

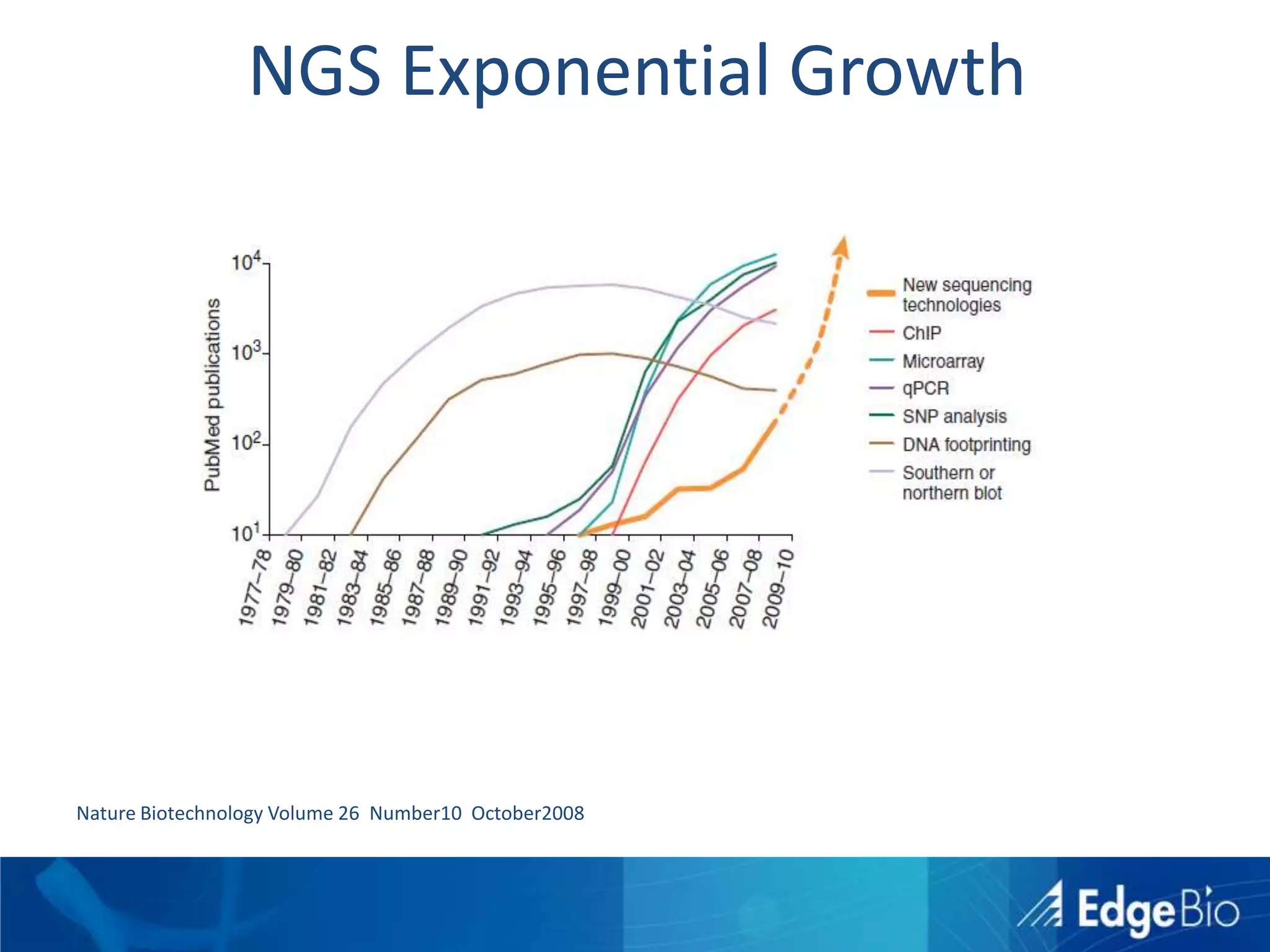


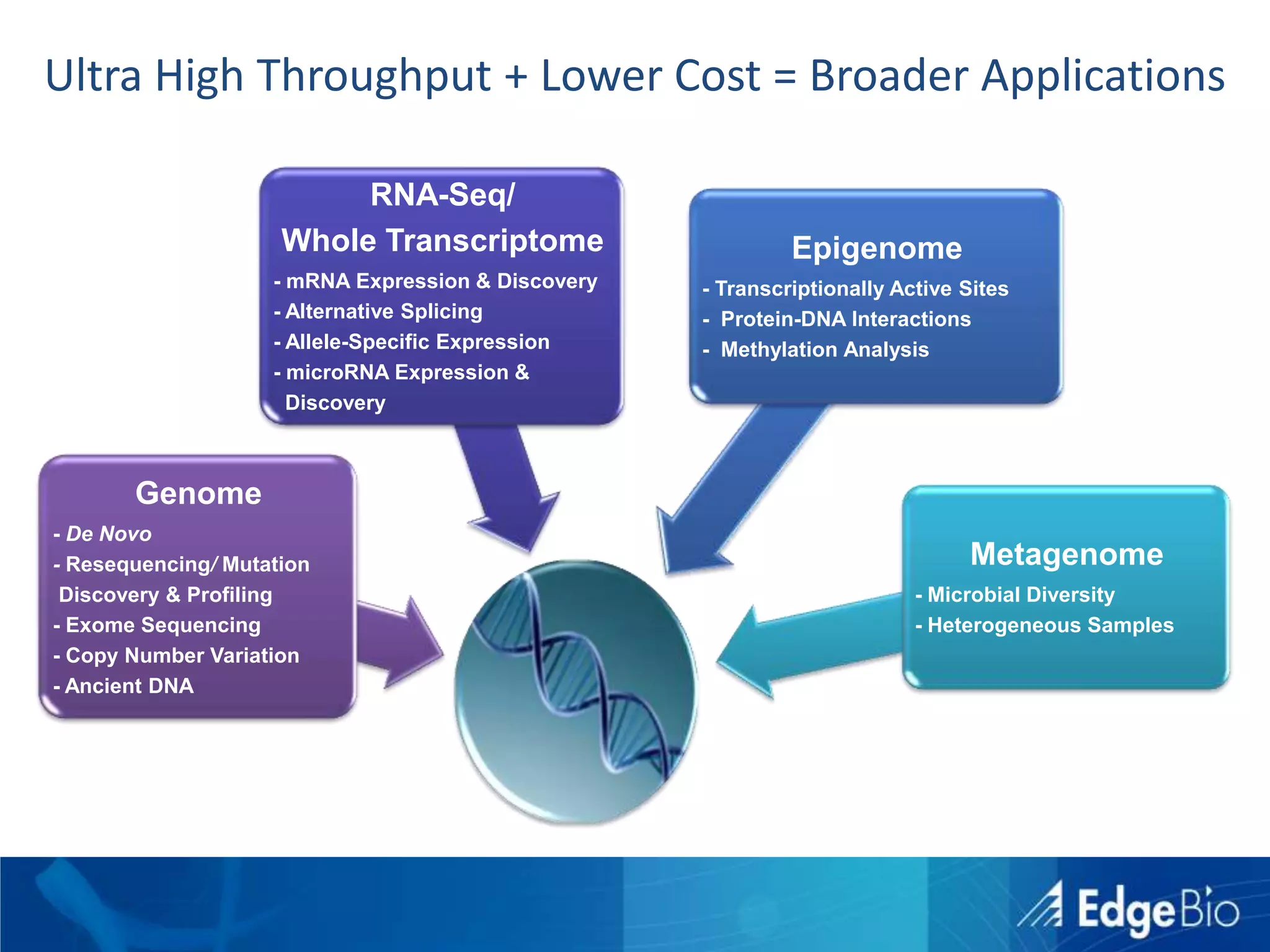







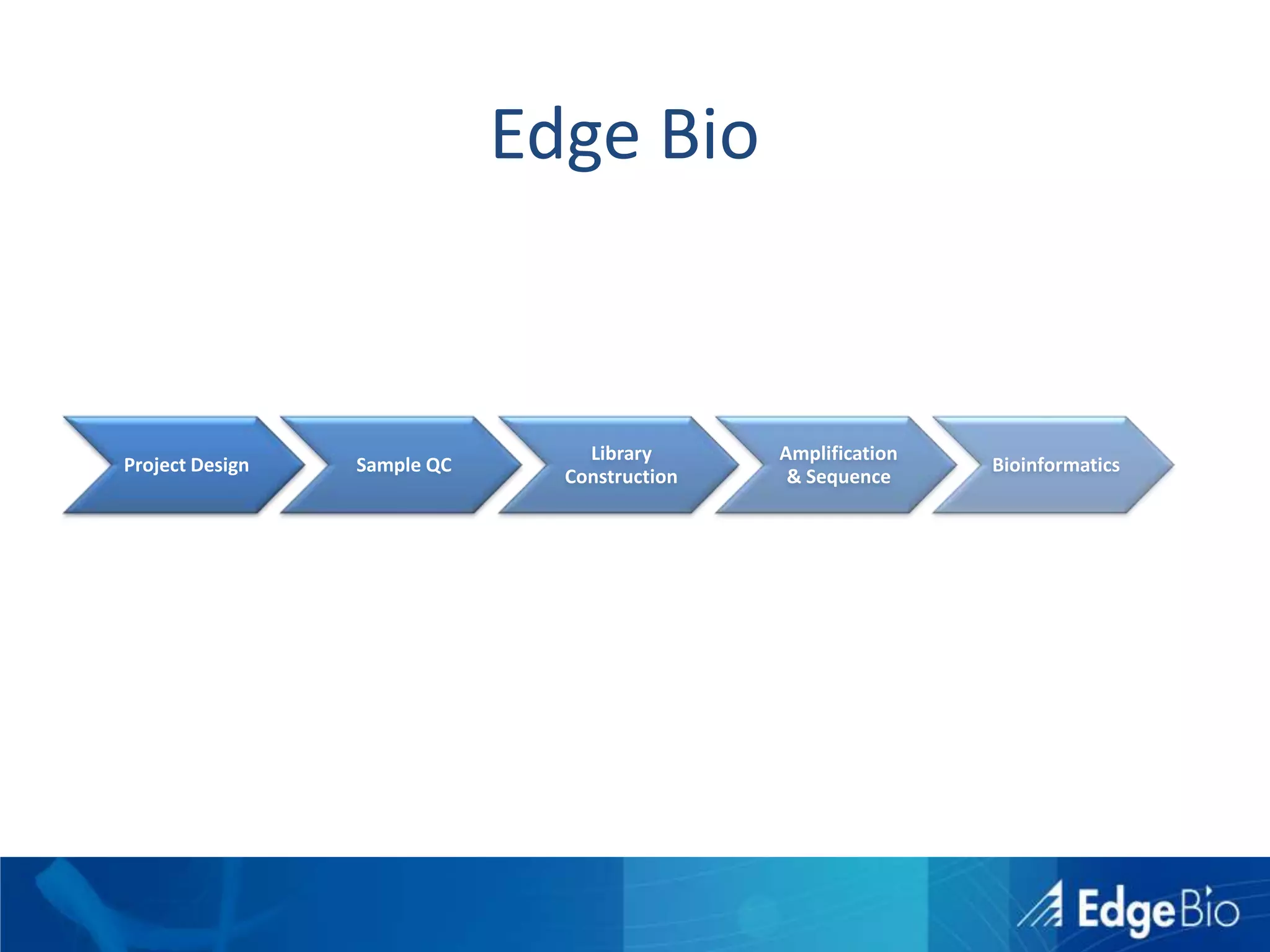

