Downloaded 92 times










































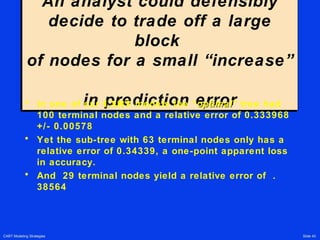













The document outlines CART (Classification and Regression Trees) modeling strategies for experienced data analysts, emphasizing the importance of data preparation, careful analysis, and the suitability of CART for handling messy data. It reiterates that although CART can improve the analysis speed and accuracy, the choice of modeling strategy is critical, as improper strategies can lead to biased results. Key methodologies discussed include exploratory data analysis, variable selection, handling multivariate outliers, and iterative improvements to models based on results.






























































































