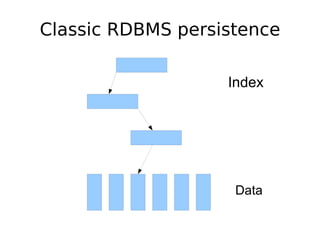
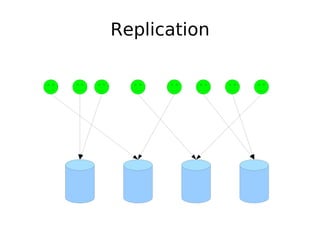
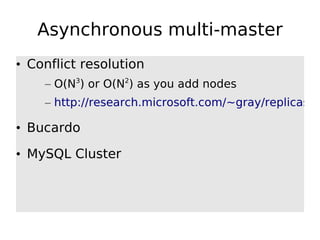
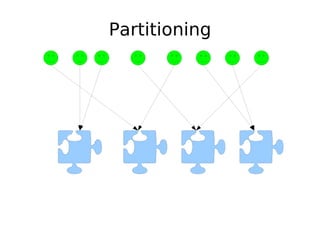
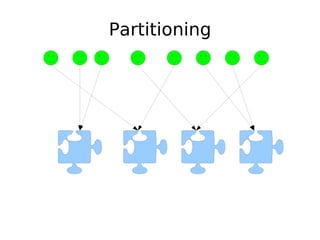
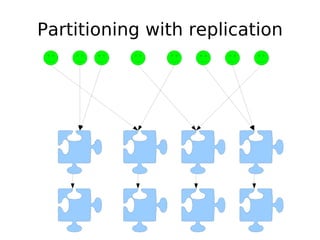
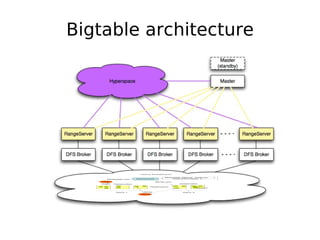
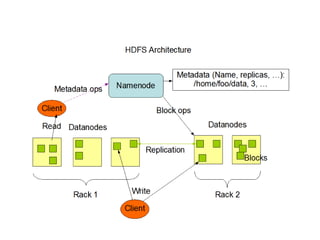
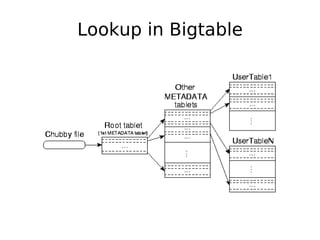
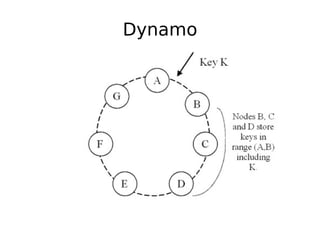
The document discusses database scalability, focusing on different replication types, partitioning methods, and the contrasts between traditional RDBMS and distributed databases like Bigtable and Dynamo. It highlights challenges in scaling reads and writes and introduces architectural considerations for coping with failure and maintaining consistency. The comparison of performance metrics indicates significant advantages of using distributed systems over traditional databases.


































![ColumnFamilies
keyA column1 column2 column3
keyC column1 column7 column11
Column
Byte[] Name
Byte[] Value
I64 timestamp](https://image.slidesharecdn.com/scalingdatabases-090729134110-phpapp01/85/What-Every-Developer-Should-Know-About-Database-Scalability-45-320.jpg)