Download as PDF, PPTX
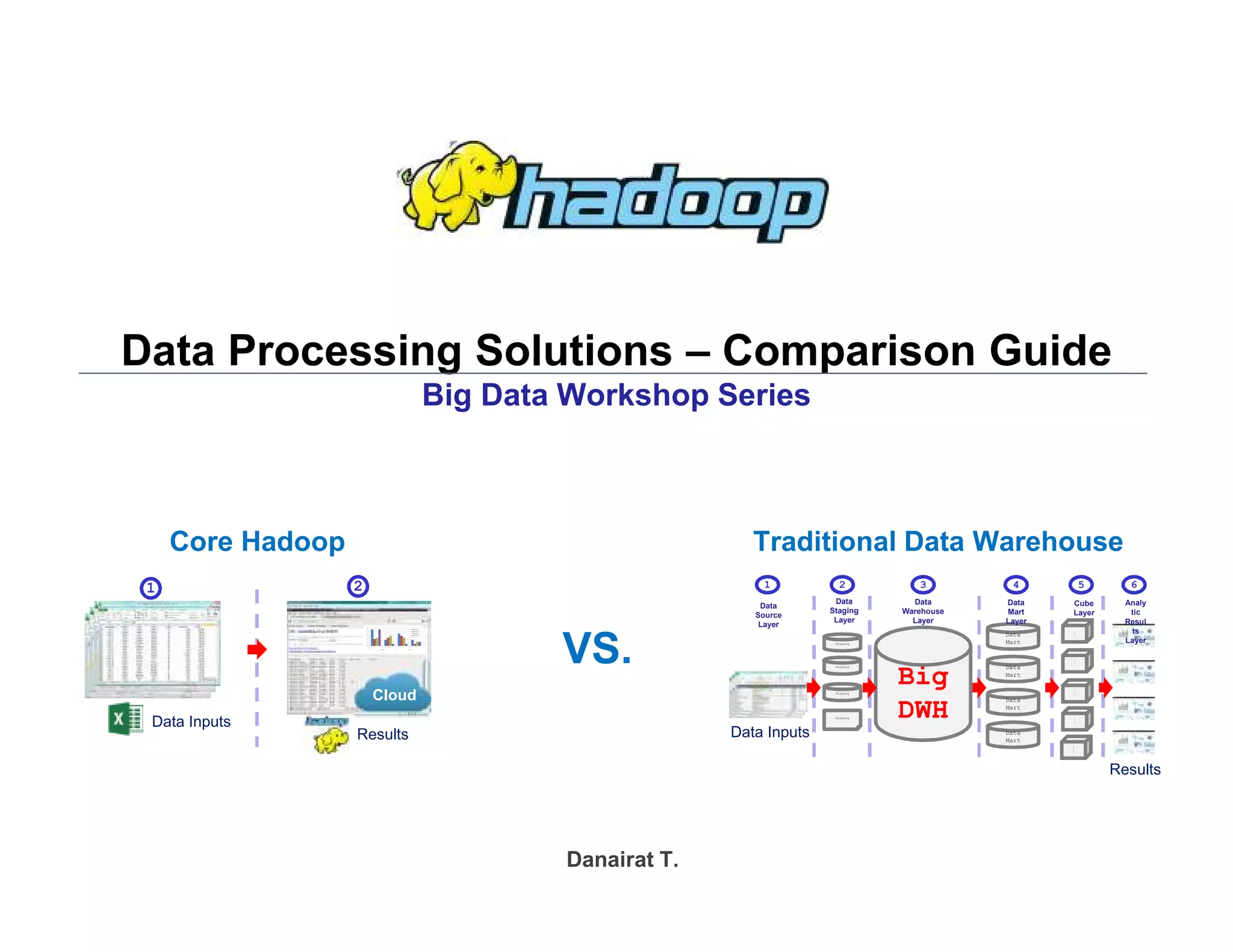
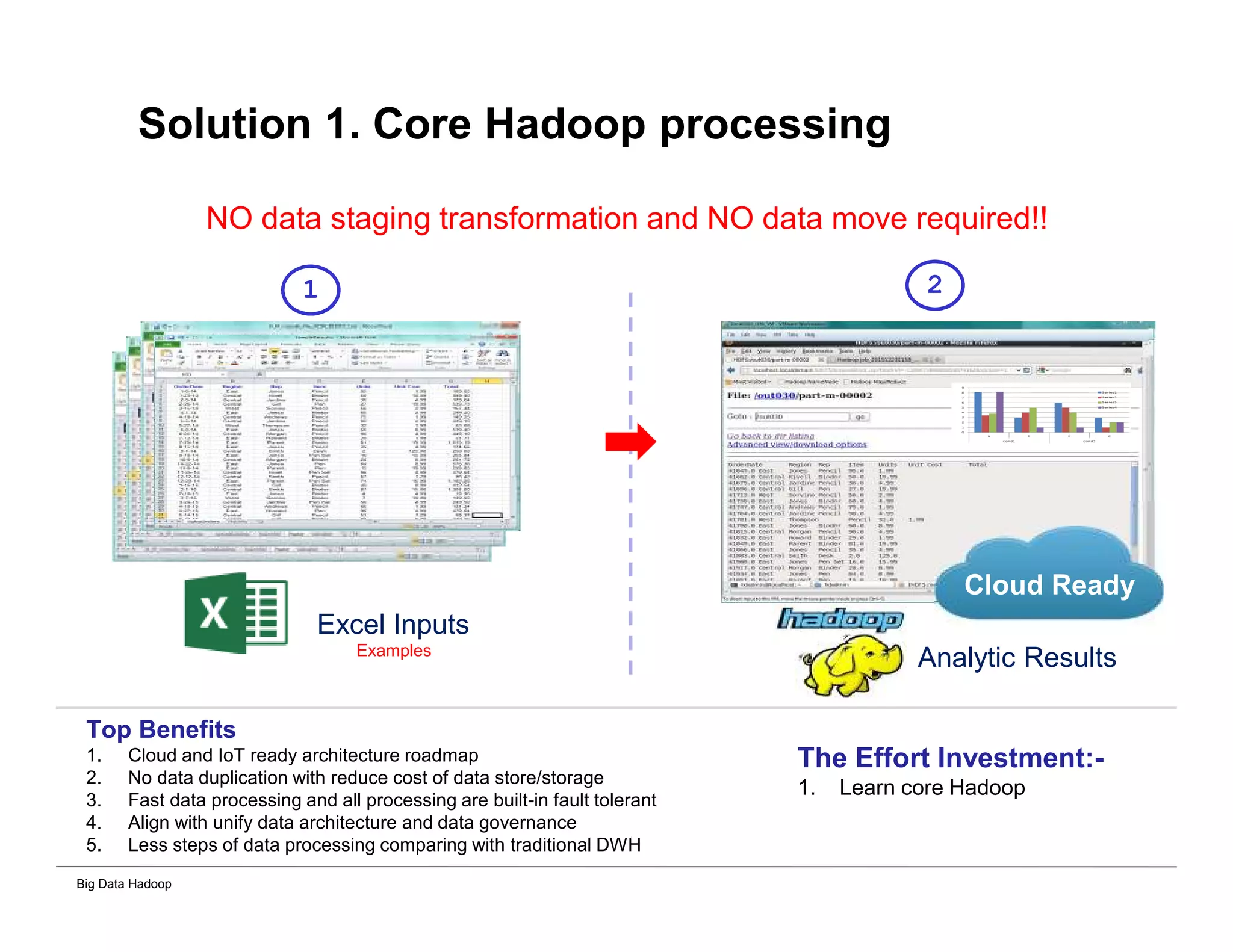
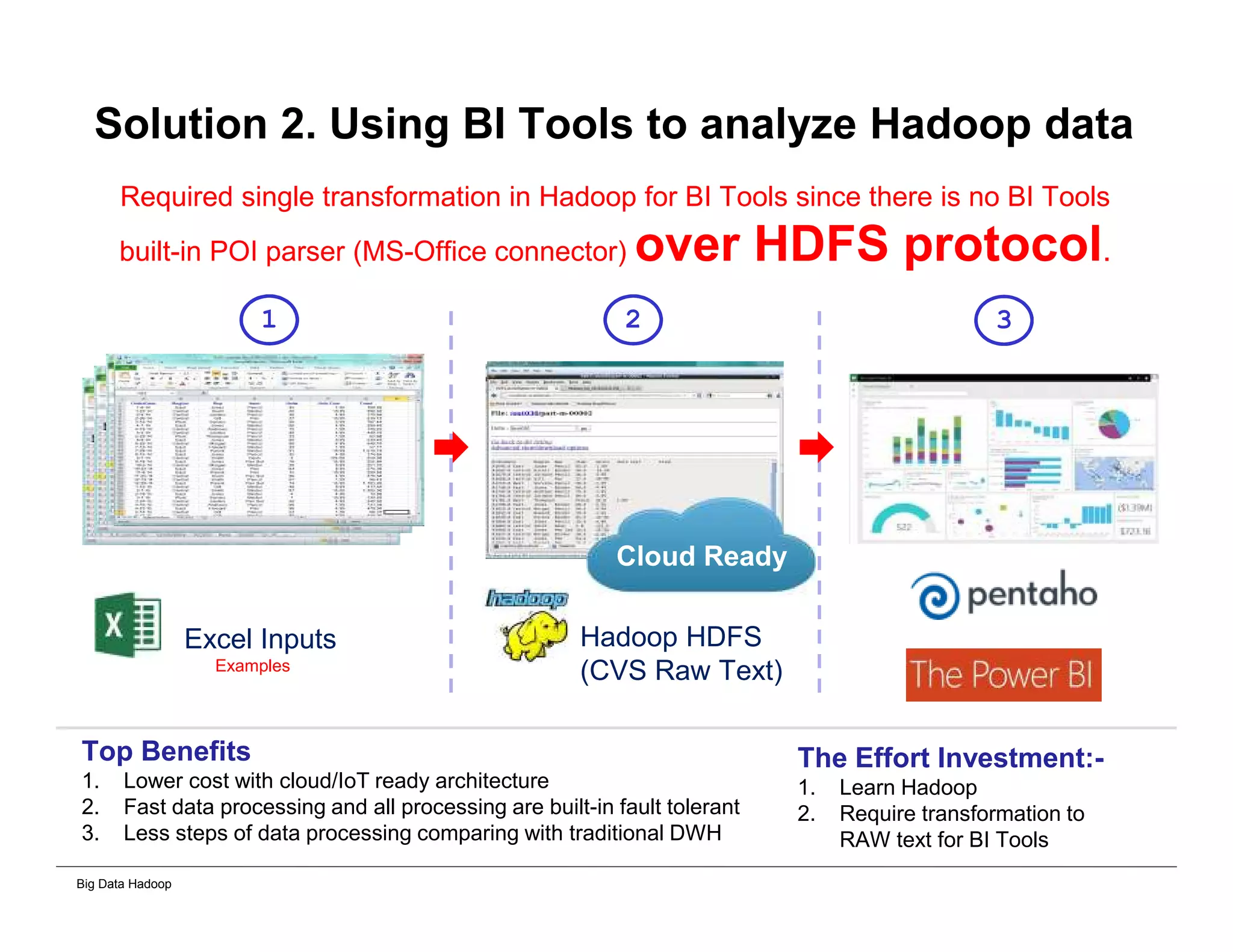
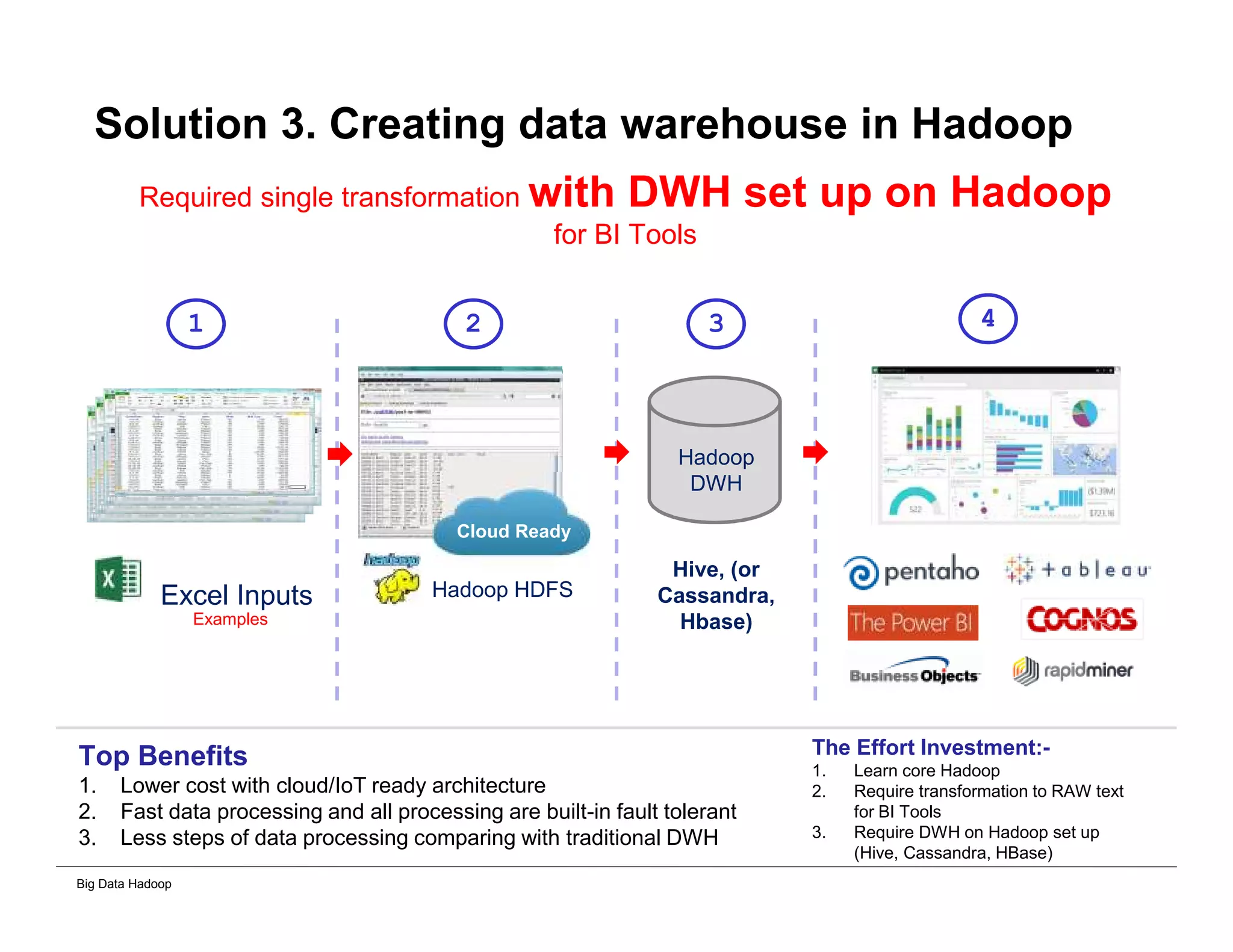
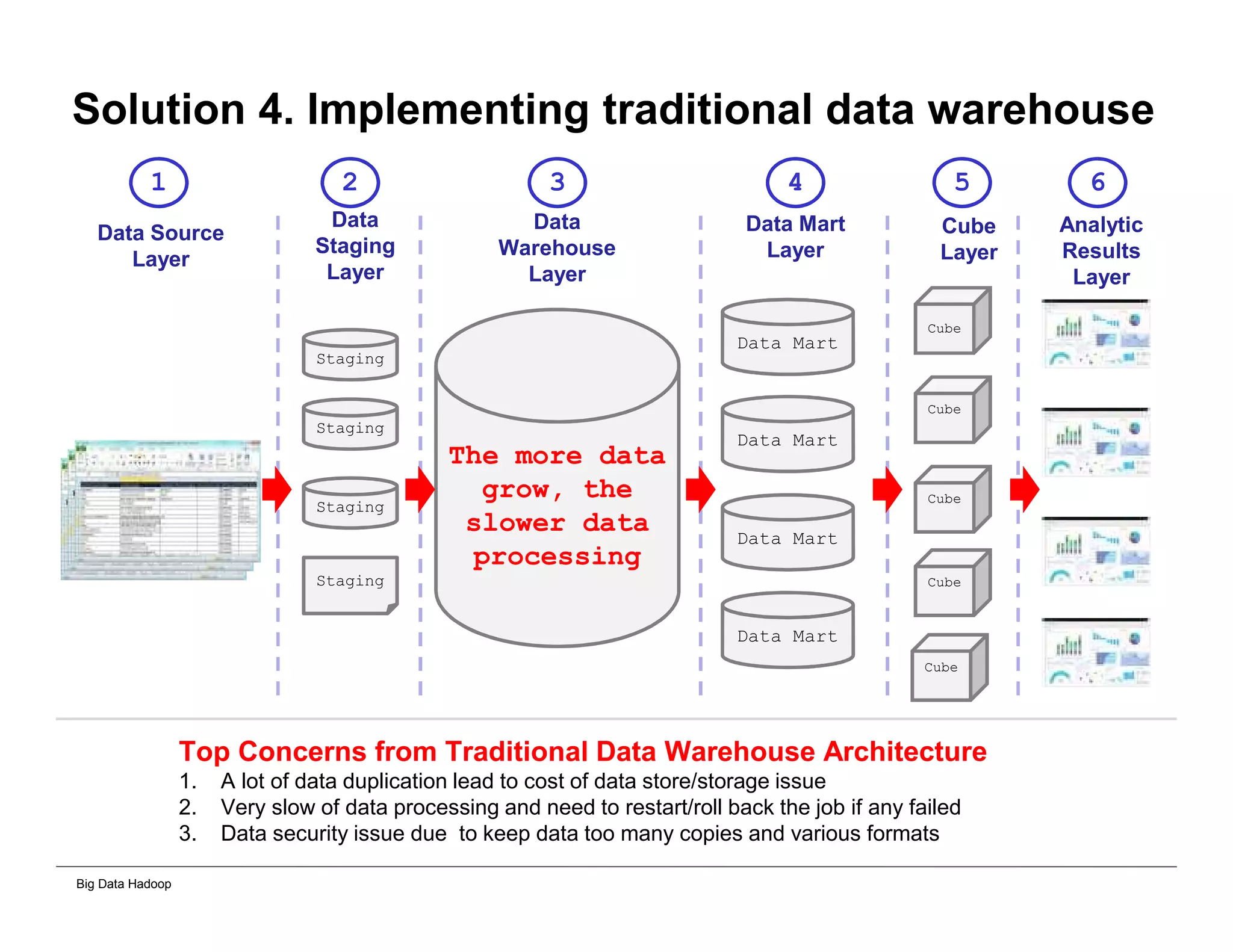
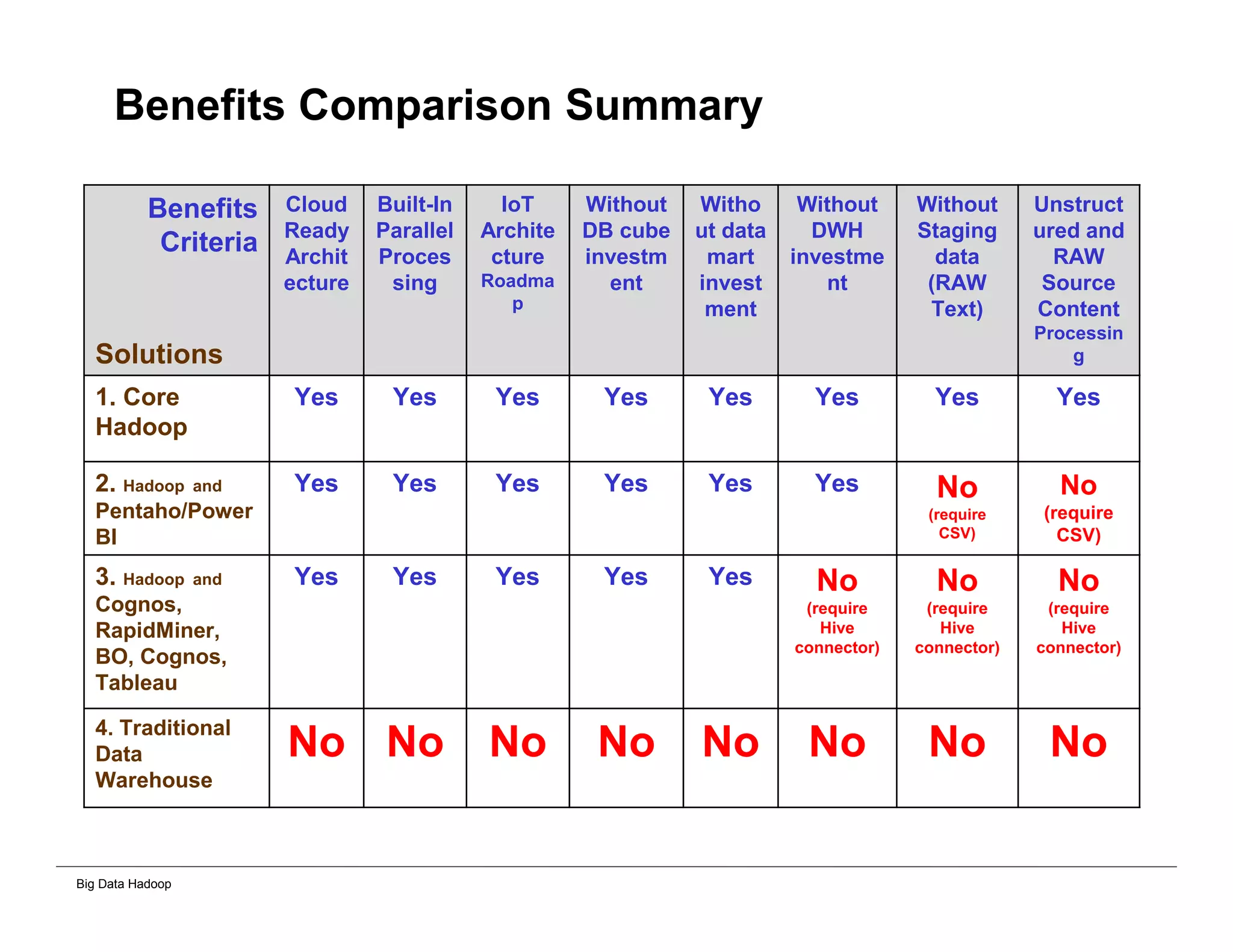

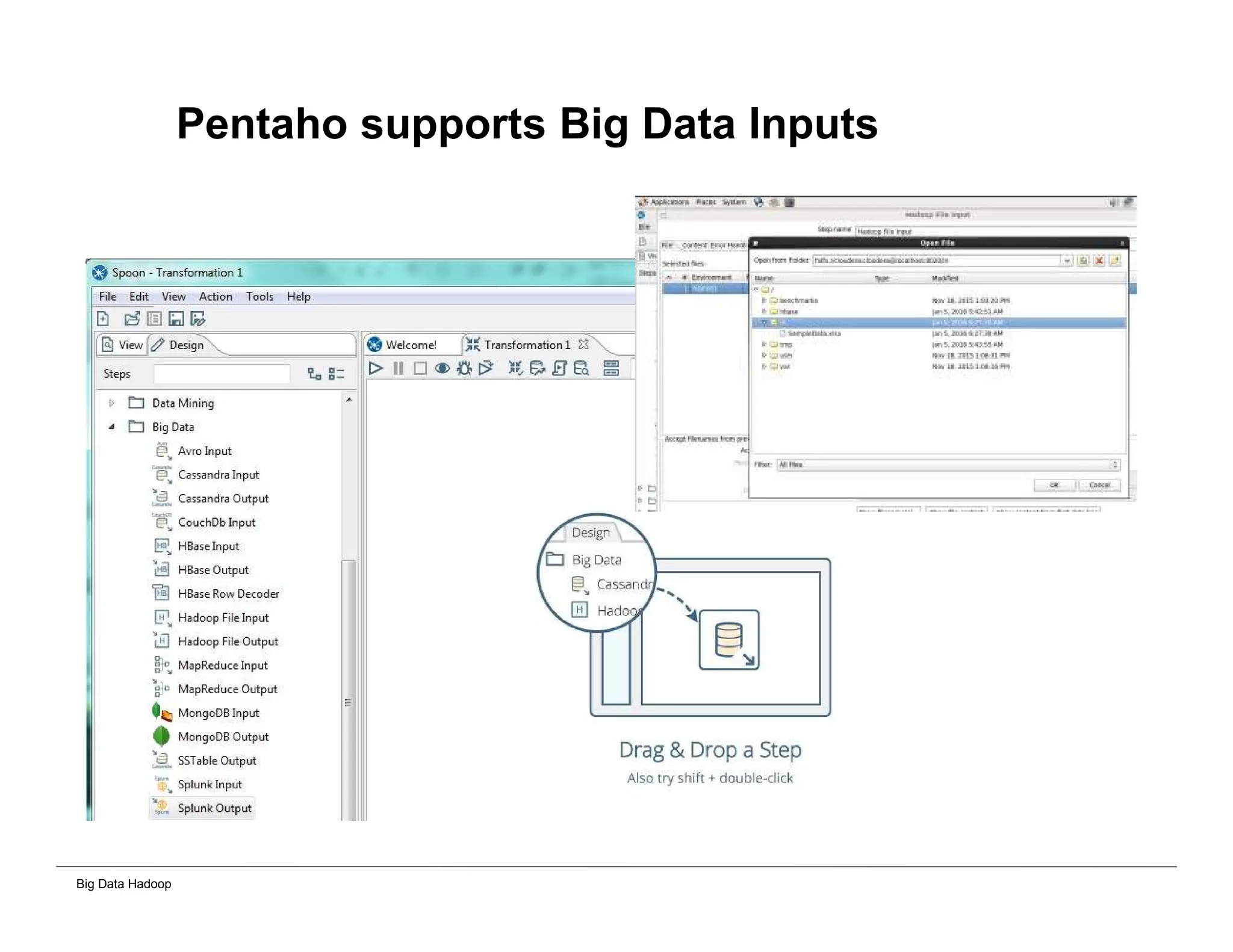
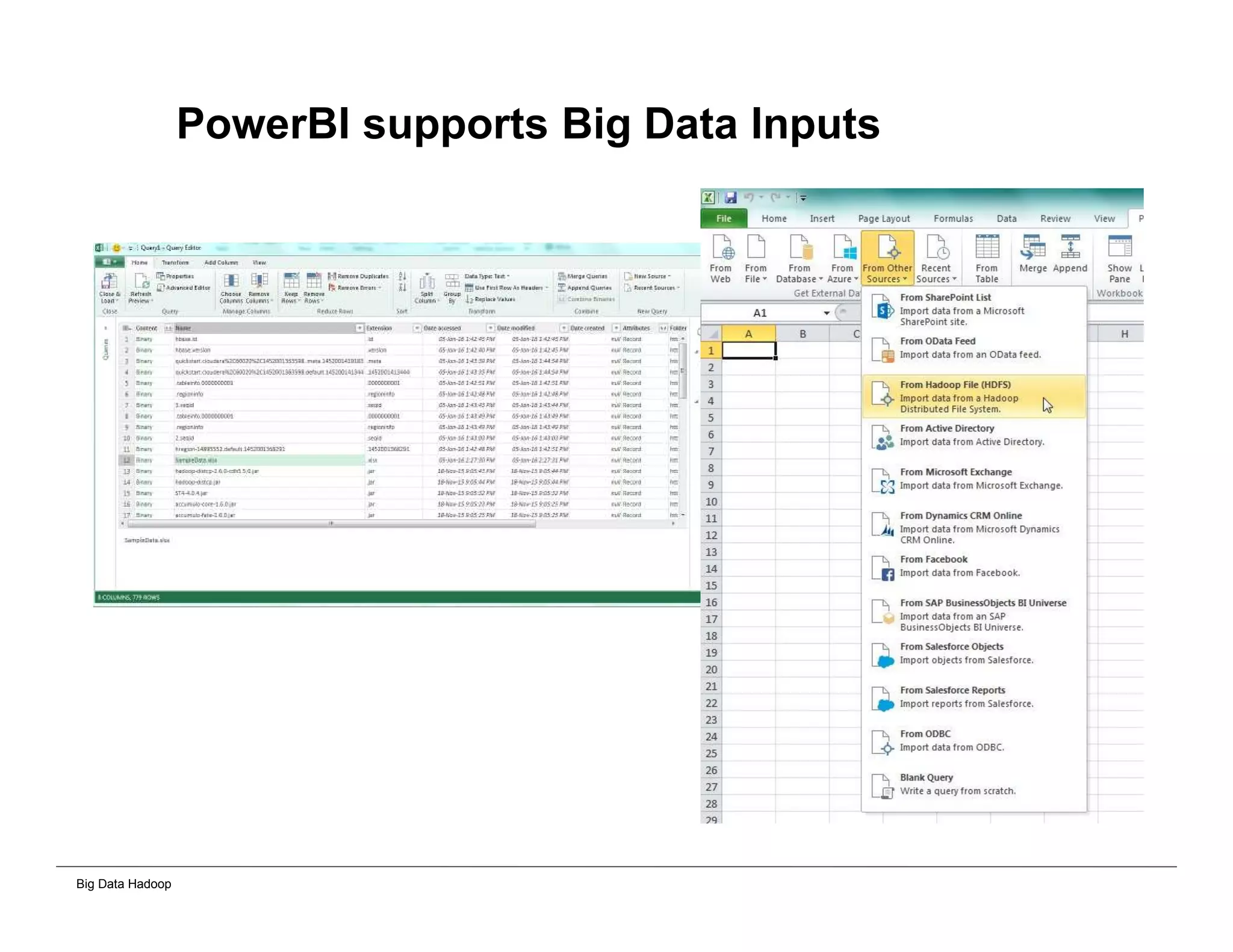
