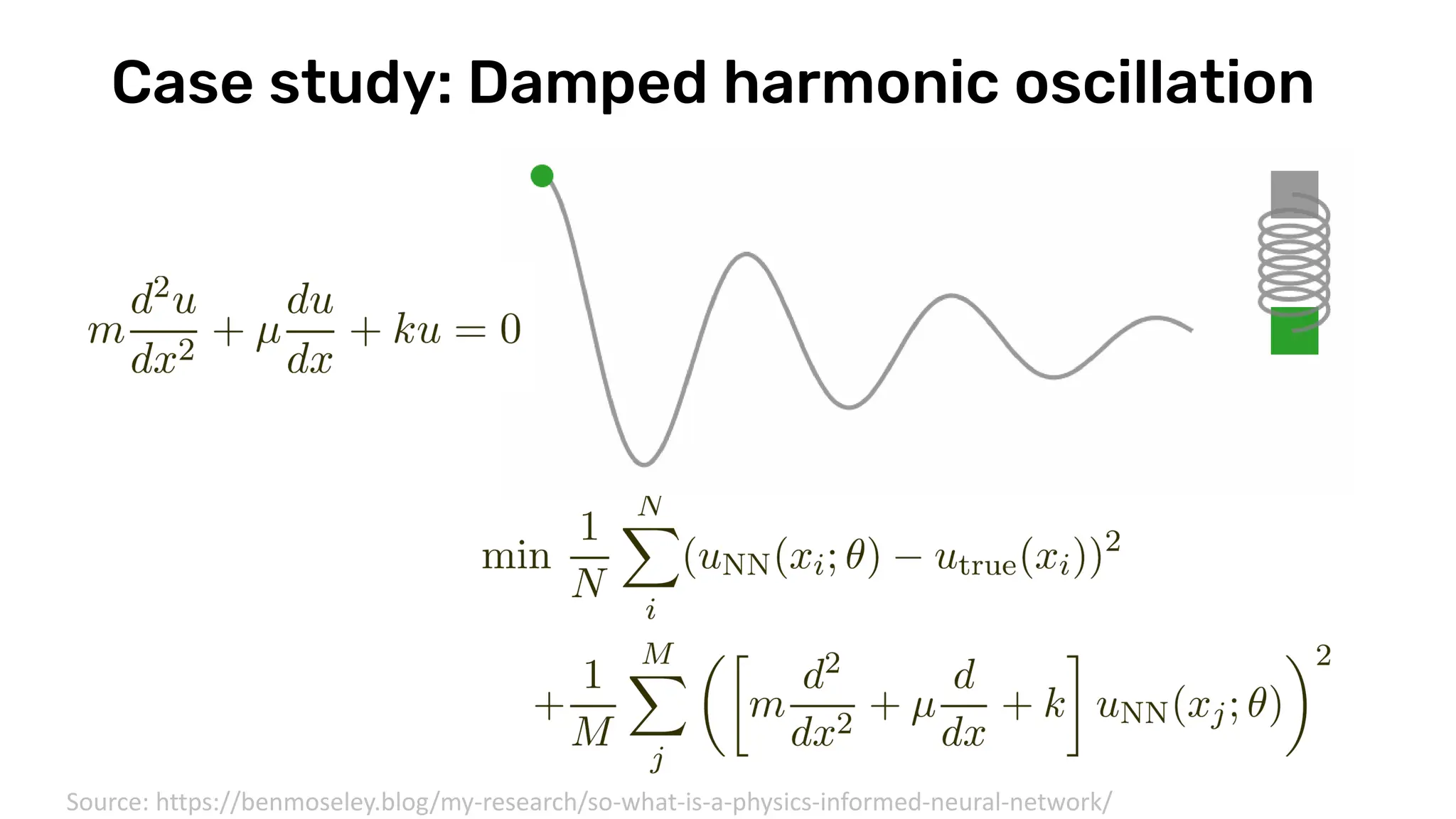

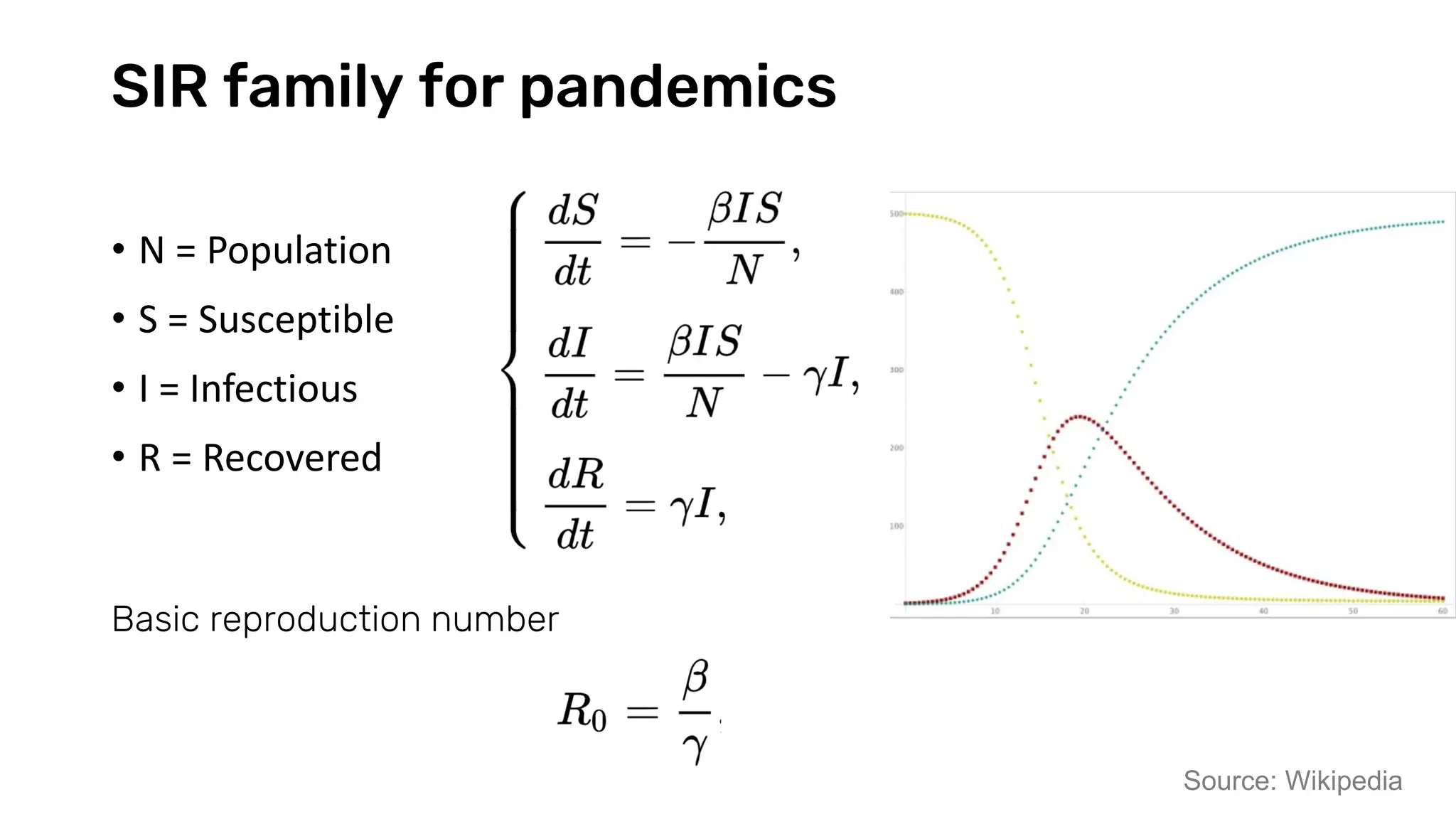



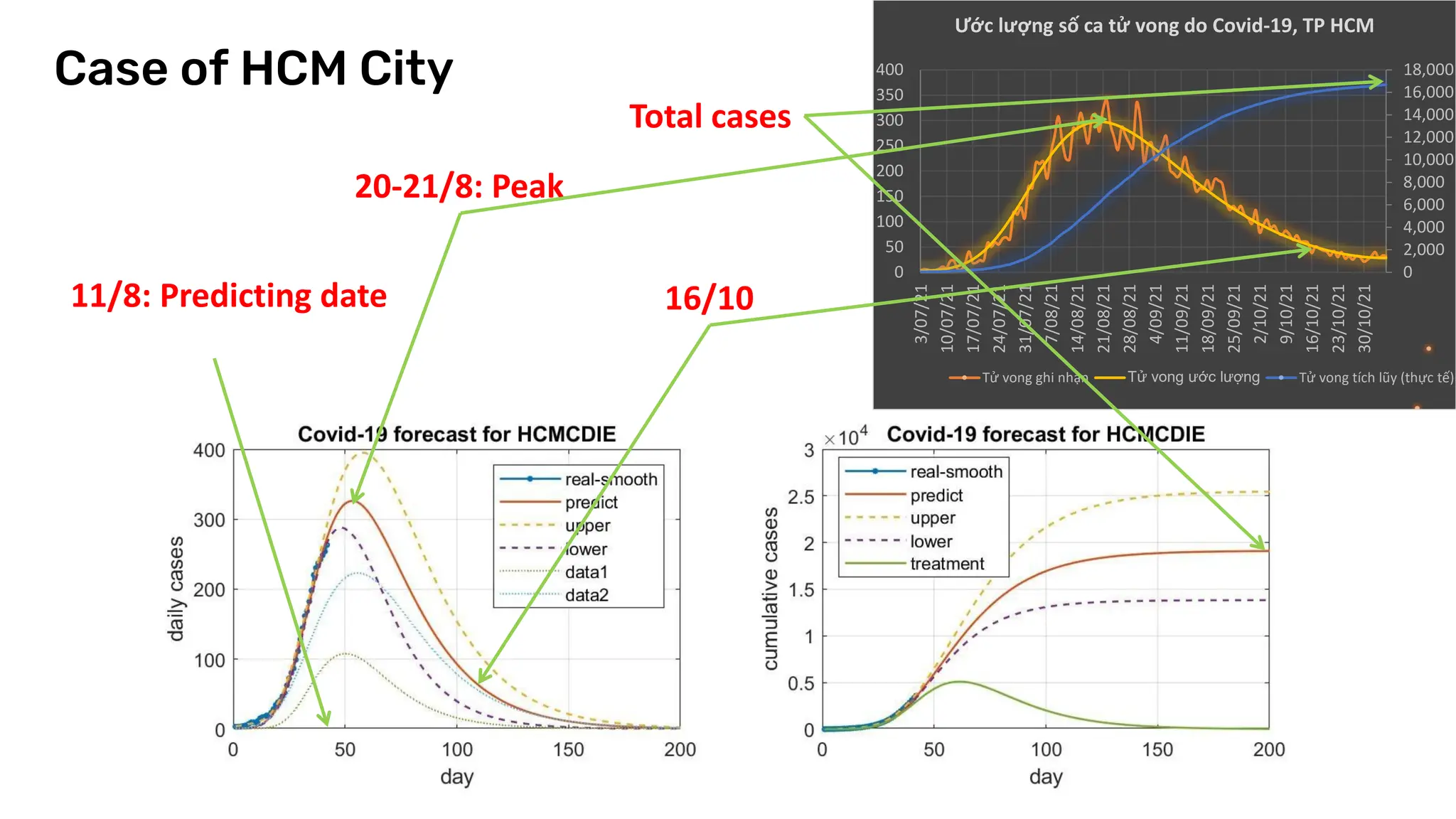
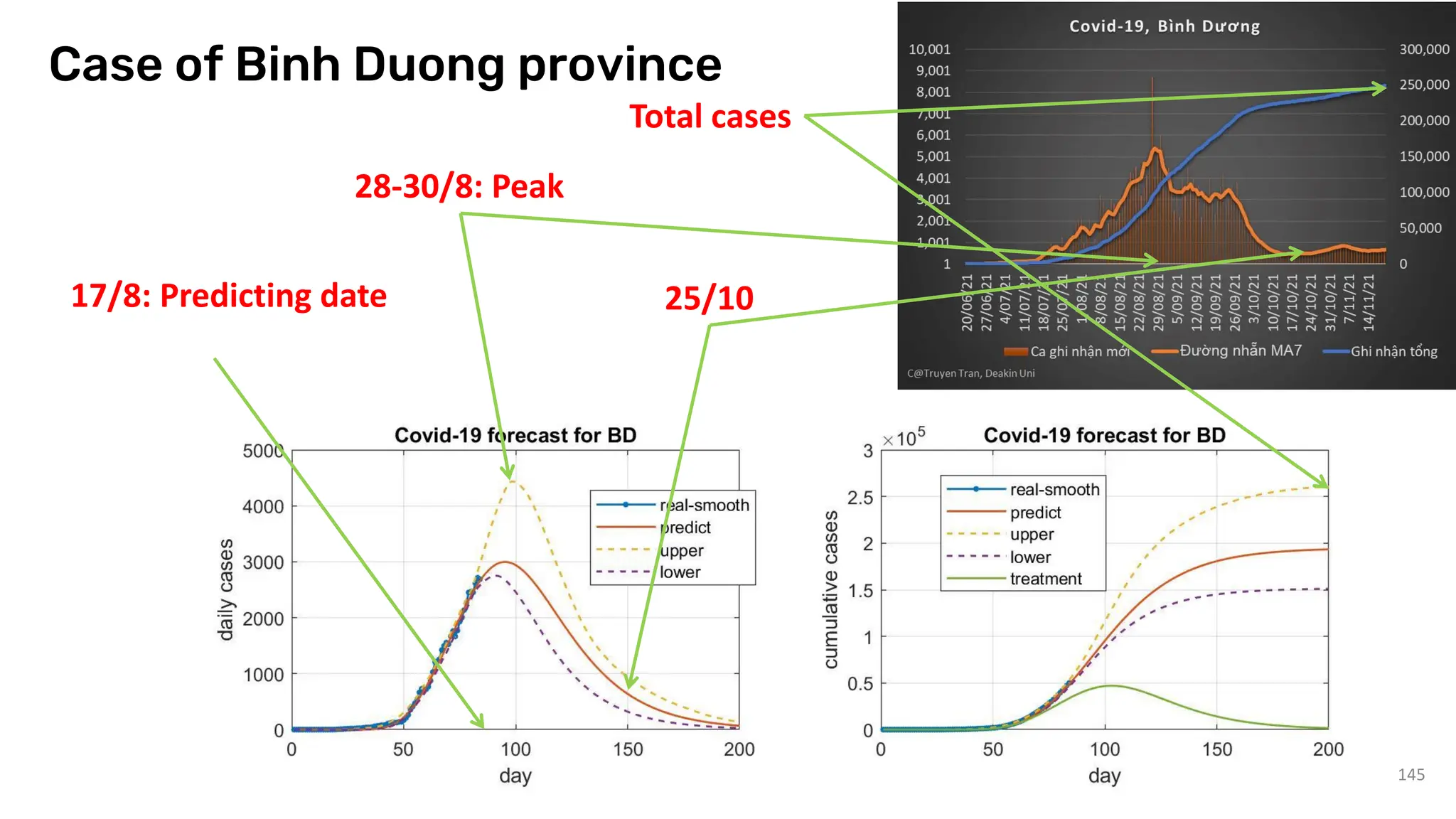
