Downloaded 11 times

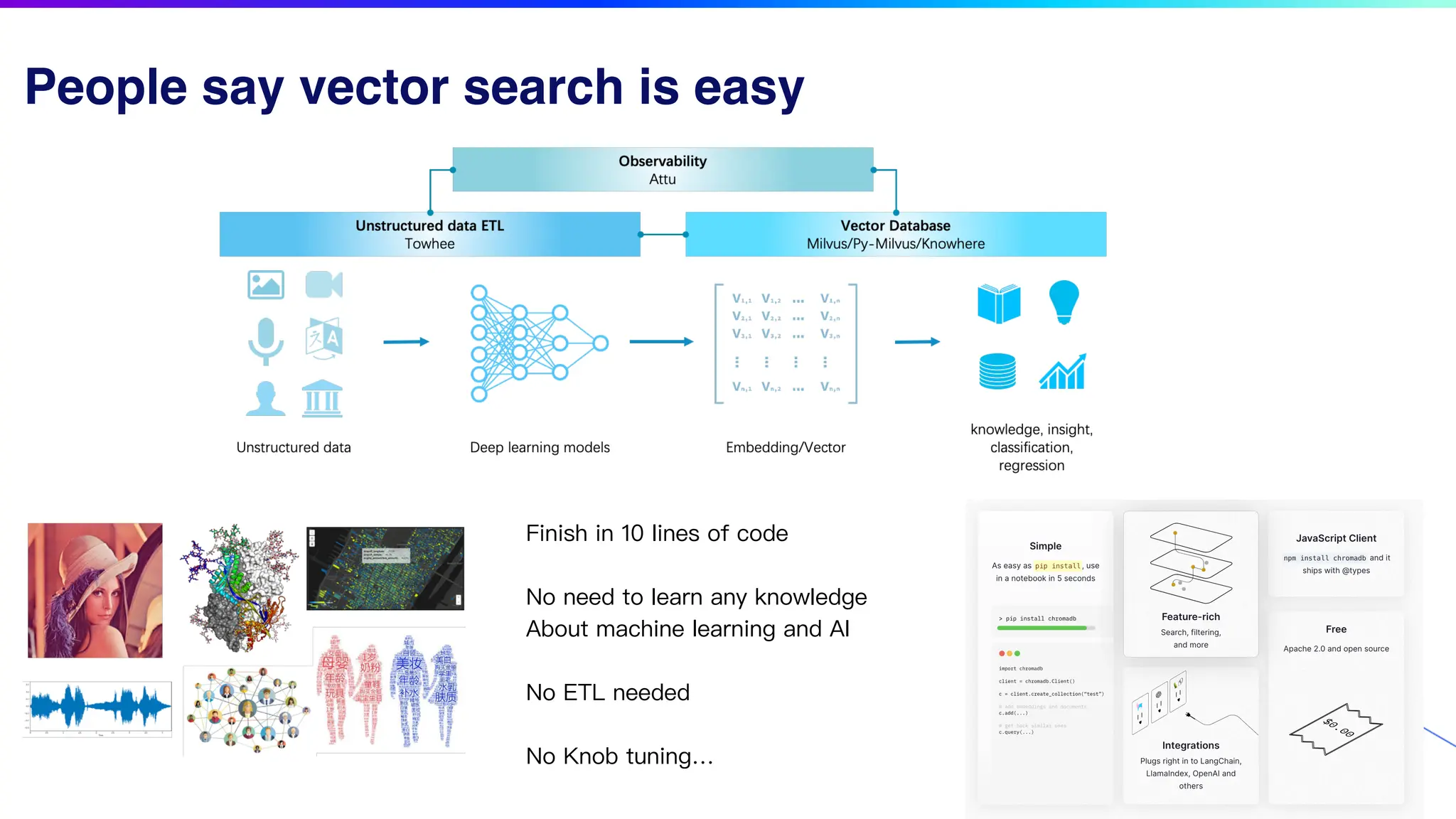
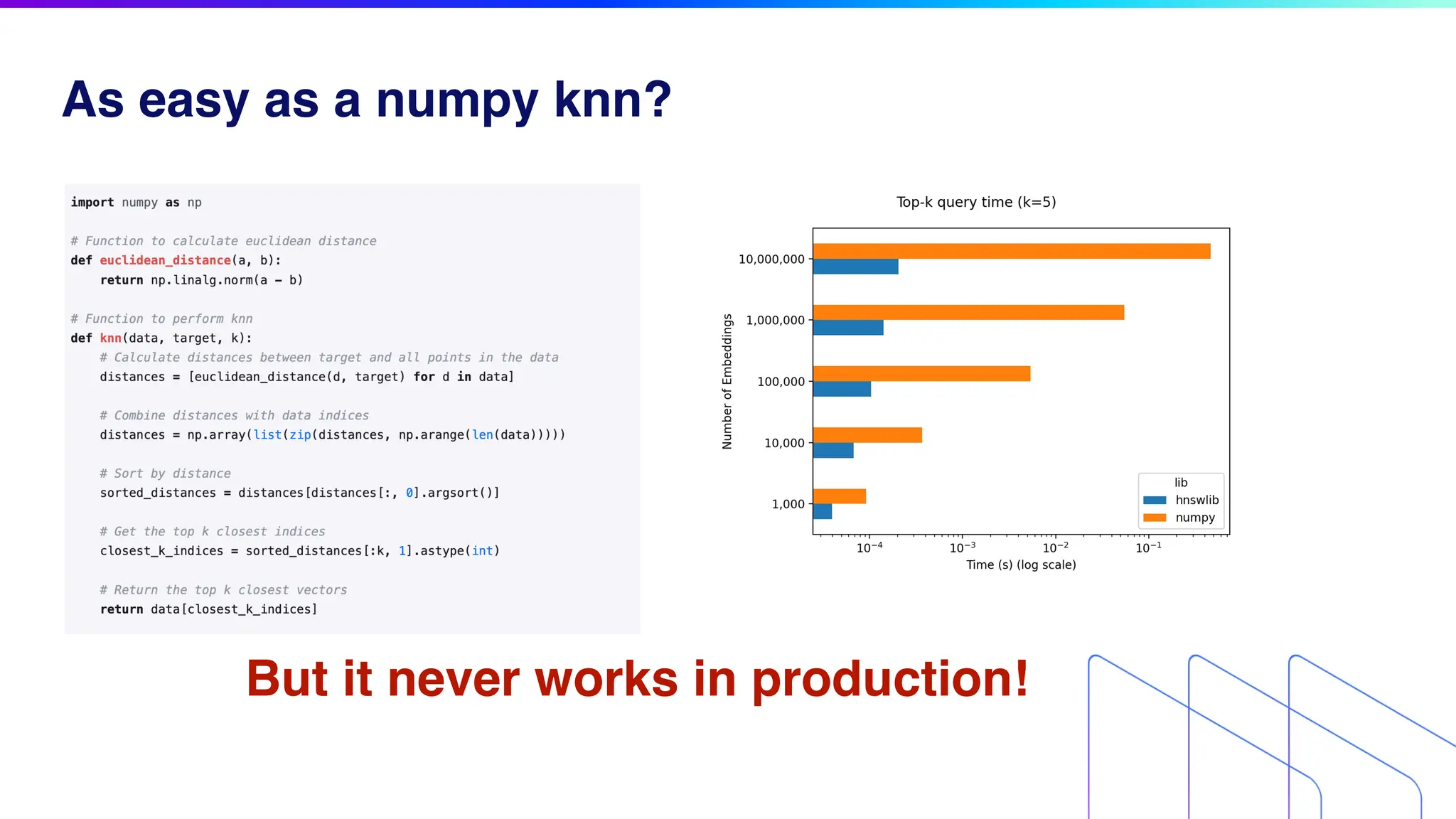



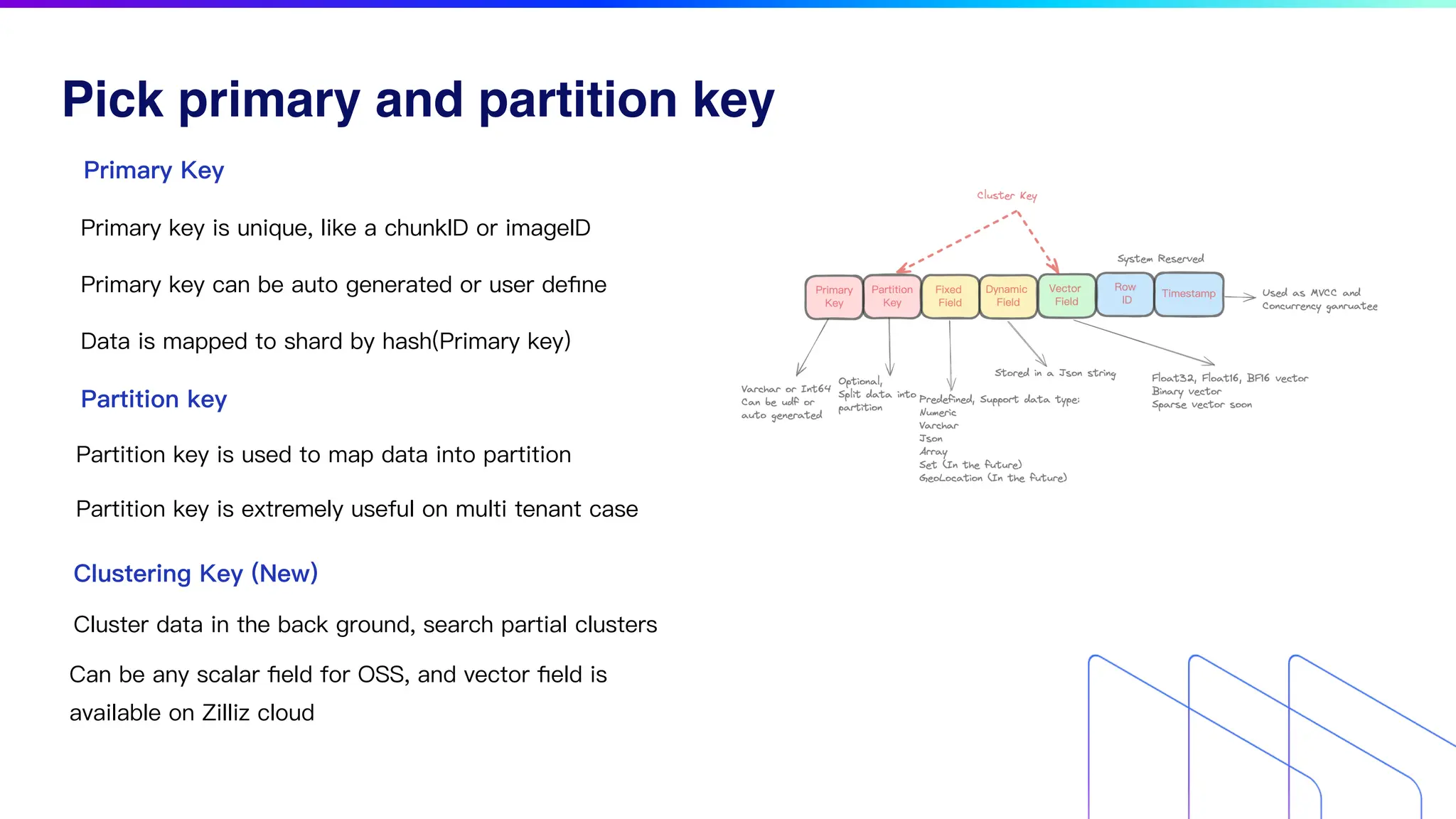