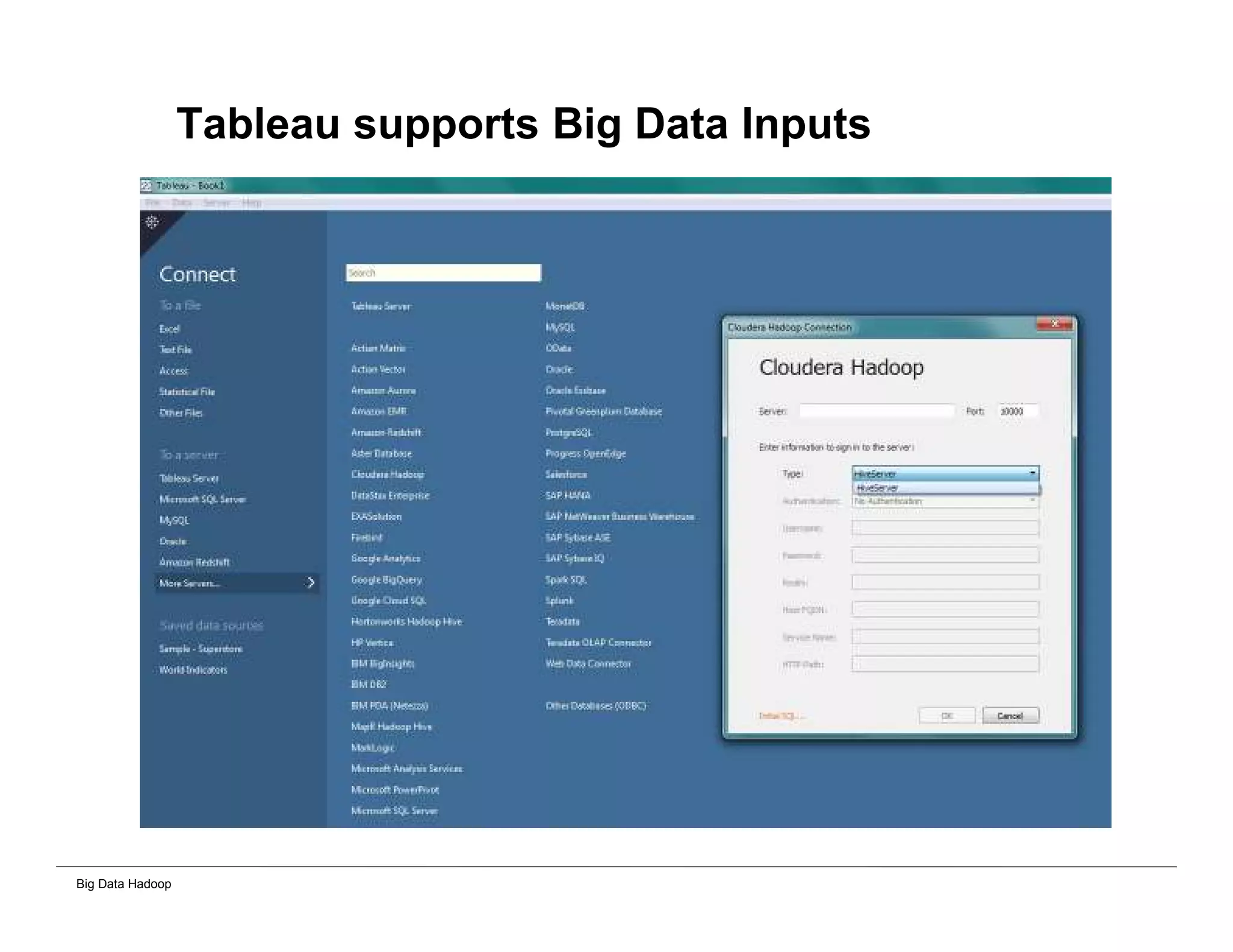
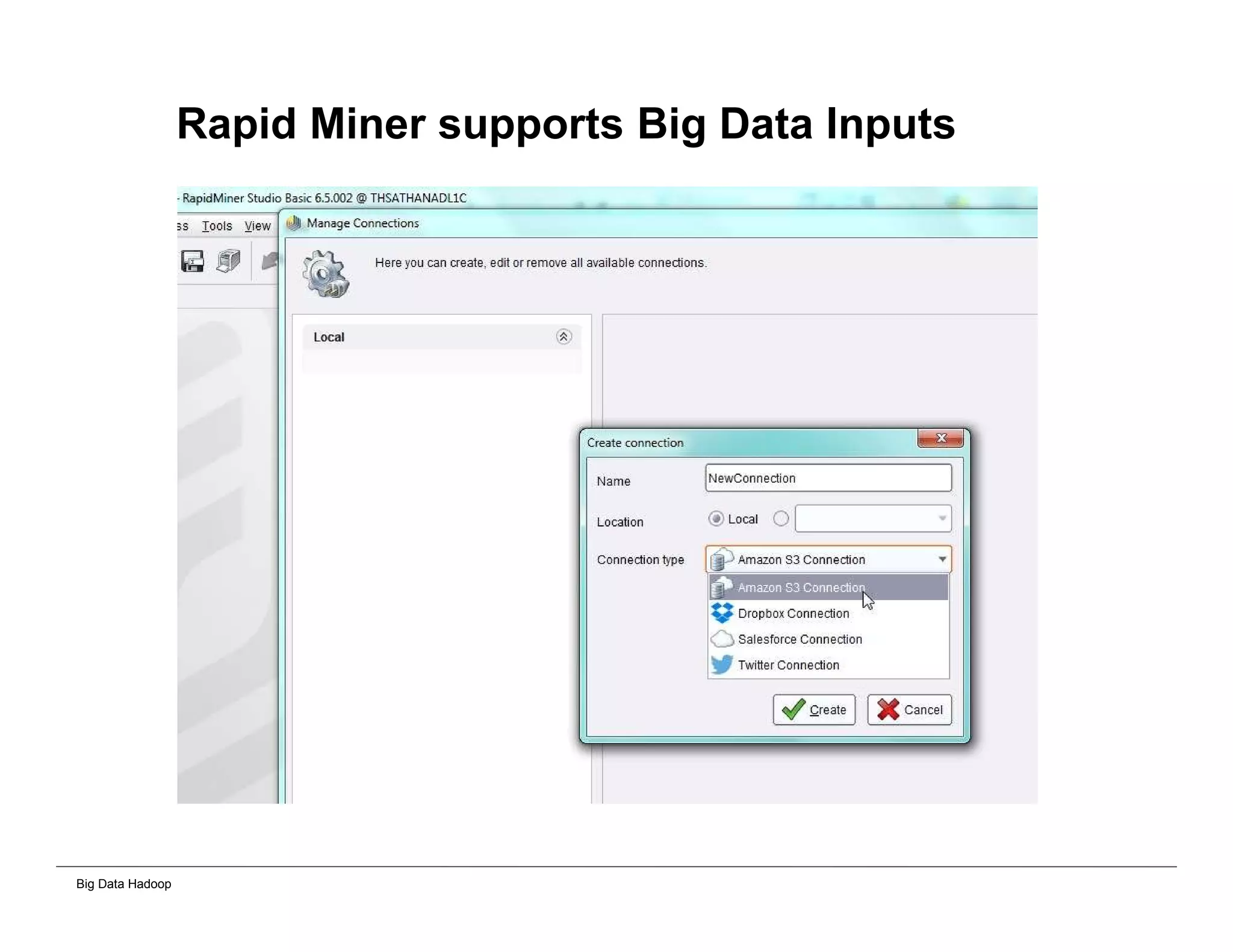

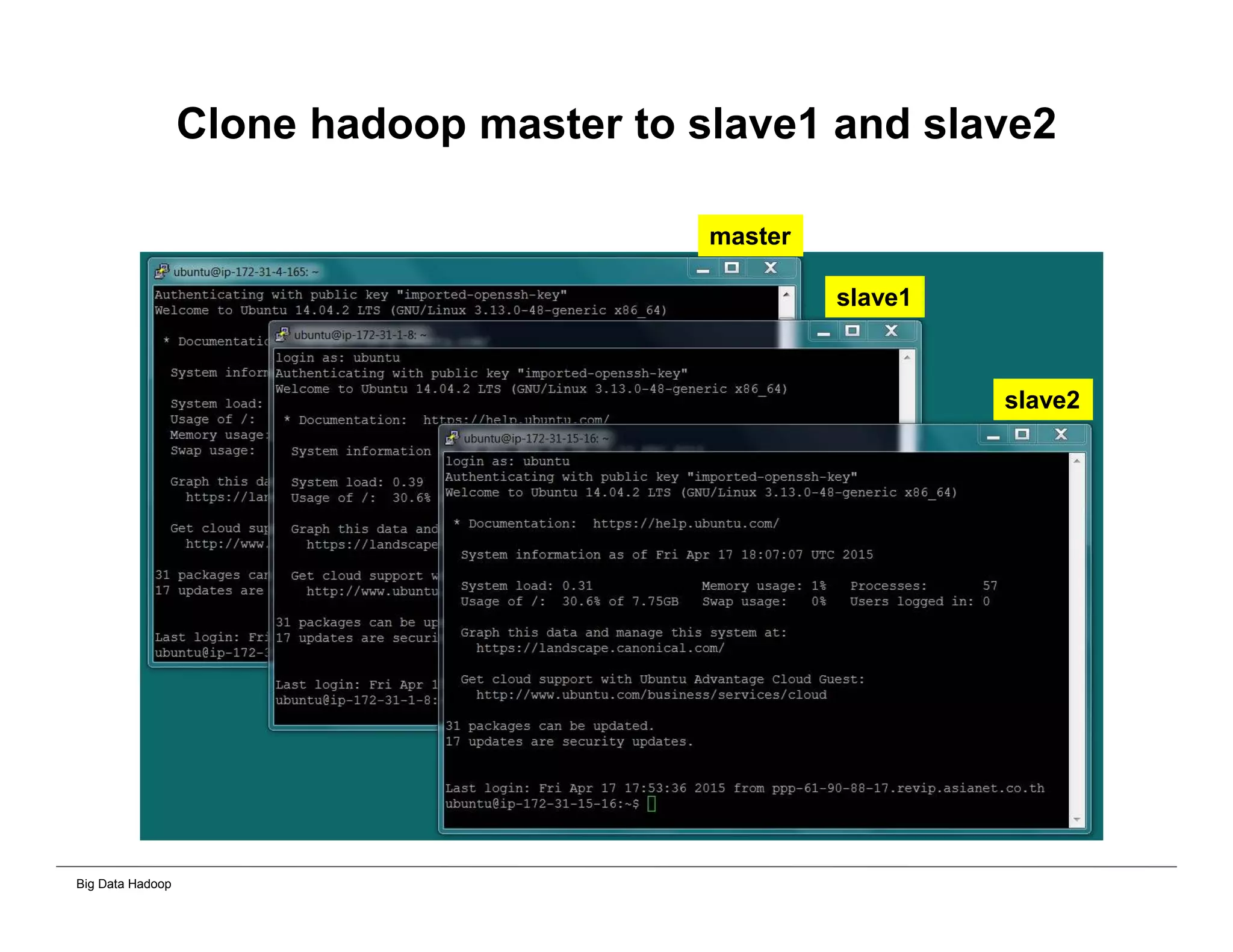
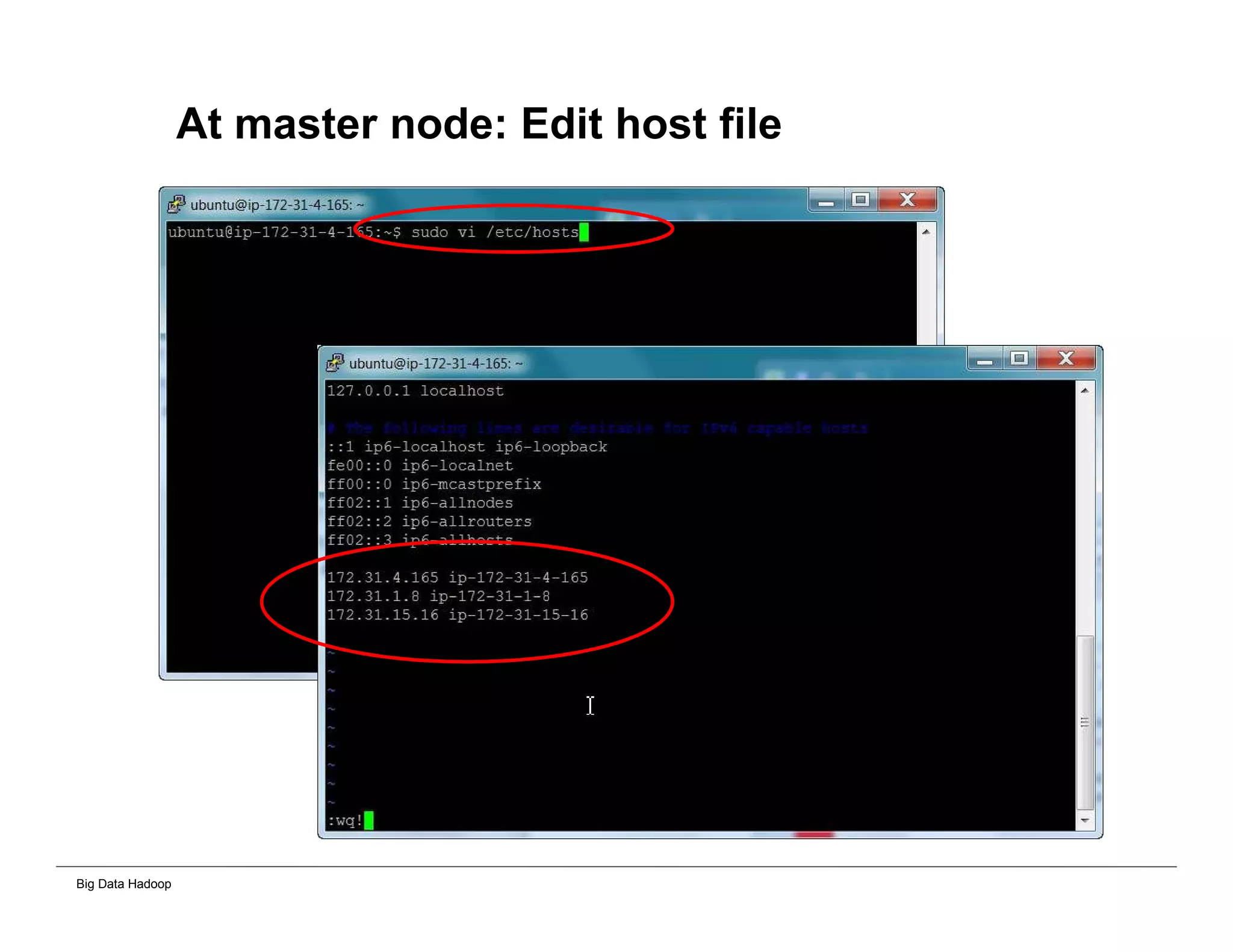
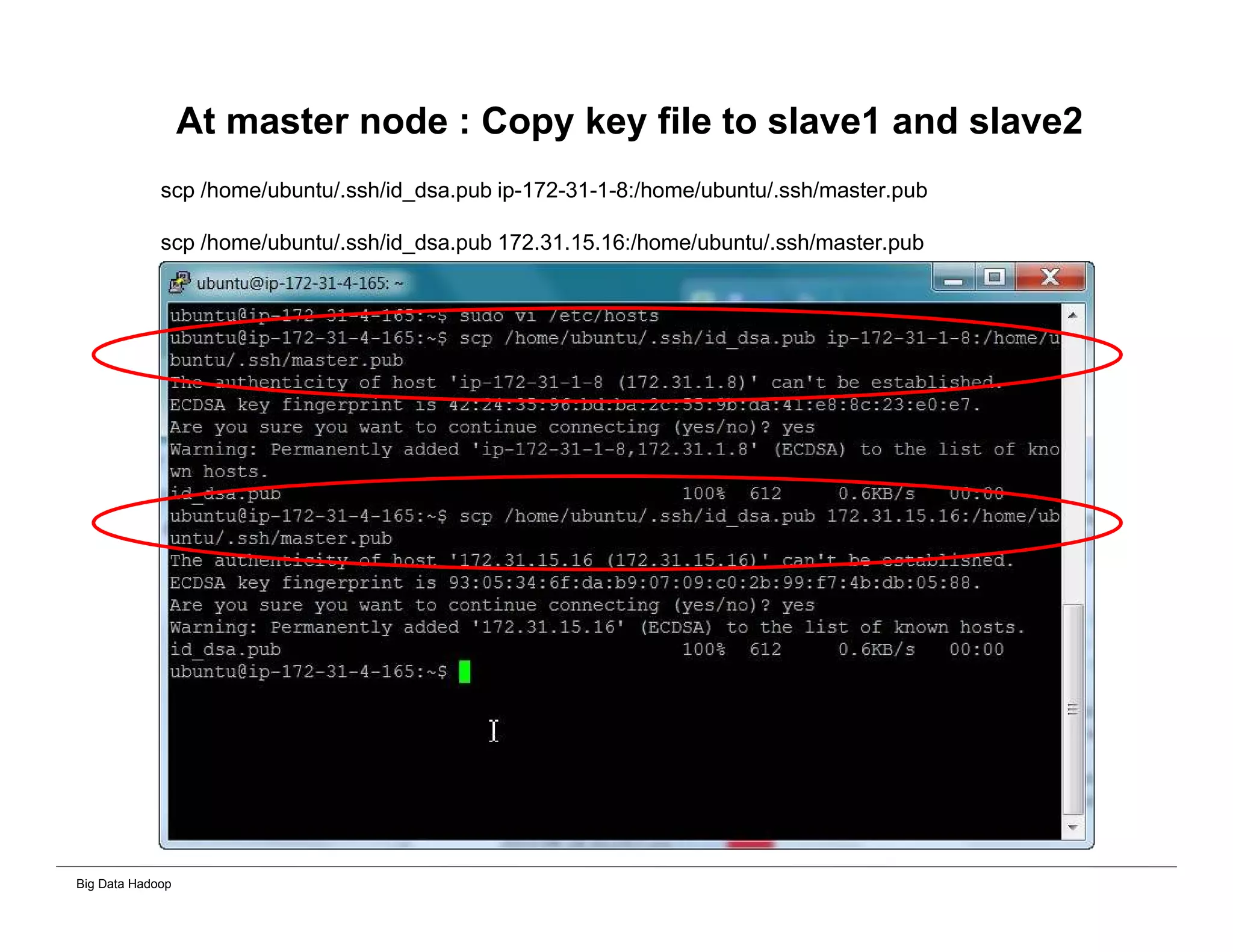

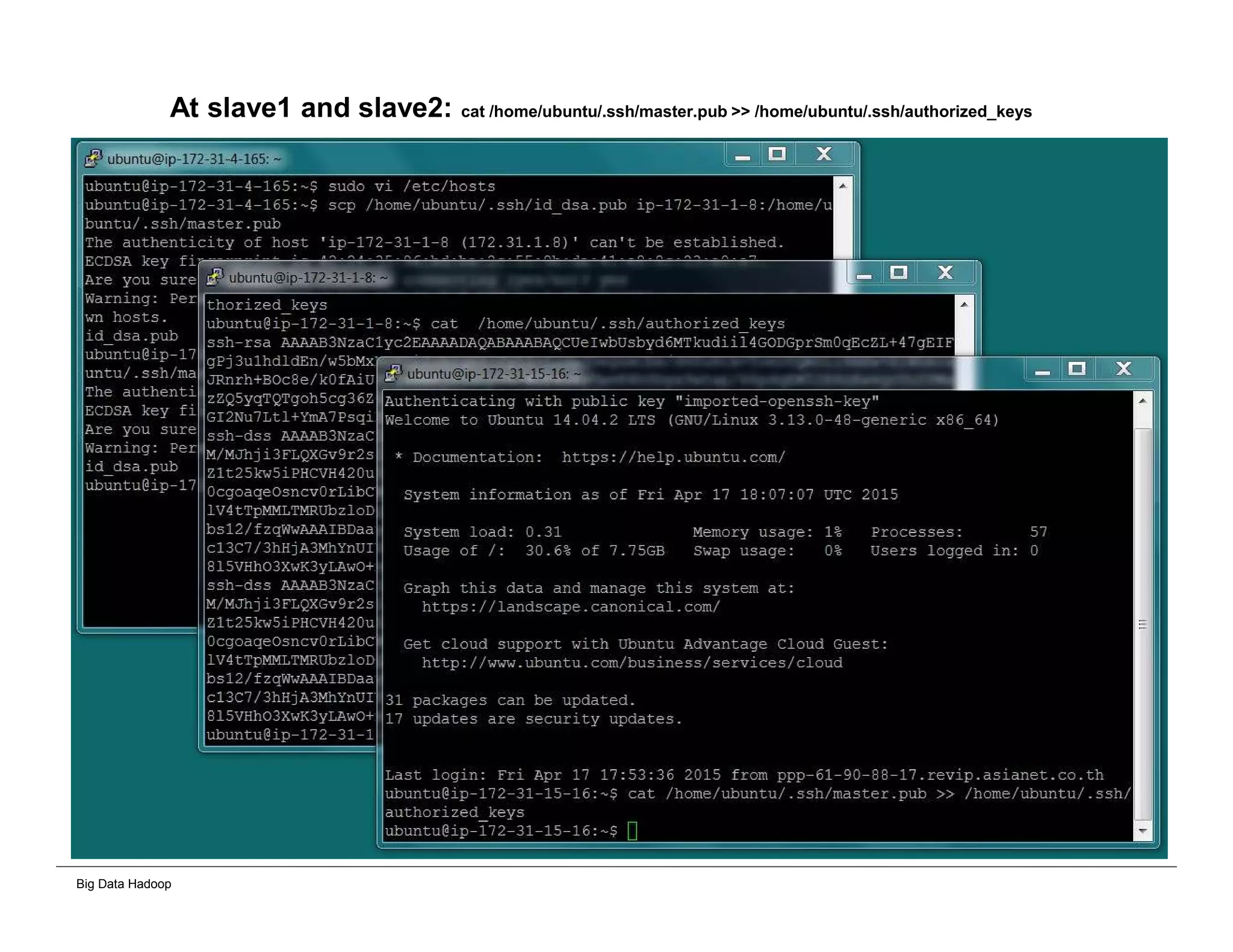

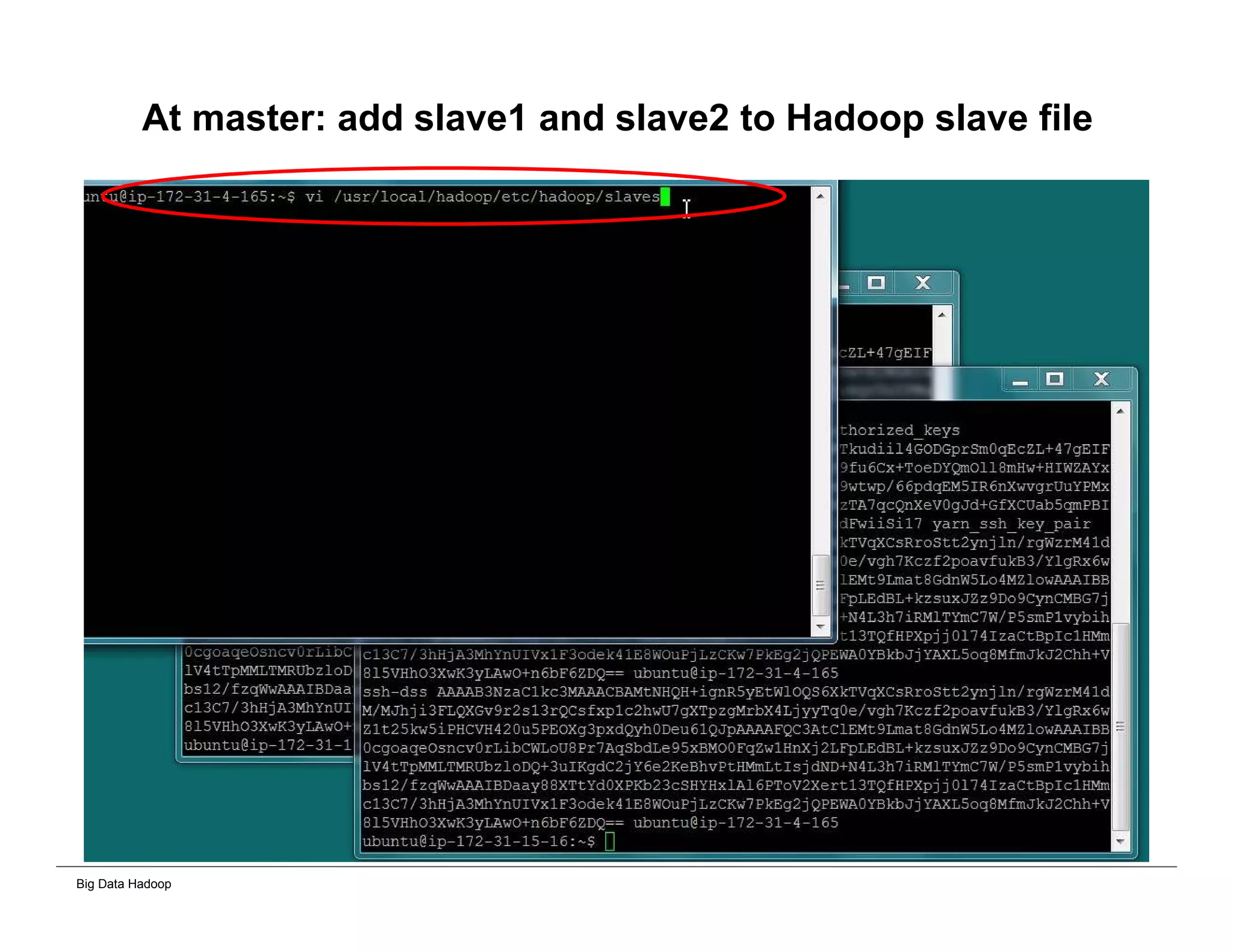
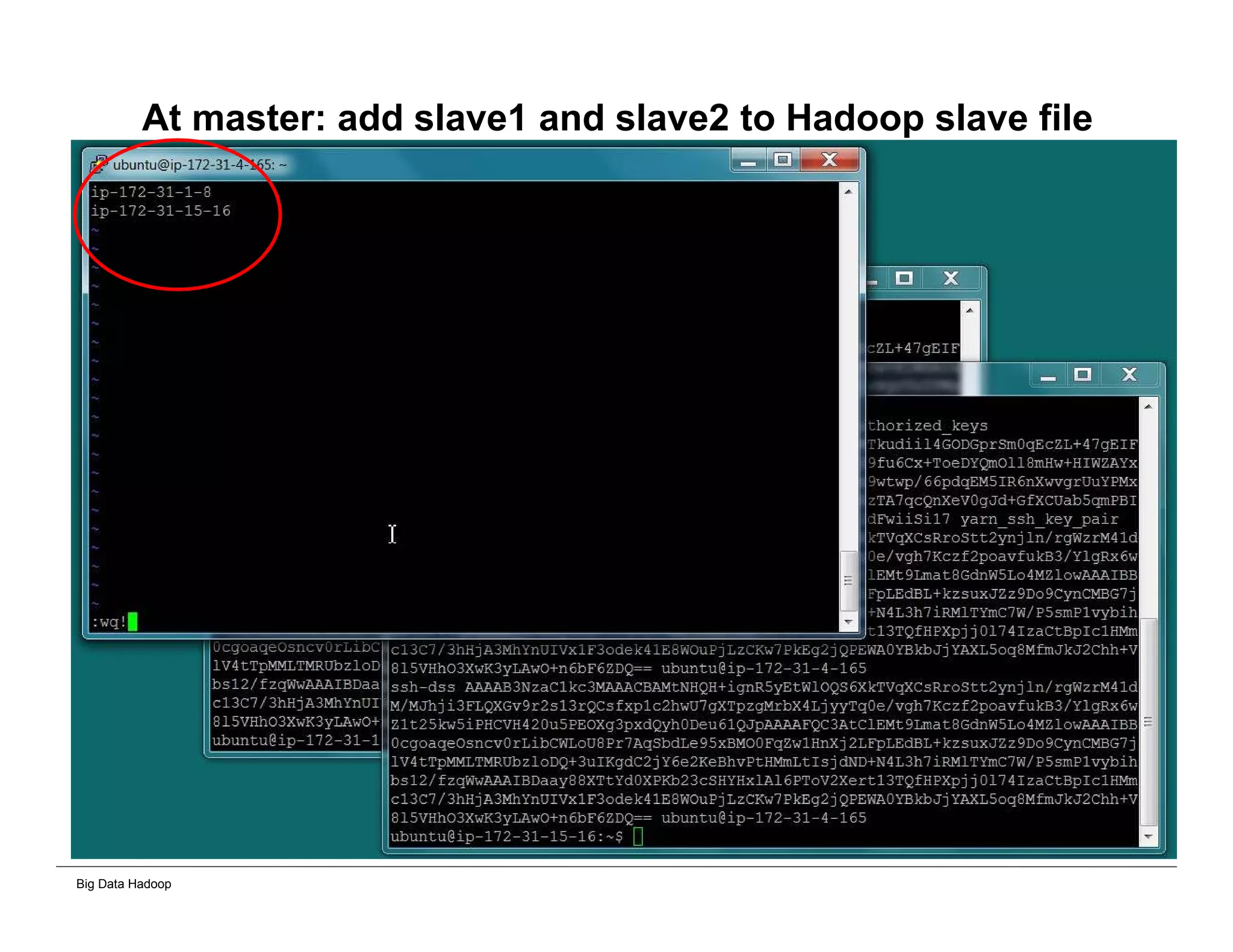
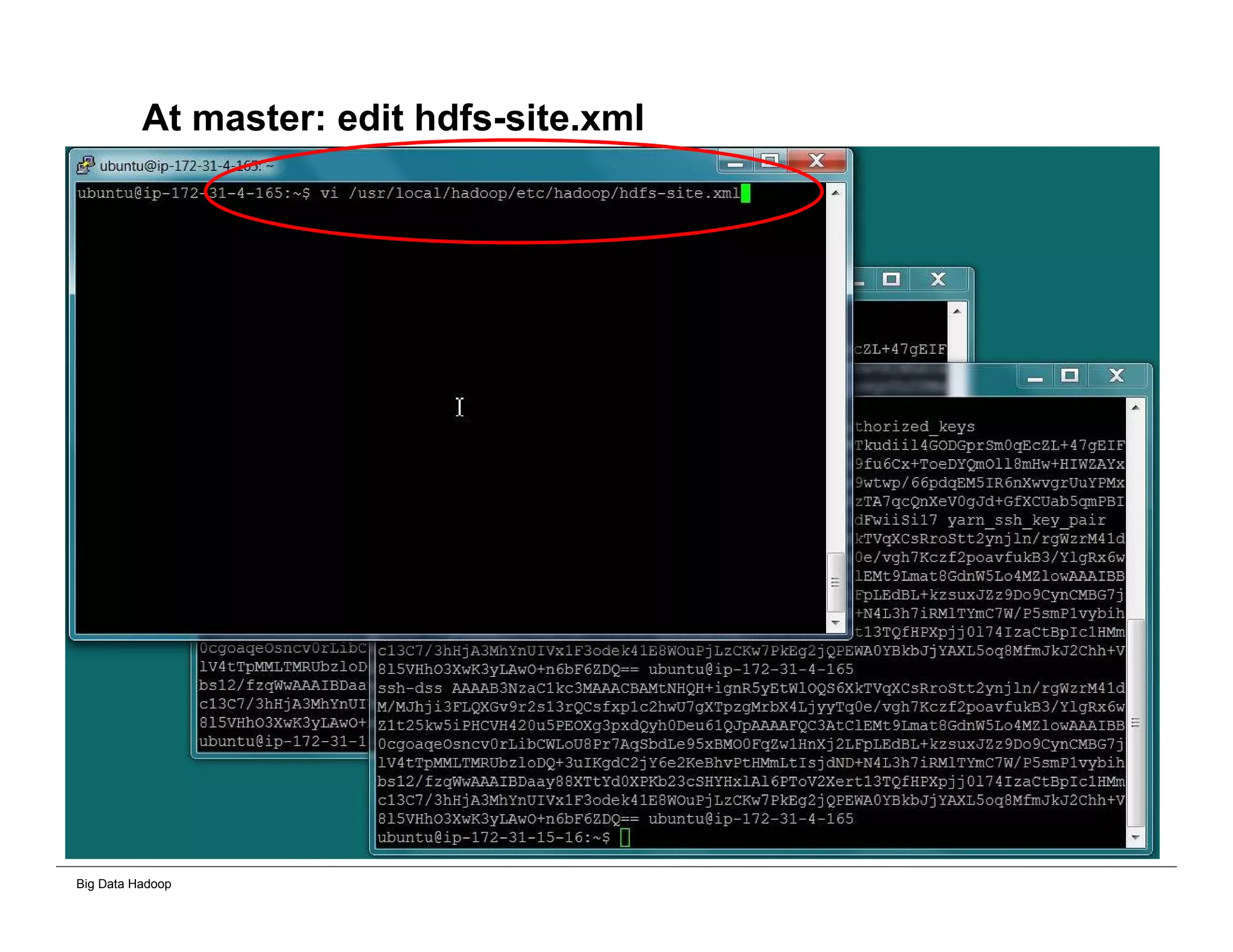
