Statistical model forCategorical data
The methods used in analysis of categorical variables
are:
Chi-squared Test
Logistic Regression
3.
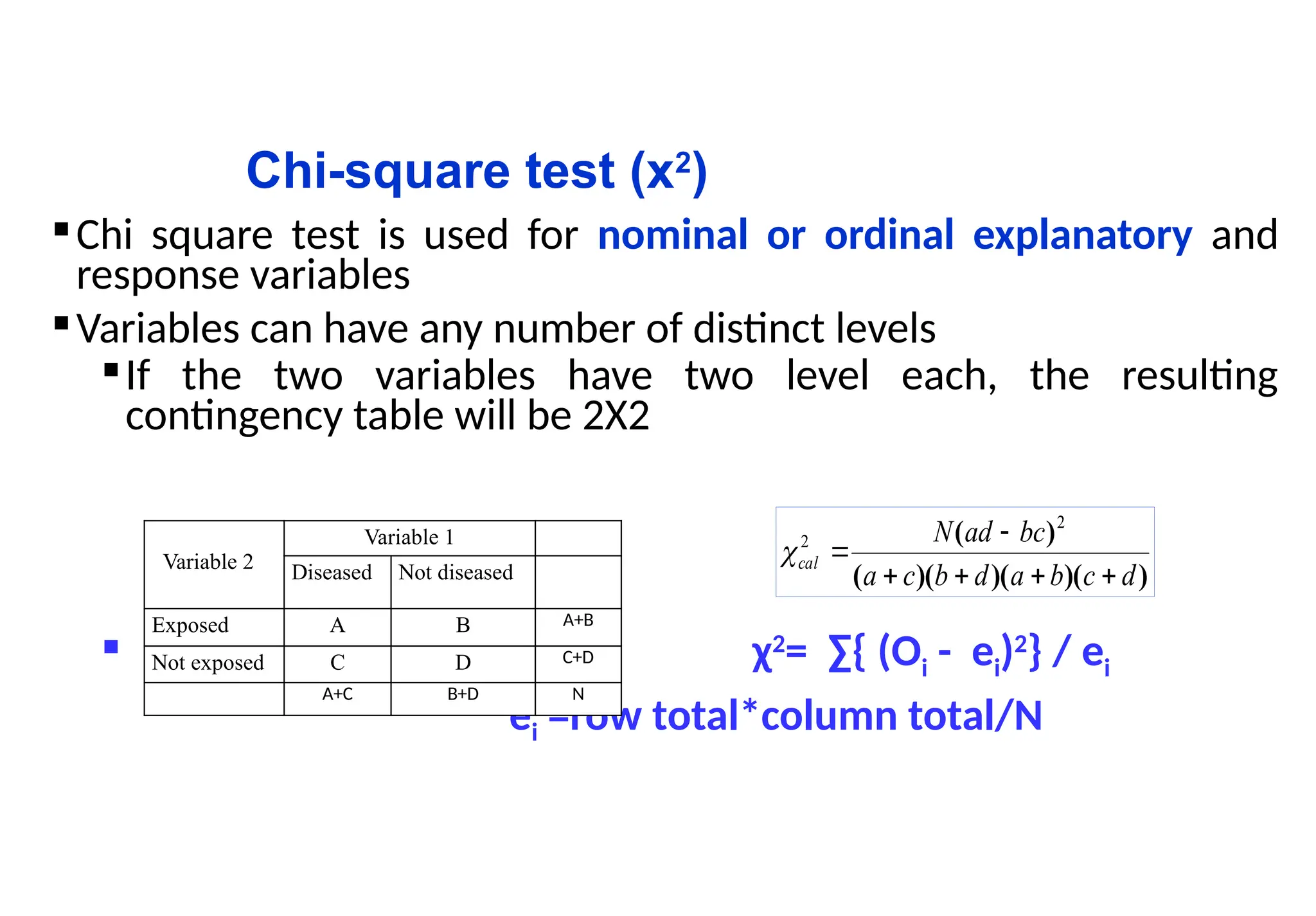
Chi-square test (x2
)
Chisquare test is used for nominal or ordinal explanatory and
response variables
Variables can have any number of distinct levels
If the two variables have two level each, the resulting
contingency table will be 2X2
χ2
= ∑{ (Oi - ei)2
} / ei
ei =row total*column total/N
Variable 2
Variable 1
Diseased Not diseased
Exposed A B A+B
Not exposed C D C+D
A+C B+D N
)
)(
)(
)(
(
)
(
d
c
b
a
d
b
c
a
bc
ad
N
cal
2
2
4.
