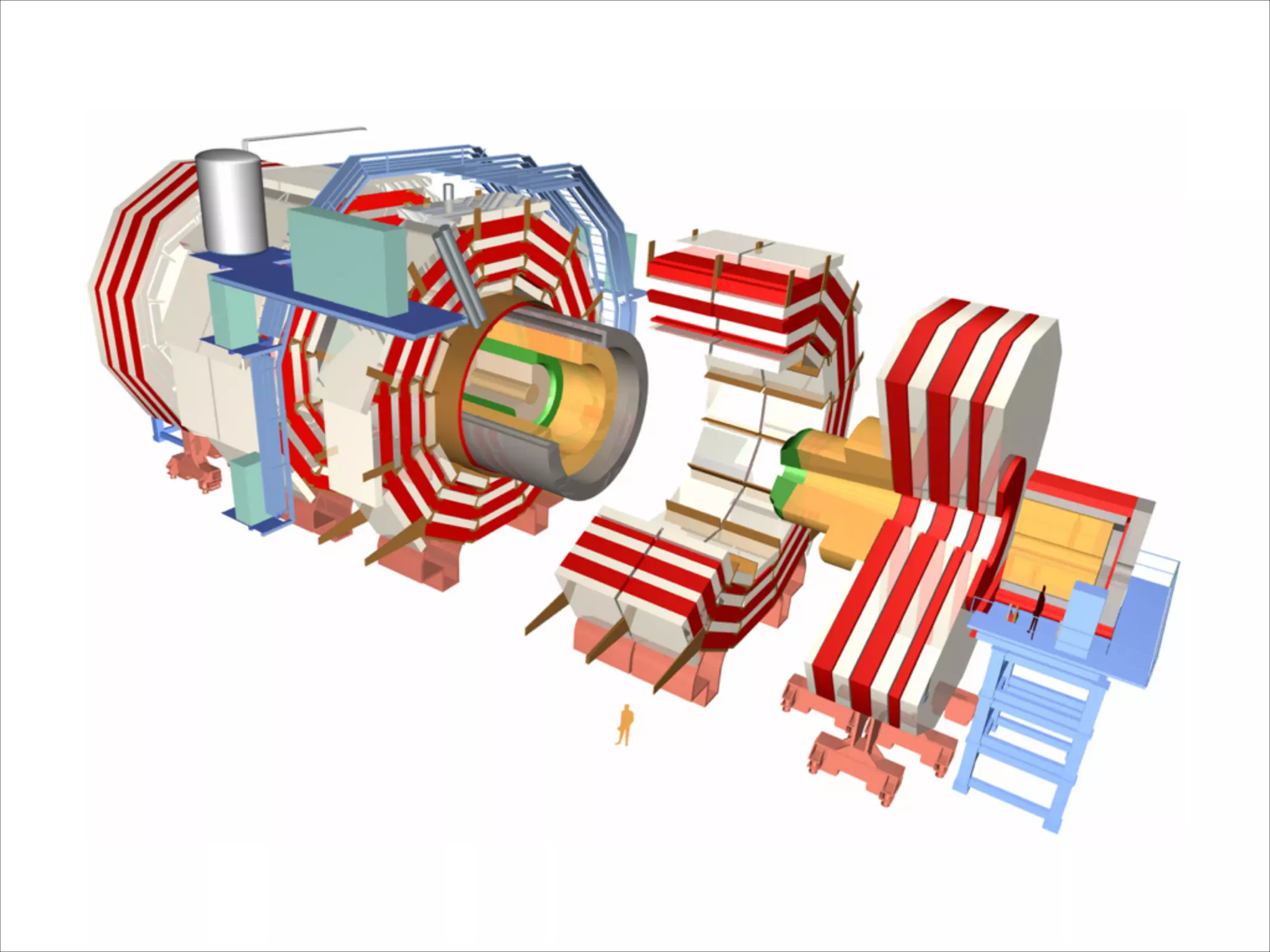