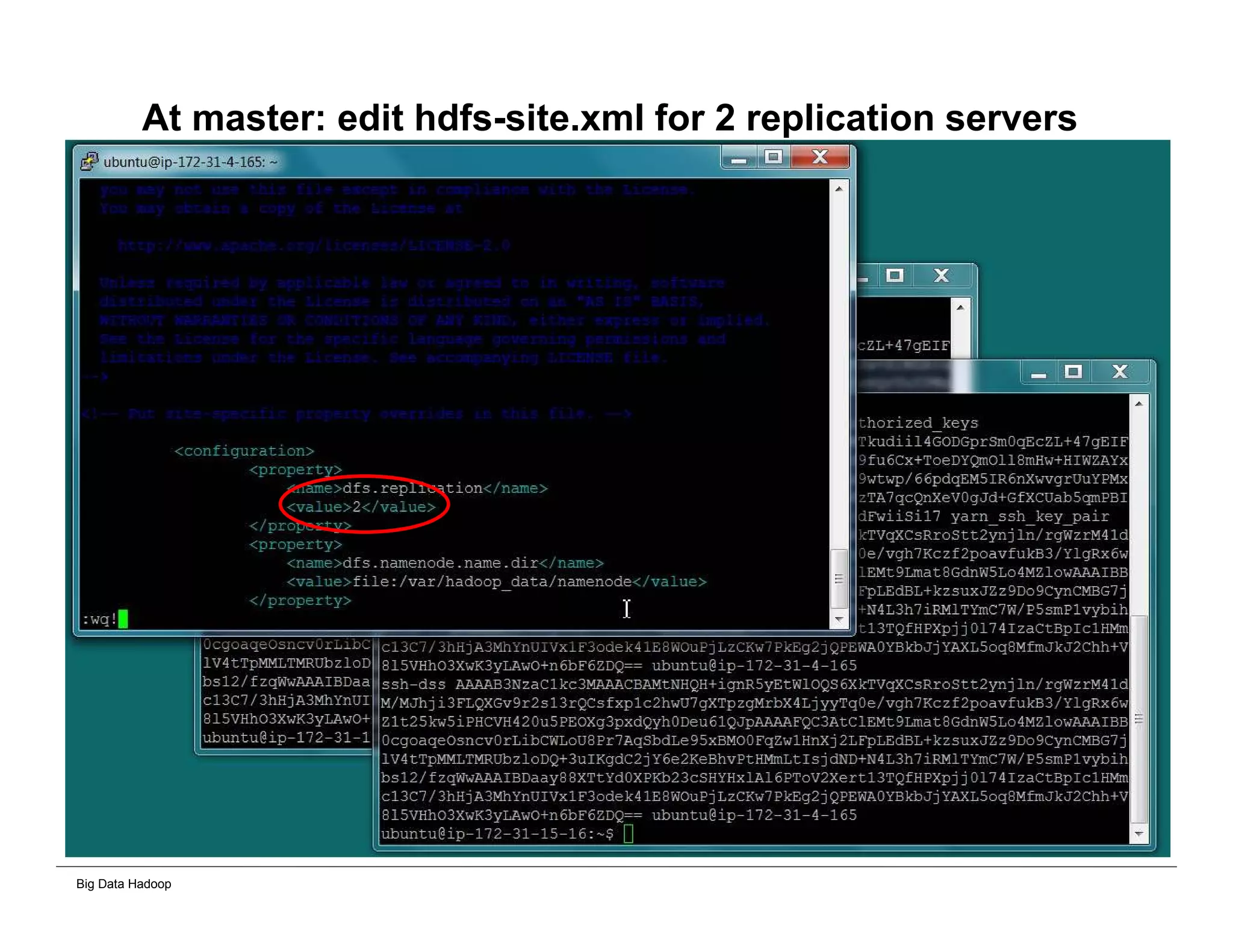
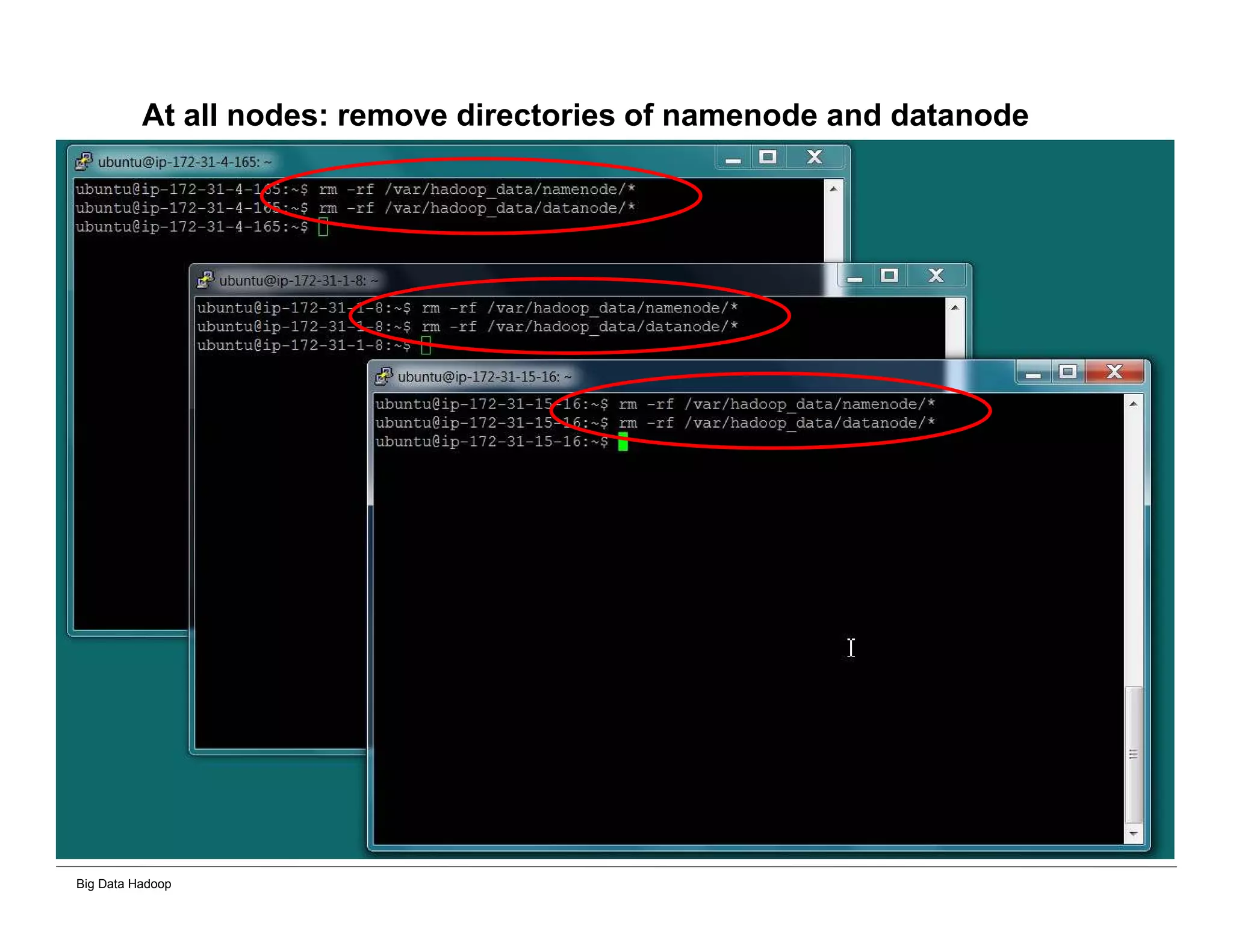
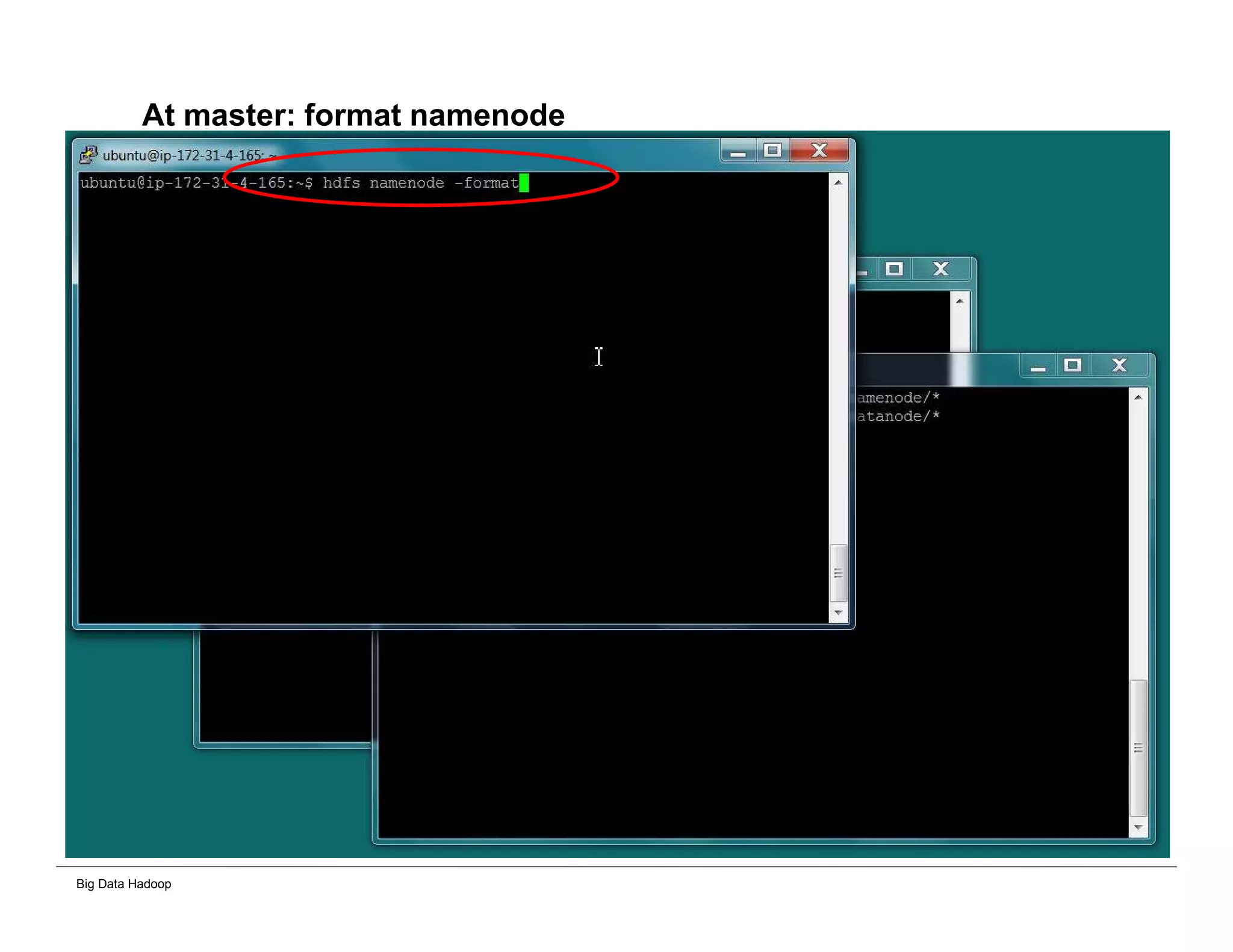
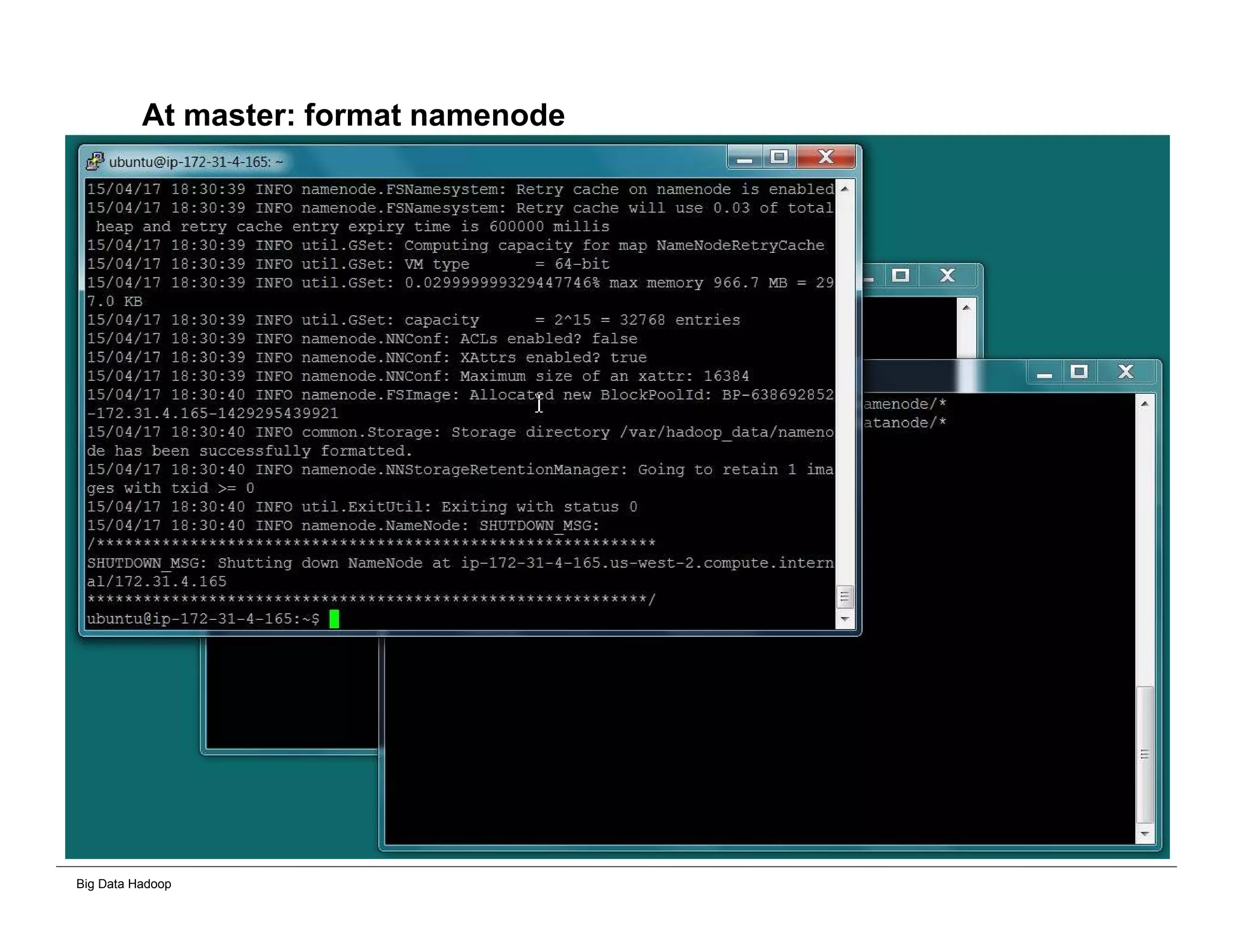
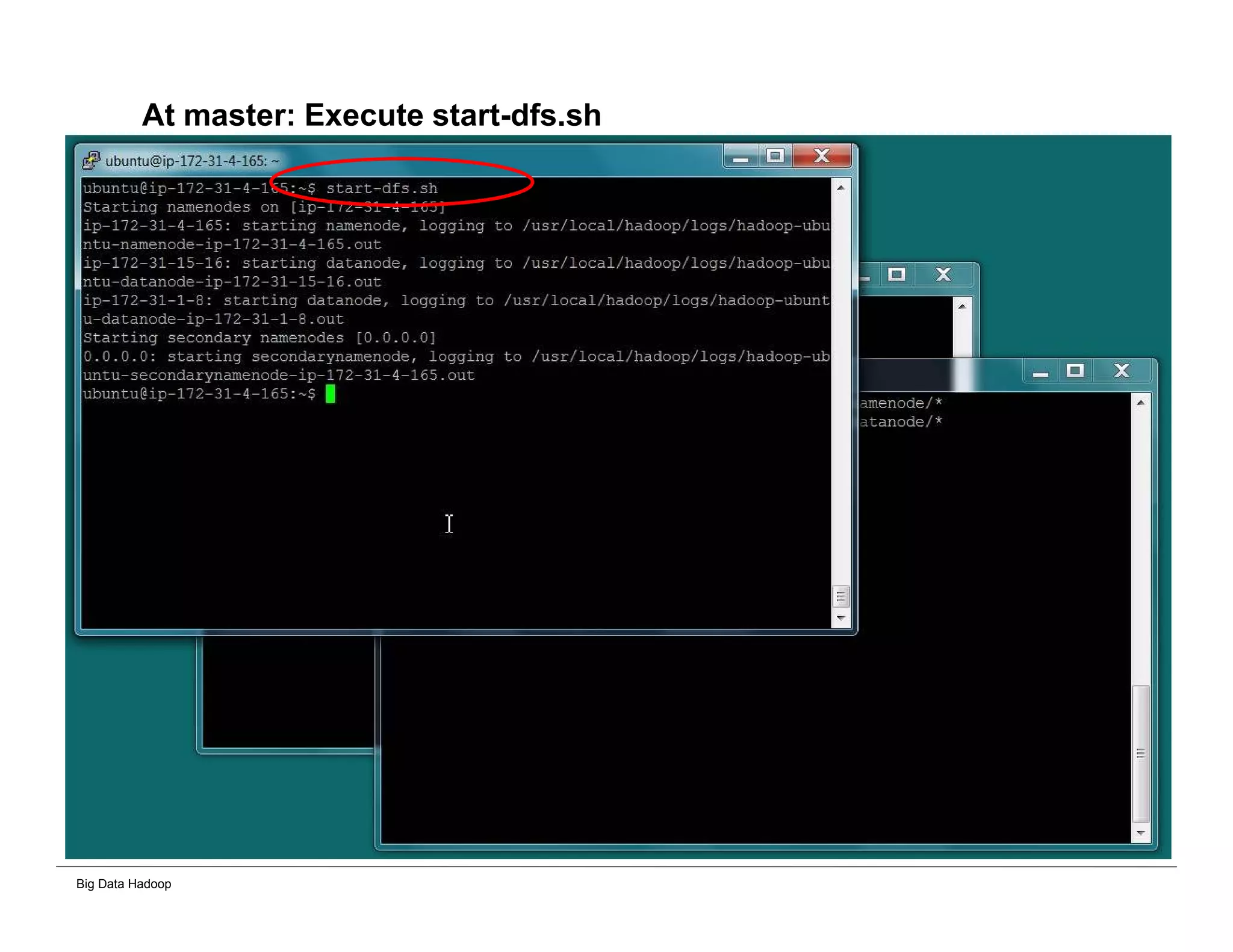
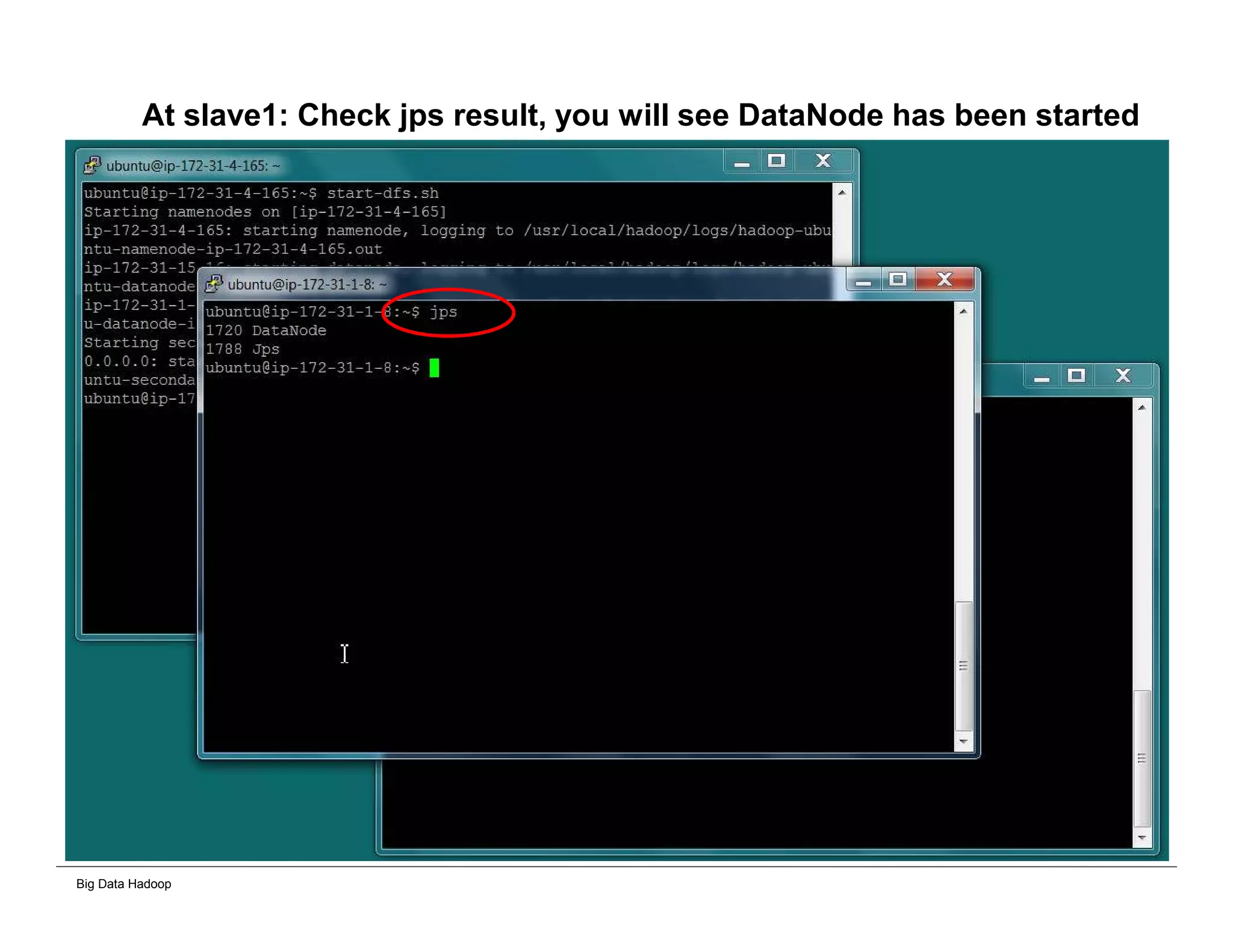
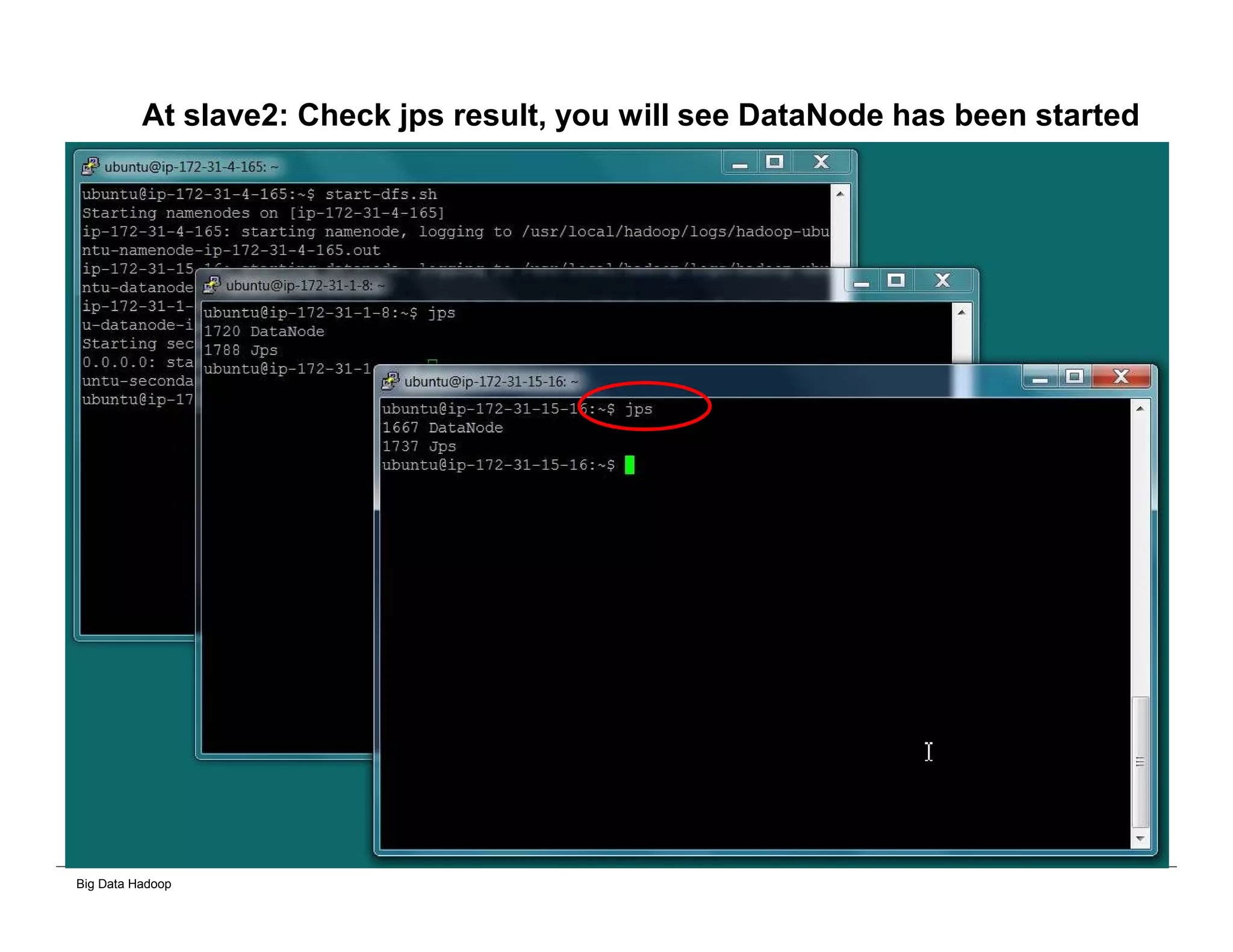
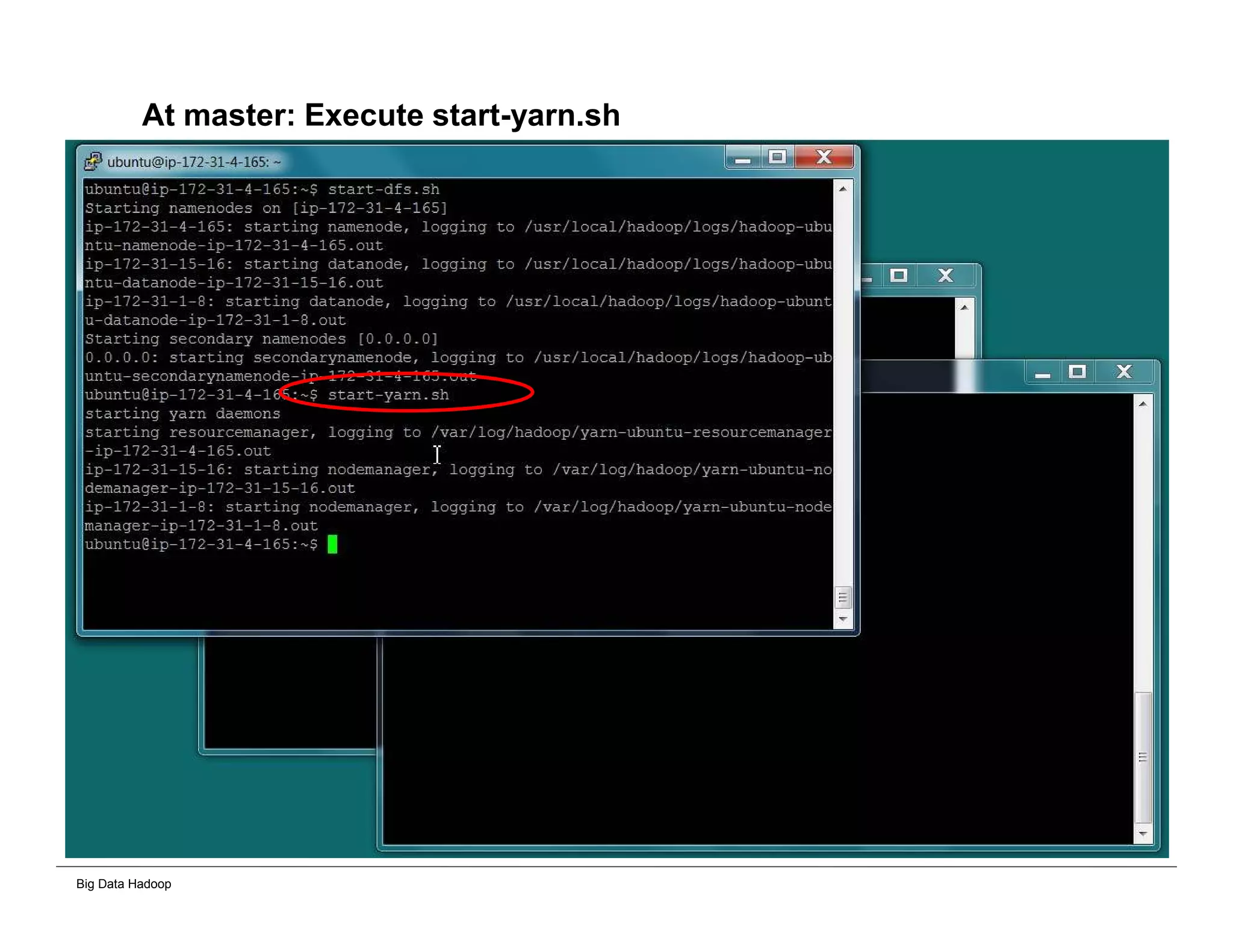
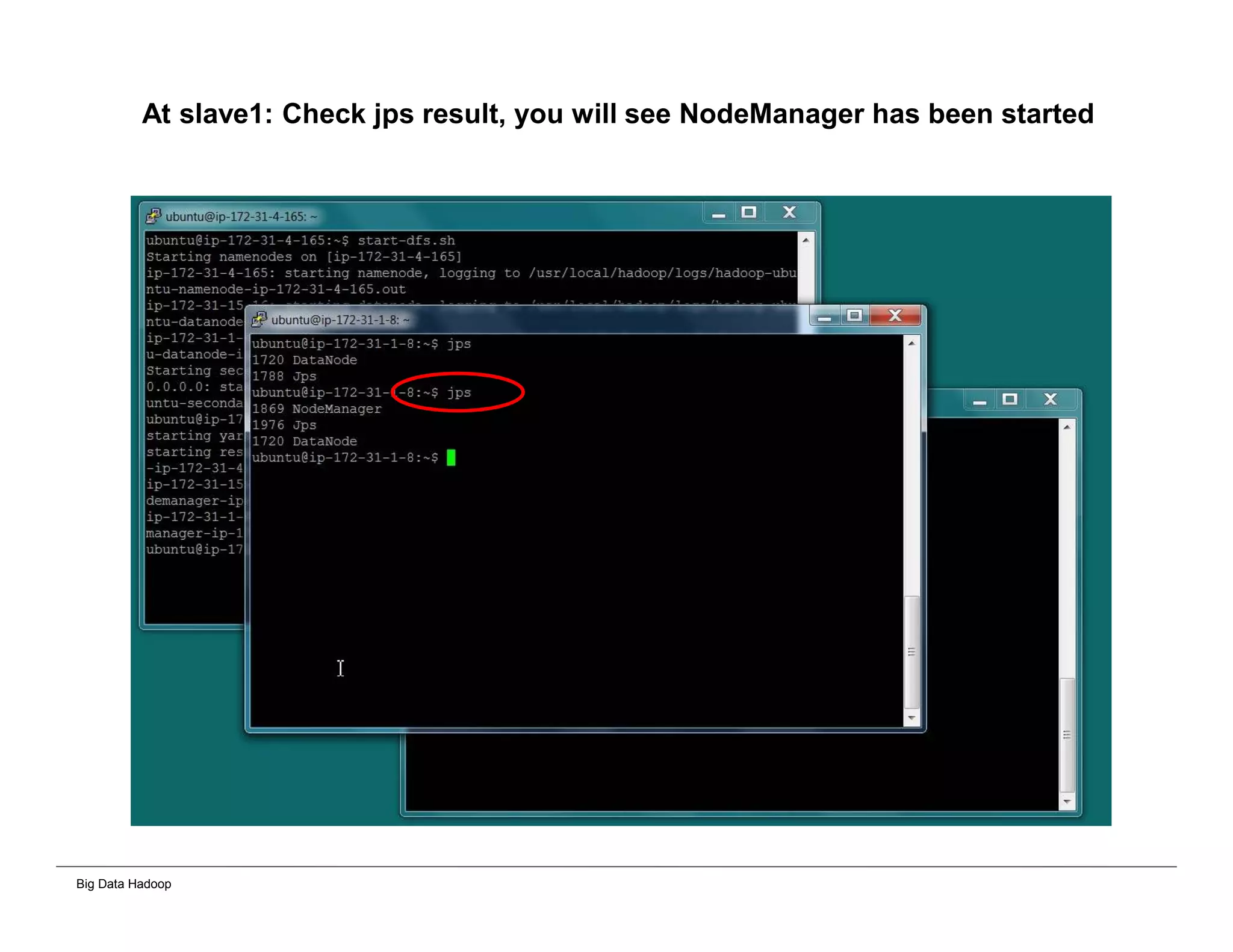