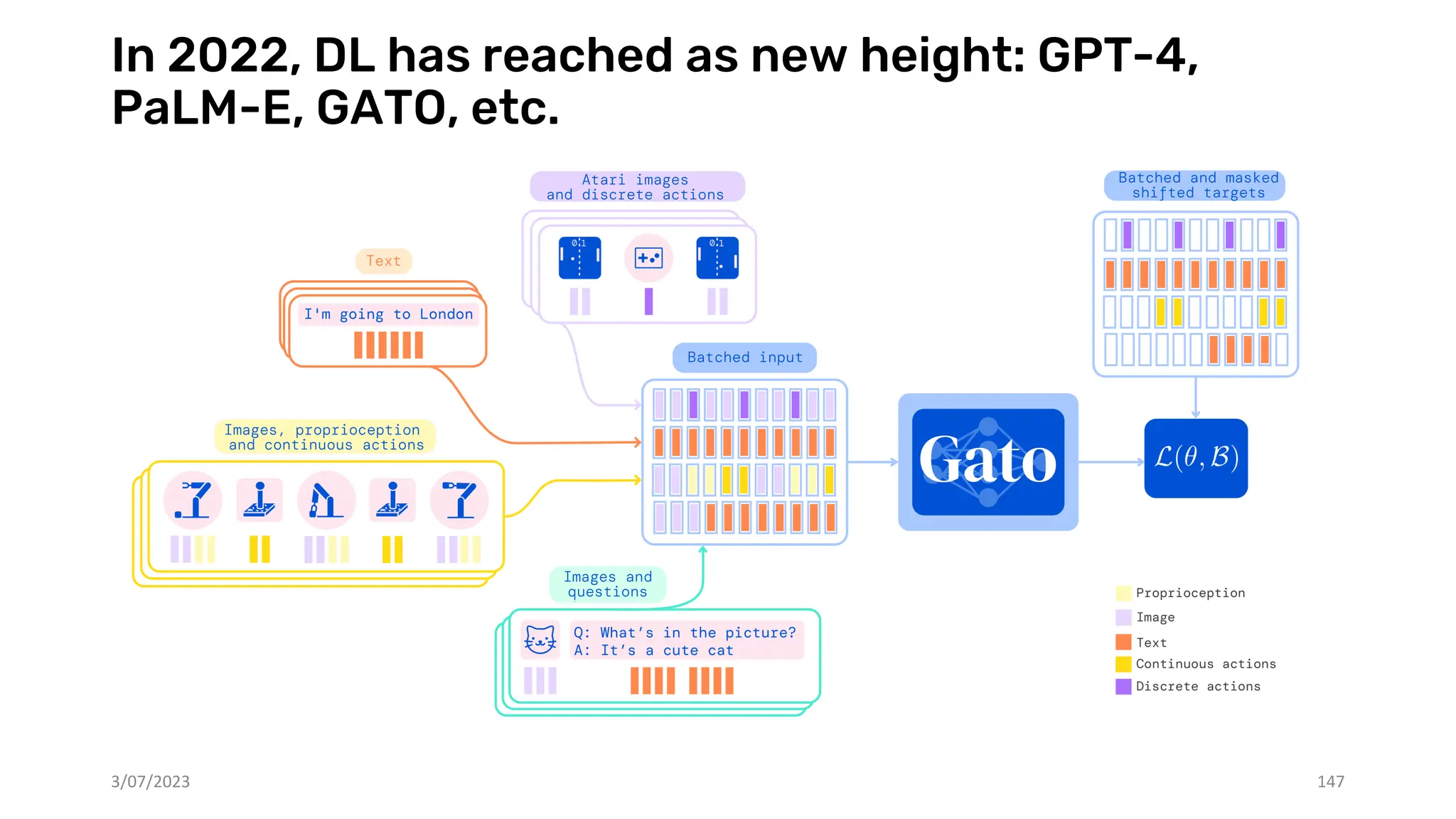




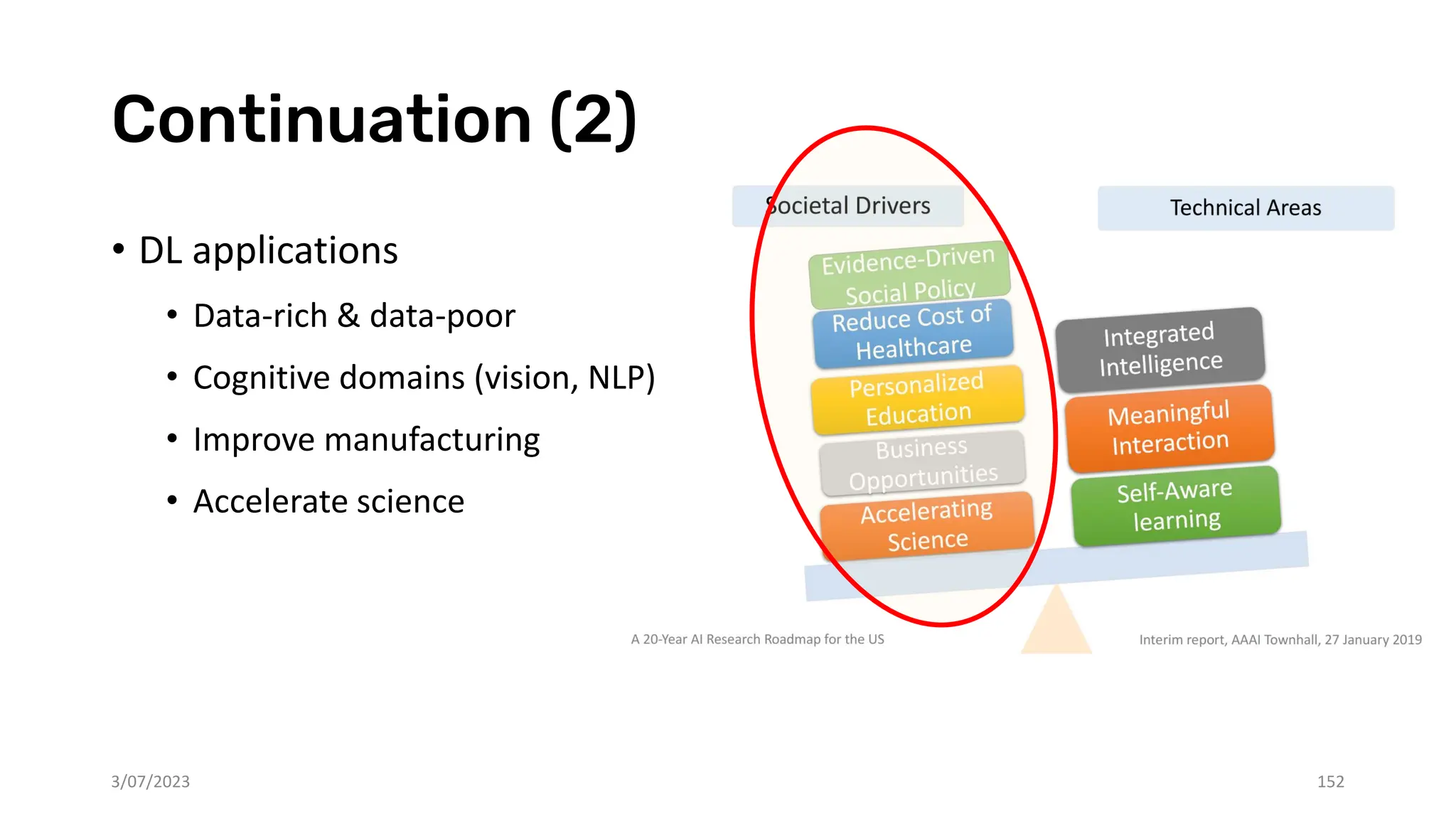






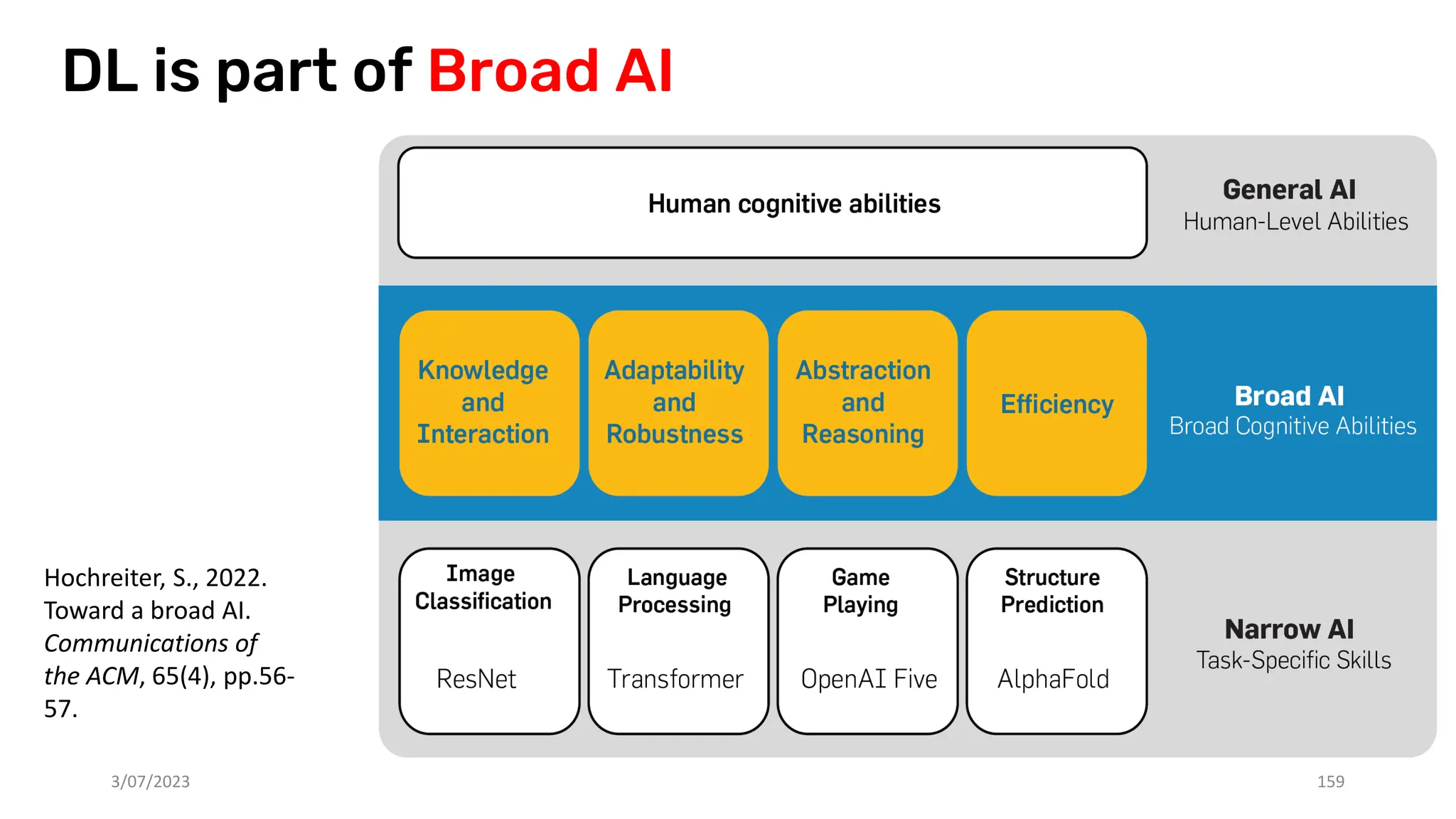
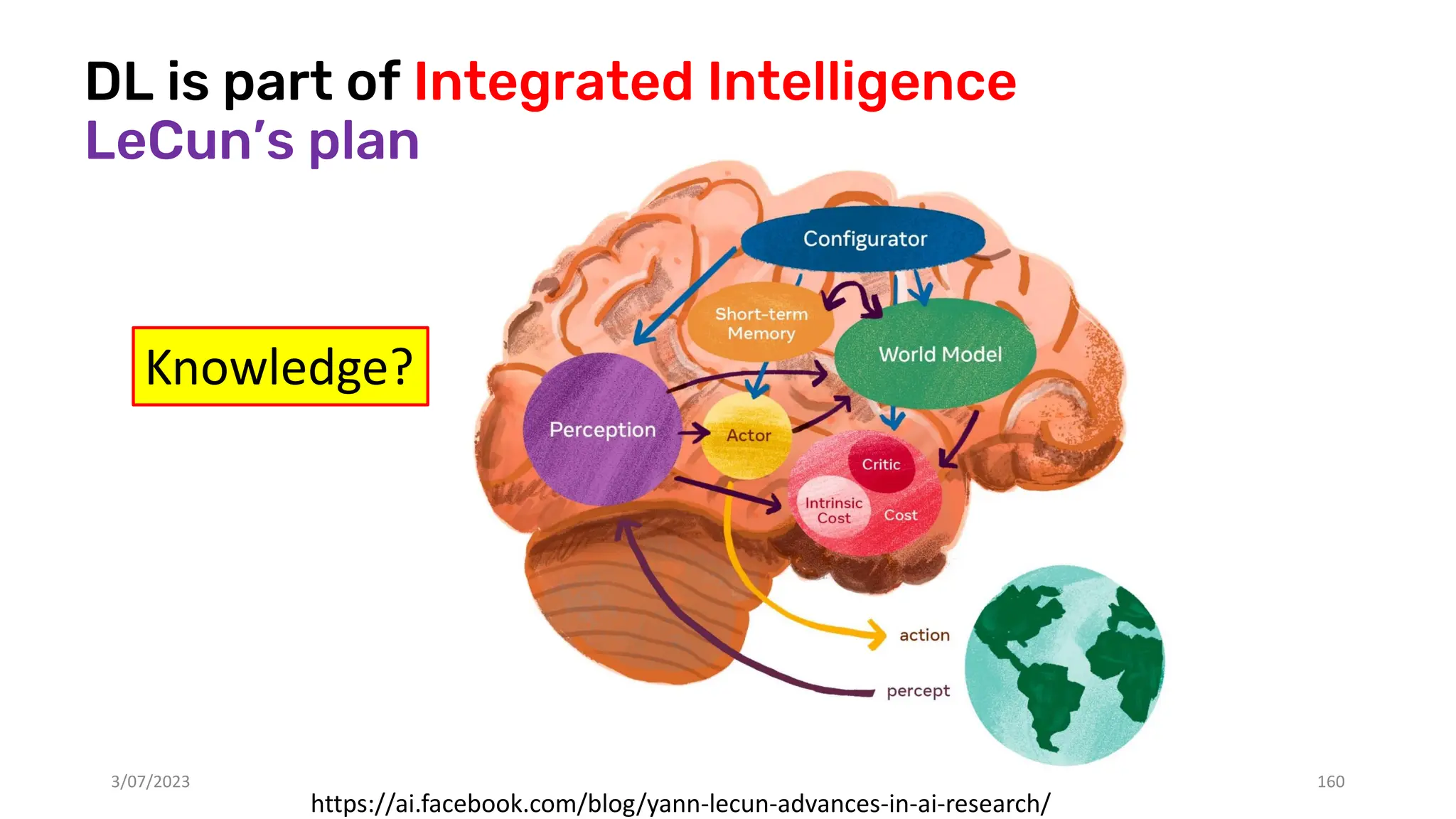





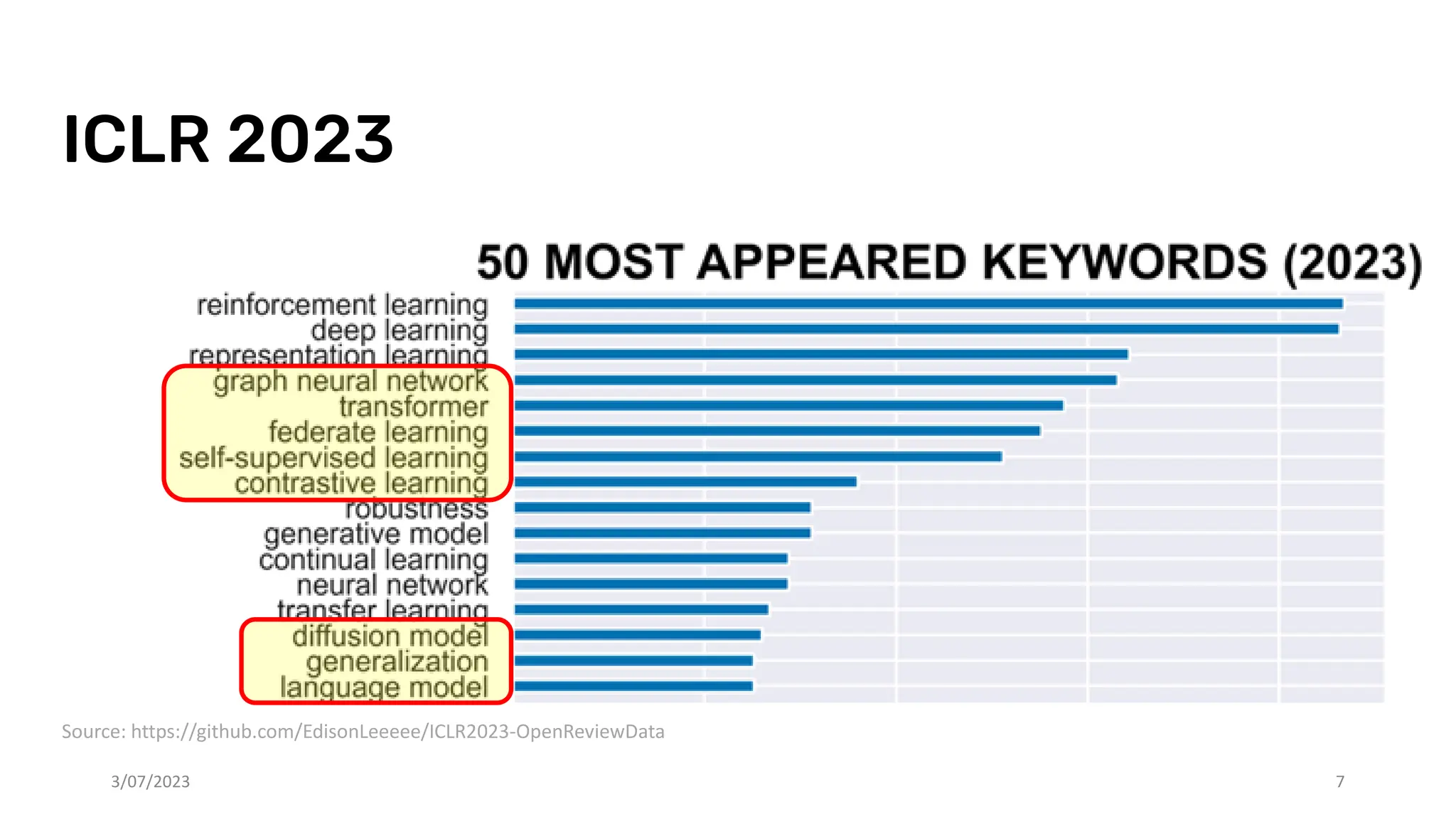