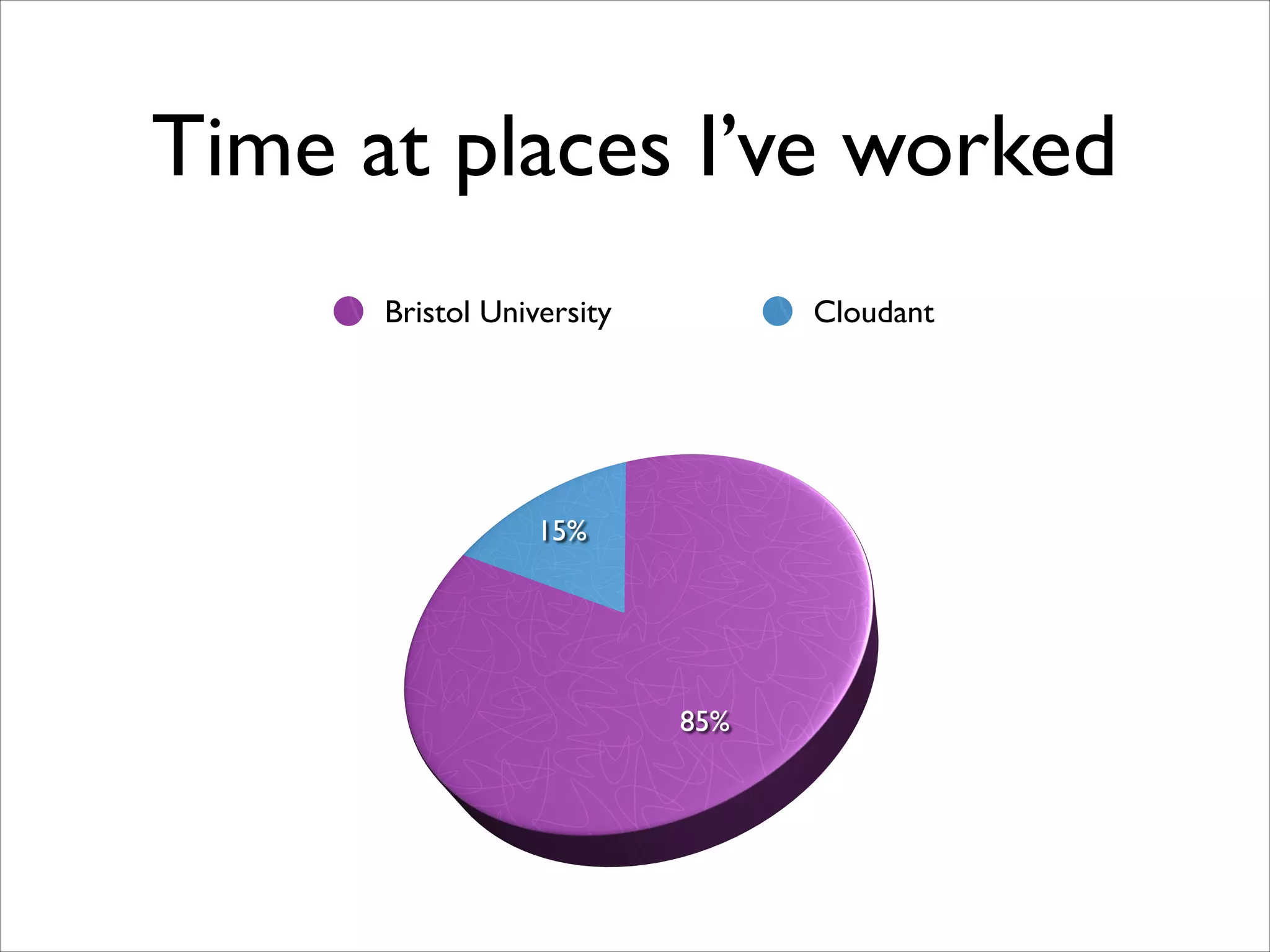