Chi-square test (x2
)
Hypothesistesting steps in chi square test
State Hypotheses:
Null hypothesis (Ho): The classification variables are independent (no association)
Alternative hypothesis (Ha): There is an association between the variables
Determine test criteria: choose
Compute test statistic:
Find the table value at 2
(df=r-1* c-1)
Compute p-value: The larger the test statistic value, the smaller the
p-value
Decision: reject H0 if p –value < 0.05 or if 2
calculated > 2
tabulated
5.
Chi-square test (x2
)…
Ingeneral chi-squared test measures the disparity
between observed frequencies (data from the
sample) and expected frequencies.
The Chi-squaredtest is valid
If no observed cell is 0
No more than 20% of expected cell is less than 5
6.
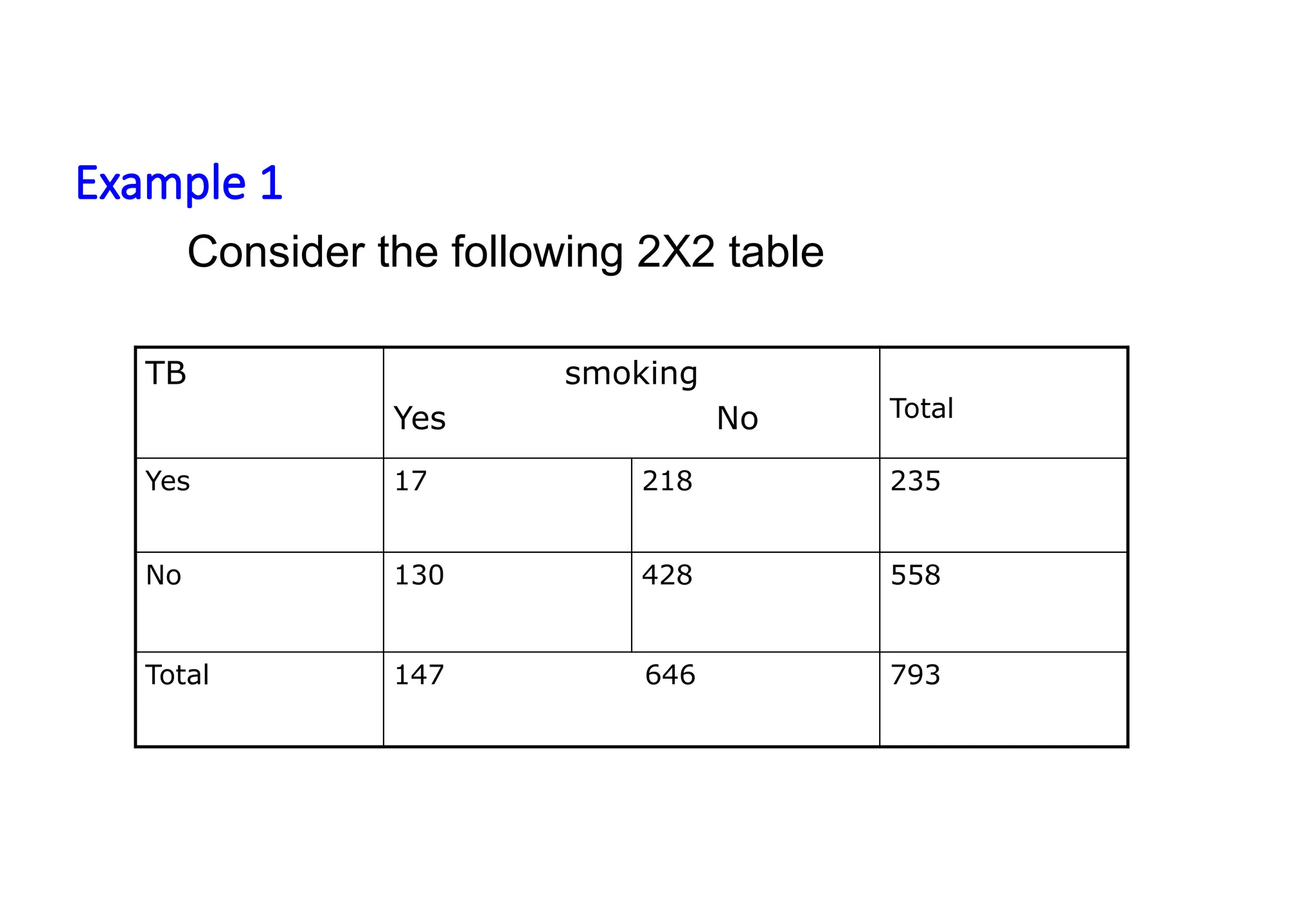
Example 1
TB smoking
YesNo Total
Yes 17 218 235
No 130 428 558
Total 147 646 793
Consider the following 2X2 table
7.