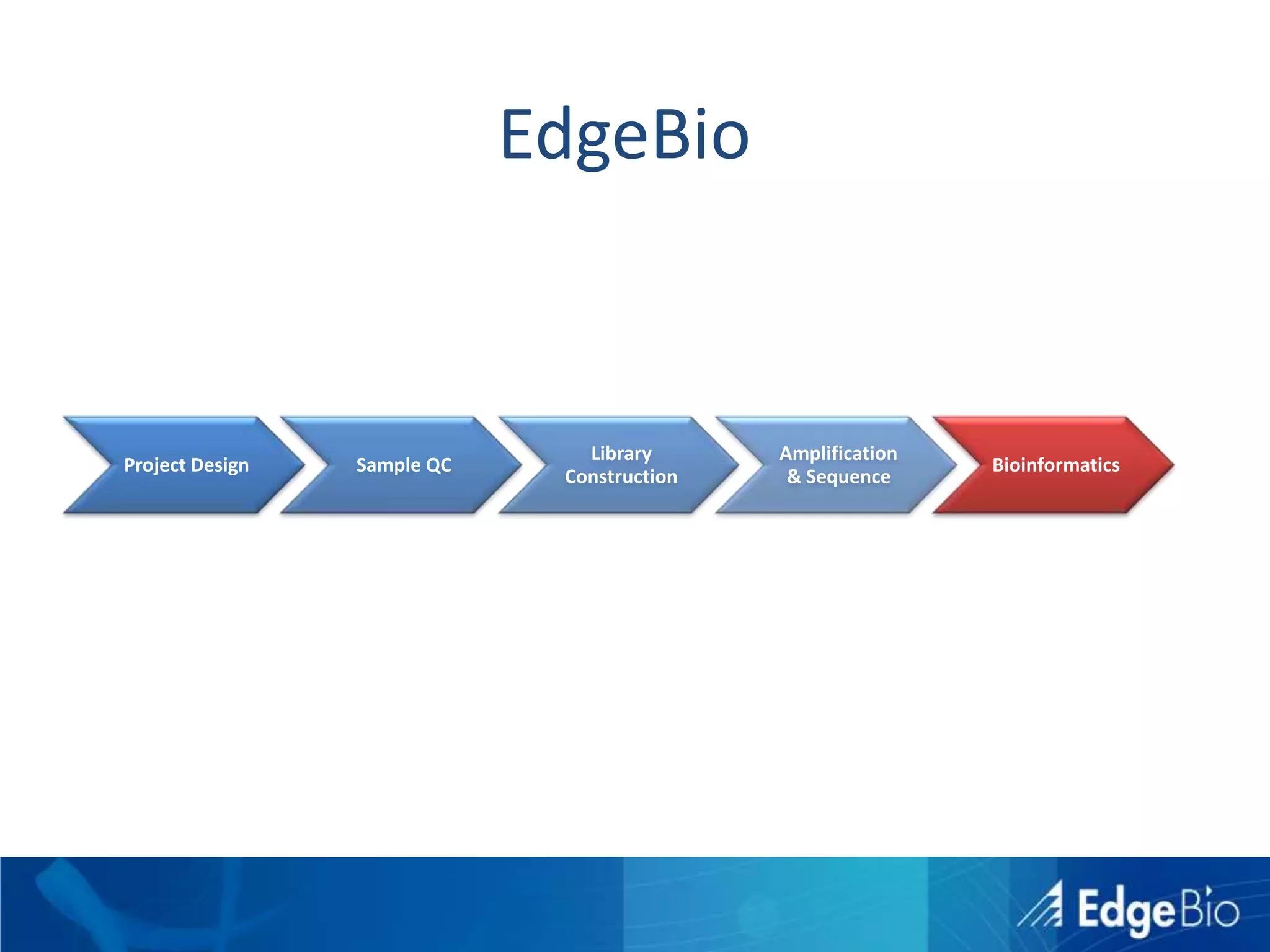






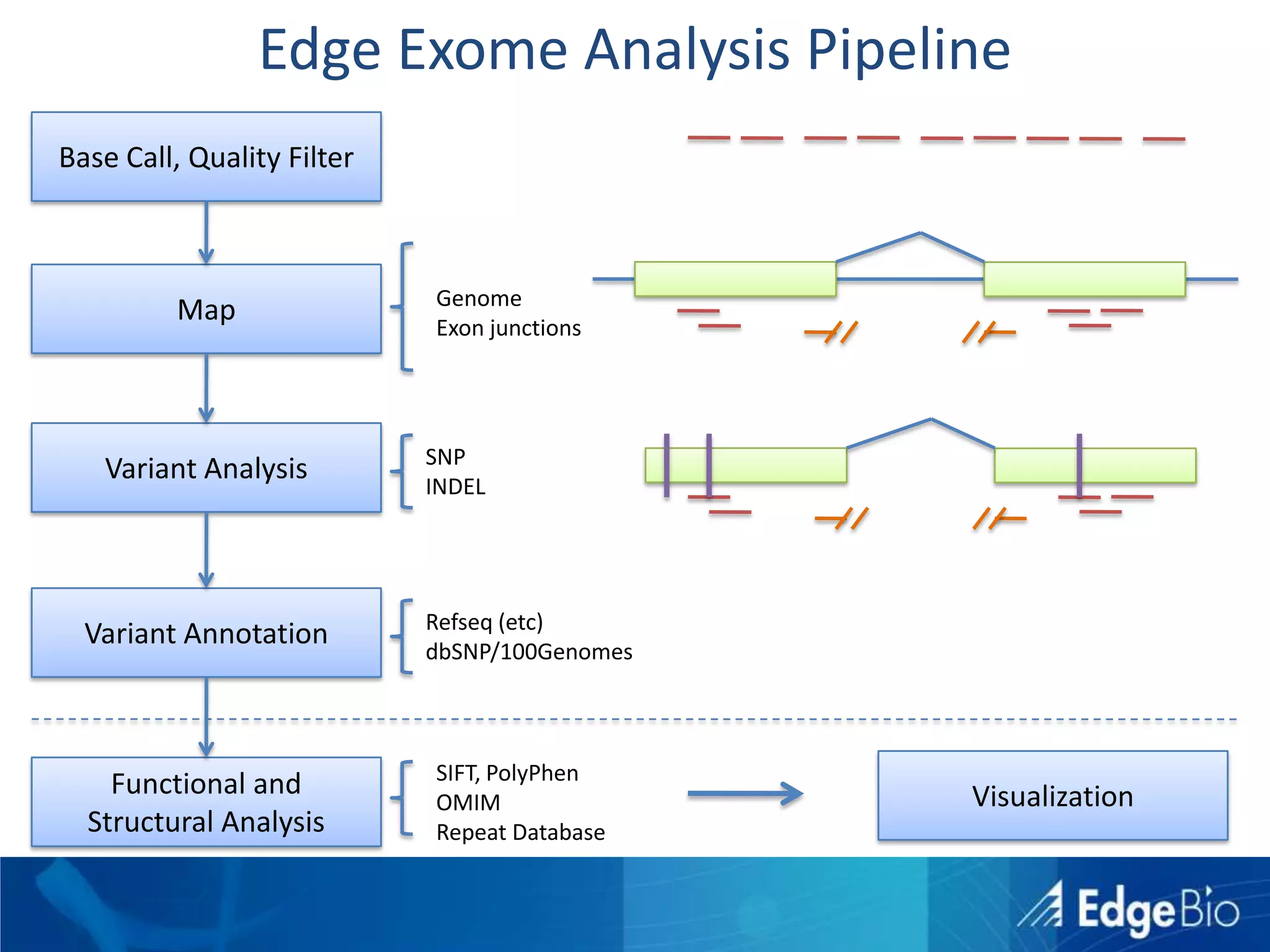