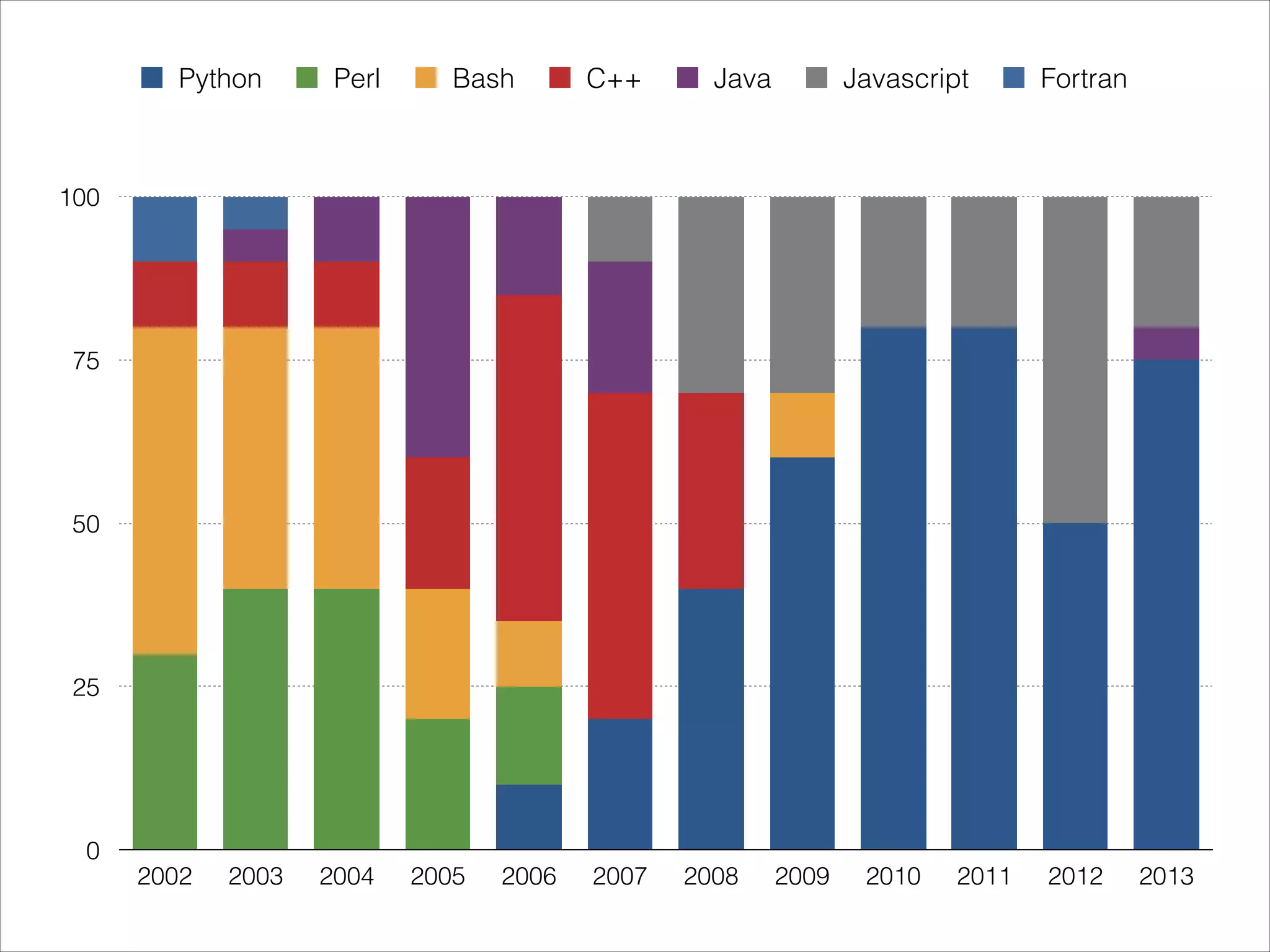
