Downloaded 525 times

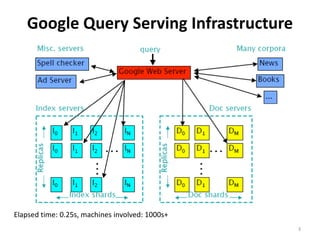







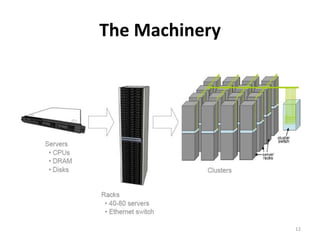
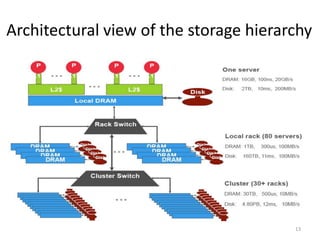






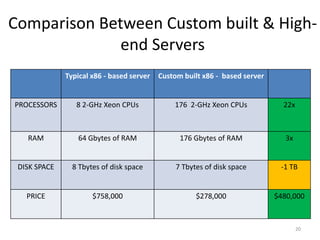



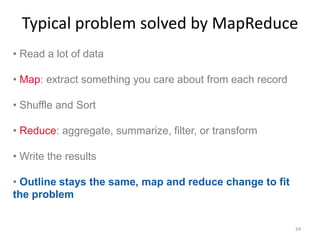



Google's search infrastructure uses a cluster architecture with thousands of machines to handle high query volumes. It employs techniques like PageRank to measure page importance, replicates data for reliability and availability, uses low-cost commodity hardware, and manages power usage. Key systems include the Google File System for storage and MapReduce for distributed processing of large datasets.























































