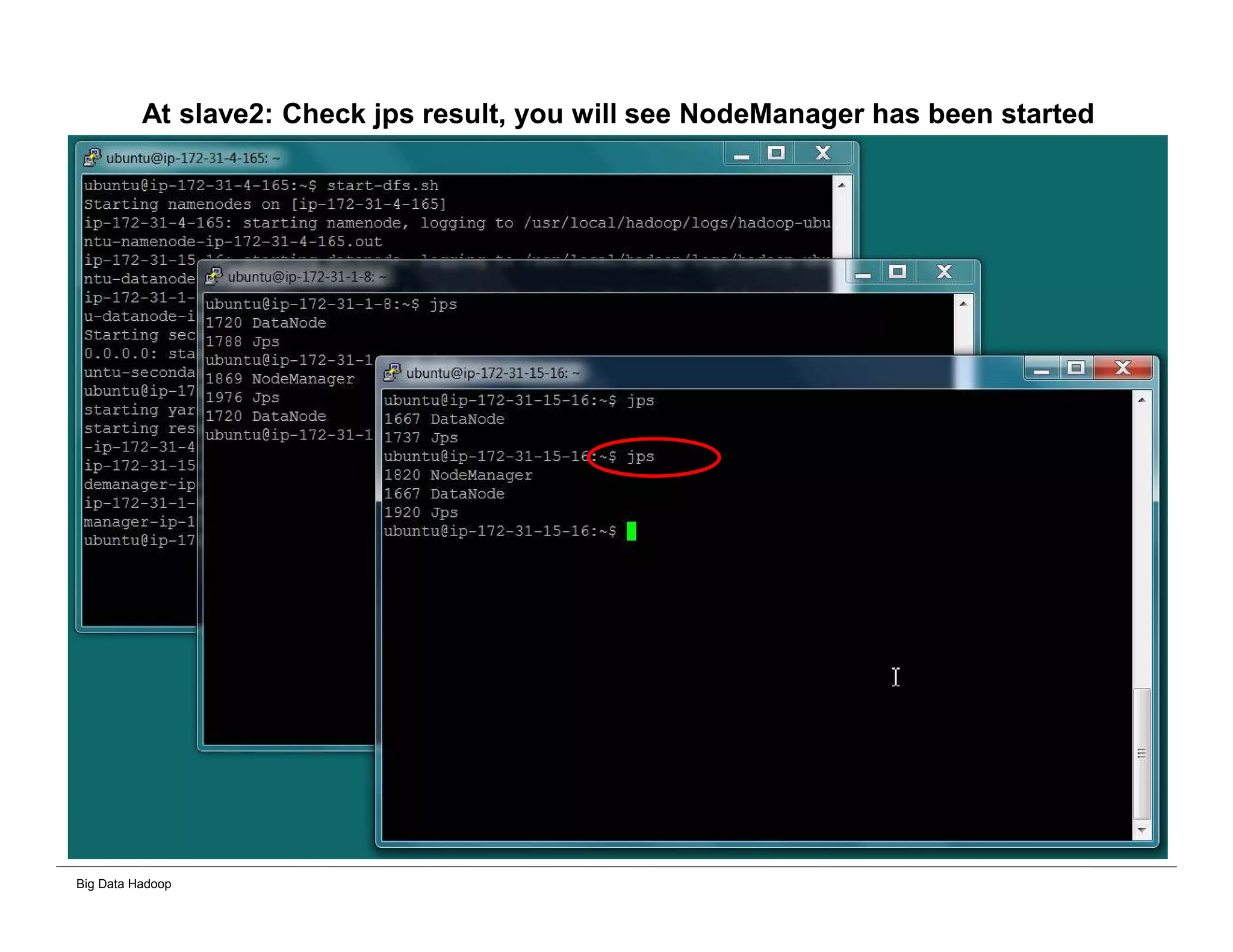

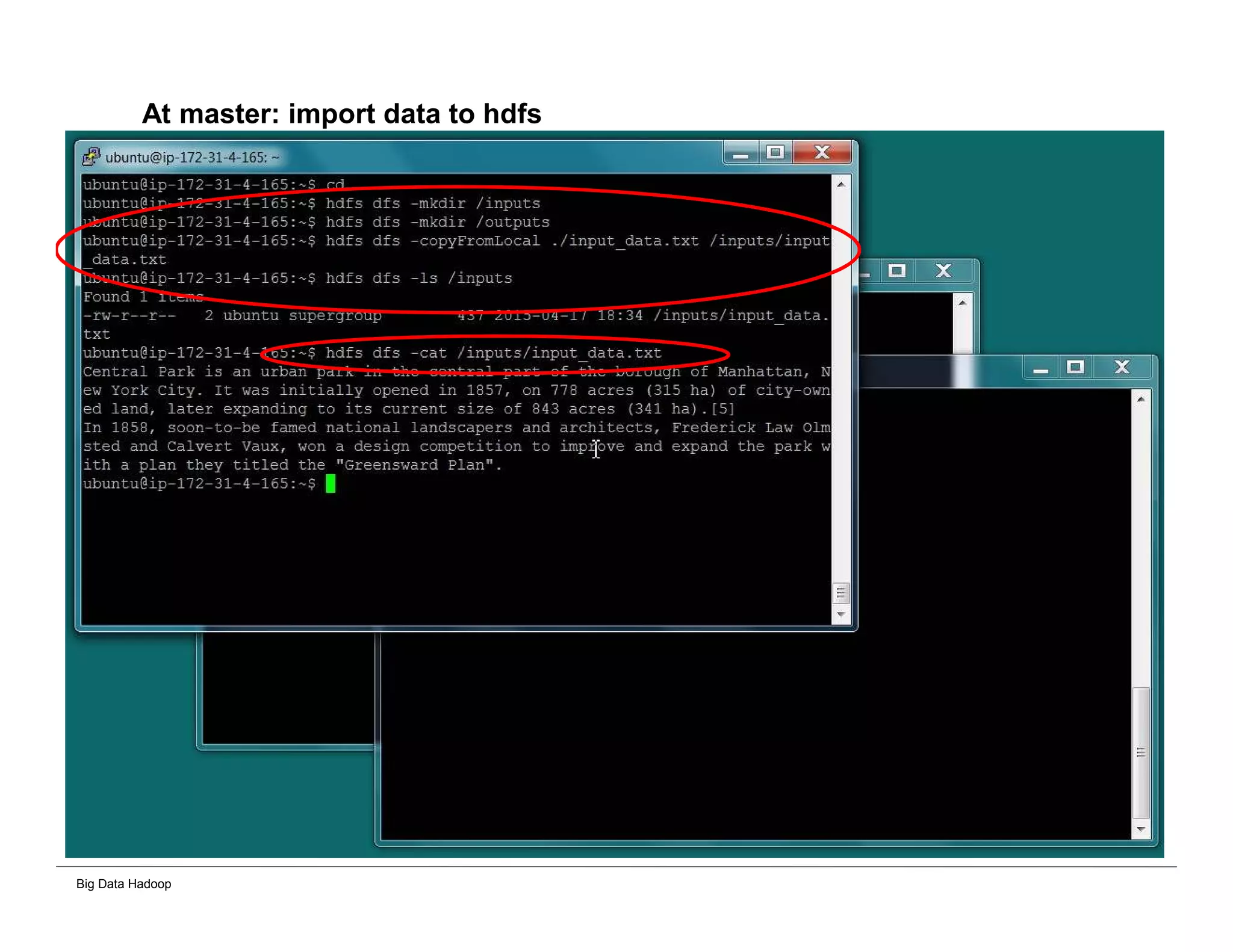
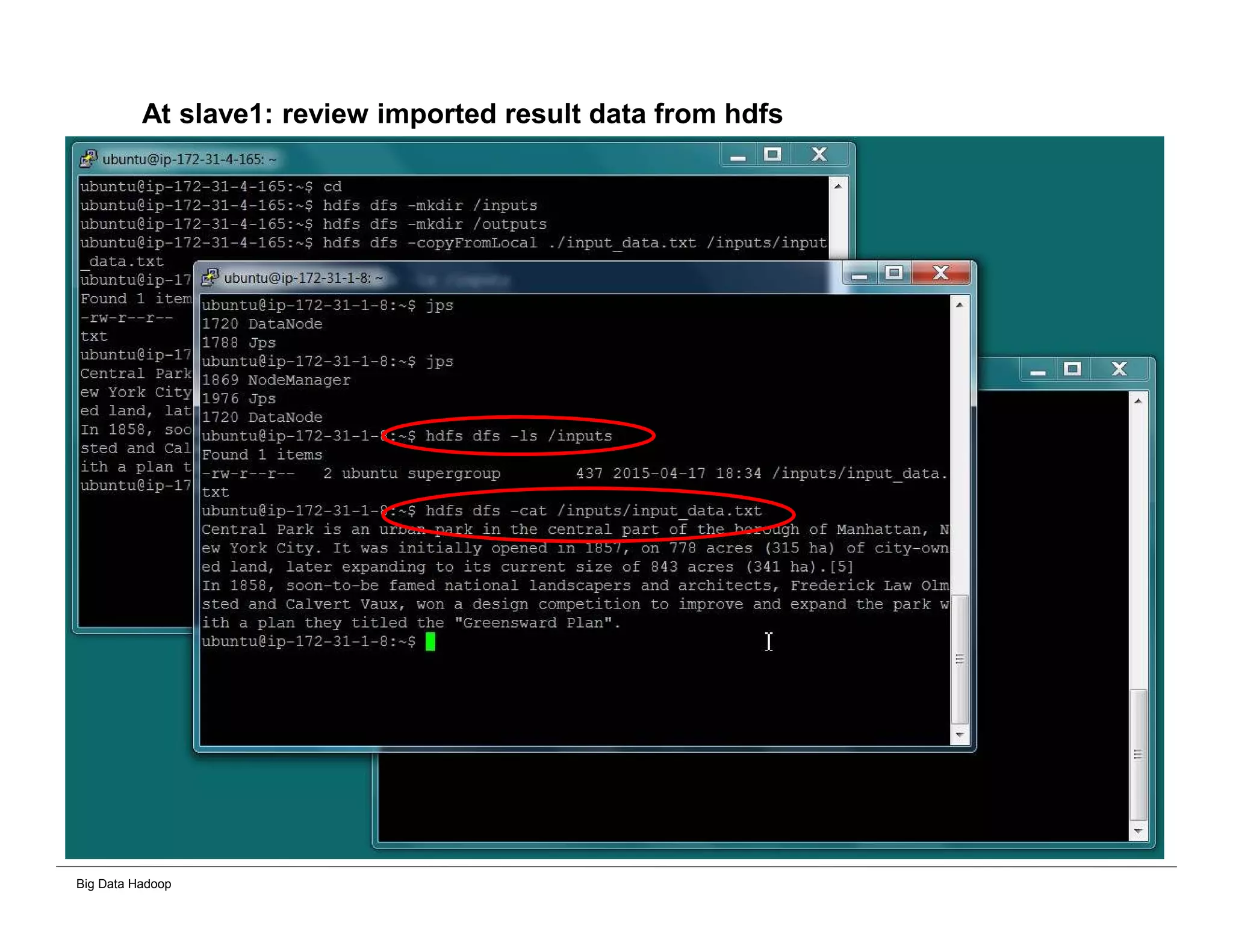
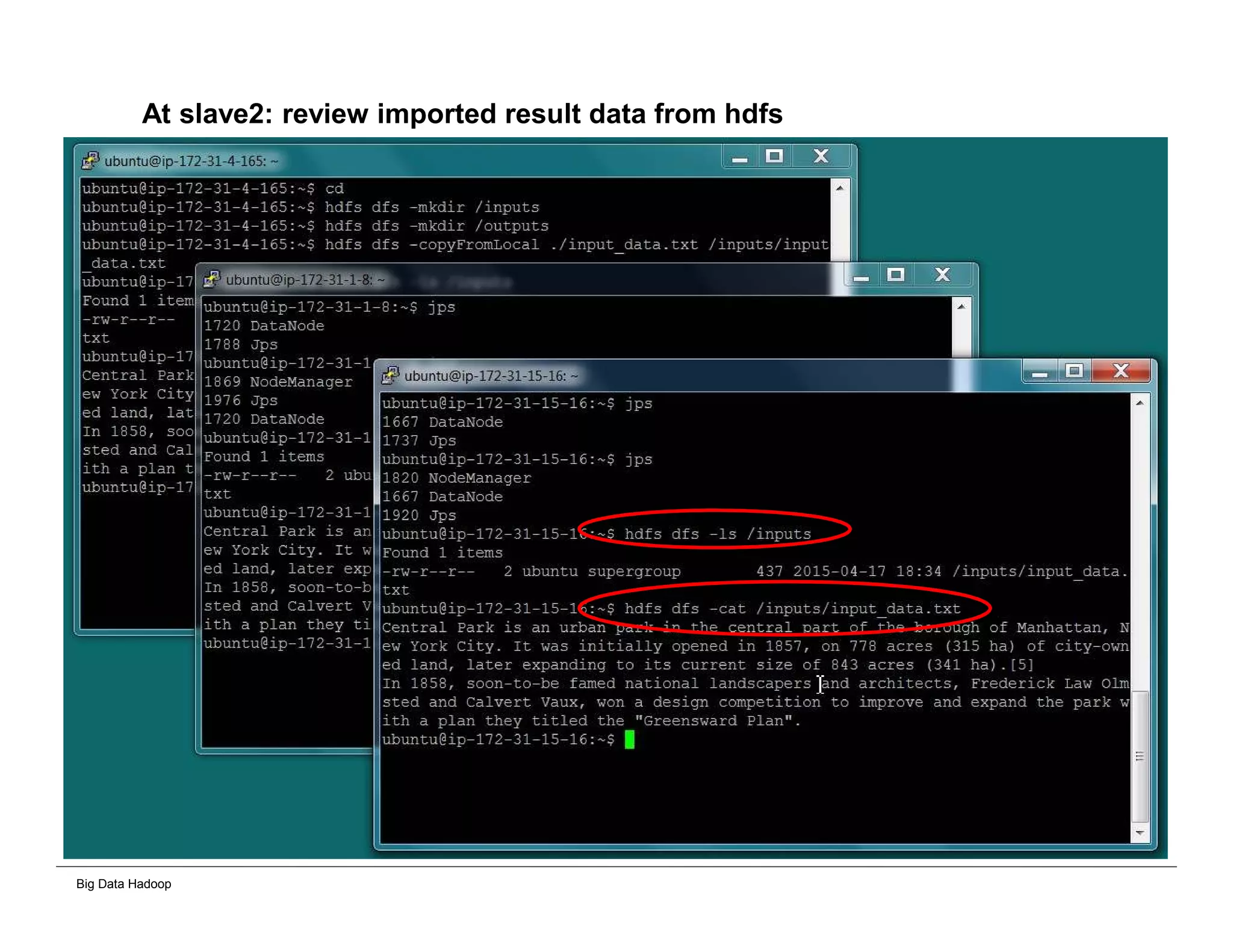

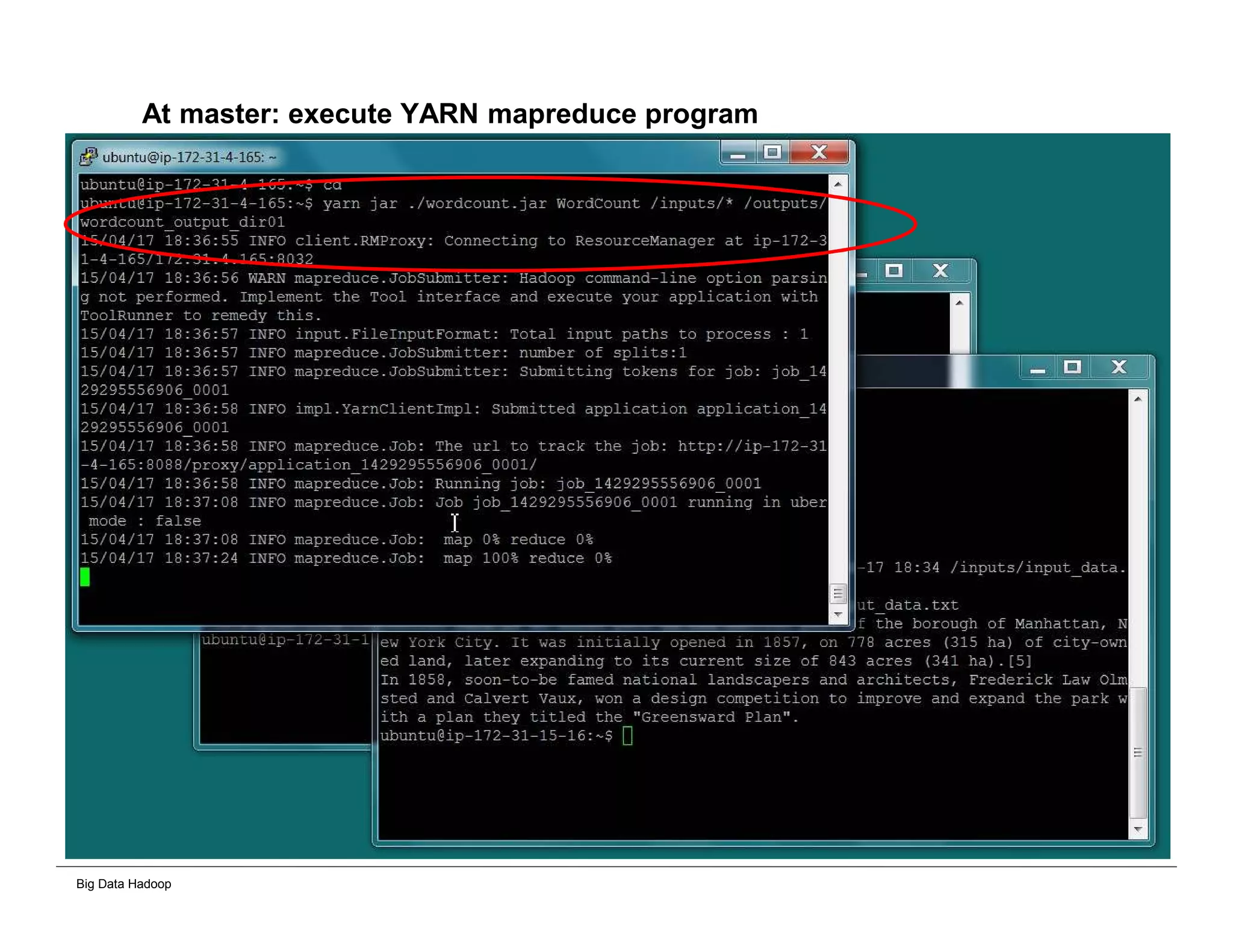
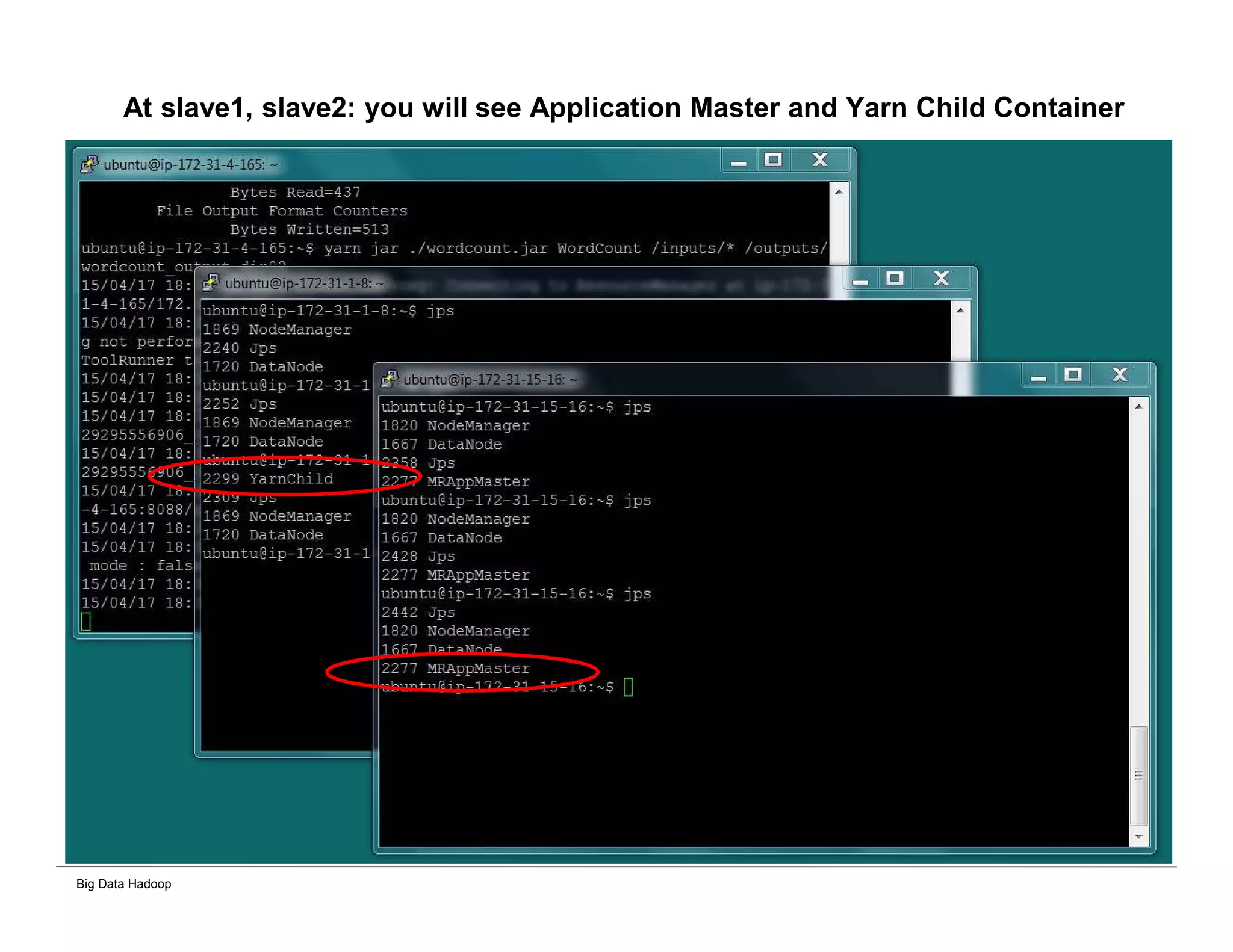
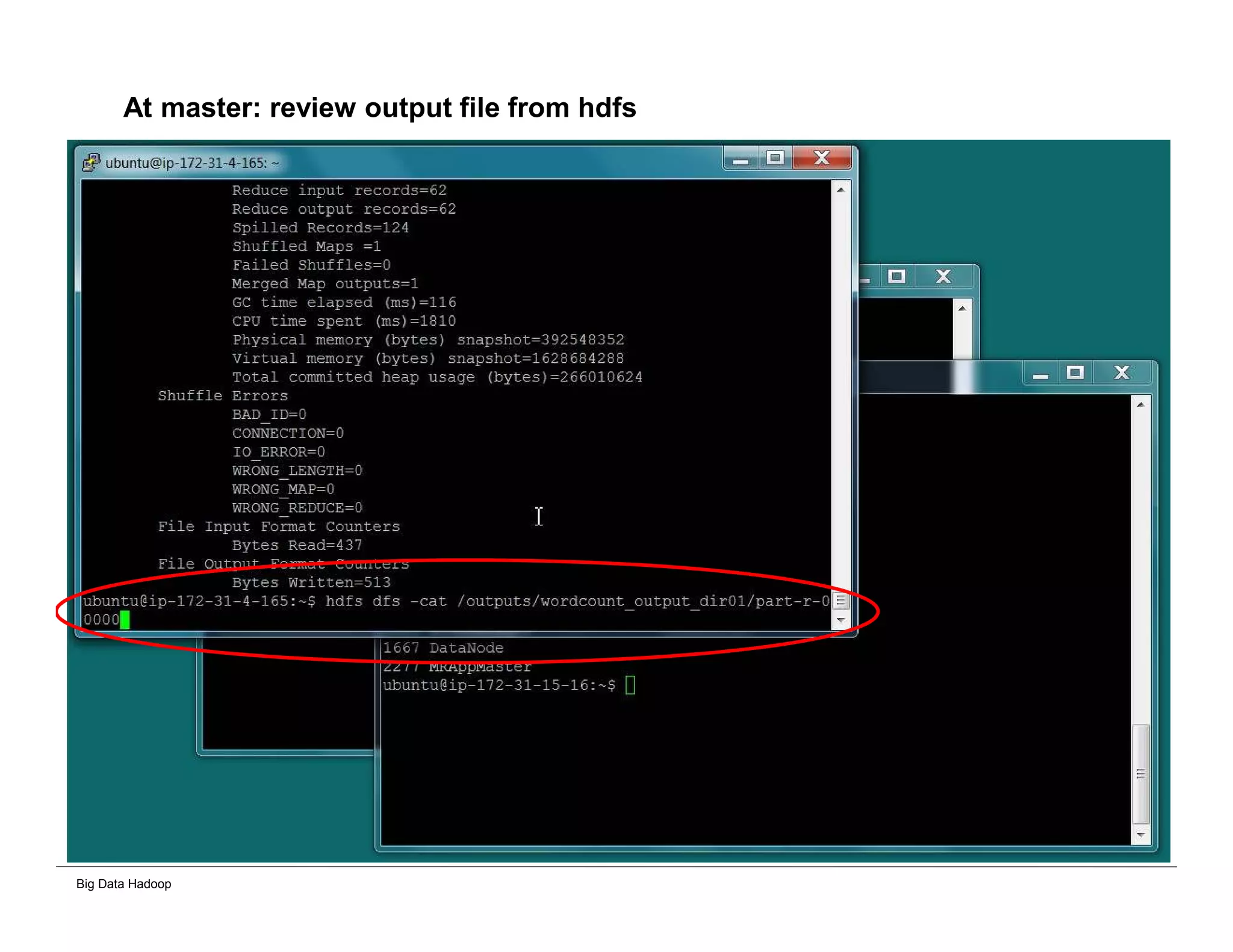
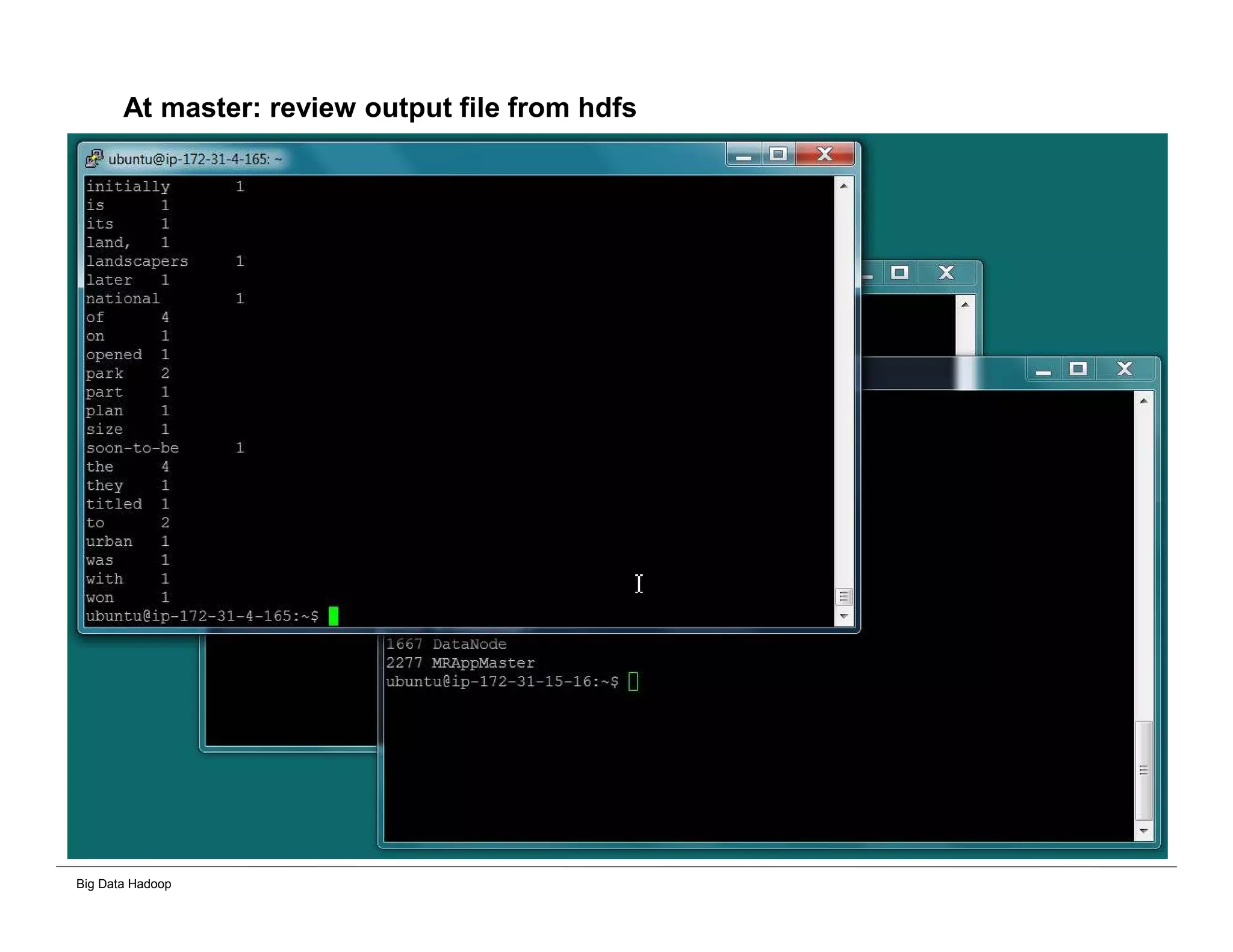
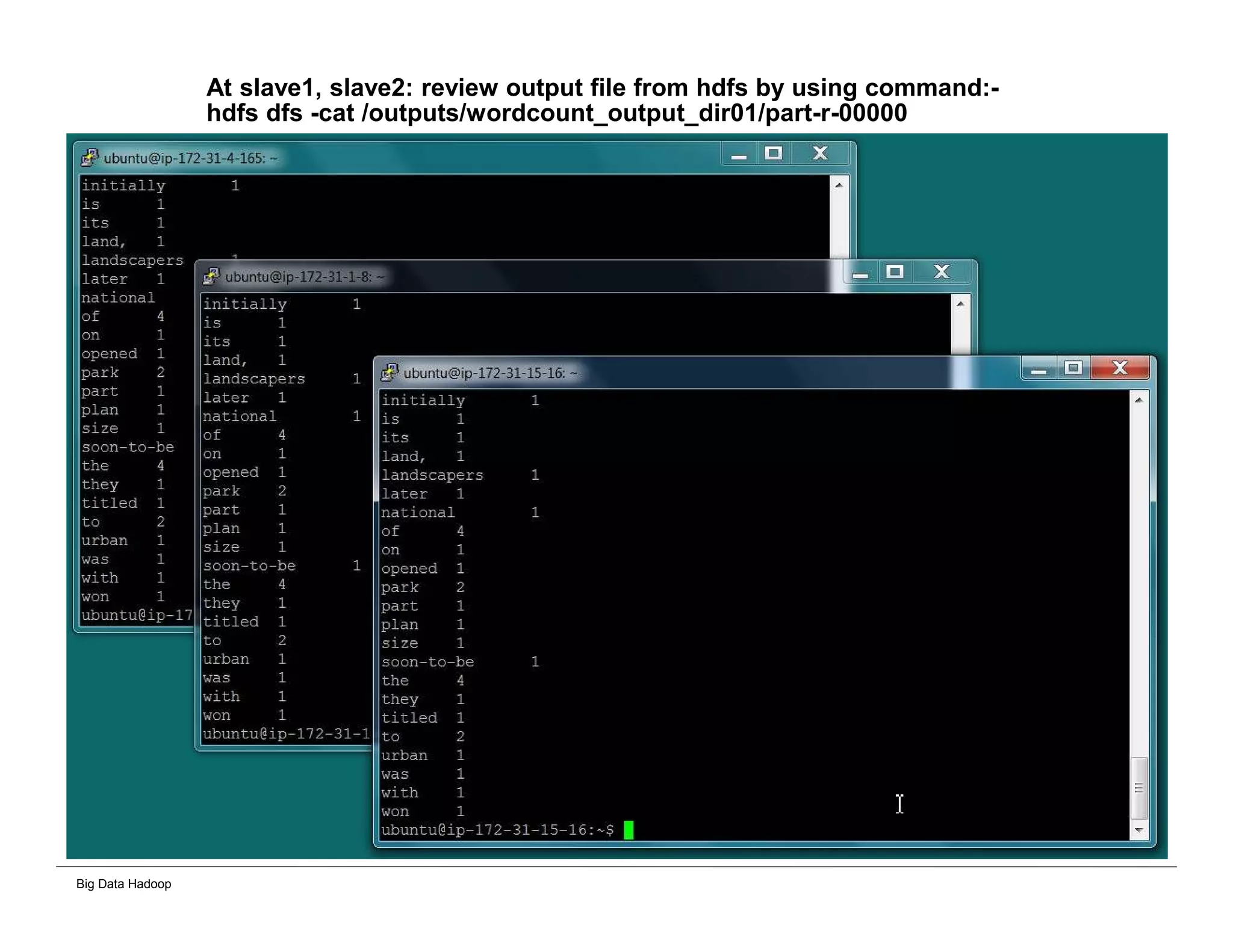