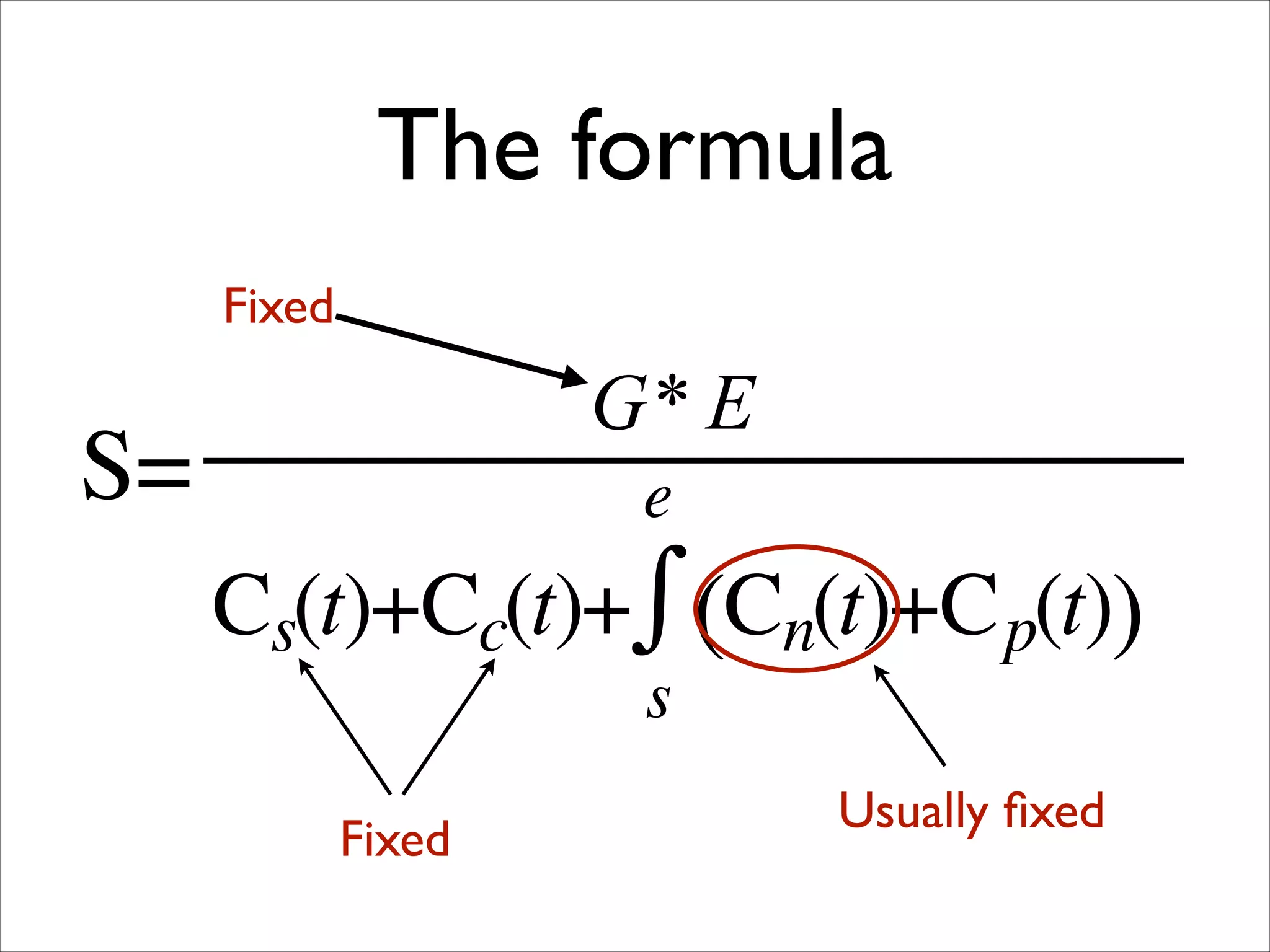