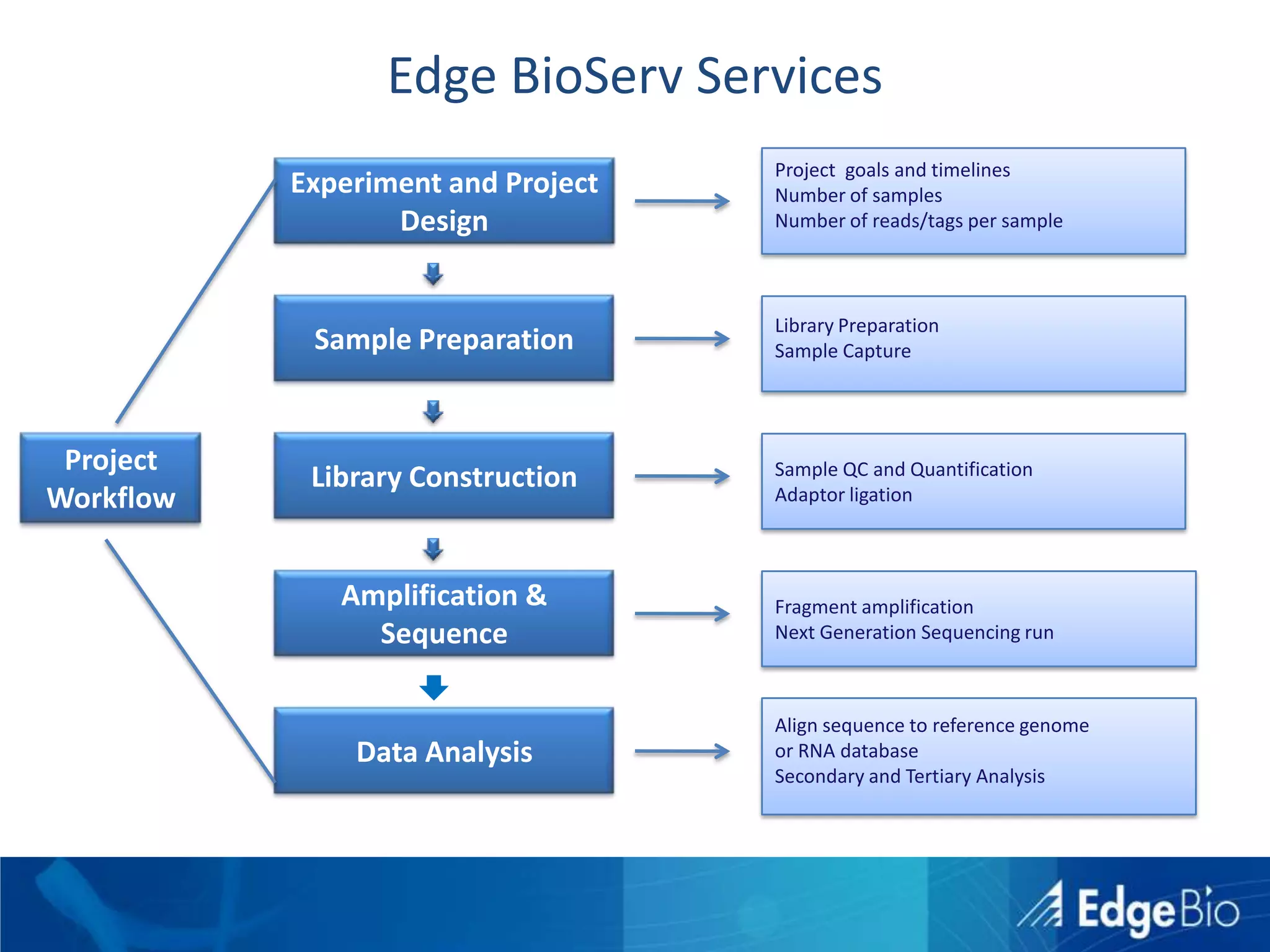


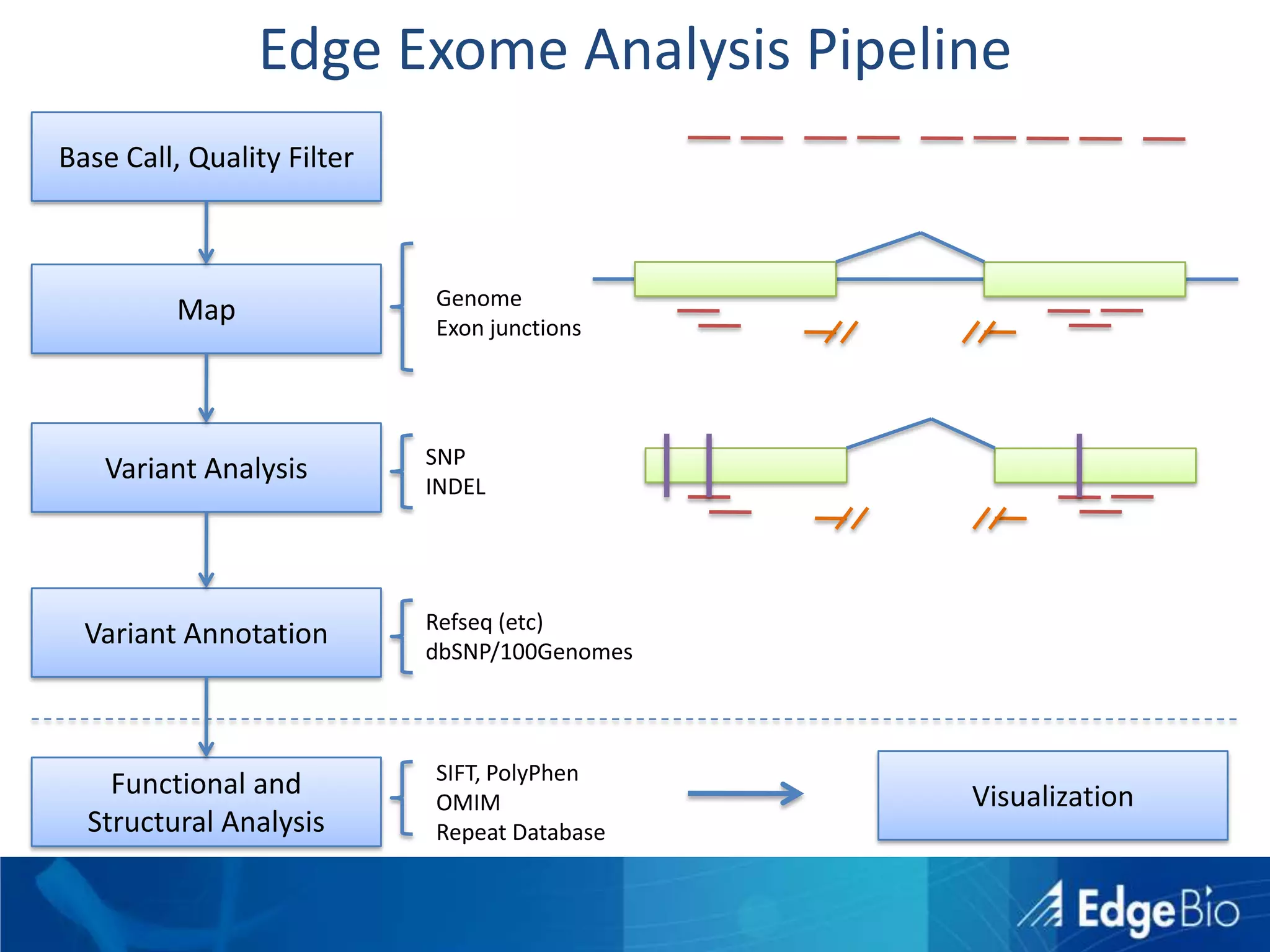
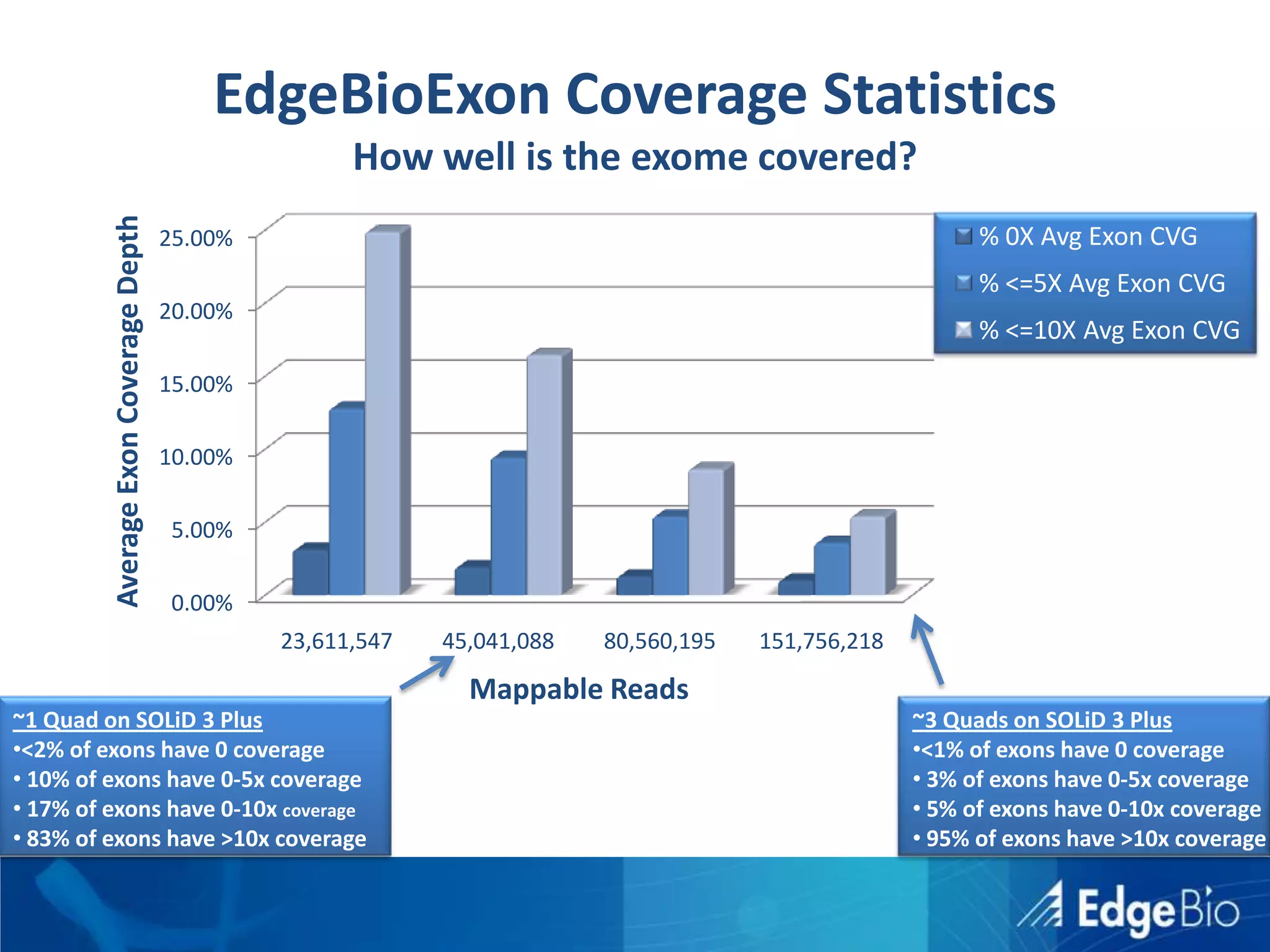








This document discusses science as a service (SaaS) and next-generation sequencing (NGS) data analysis. It summarizes challenges with exponential growth of NGS data, including data management, storage, analysis and sharing. It introduces Edge Bio's approach of distributing computational problems across cloud and HPC resources to avoid bottlenecks. Edge Bio provides full-service NGS analysis pipelines leveraging both commercial and open-source tools.












































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)










