



















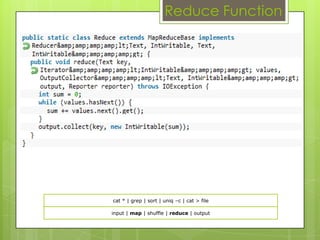



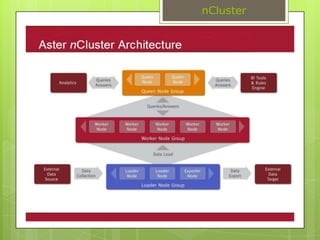


This document discusses big data, including how much data is now being collected, challenges with traditional database management systems, and the need for new approaches like Hadoop and Aster Data. It provides details on characteristics of big data, architectural requirements, techniques for analysis, and solutions from companies like IBM, Teradata, and Aster Data. Hadoop is discussed in depth, covering how it works, the ecosystem, and example users. Aster Data is also summarized, focusing on its massively parallel SQL layer and in-database analytics capabilities.

































![Rural urban linkages and public private partnership [compatibility mode]](https://cdn.slidesharecdn.com/ss_thumbnails/rural-urbanlinkagesandpublicprivatepartnershipcompatibilitymode-141227111352-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)



































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

