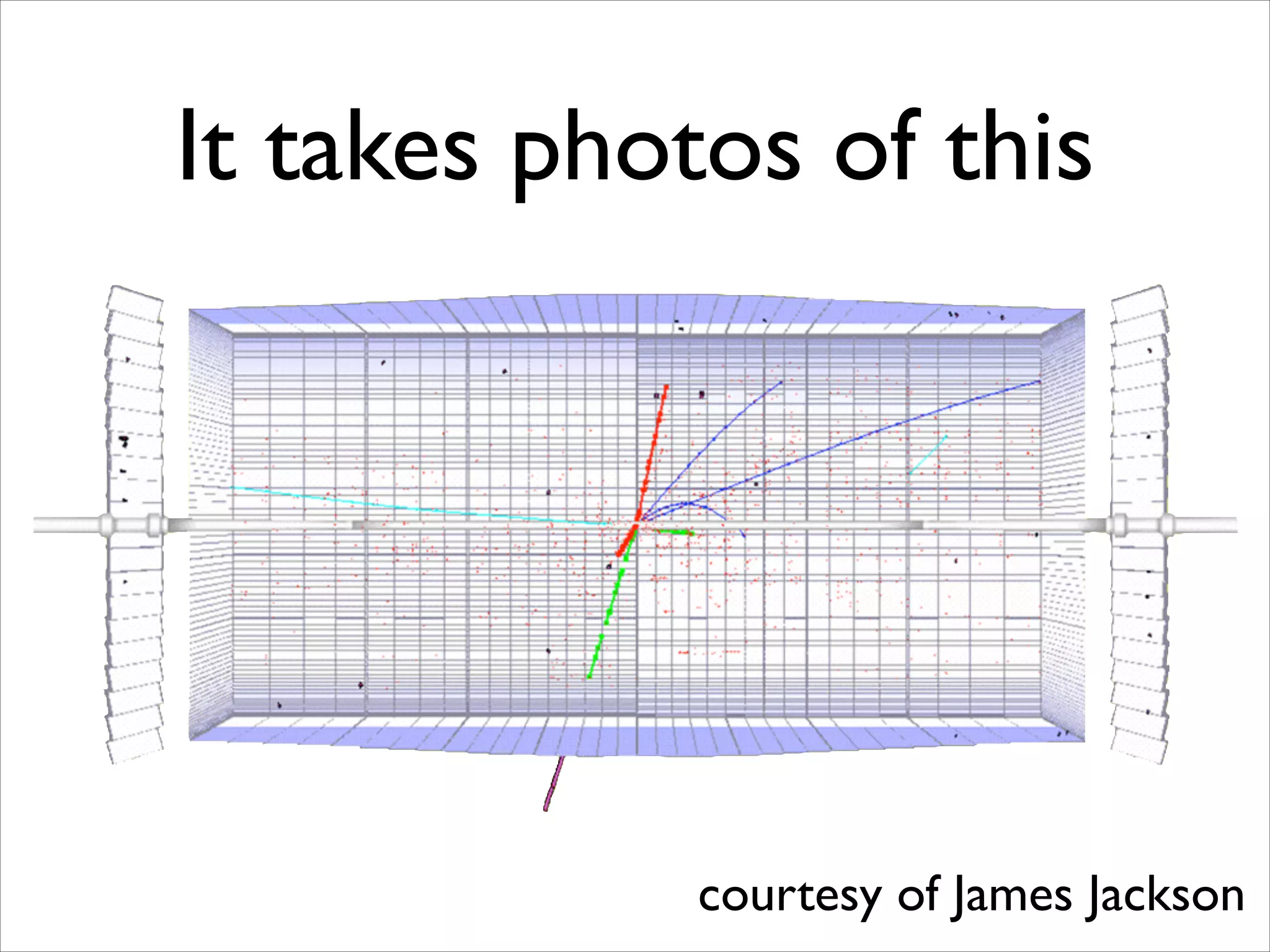
