Downloaded 22 times



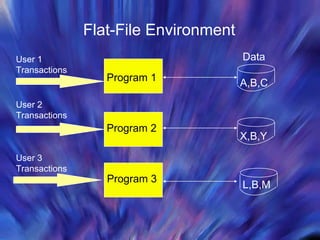




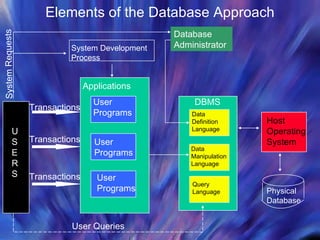










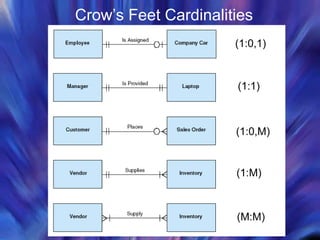









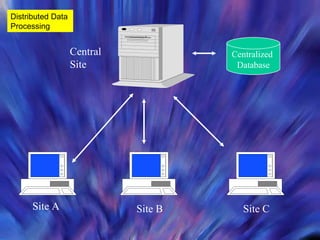











The document discusses database management systems and distributed databases. It covers the problems with flat file data storage, how databases address these issues, database design concepts like normalization, and the advantages and challenges of distributed database systems. Distributed databases can be centralized, partitioned, or replicated across multiple sites to improve performance, but maintaining data consistency is challenging and requires concurrency control methods.









































