Example 1
Step1: hypothesis
HO : Pr(TBsmoker)= Pr(TBnon smoker)
HA : Pr(TBsmoker) ≠ Pr(TBnon smoker)
Step 2: Test statistics
χ2
= __N (ad-bc)2
__= (17*428-218*130)2
*793= 28.26
nD nND nE nNE 235*559*147*646
χ2
calculated > χ2
tabulated
Step 3: critical value χ2
= 3.84
Step 4: Decision reject the null hypothesis
Conclusion=there is an association between smoking and TB
8.
Logistic regression model
A logistic regression model predicts a dependent variable by analyzing the
relationship between one or more existing independent variables.
Logistic regression is part of a category of statistical models called
generalized linear models.
We're only modeling the mean, not each individual value of Y (no error
term)
Logistic regression and least squares regression are almost identical
Both methods produce prediction equations
In both cases the regression coefficients measure the predictive
capability of the independent variables
9.
Binary Logistic regressionmodel
Response variable that characterizes logistic regression is what makes it
special
With linear least squares regression response variable is a continuous
variable
However with logistic regression, response variable is an indicator of some
characteristic, that is, a 0/1 variable( IT IS CATEGORICAL)
Results can be summarized in a simple 2 X 2
contingency table as
10.
Logistic Regression Model…
Dependent variable can take the value
1 for the event of interest with a probability p
0 with probability of failure 1-p
Independent or predictor variables in logistic regression can take
any form
Logistic regression makes no assumption about the distribution of
the independent variables
They do not have to be normally distributed, linearly related or
of equal variance within each group like linear regression do
We need to check model adequacy
11.
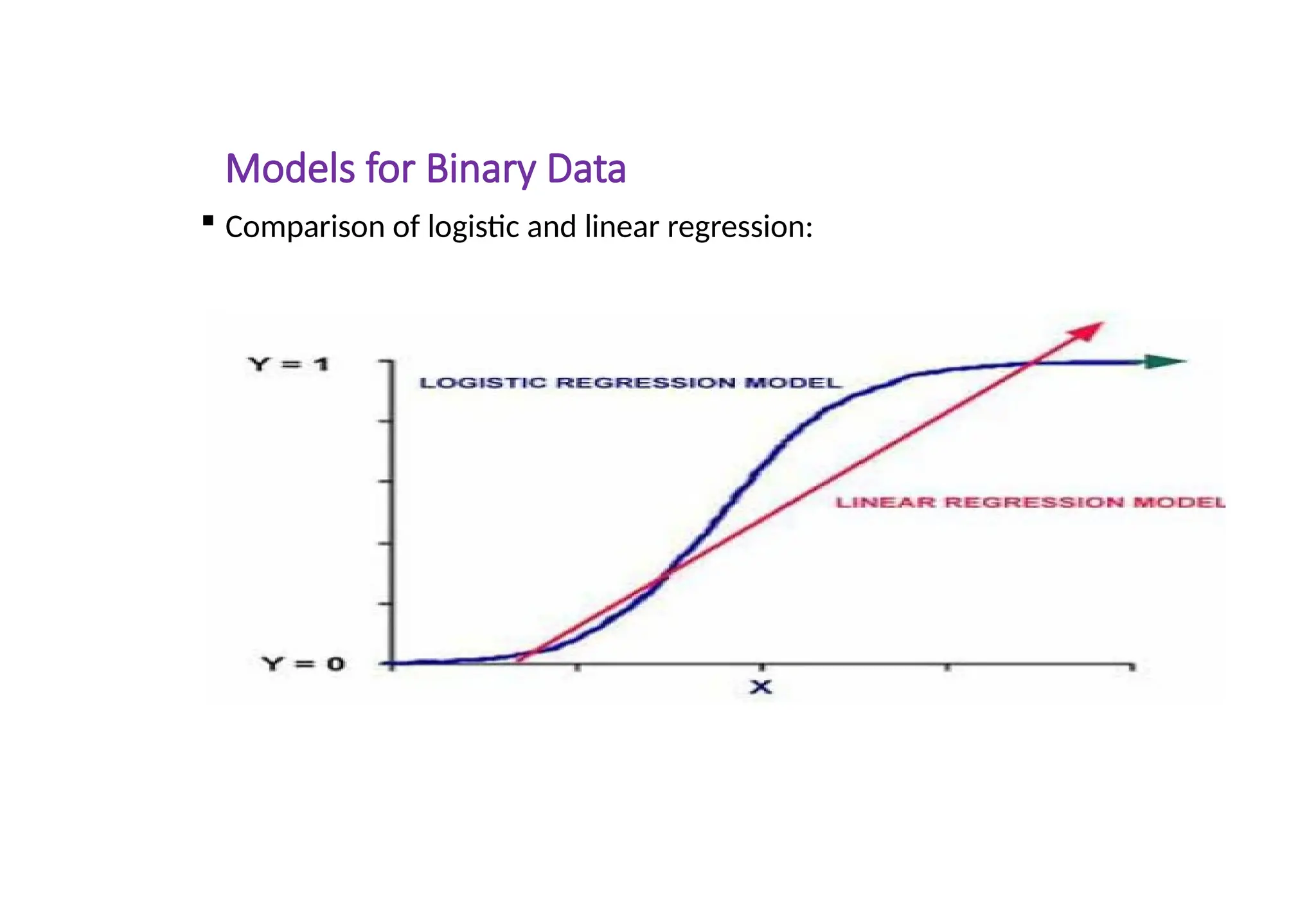
Models for BinaryData
Comparison of logistic and linear regression:
12.
Models for BinaryData
The constraints at 0 and 1 make it impossible to construct a linear
equation for predicting probabilities
With logistic regression we are interested in modeling the mean