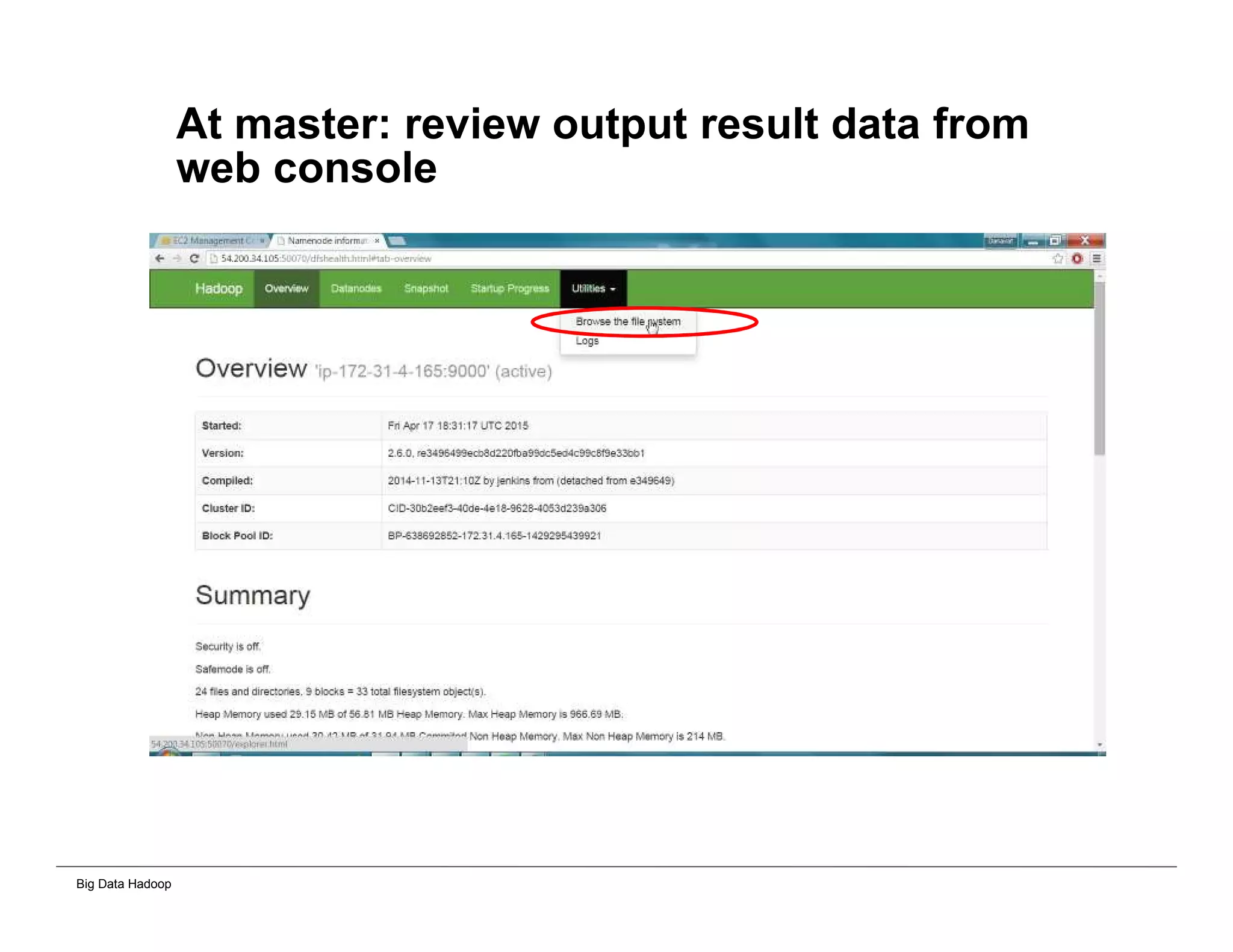
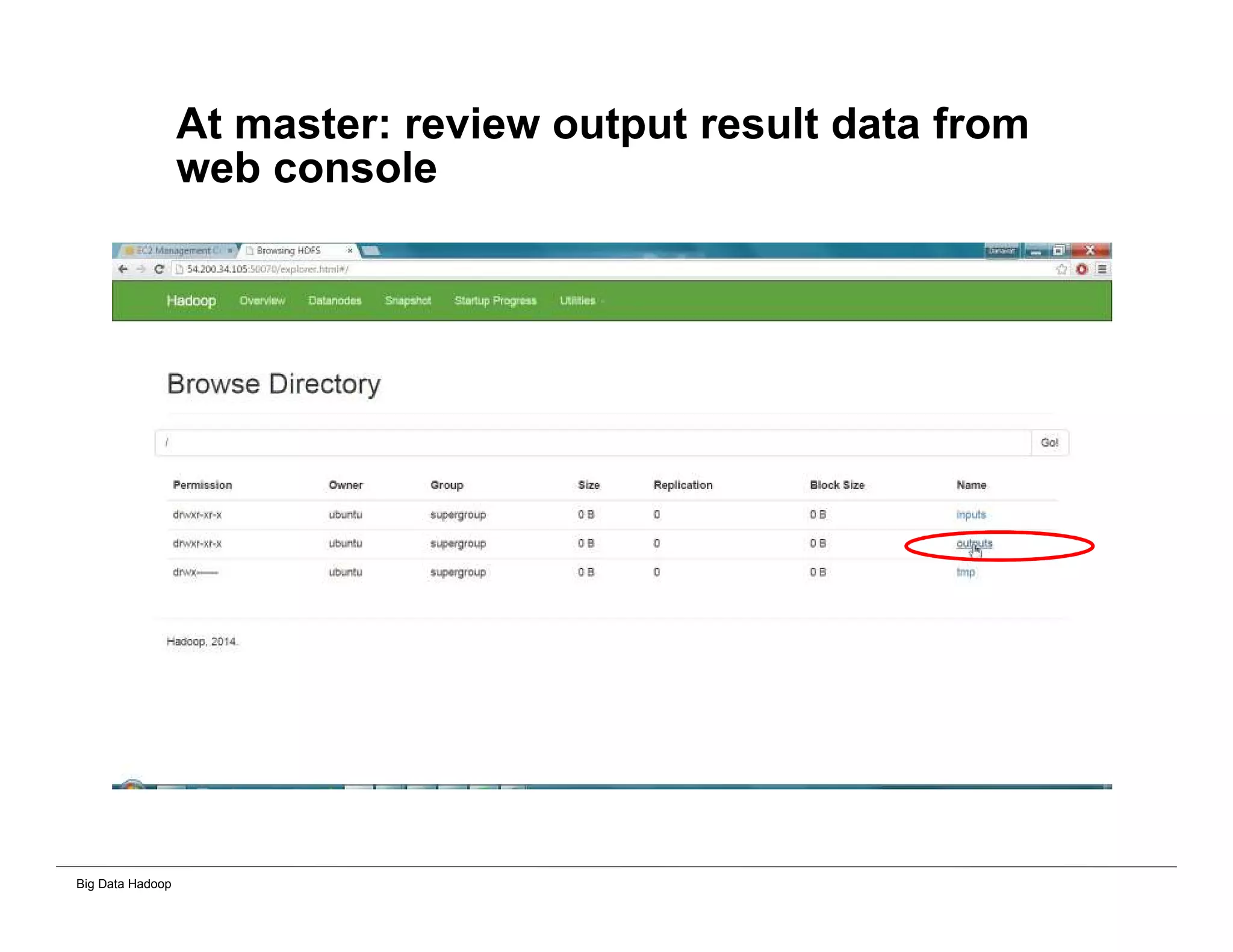
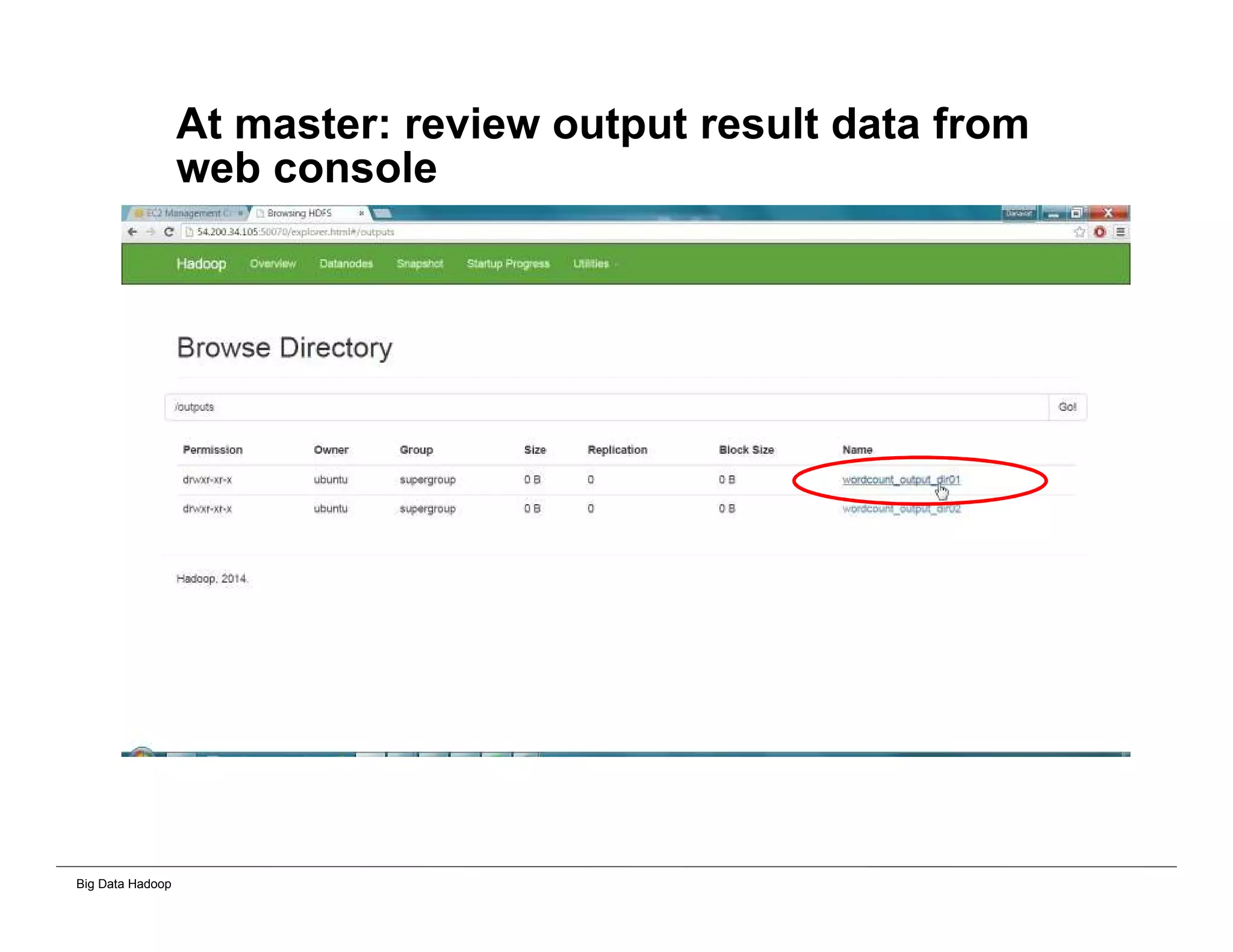
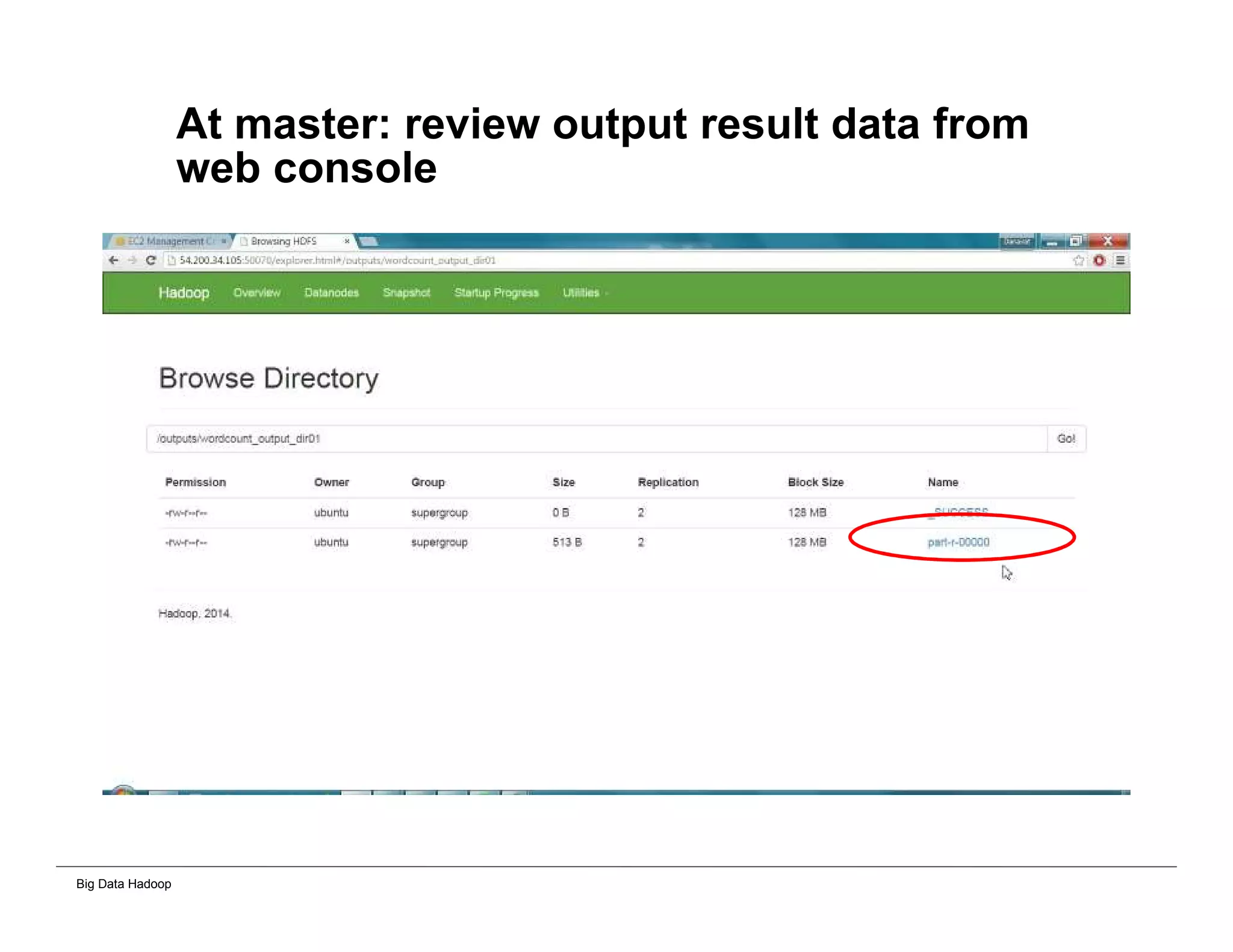





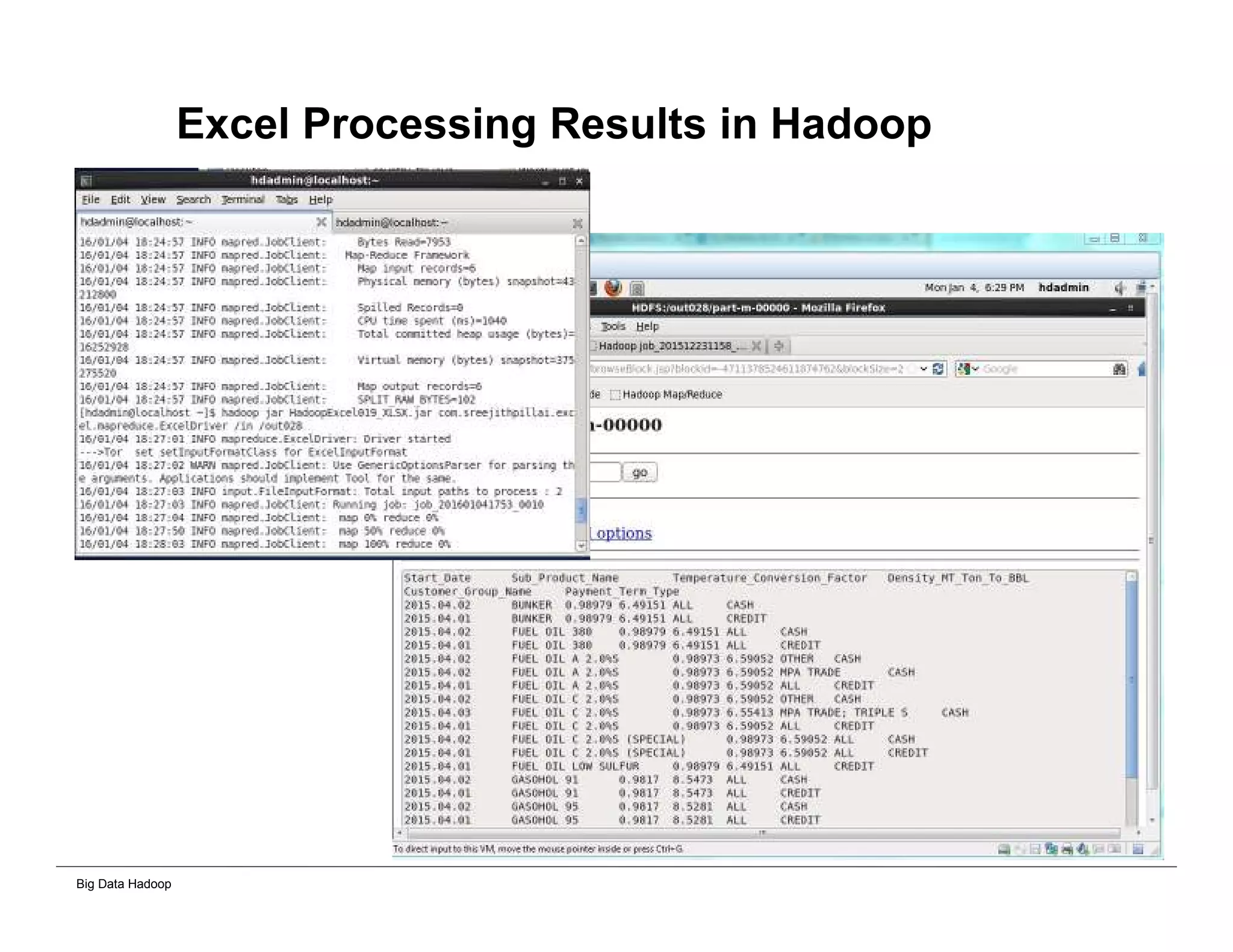

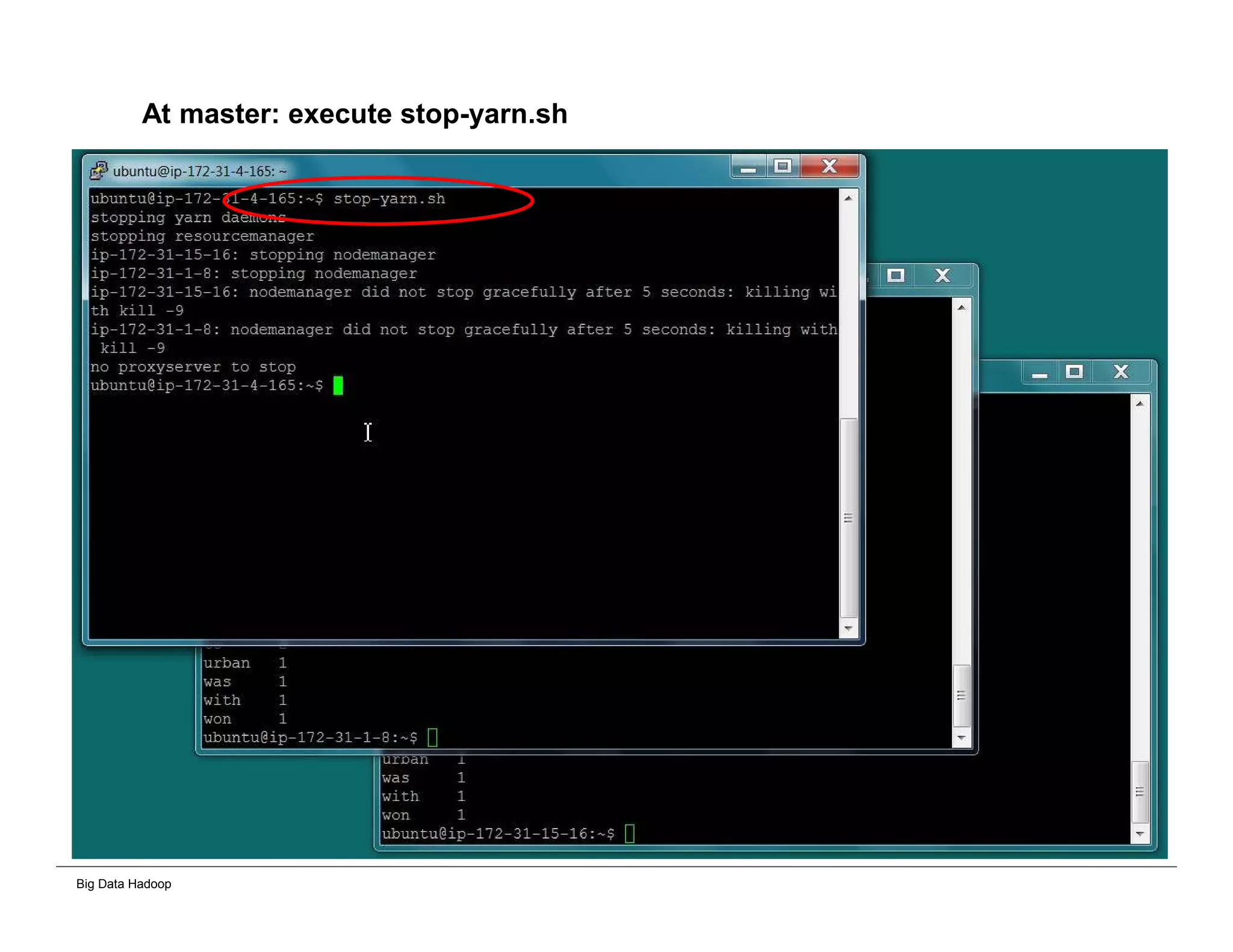
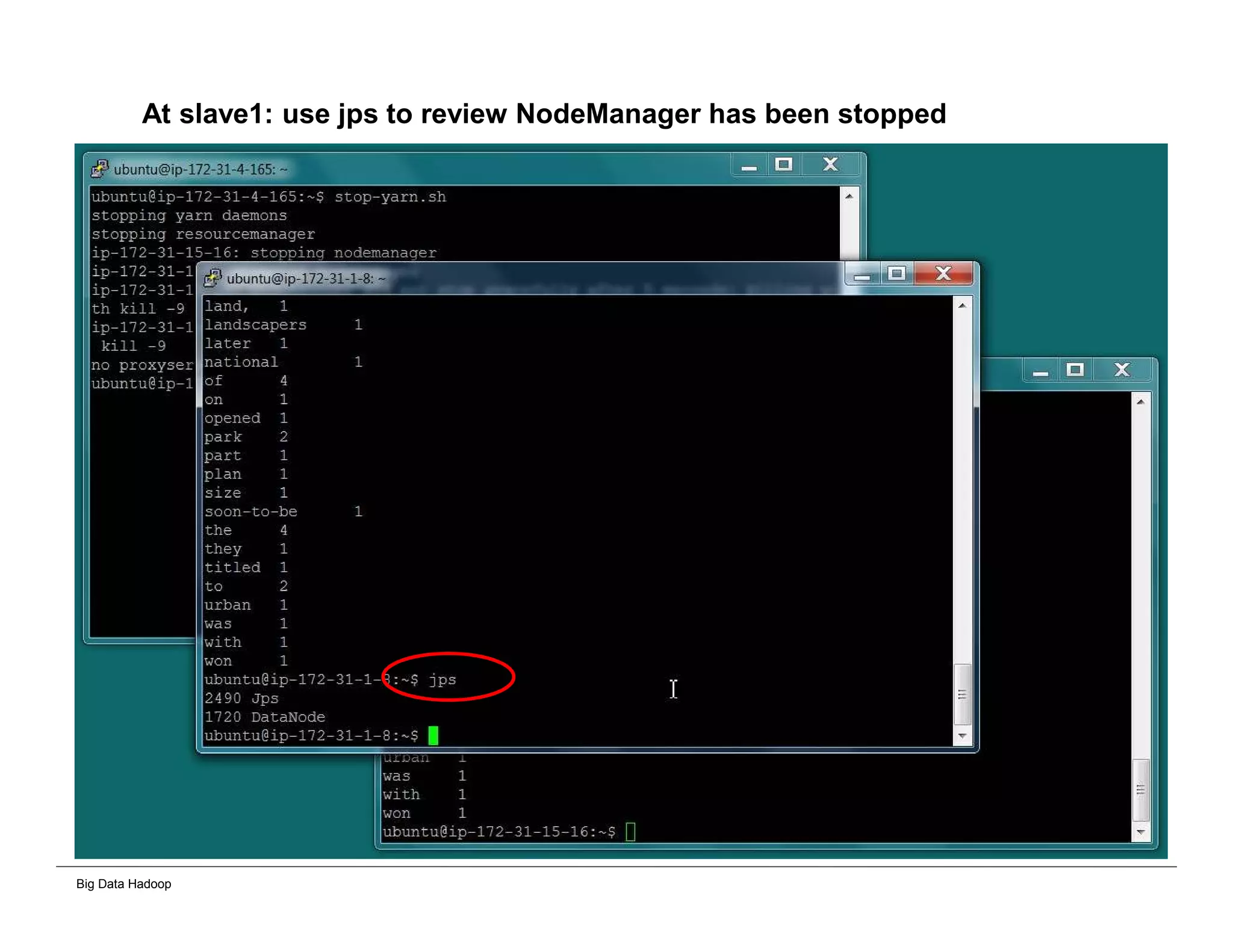
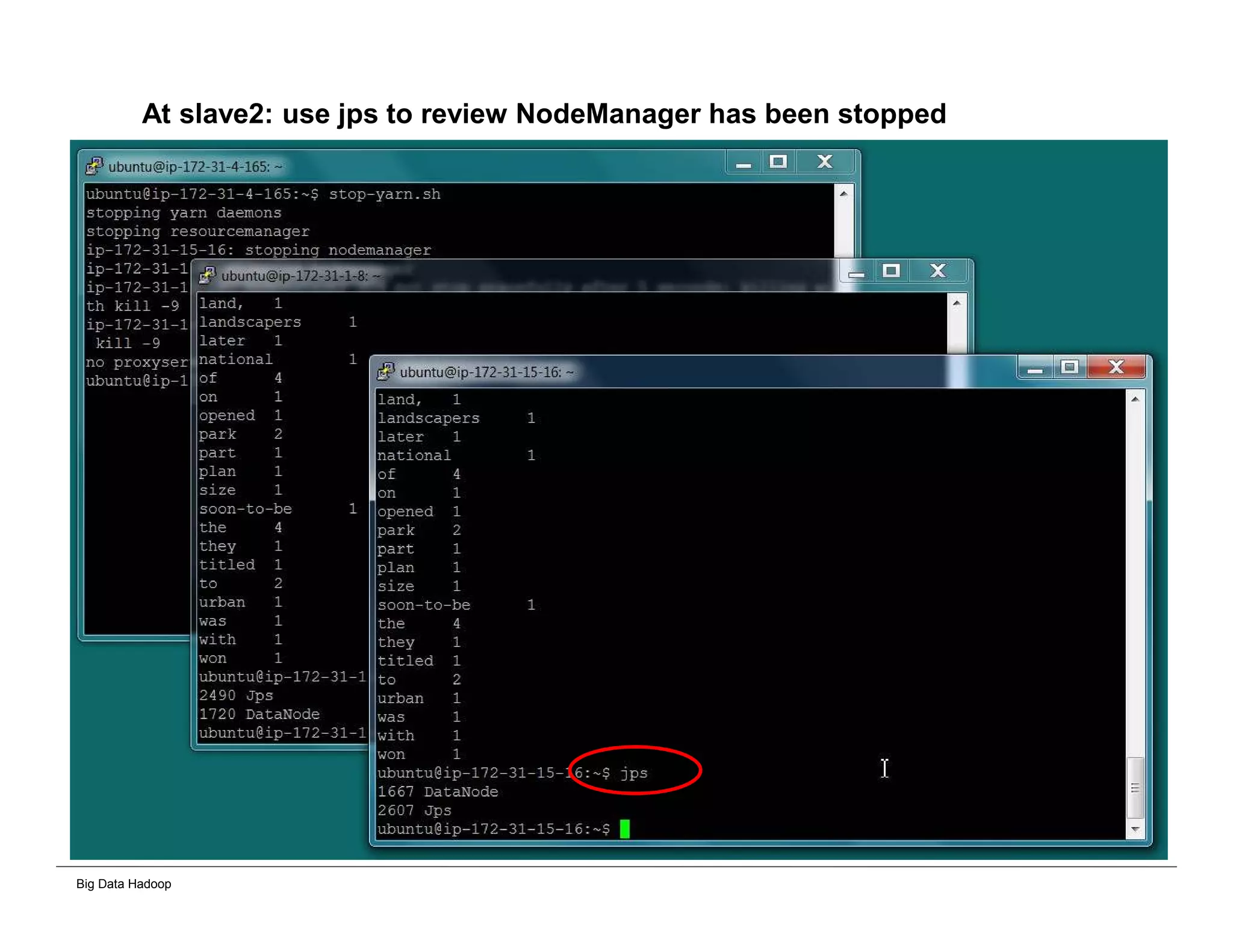