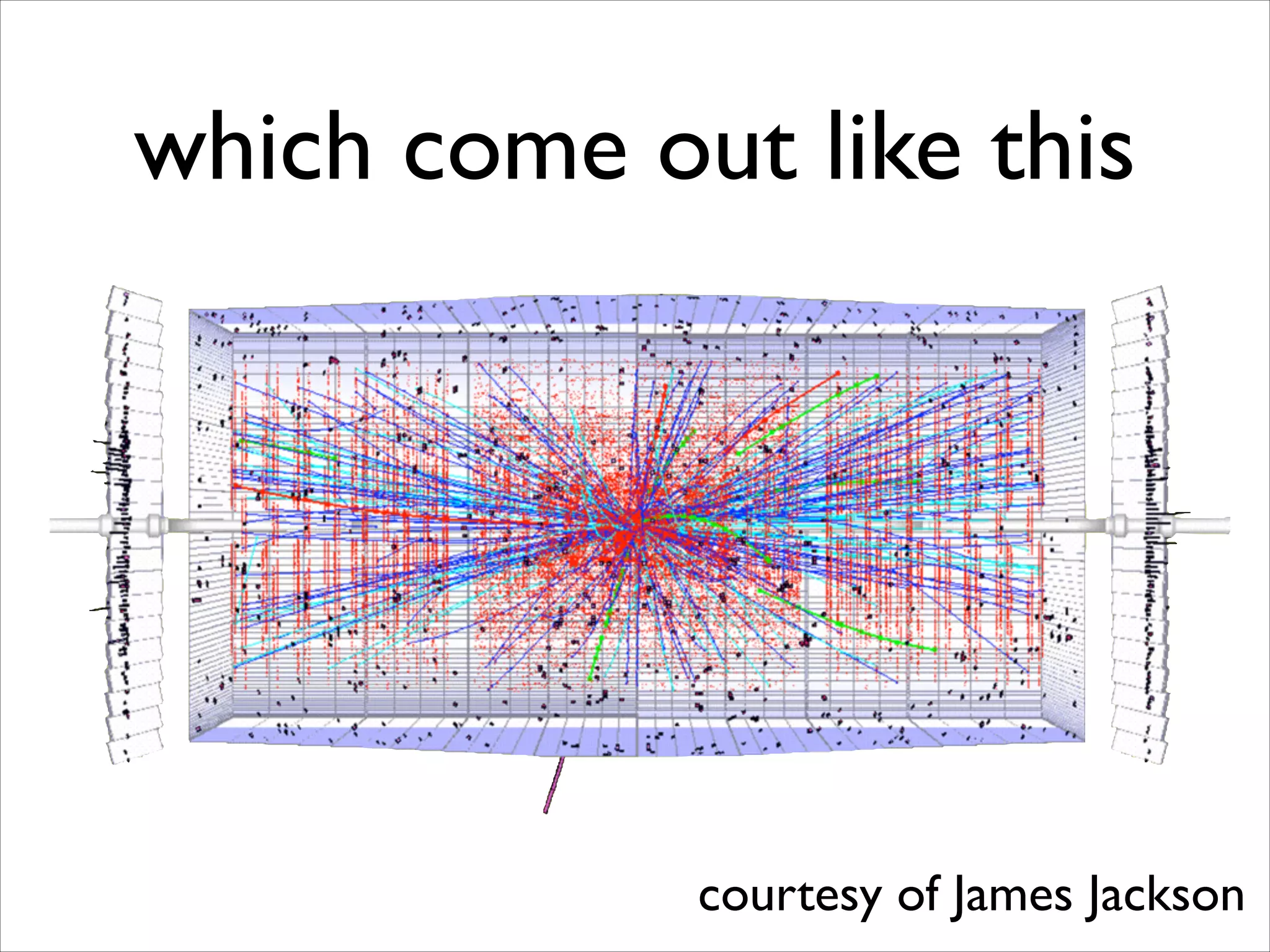