of the response variable p in terms of an explanatory variable x
We could try to relate p and x through the equation
p(x) = α+ βx
Unfortunately, this is not a good model as long as β0, extreme
values of x will give values of α+ βx that are inconsistent with the
fact that 0 ≤p(x) ≤1
13.
Models for BinaryData
The logistic regression solution to this difficulty is to transform
the odds (p/(1- p))
using the natural logarithm (log( p(x)/(1-p(x)))
We use the term log odds for this transformation
Assuming the response variable has only one explanatory
variable x, log odds is a linear function of the explanatory
variable:
14.
Models for BinaryData
In the model α is the intercept and β is the slope
In addition, exp(β) is called the odds ratio between two values
of the exposure variable
How do we estimate the parameters of this relationship?
We need some method corresponding to the Least Squares
method used for linear regression models which is the
Maximum Likelihood estimation (MLE)
15.
Likelihood Function andMaximum Likelihood Estimation
Maximum likelihood estimate of a parameter is the parameter
value for which the probability of the observed data takes its
greatest value
It is the parameter value at which the likelihood function takes
its maximum
16.
Logistic Curve
Thelogistic curve relates the independent variable, X, to the dependent
variable
The formula to do so may be written either
a = log odds of disease
in unexposed
b = log odds ratio associated
with being exposed
e
b
= odds ratio
βx
α
P
-
1
P
log
e
P
-
1
P βx
α
17.
Interpretation of b
•b= increase in log-odds for a one unit increase in x (Test of the
hypothesis that b=0 )
• OR=increase in odds of event for one unit increase in x ((Test of
the hypothesis that OR=1 )
• OR=1 No effect
• OR>1 Risk
• OR<1 Protective
18.
Example
Consider the dataon HIV test result and the variables age, sex,
residence and education status.
Dependent variable: HIV test result
Independent variable: age, sex, residence and education status.
The response variable is dichotomous (positive and negative).