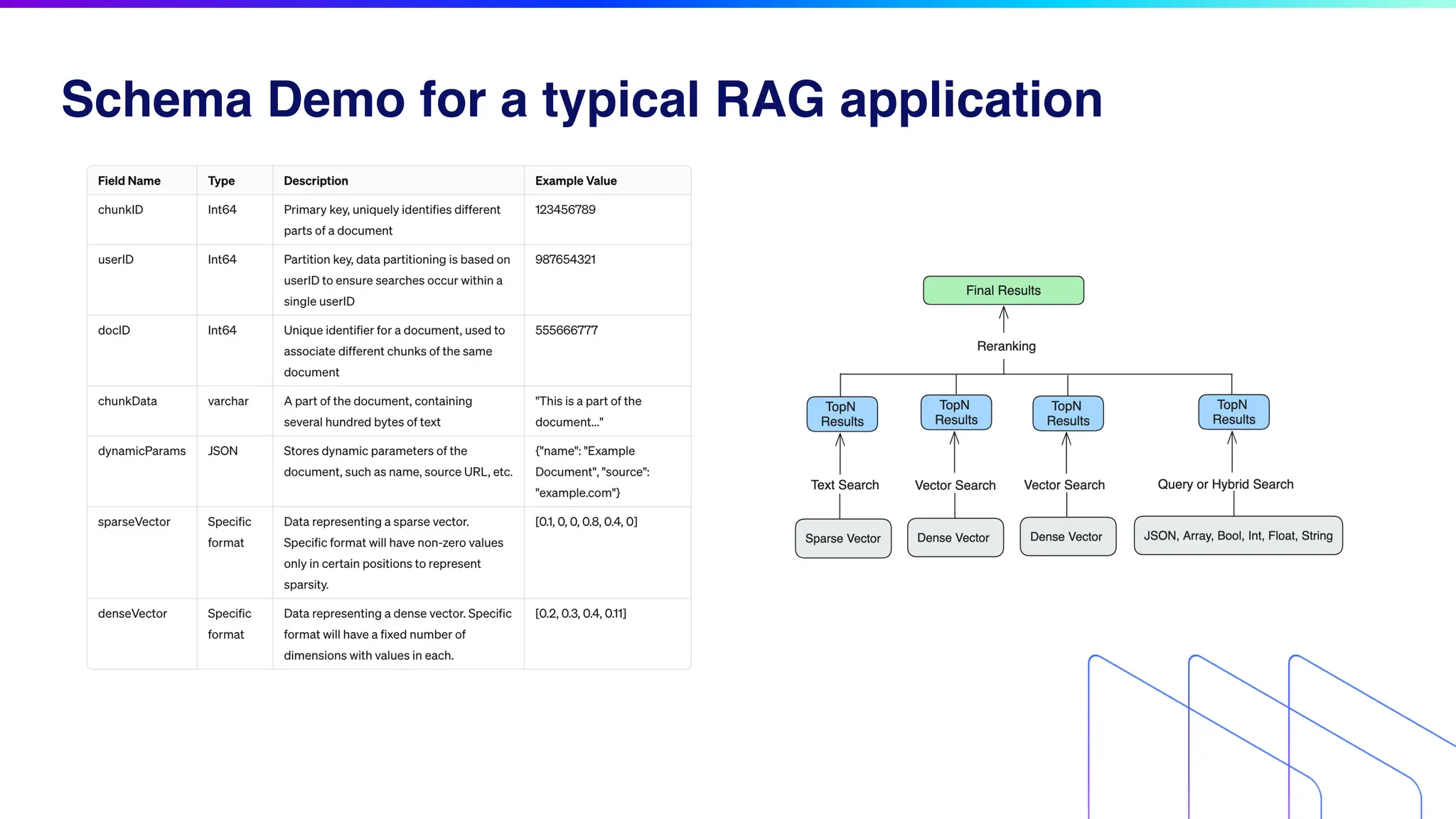
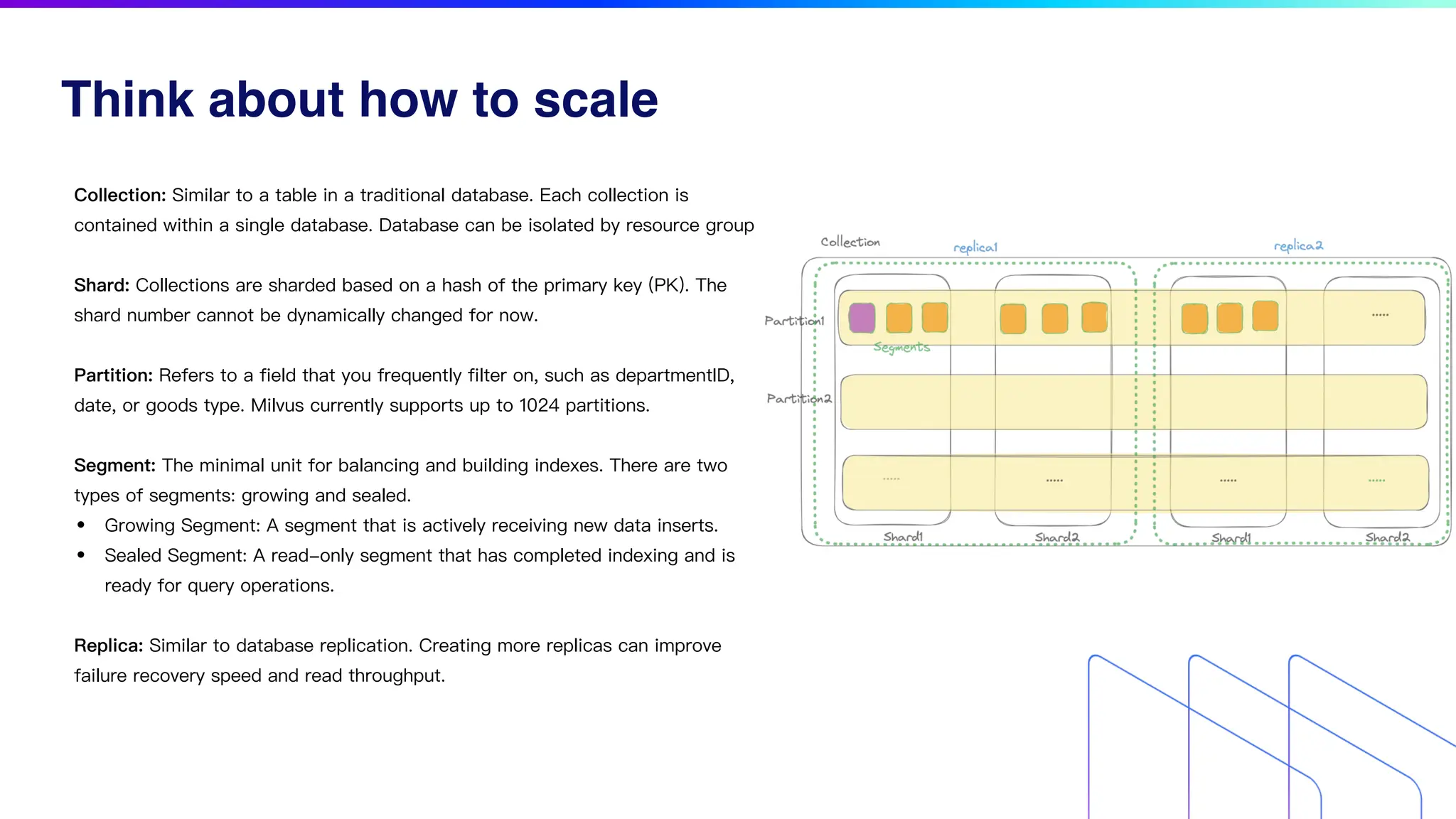

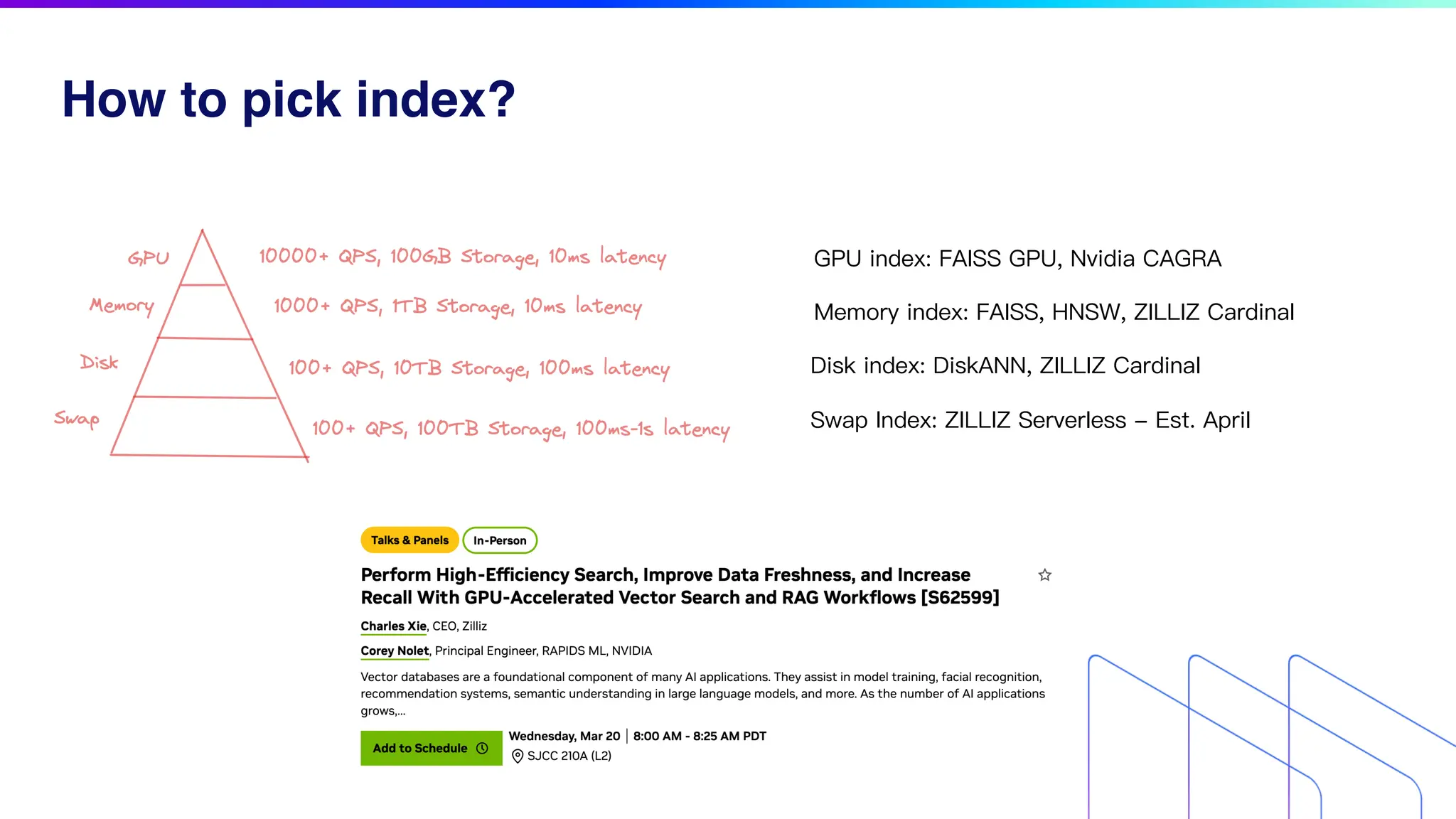
