Download to read offline







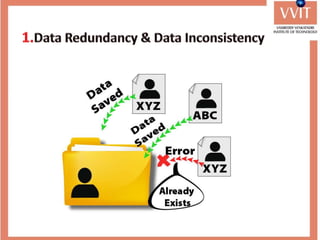



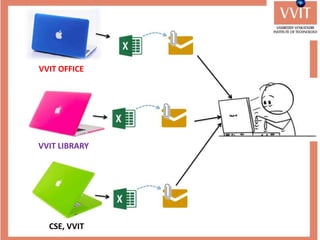











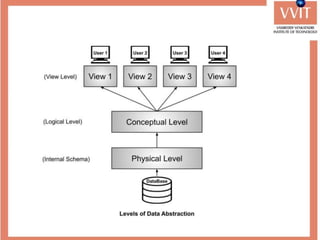








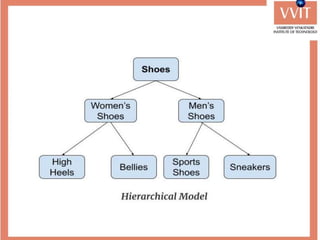

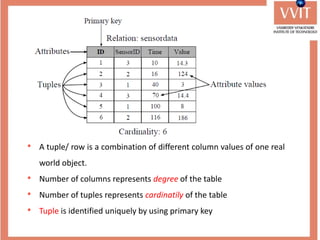






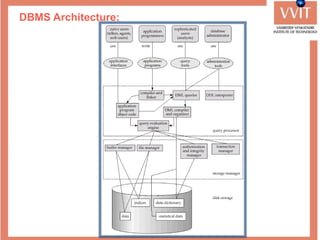


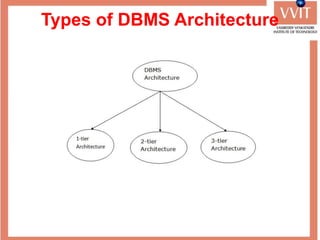

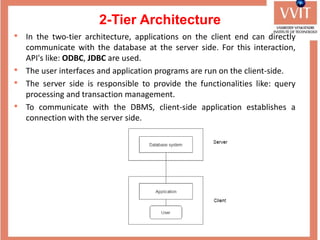
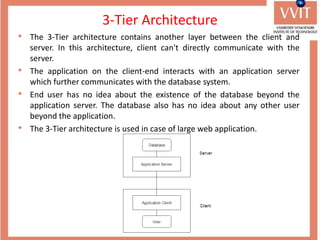

The document discusses the advantages and applications of database management systems (DBMS) over traditional file systems, highlighting issues like data redundancy, inconsistency, and security. It explains various levels of data abstraction and independence, as well as the roles of different database users and DBMS architecture types. Additionally, it covers data models, with a focus on the relational model, and provides insights on the responsibilities of database administrators and designers.



































