Thus the appropriate model is binary logistic regression
Example …
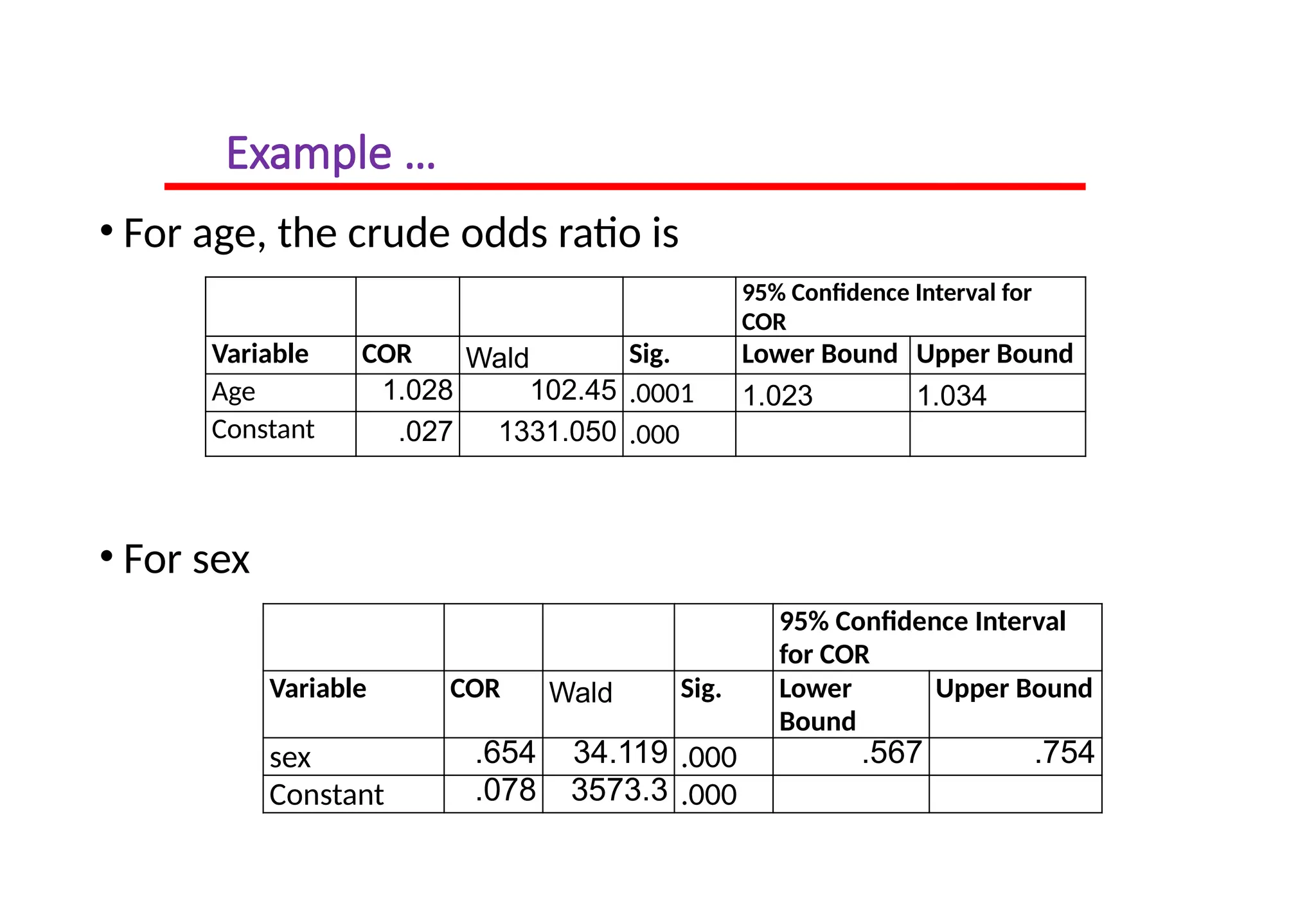
• Forage, the crude odds ratio is
• For sex
95% Confidence Interval for
COR
Variable COR Wald Sig. Lower Bound Upper Bound
Age 1.028 102.45 .0001 1.023 1.034
Constant .027 1331.050 .000
95% Confidence Interval
for COR
Variable COR Wald Sig. Lower
Bound
Upper Bound
sex .654 34.119 .000 .567 .754
Constant .078 3573.3 .000
21.
Multivariable Logistic Regression
More than one independent variable
Dichotomous, ordinal, nominal, continuous …
Interprétation of bi
Increase in log-odds for a one unit increase in xi with all the other xis
constant
Measures association between xi and log-odds adjusted for all other xi
i
i
2
2
1
1 x
β
...
x
β
x
β
α
P
-
1
P
ln
Logistic regression isa powerful statistical tool for estimating the
magnitude of the association between an exposure and a binary
outcome after adjusting simultaneously for a number of potential
confounding factors
24.