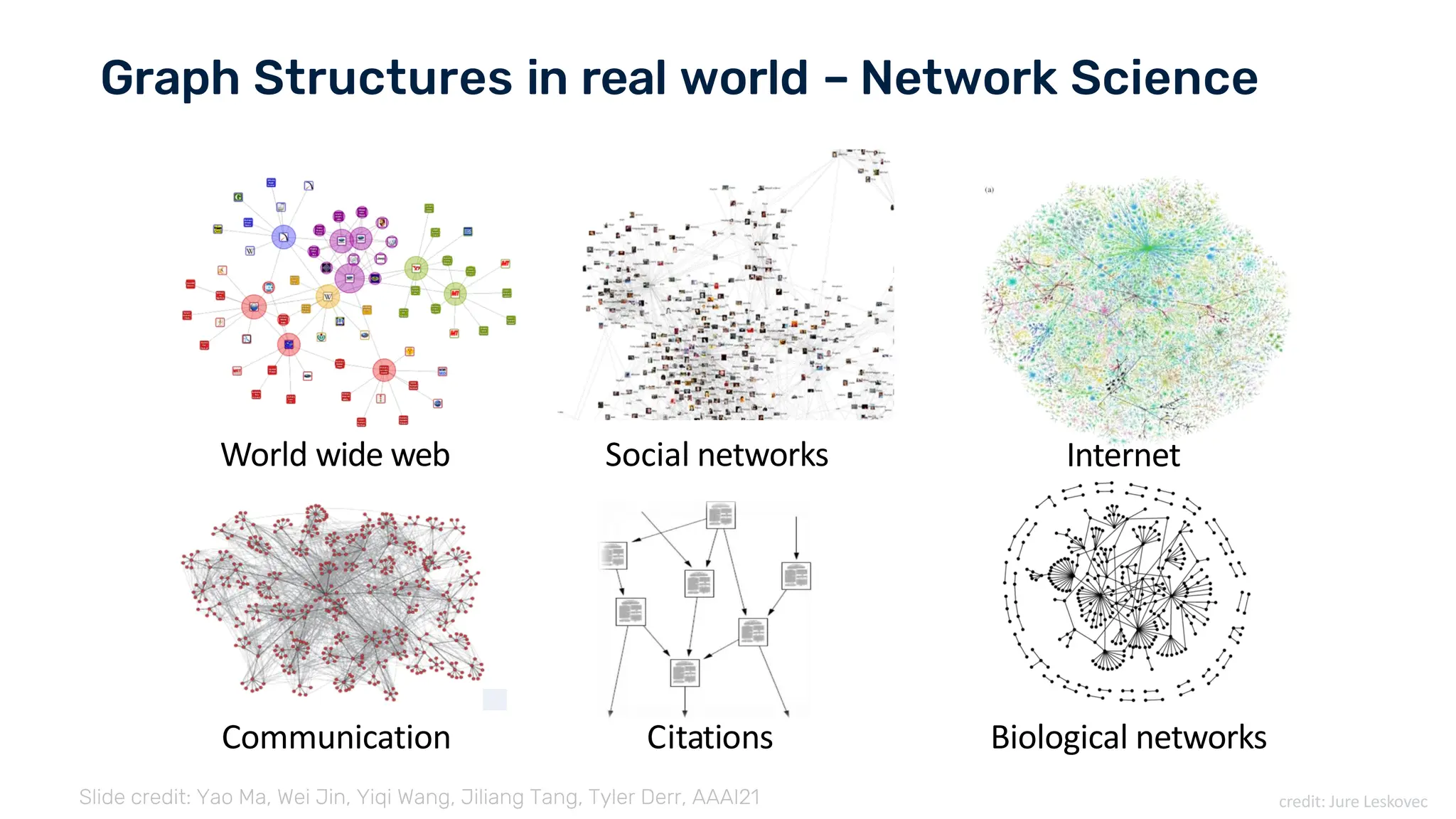
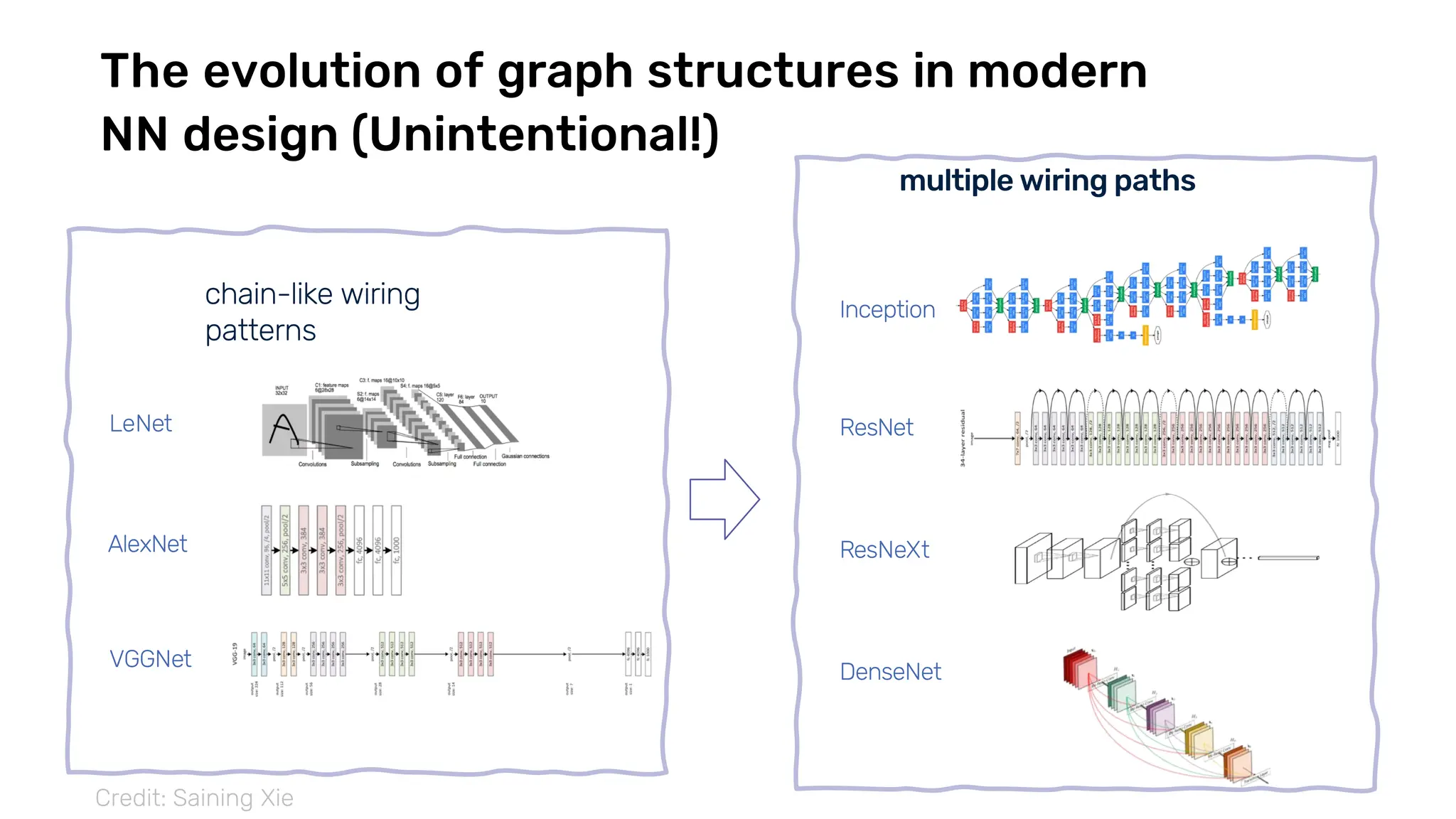
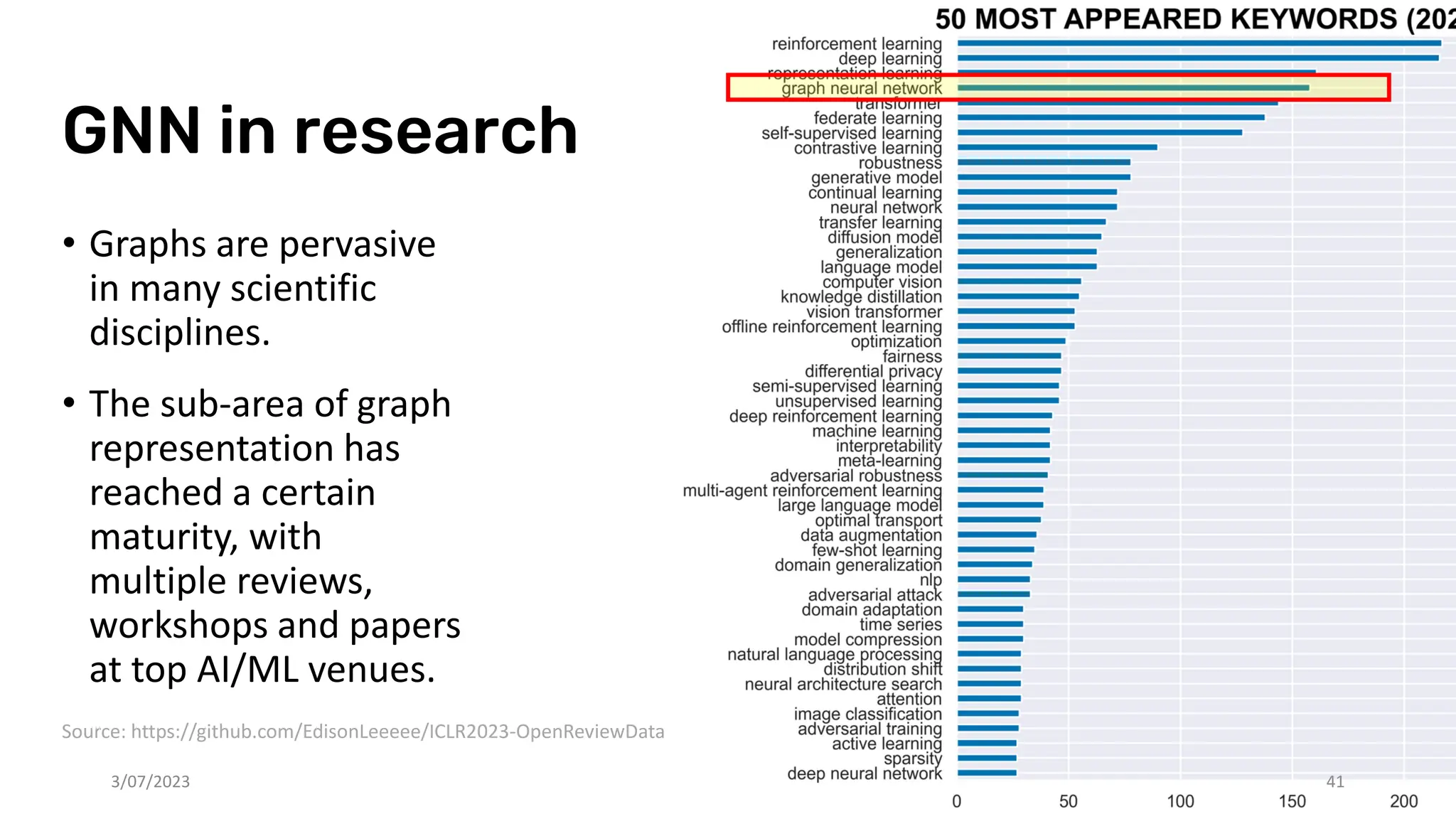
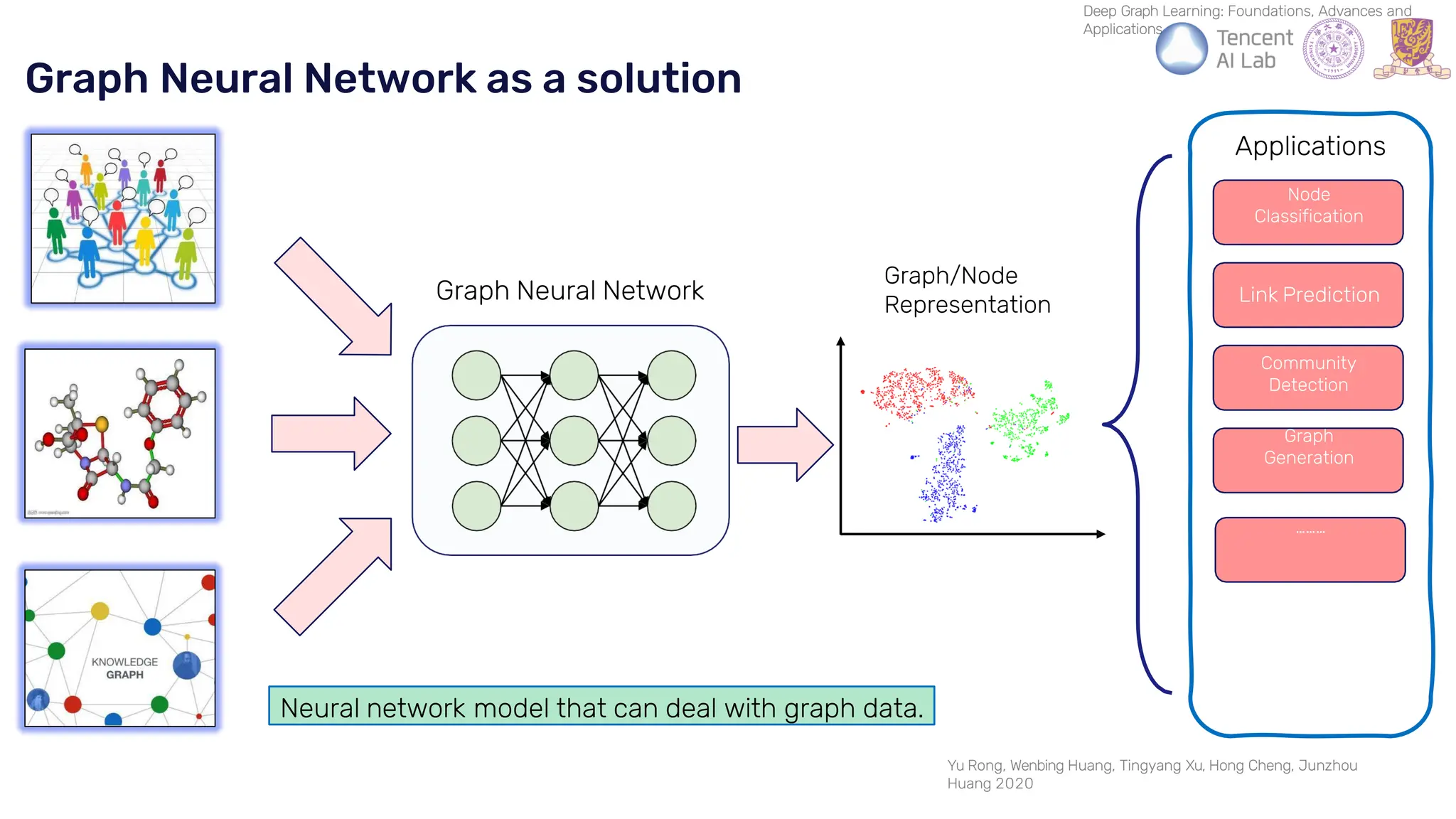
