Downloaded 218 times




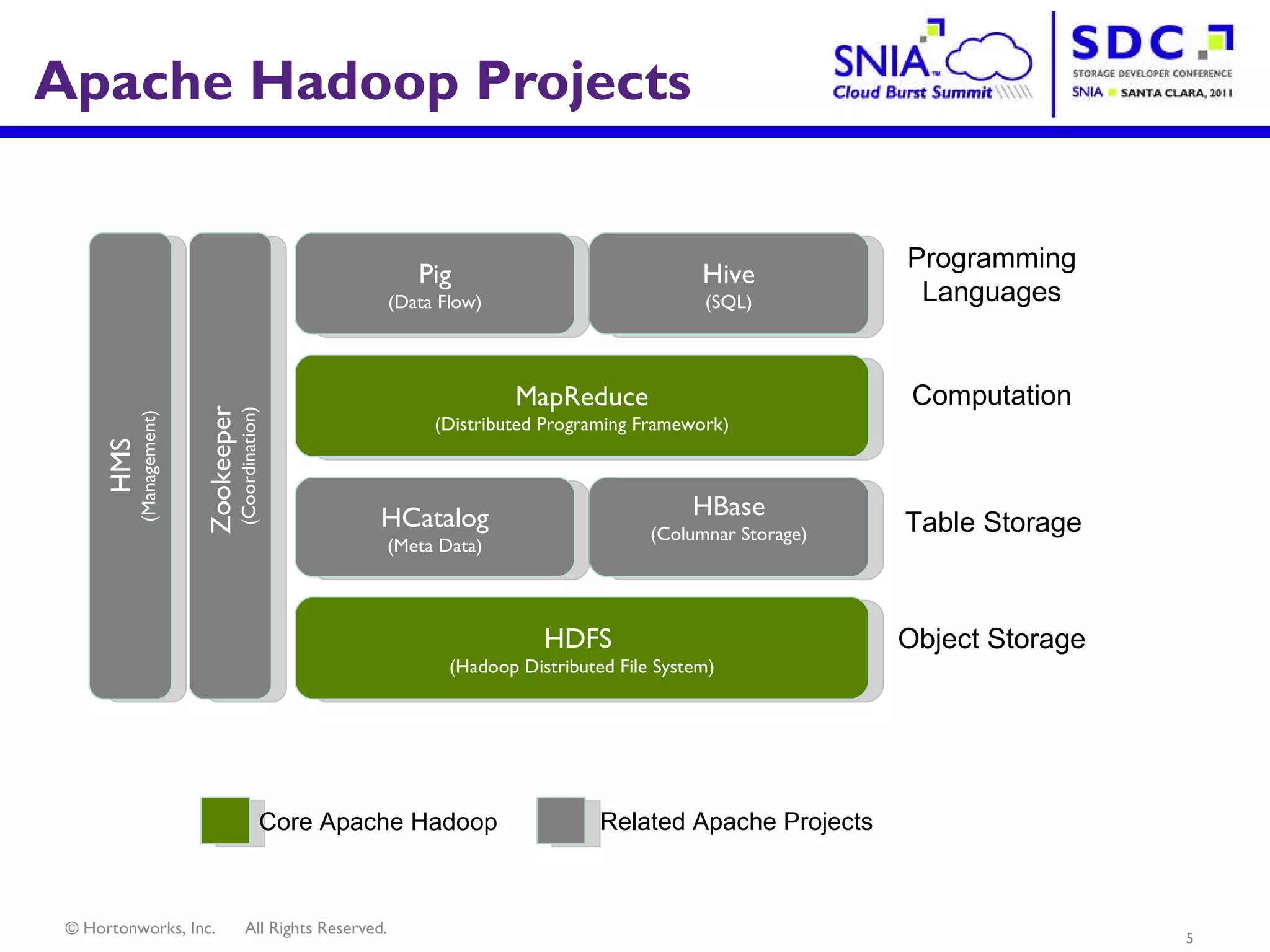




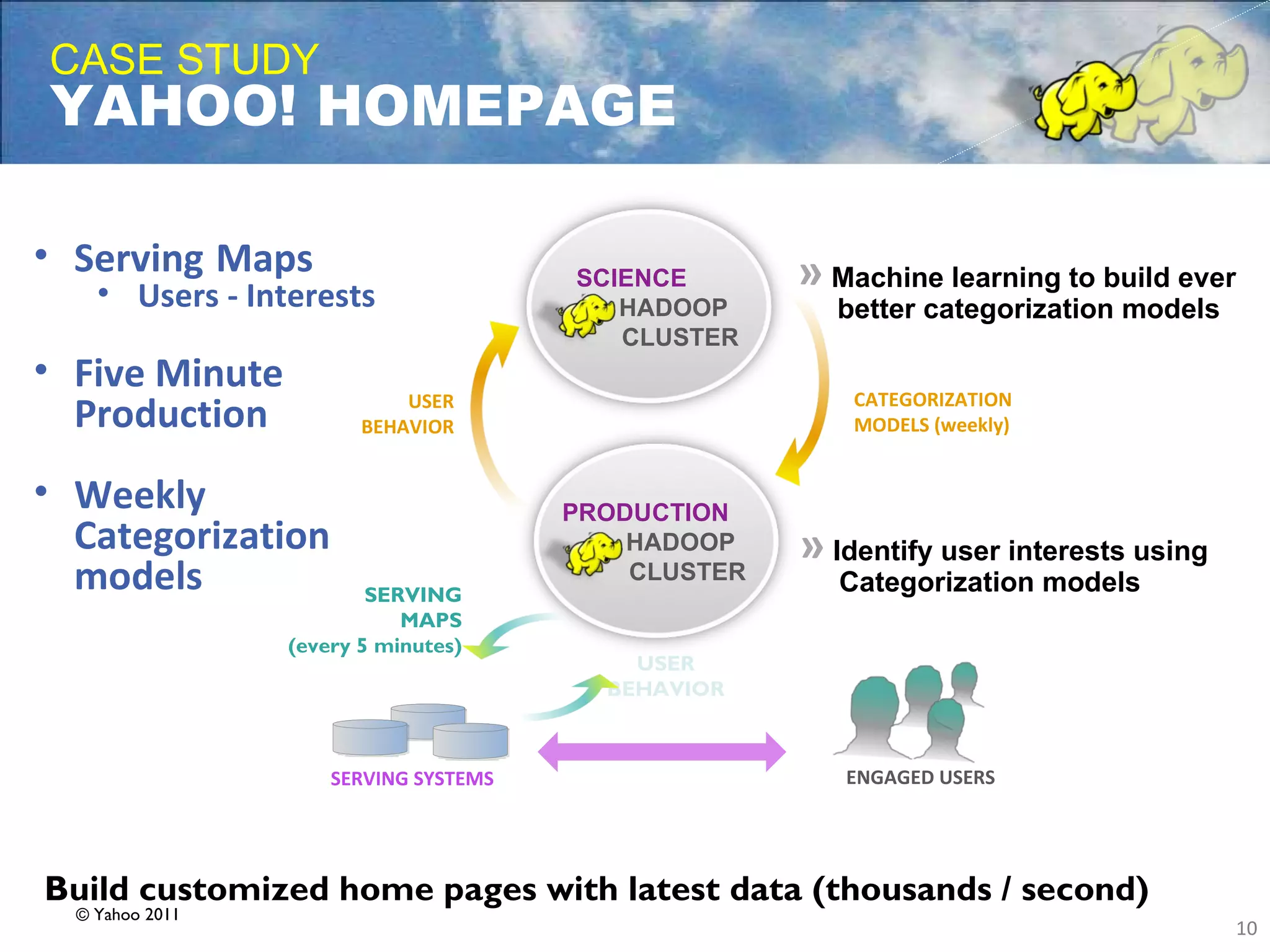

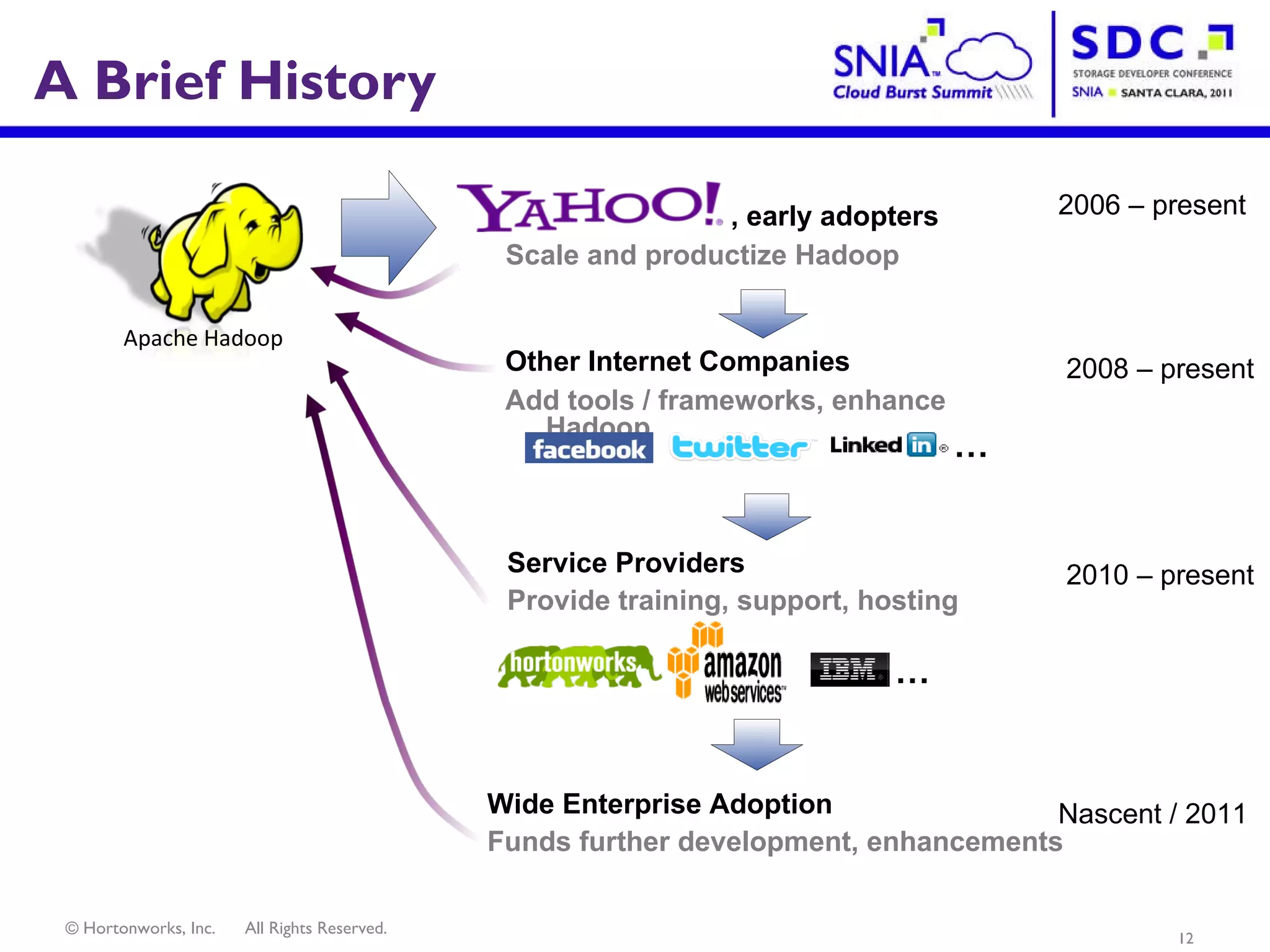

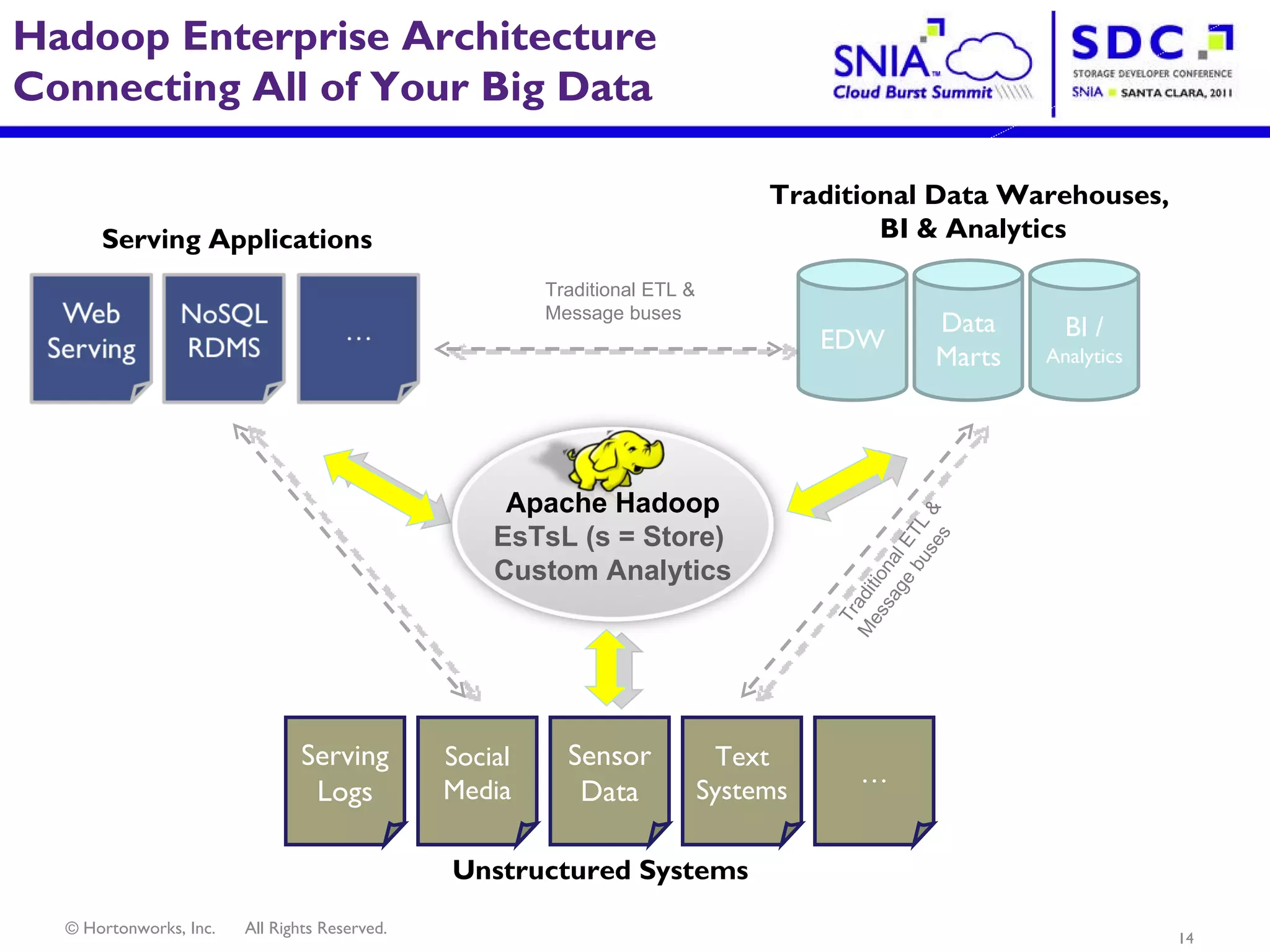