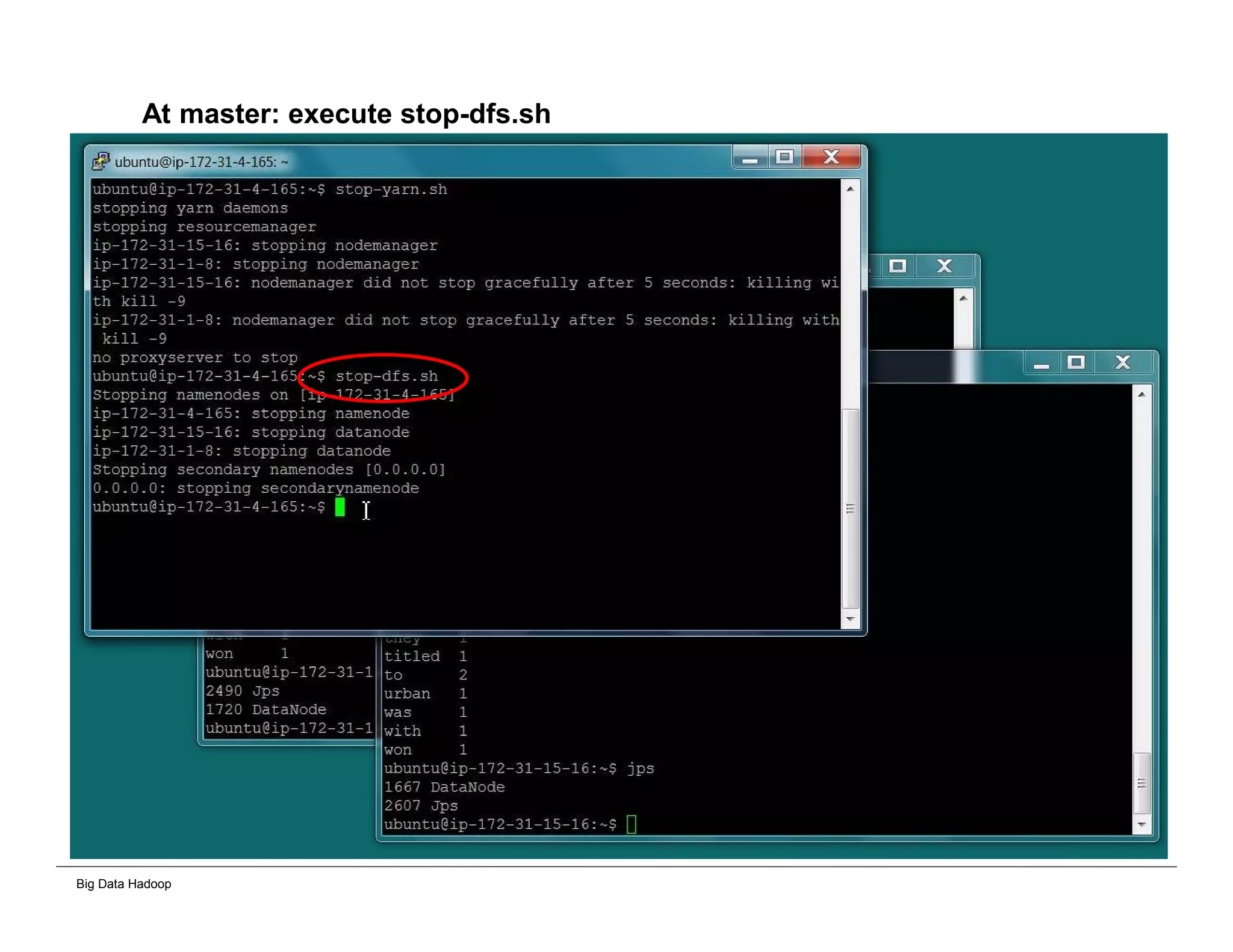
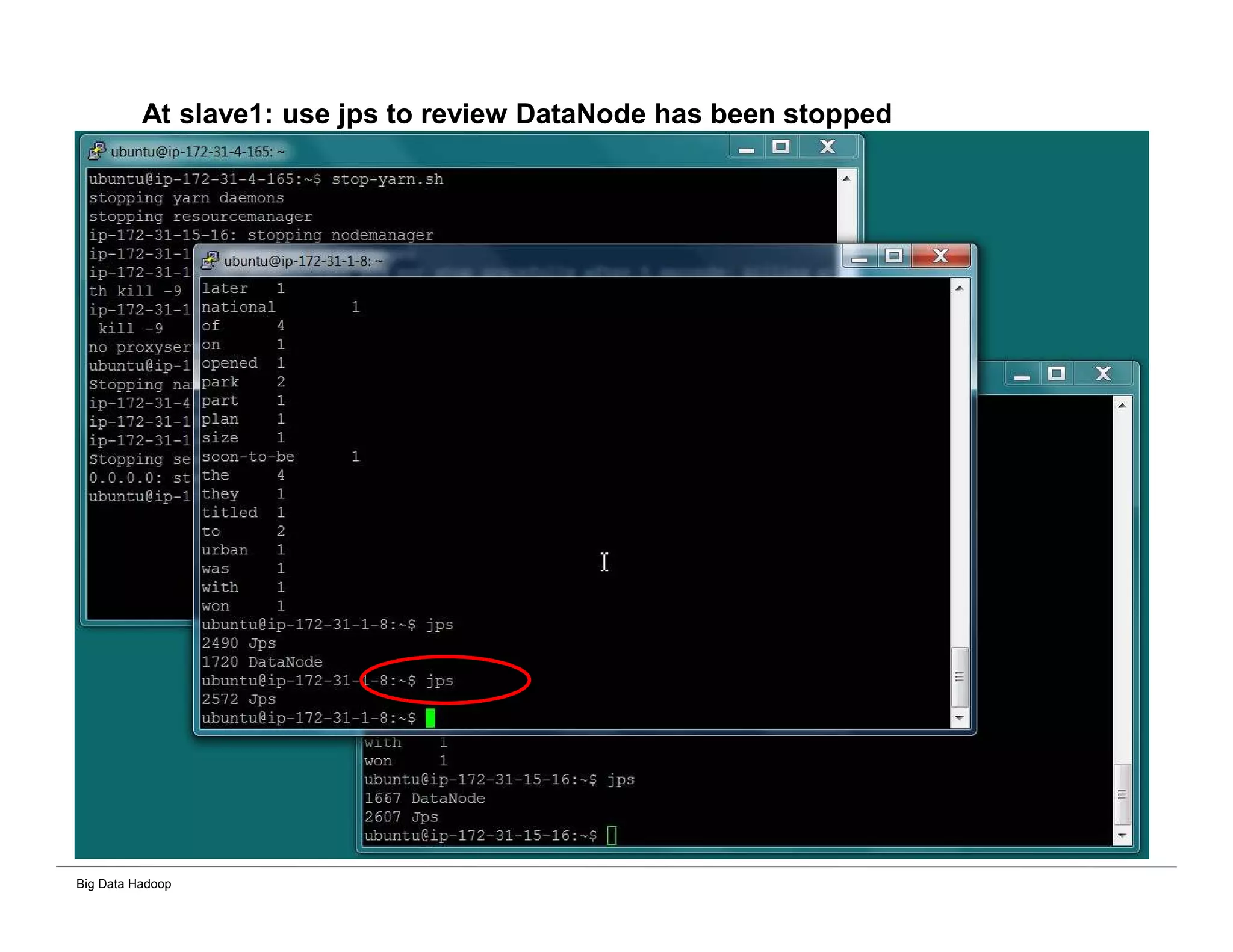
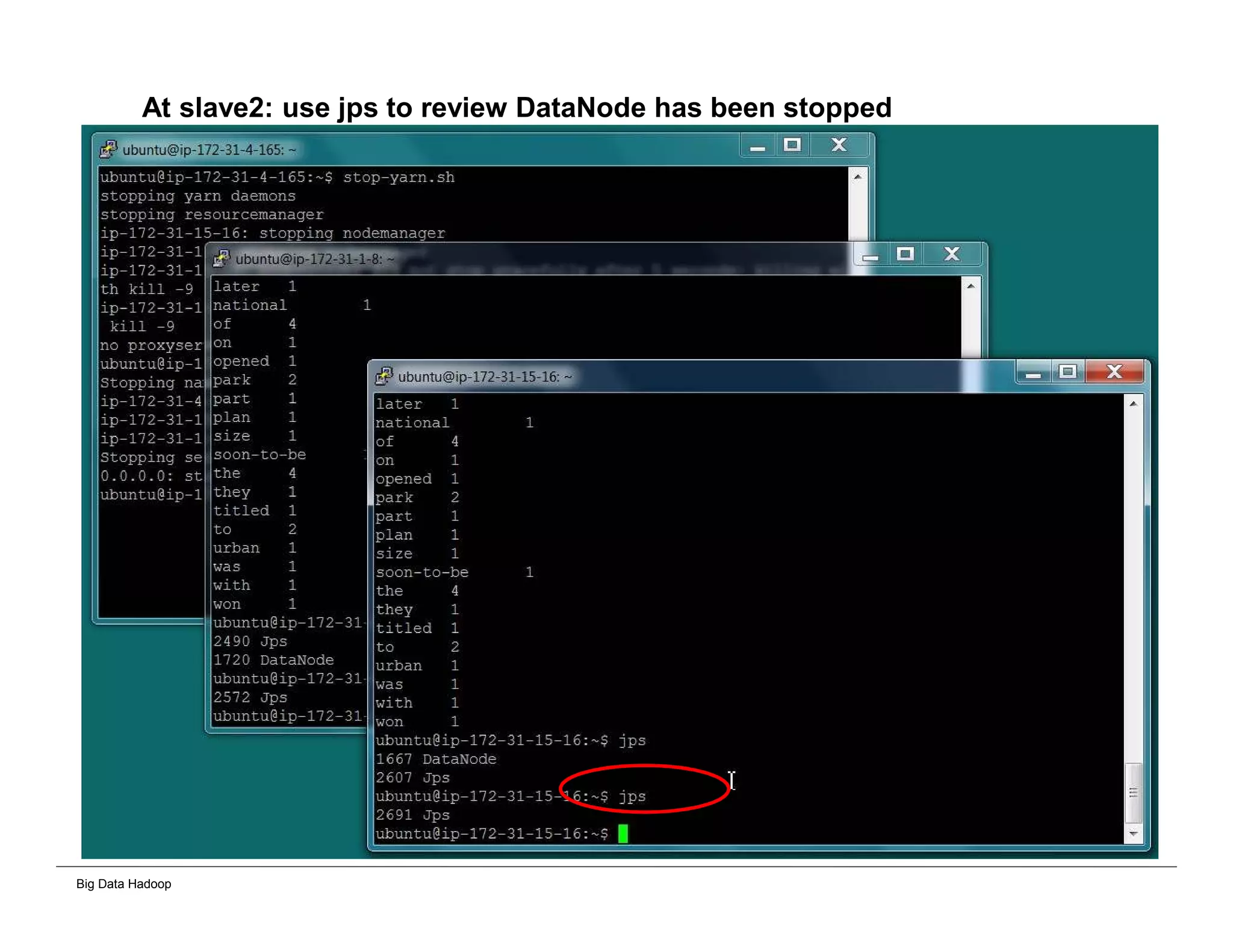


The document discusses solutions for processing big data using Hadoop as compared to a traditional data warehouse. It describes 4 solutions: 1) using core Hadoop with no data staging or movement required, 2) using BI tools to analyze Hadoop data with one transformation, 3) creating a data warehouse in Hadoop with one transformation, and 4) implementing a traditional data warehouse. Each solution is compared based on benefits like being cloud ready, parallel processing, and having an IoT architecture roadmap. The document also includes examples and steps for installing a Hadoop cluster, importing and analyzing sample data, and processing an Excel worksheet.






![Interview questions on Apache spark [part 2]](https://cdn.slidesharecdn.com/ss_thumbnails/interviewquestionsonapachesparkpart2-150731093720-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)





























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