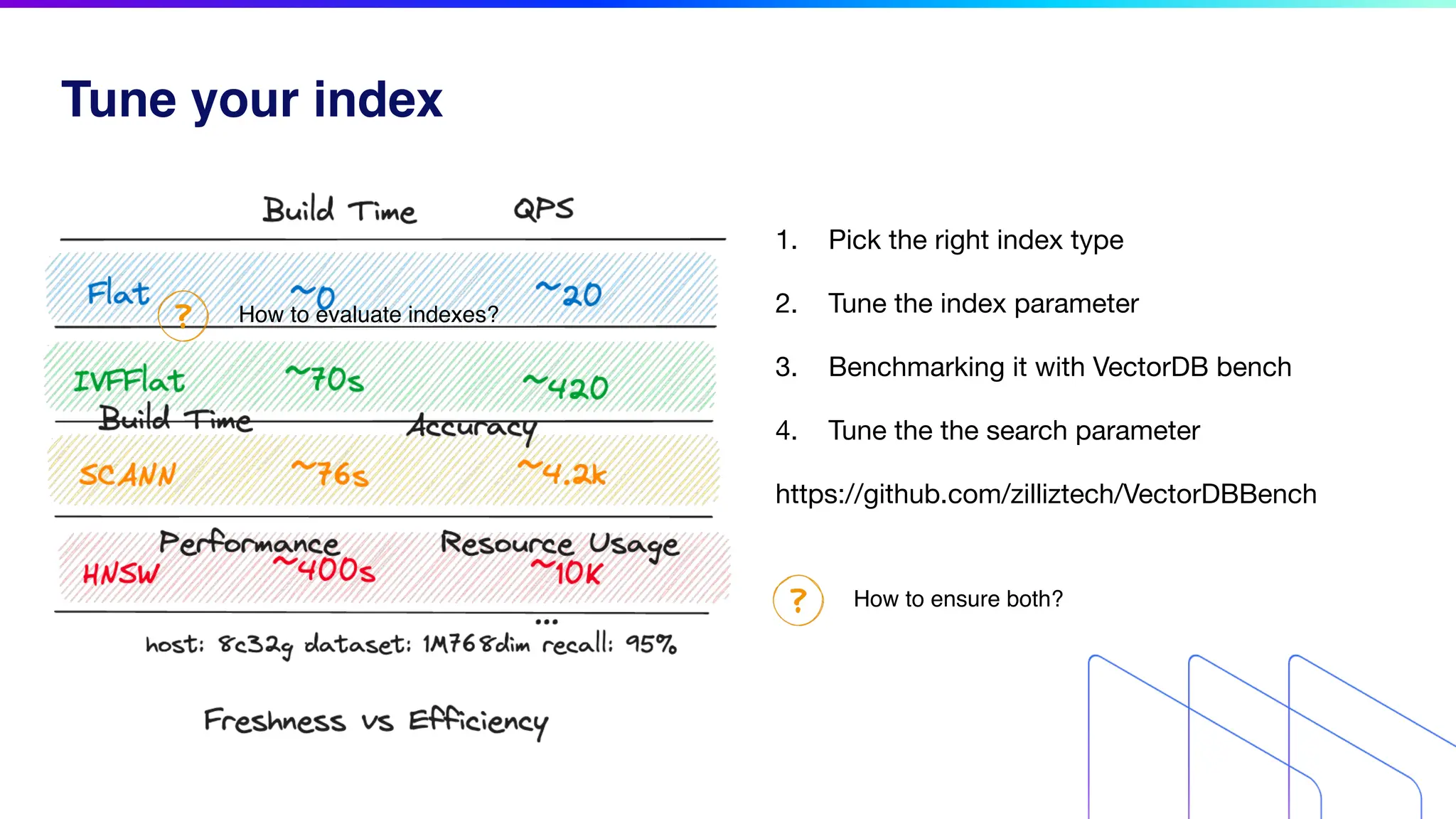
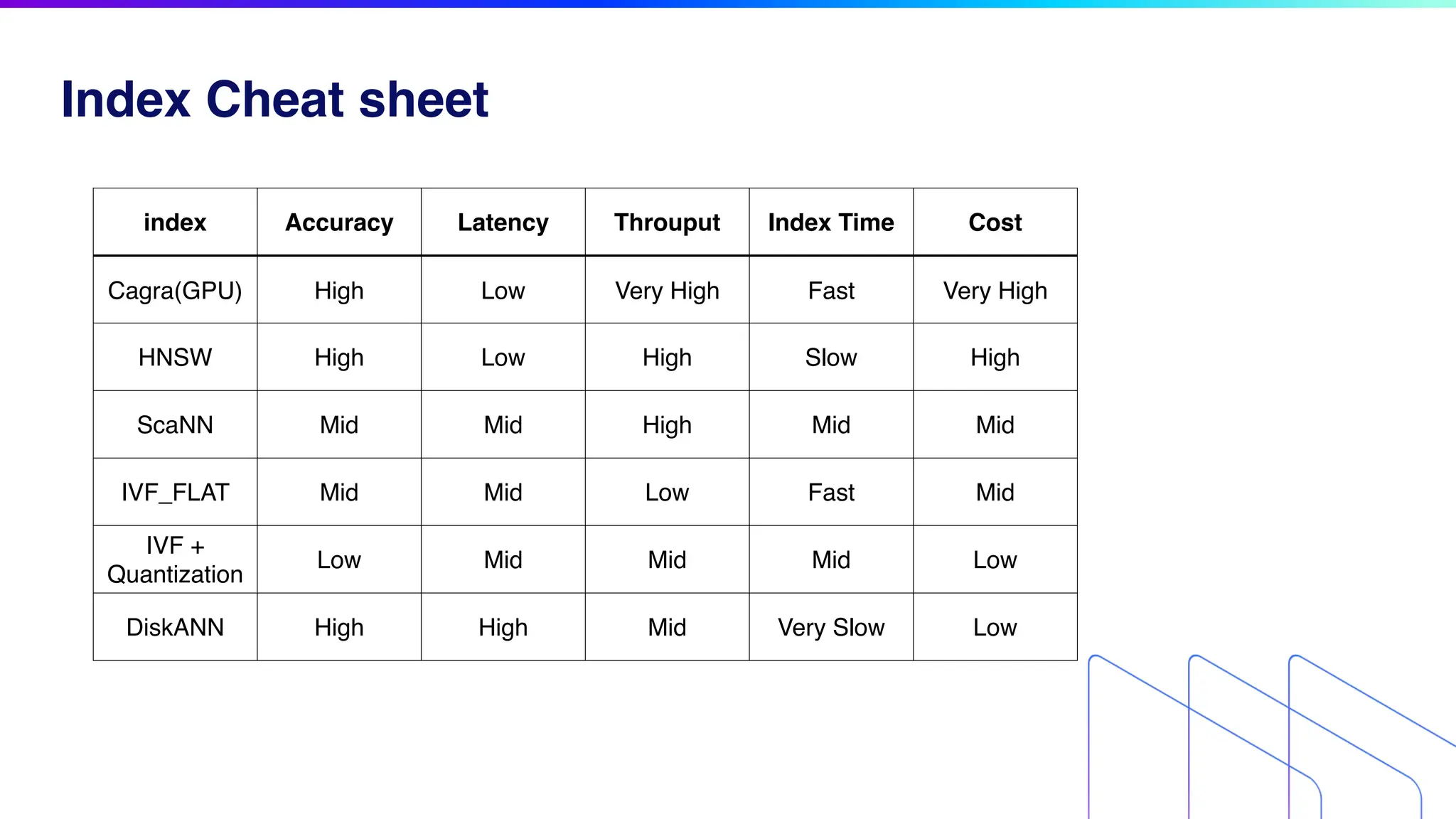


The document discusses key factors for optimizing performance in scalable vector search applications, emphasizing the importance of search quality, scalability, multi-tenancy, cost, and security. It outlines best practices for schema design, scaling collections, and index selection, providing practical examples and considerations for deploying vector databases in production. The document also highlights performance tuning and benchmarking techniques for different index types to enhance efficiency.













![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Secret X 팀] : XAI를 활용한 수능 영어영역 문제풀이](https://cdn.slidesharecdn.com/ss_thumbnails/xai-220728094640-df53ef35-thumbnail.jpg?width=640&height=640&fit=bounds)








































