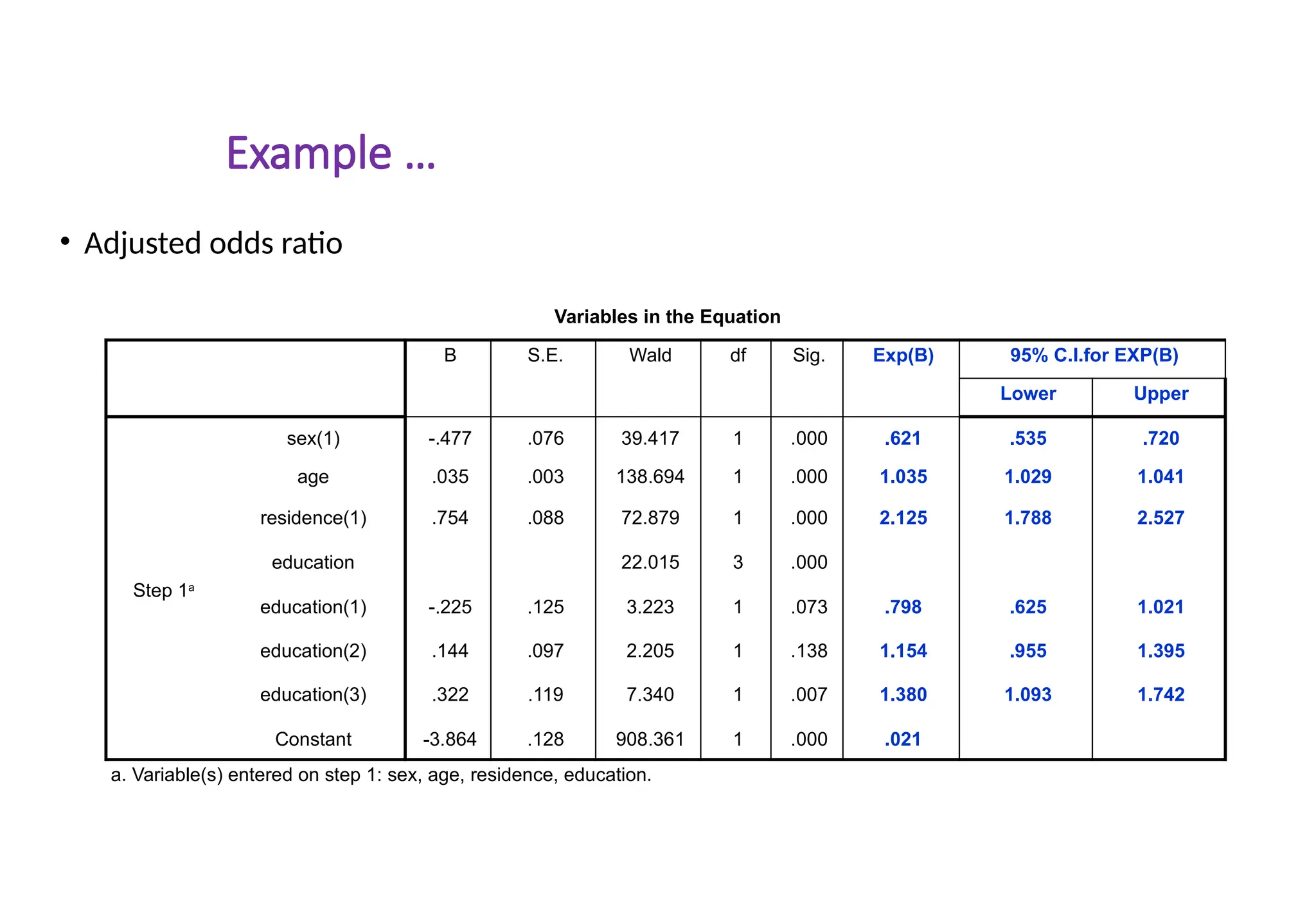
Crude and AdjustedOR
Odds ratios calculated using single independent variable are
sometimes called crude odds ratios
Adjusted for the presence of other factors in the regression equation
because the odds ratios are obtained simultaneously with all the factors
together
Adjusted odds ratios are less affected by confounding between the factors
Confidence intervals and p-value can be derived for odds ratio estimated
from logistic regression
Interpretation of these is the same as in the case of the crude odds ratios
25.
Hosmer and LemeshowTest
Hosmer -Lemeshow goodness- of - fit statistic
Used to assess whether the necessary assumptions for the
application of multivariable logistic regression are fulfilled
Computed as the Pearson chi-square from the contingency
table of observed frequencies and expected frequencies
A good fit as measured by Hosmer and Lemeshow's test will
yield a large p-value (>0.05)




























![logistic model final_pptx__corected_one[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/finalpptxcorectedone1-251124022241-c29356b7-thumbnail.jpg?width=640&height=640&fit=bounds)













































![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)