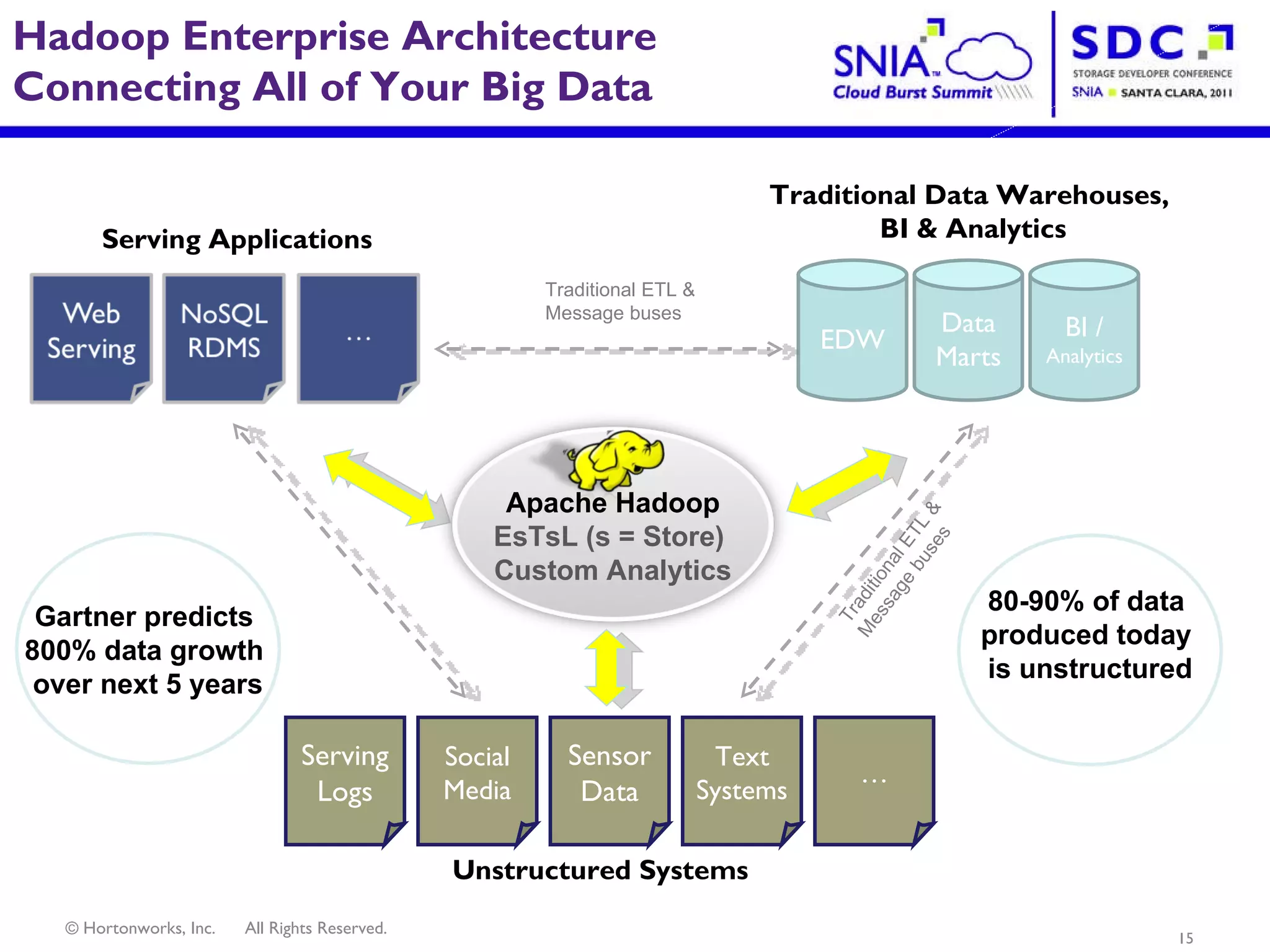

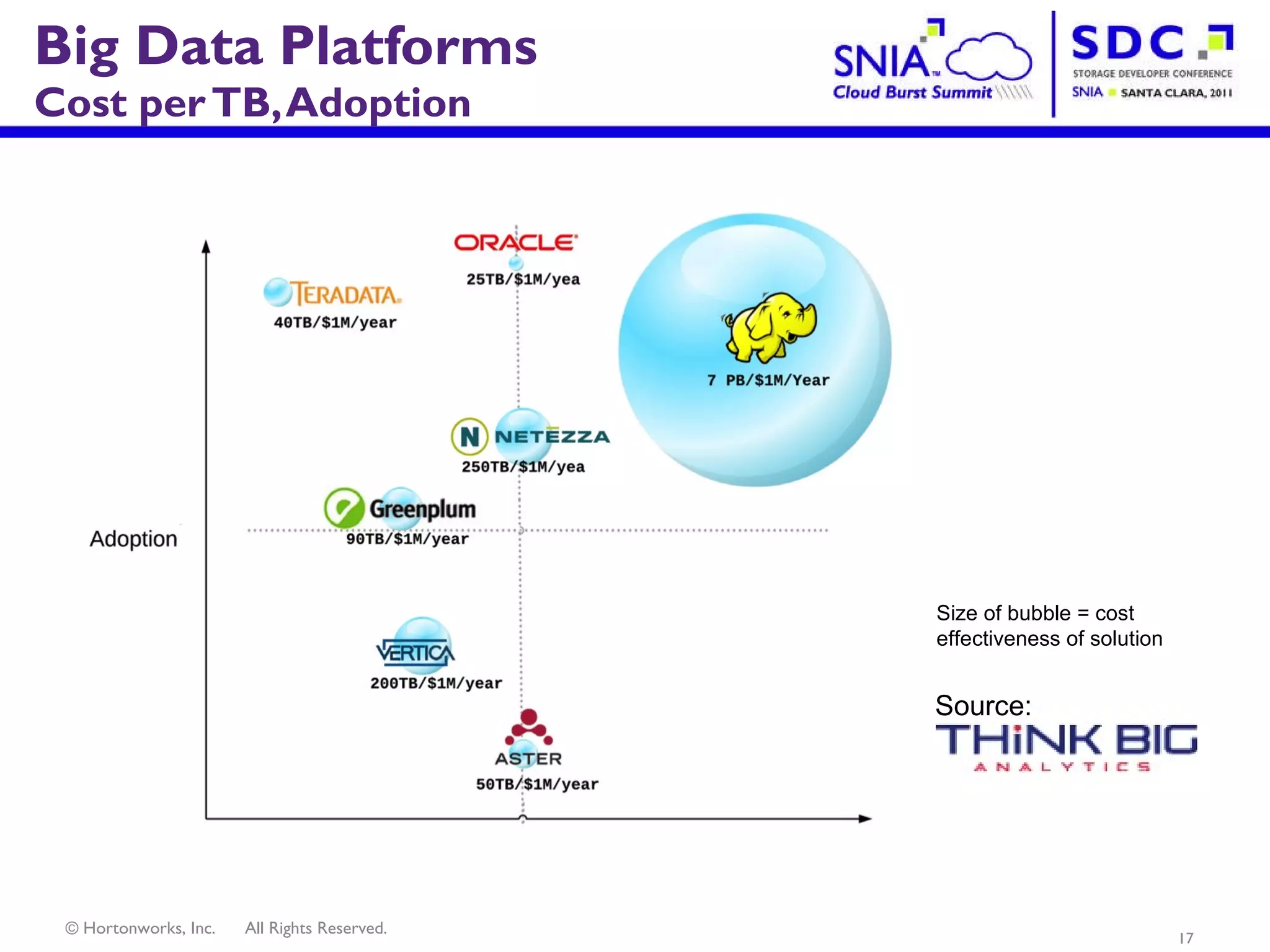

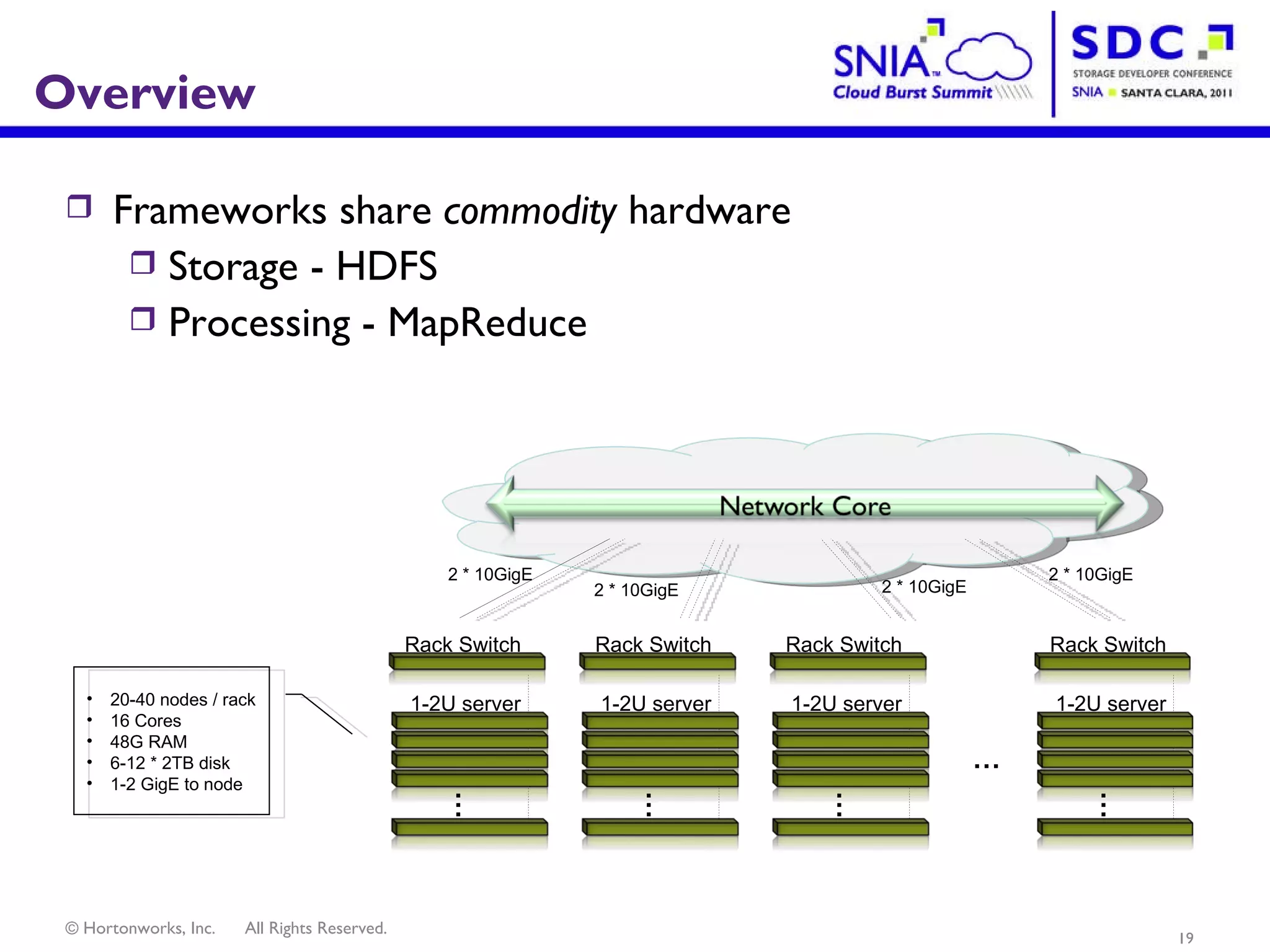

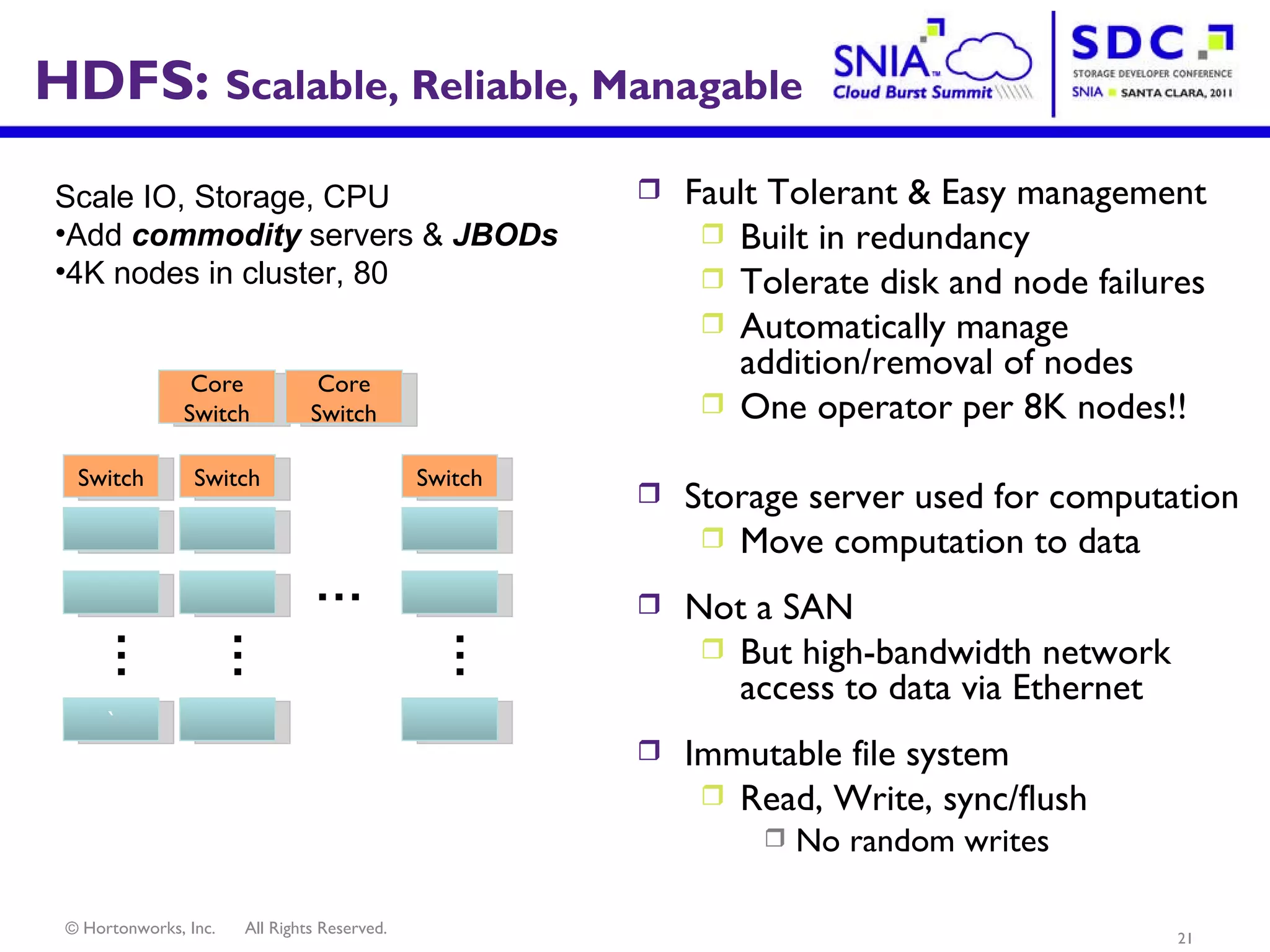