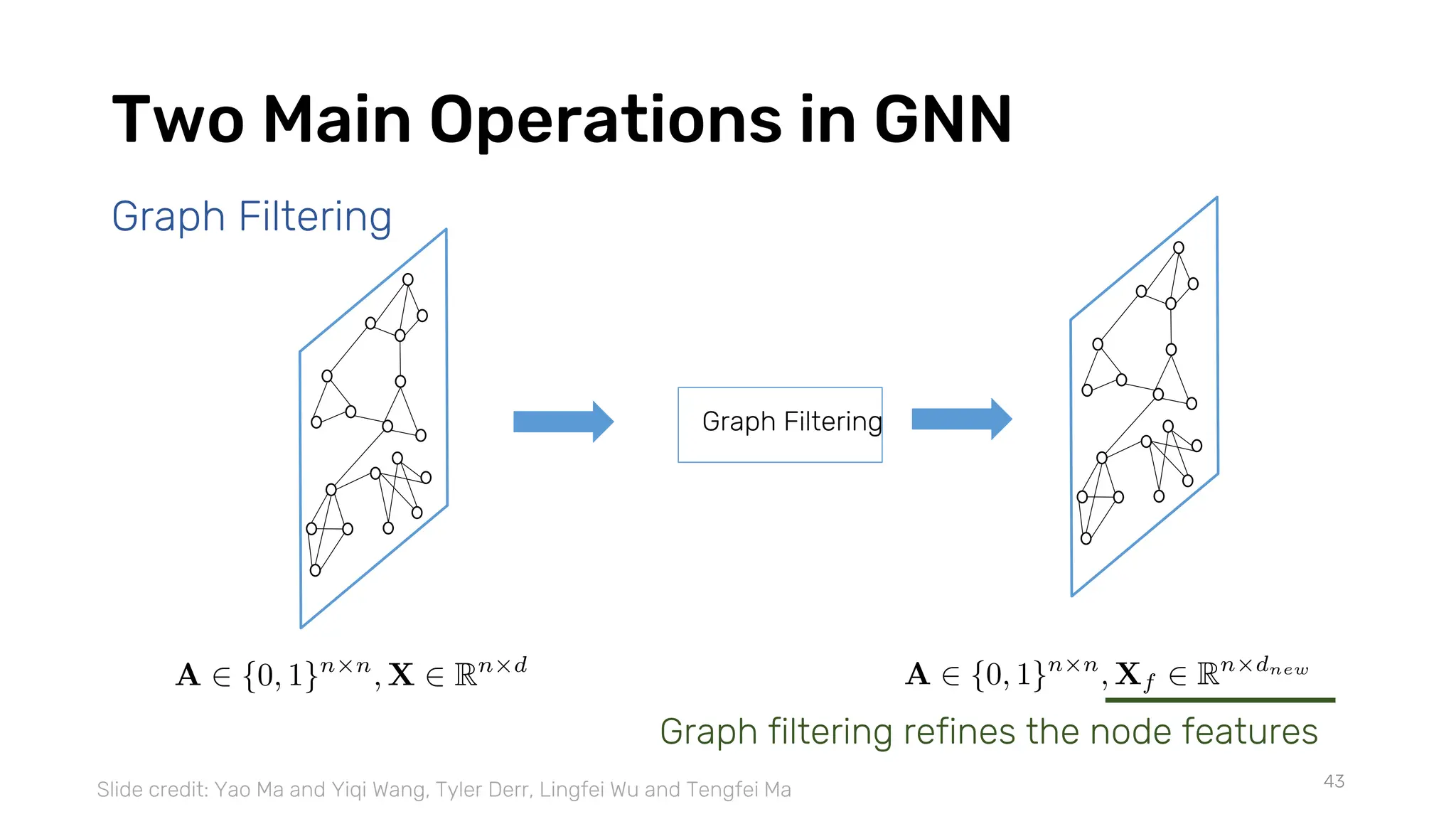
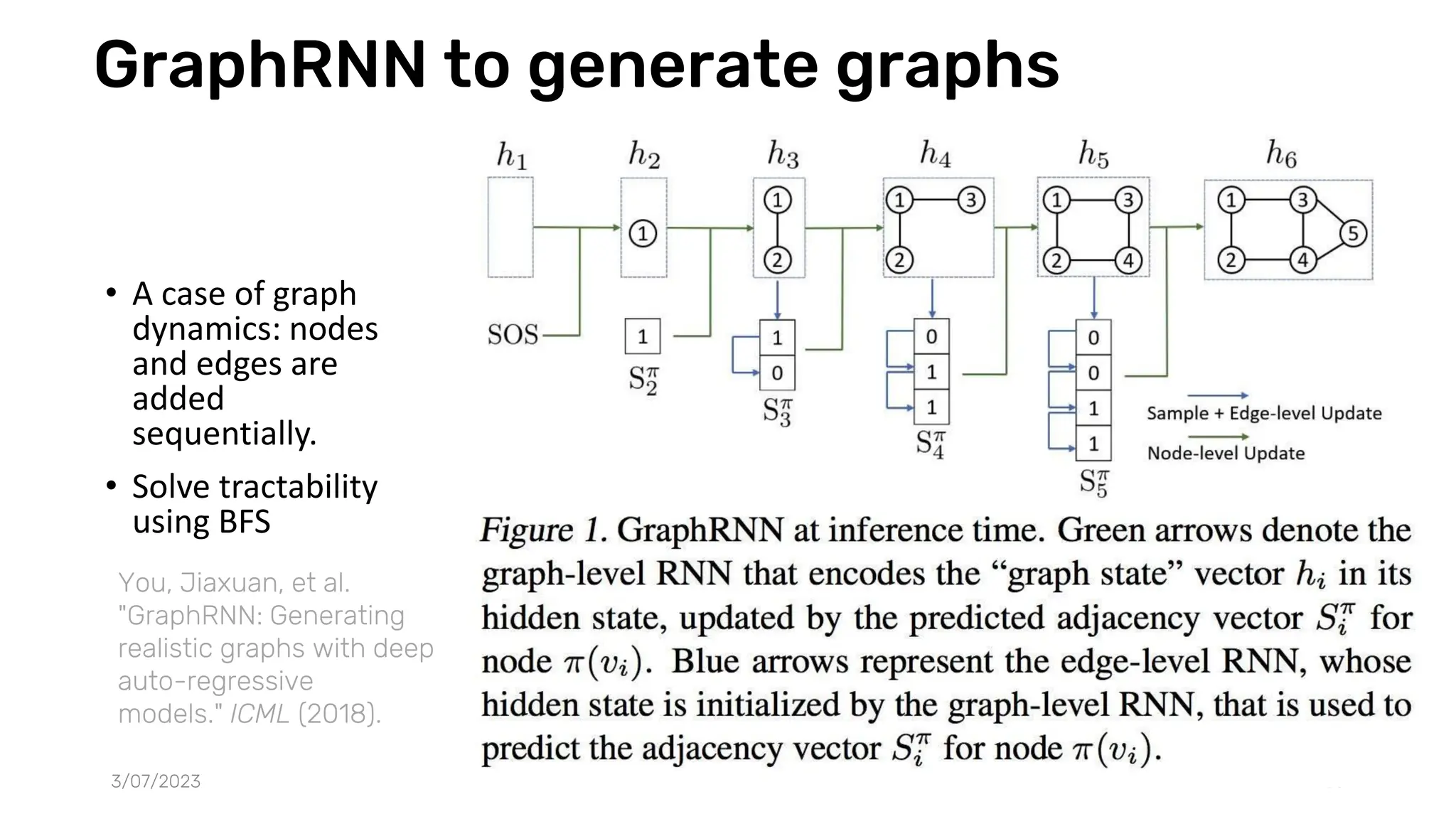
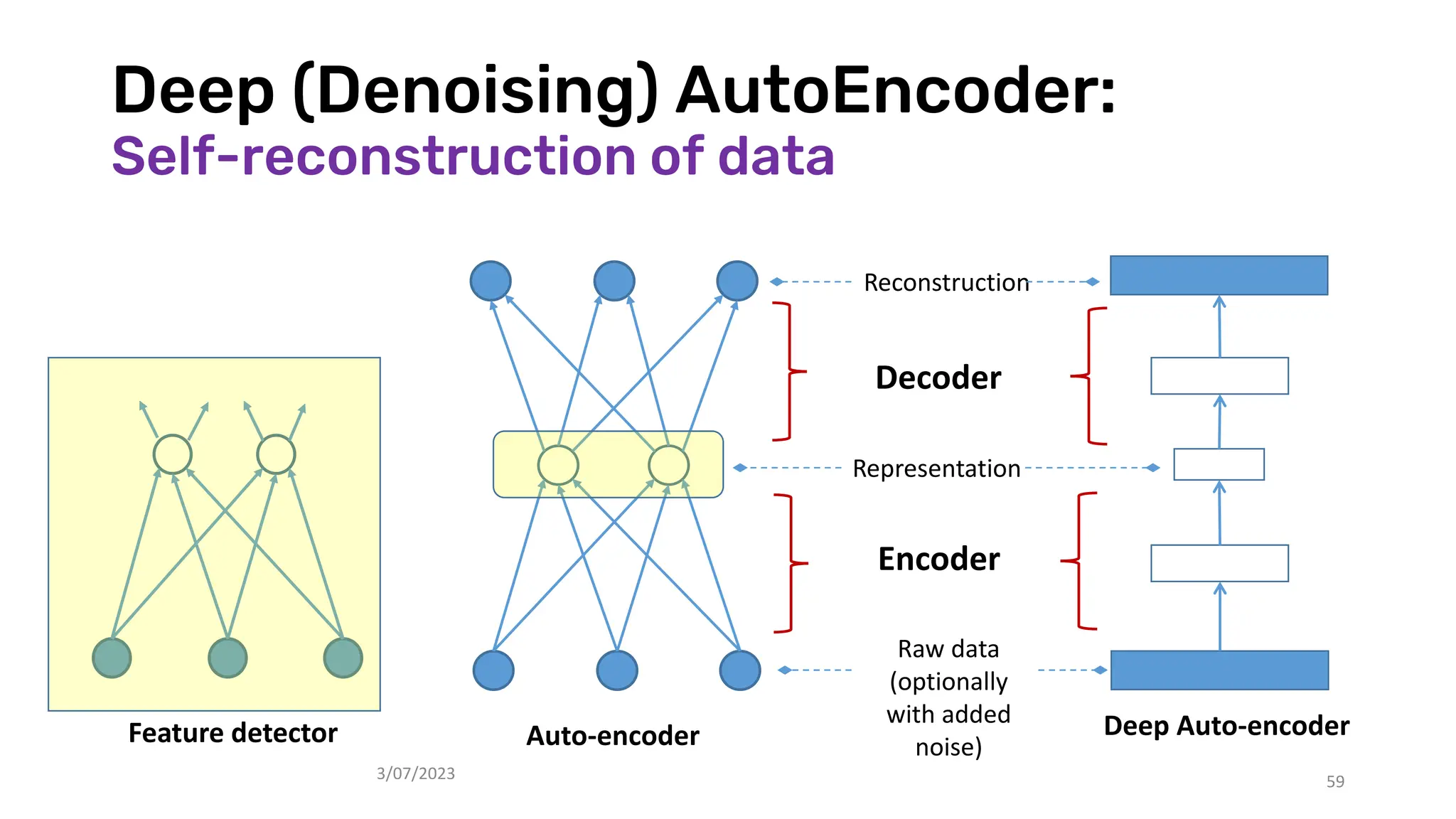
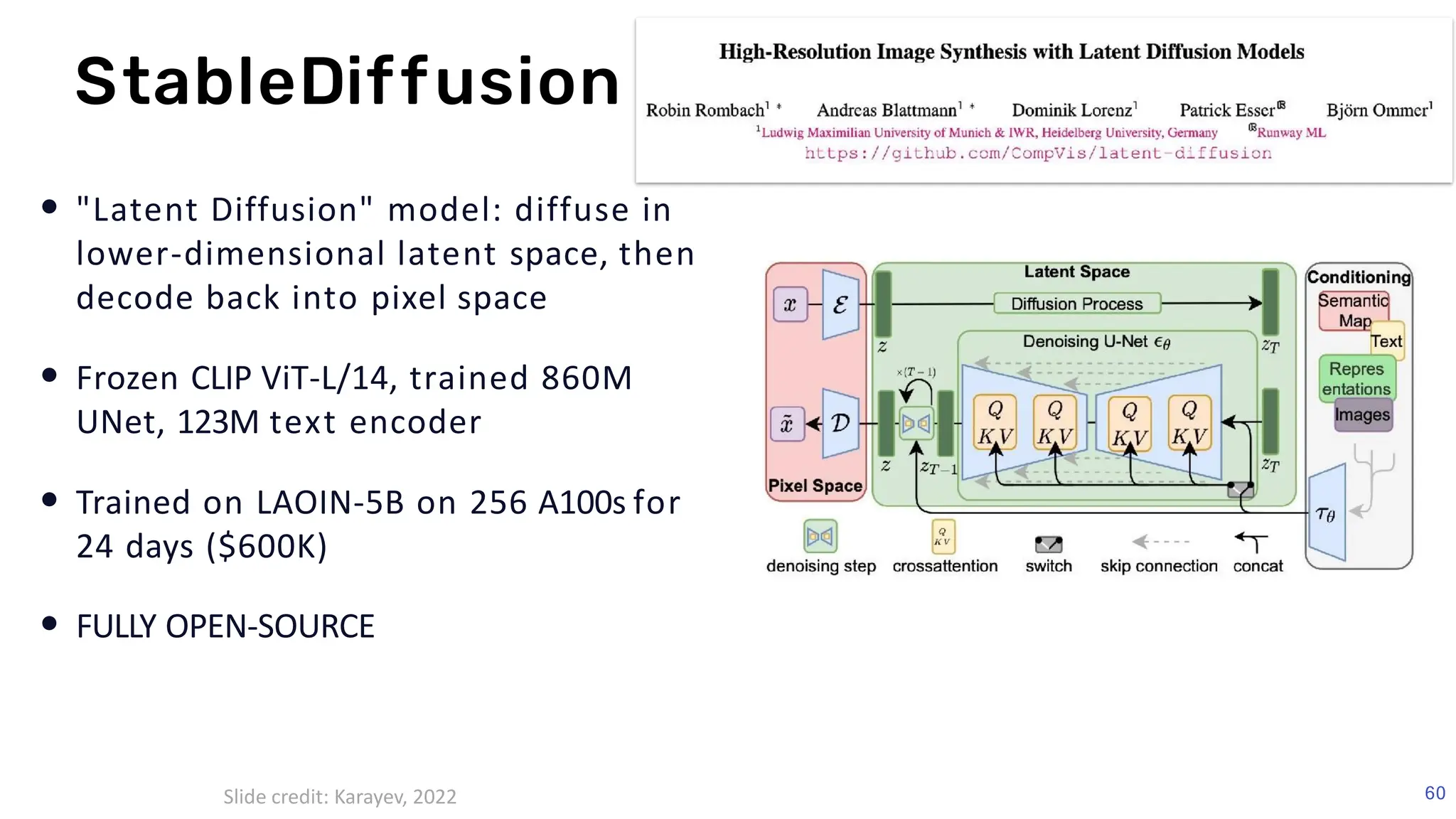
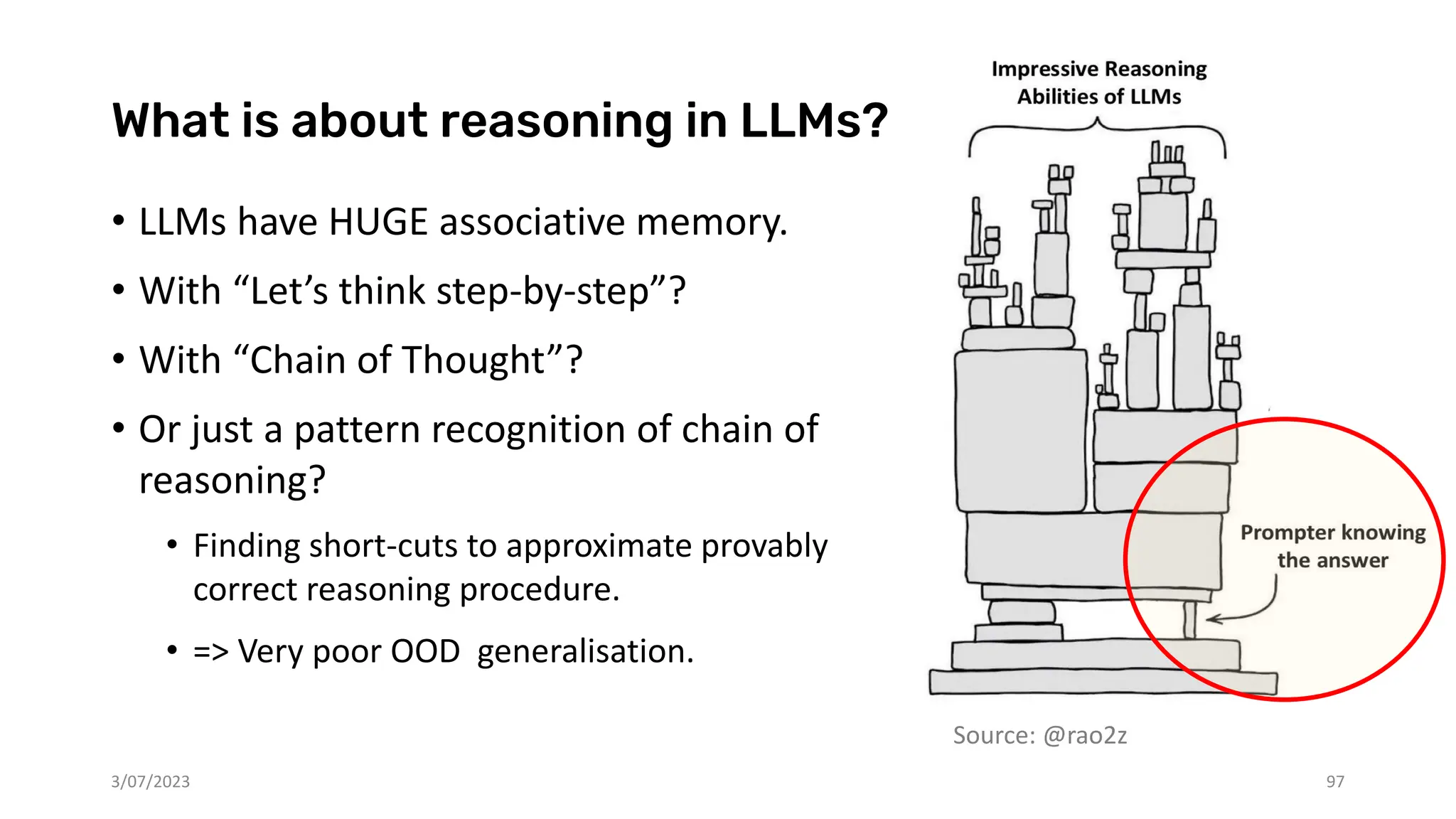
