Downloaded 152 times




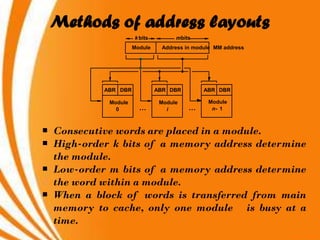
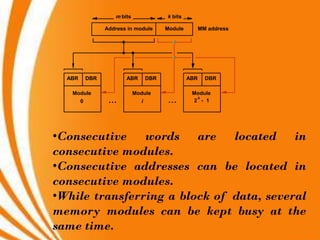






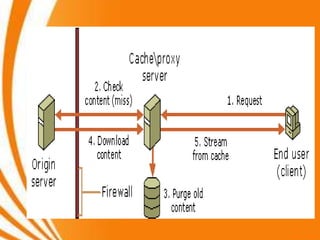
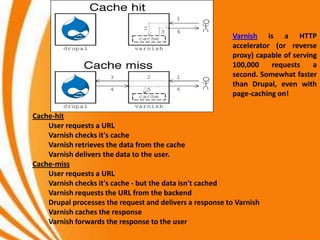
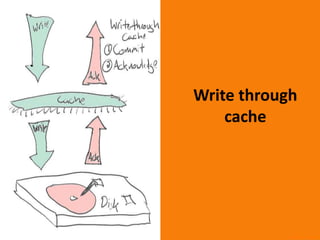
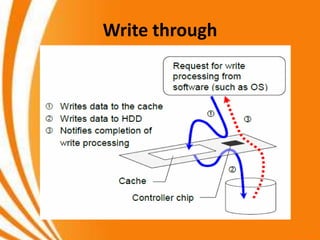
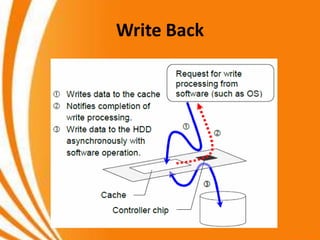
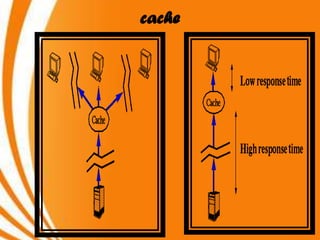
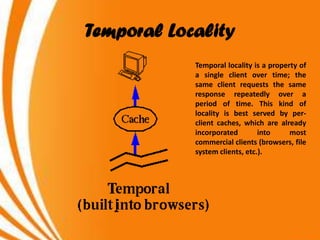
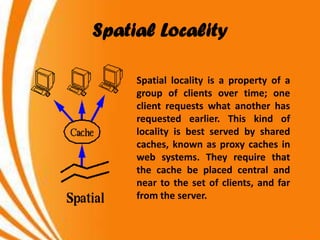
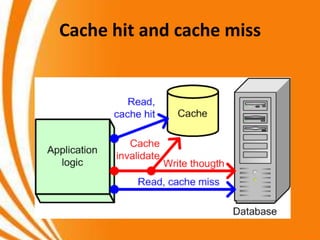

- A key objective of computer systems is achieving high performance at low cost, measured by price/performance ratio. - Processor performance depends on how fast instructions can be fetched from memory and executed. - Caches improve performance by storing recently accessed data from main memory closer to the processor, reducing access time compared to main memory. This can increase hit rates but requires managing cache misses and write policies.





















































![[Paper reading] Interleaving with Coroutines: A Practical Approach for Robust...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadinginterleavingwithcoroutinesapracticalapproachforrobustindexjoin-211011055753-thumbnail.jpg?width=640&height=640&fit=bounds)









