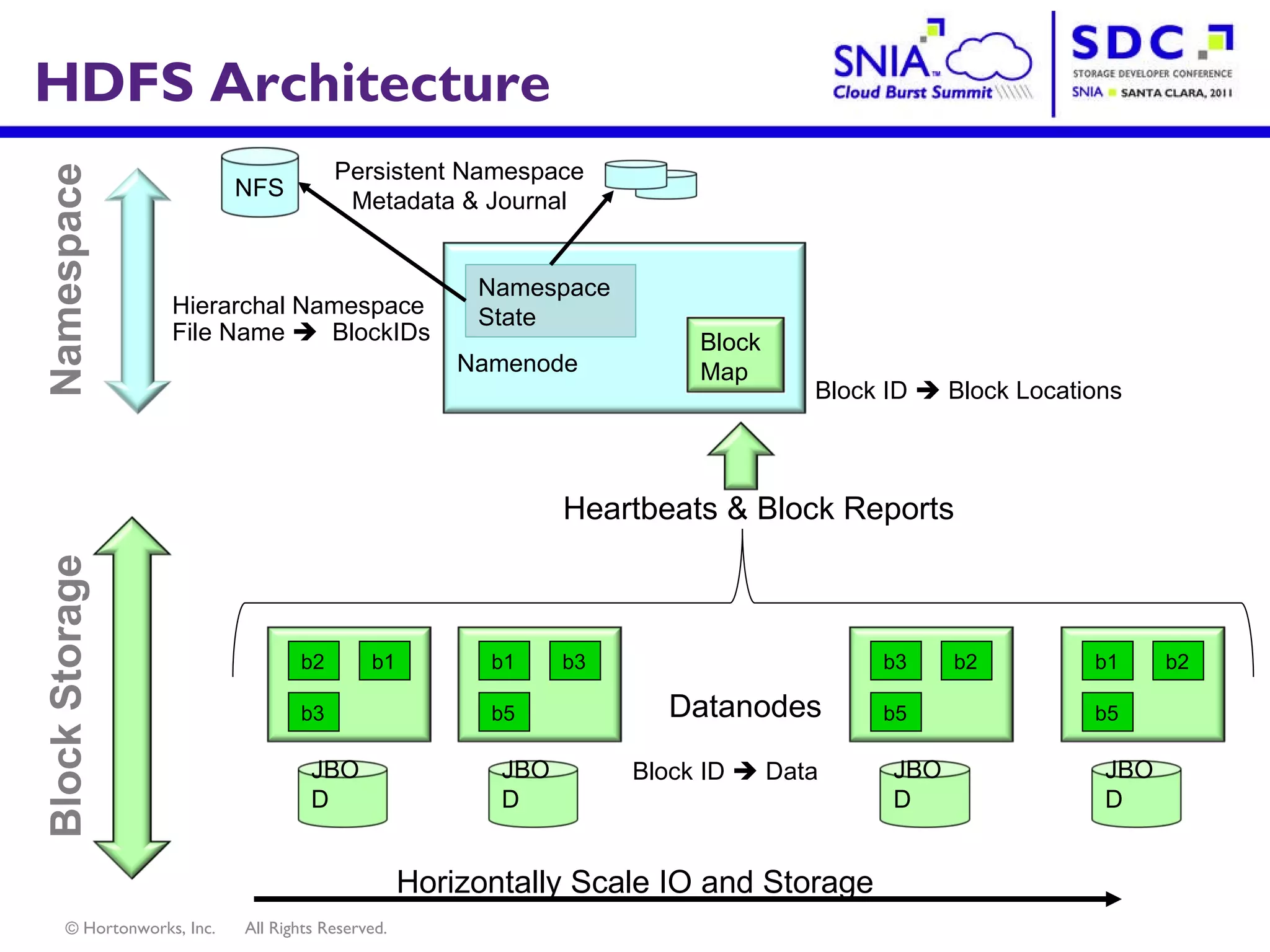
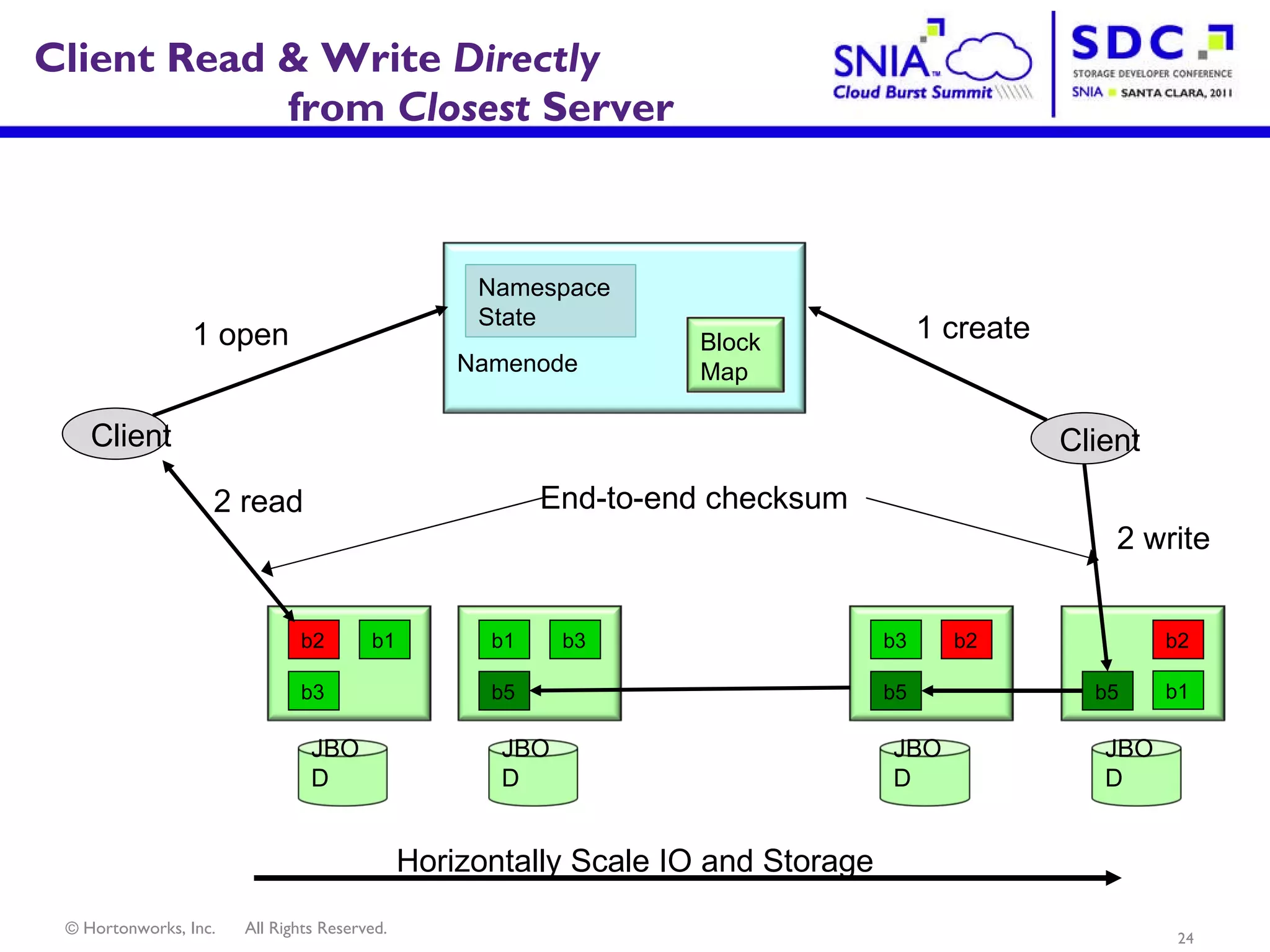
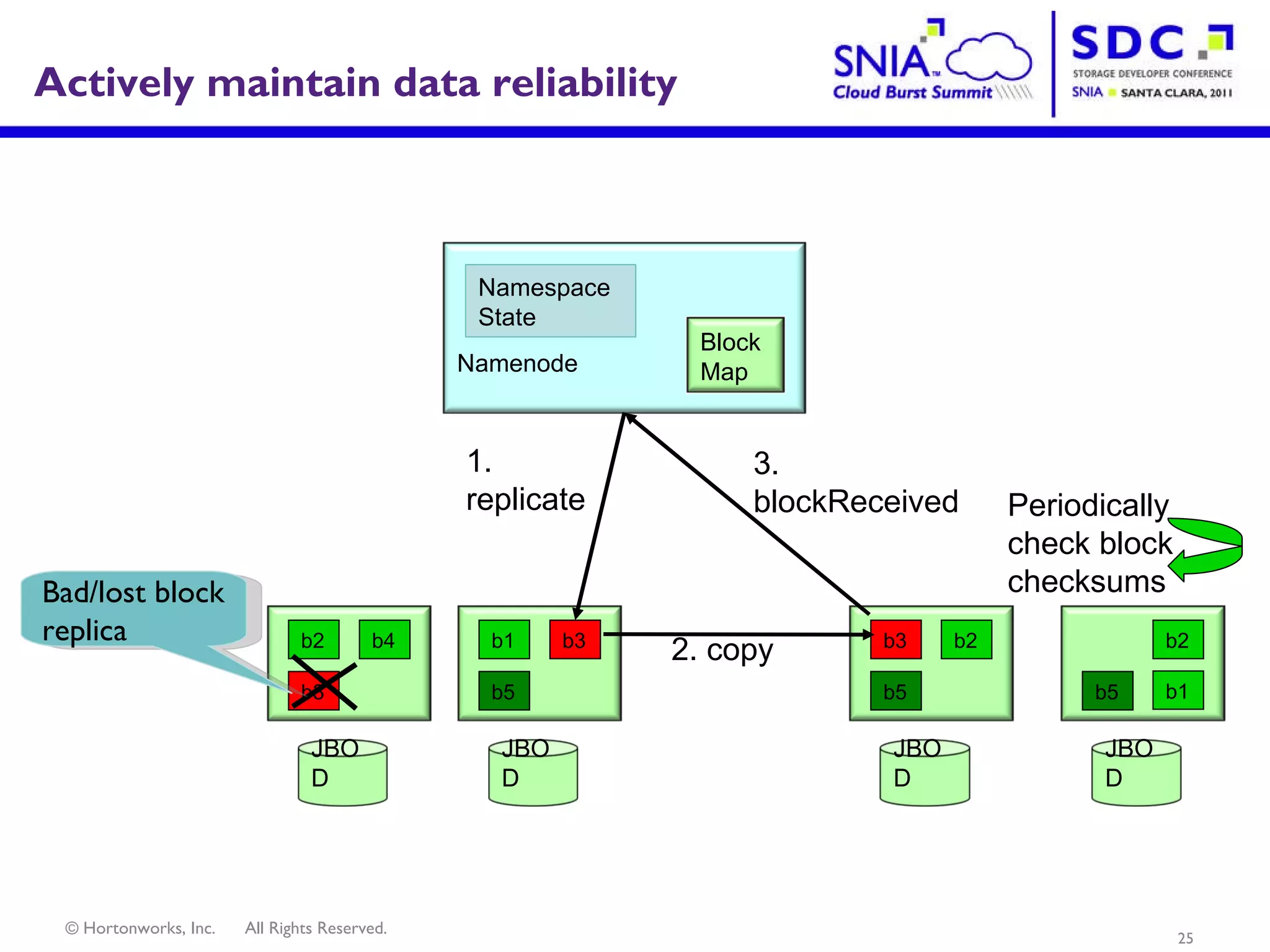




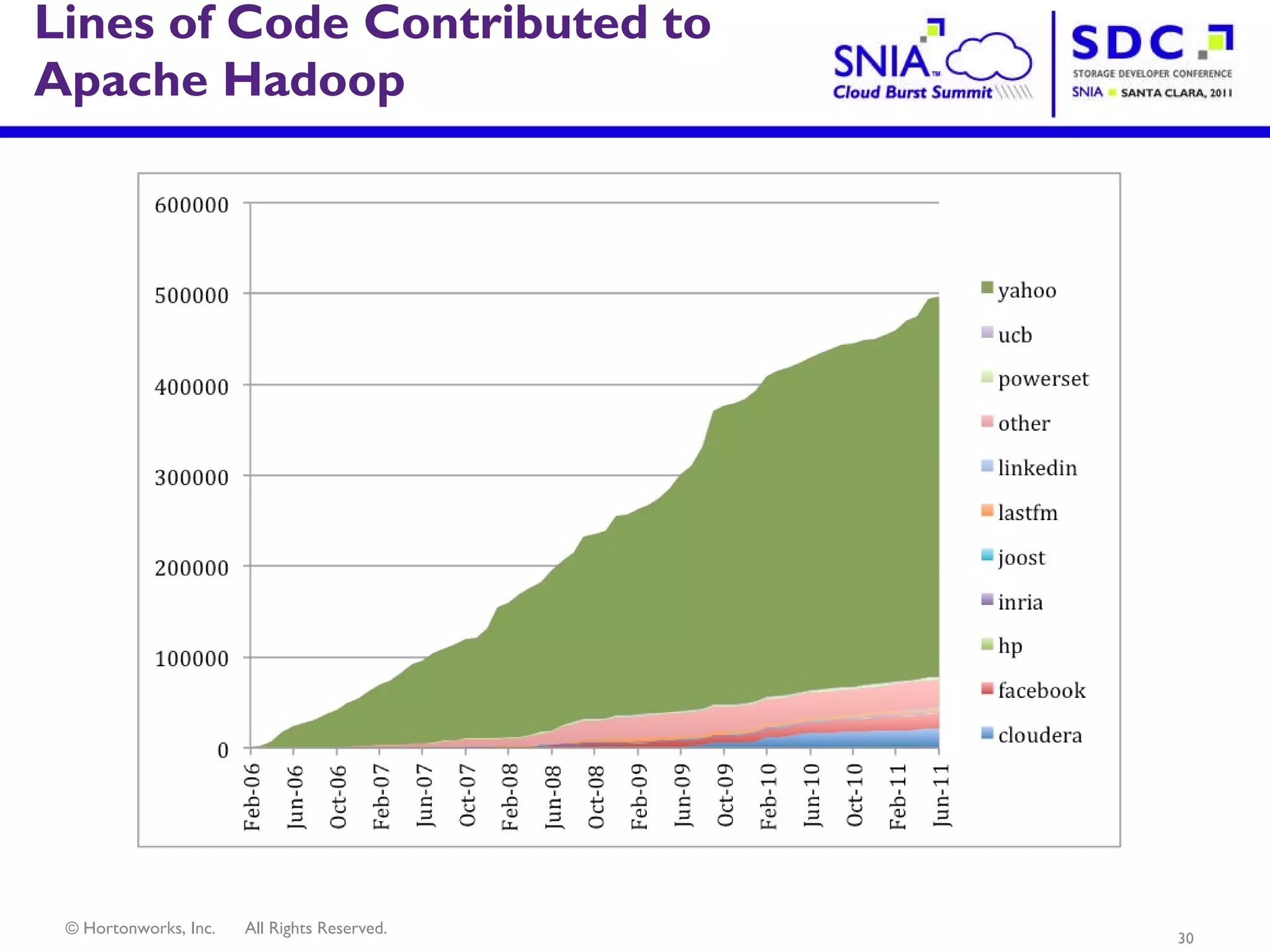




- Apache Hadoop is an open-source software framework for distributed storage and processing of large datasets across clusters of computers. It allows for the reliable storage of petabytes of data and large-scale computations across commodity hardware. - Apache Hadoop is used widely by internet companies to analyze web server logs, power search engines, and gain insights from large amounts of social and user data. It is also used for machine learning, data mining, and processing audio, video, and text data. - The future of Apache Hadoop includes making it more accessible and easy to use for enterprises, addressing gaps like high availability and management, and enabling partners and the community to build on it through open APIs and a modular architecture.




































































![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)