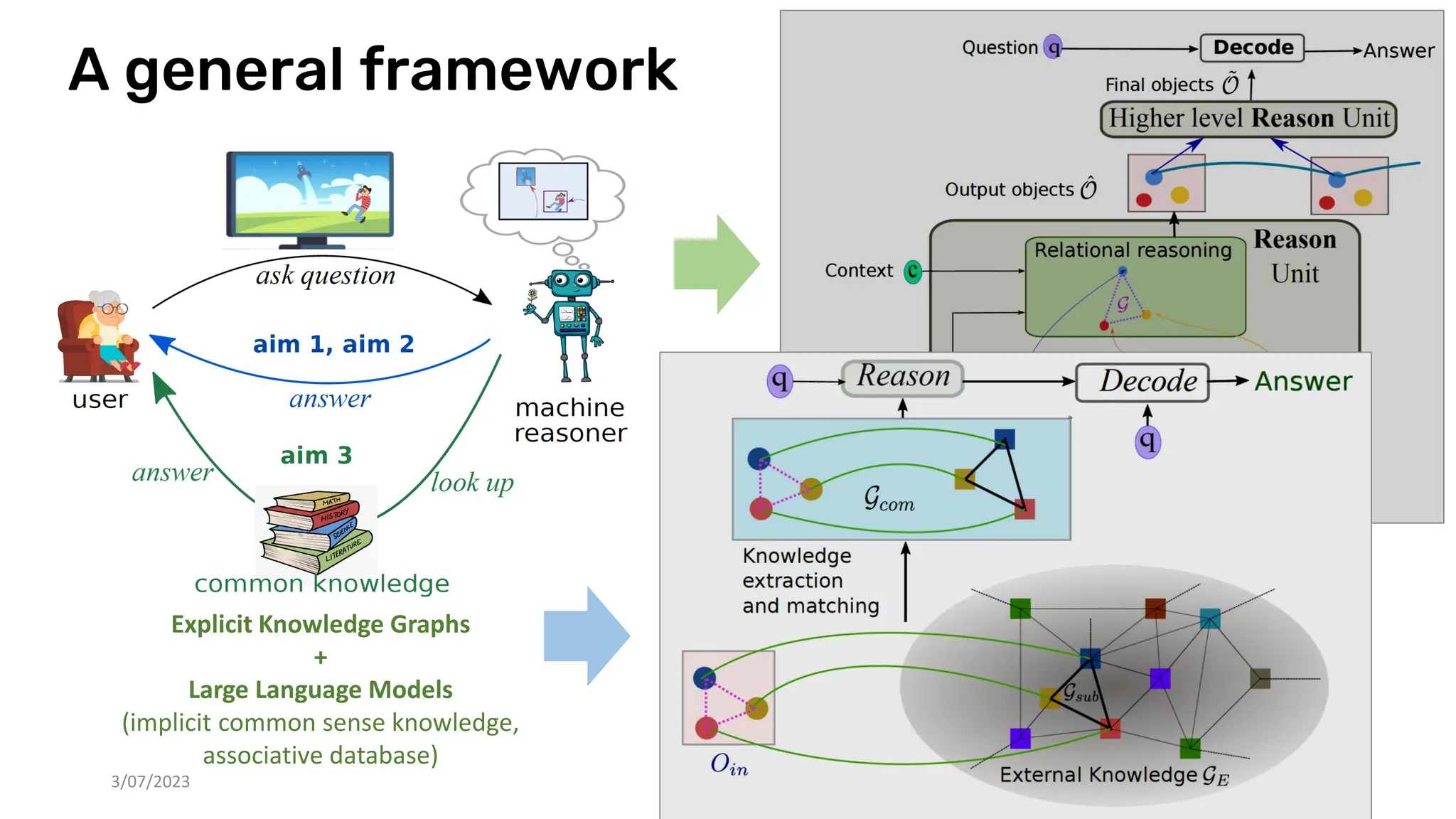
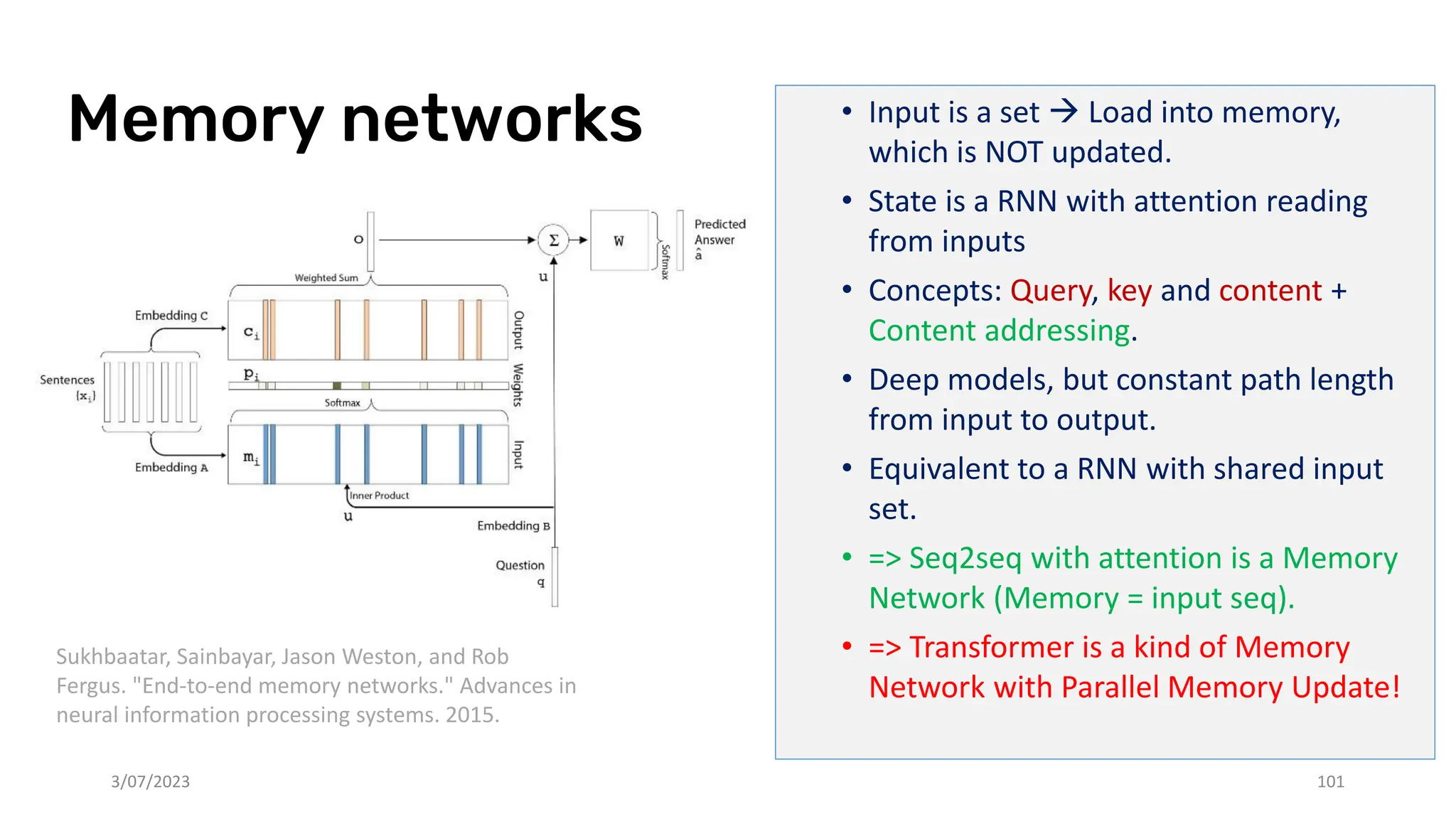
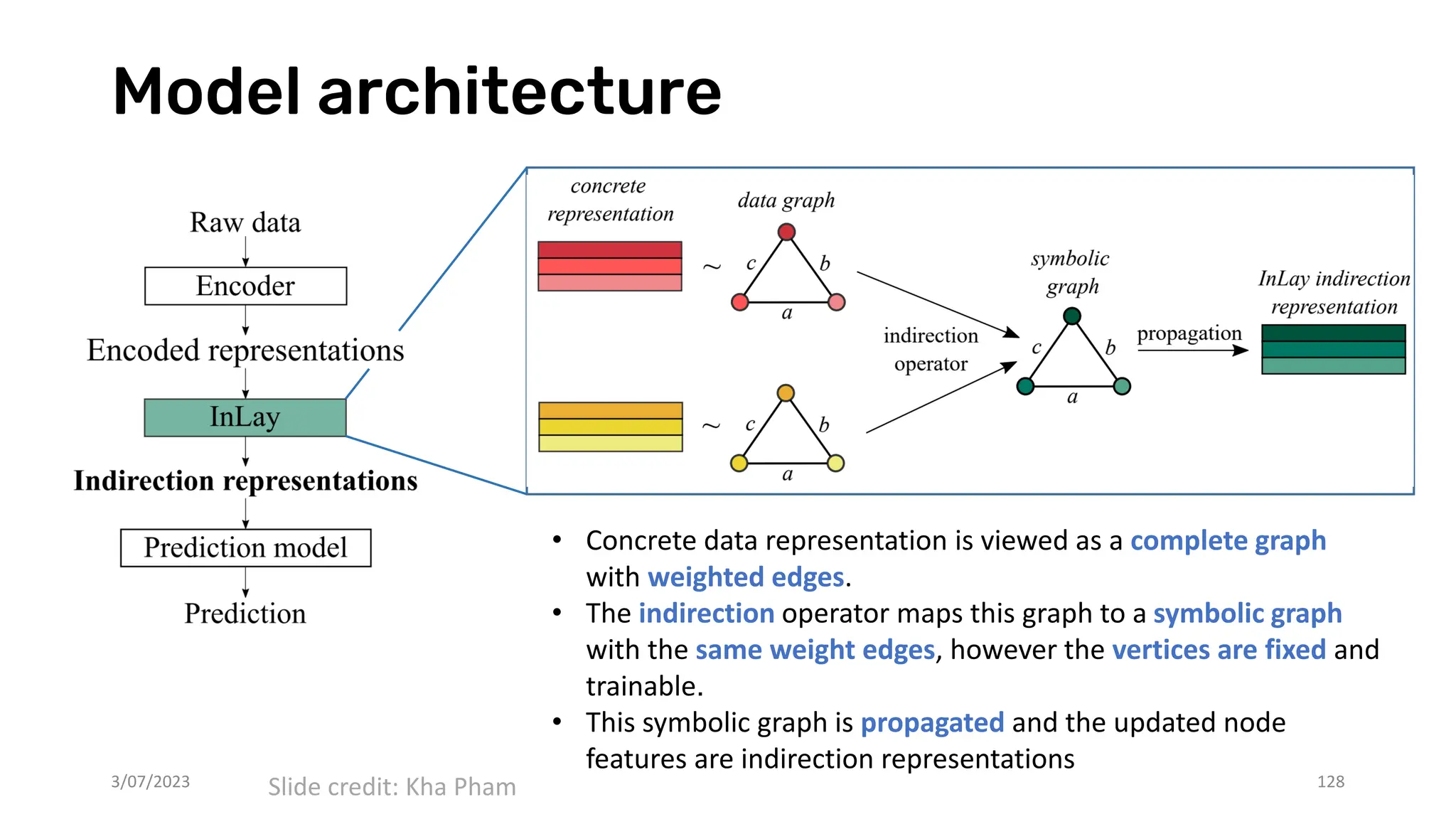
The document discusses recent advances in deep learning and reasoning, with a focus on neural architectures such as graph neural networks and unsupervised learning techniques. It highlights the significance of neural networks in various domains and their capability to approximate functions, adapt to large data sets, and represent complex structures. Additionally, it emphasizes the evolution of neural network models and the application of graph structures in understanding real-world phenomena.













































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)









