Download to read offline



























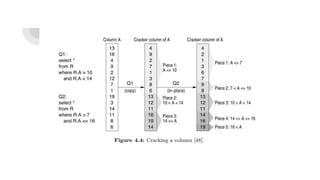

![Arithmetic operations. Other operators that may be used in the select clause in an SQL
query, i.e., math operators (such as +,-*,/) also exploit the columnar layout to perform those
actions eciently. However, in these cases, because such operators typically need to operate
on groups of columns, e.g., select A+B+C From R ..., they typically have to materialize
intermediate results for each action. For example, in our previous example, a inter=add(A,B)
operator will work over columns A and B creating an intermediate result column which will
then be fed to another res=add(C,inter) operator in order to perform the addition with
column C and to produce the final result. Vectoriza-
tion helps in minimizing the memory footprint of intermediate results at any given time, but it
has been shown that it may also be beneficial to on-the-fly transform intermediate results
into column-groups in order to work with (vectors of) multiple columns [101], avoiding
materialization of intermediate results completely. In our example above, we can create a
column-group of the qualifying tuples from all columns (A, B, C) and perform the sum
operation in one go.](https://image.slidesharecdn.com/thedesignandimplementationofmoderncolumn-orienteddatabases-210704125132/85/The-design-and-implementation-of-modern-column-oriented-databases-33-320.jpg)



This document discusses the design and implementation of modern column-oriented databases, emphasizing their advantages over traditional row-oriented systems, particularly in analytical applications. It covers various aspects such as column store architectures, query execution models, the benefits of vectorized queries and compiled queries, and different compression techniques used in columnar storage. Additionally, it highlights challenges like materialization trade-offs, efficient query processing, and the need for further research on complex queries.



















![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)















