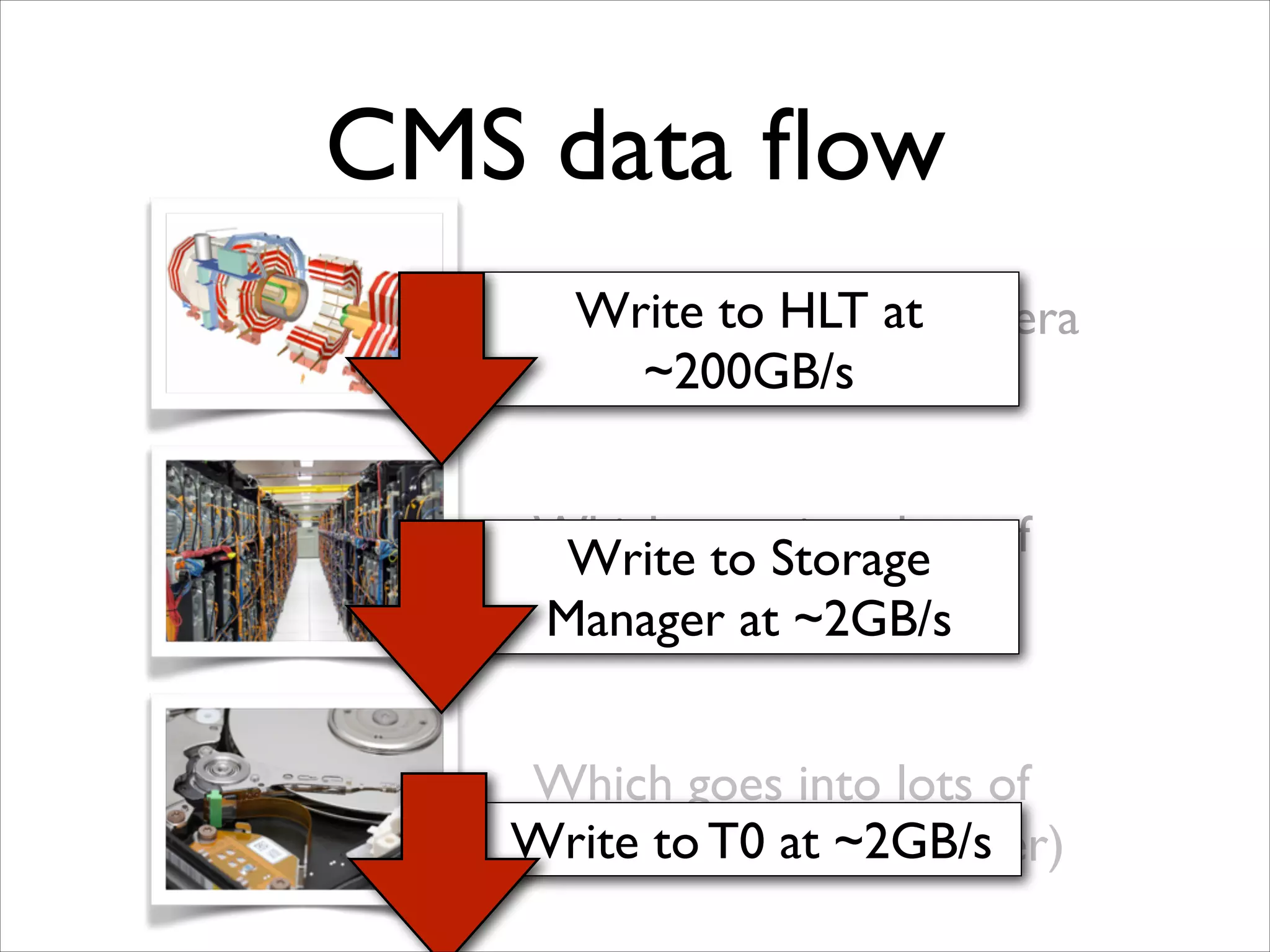
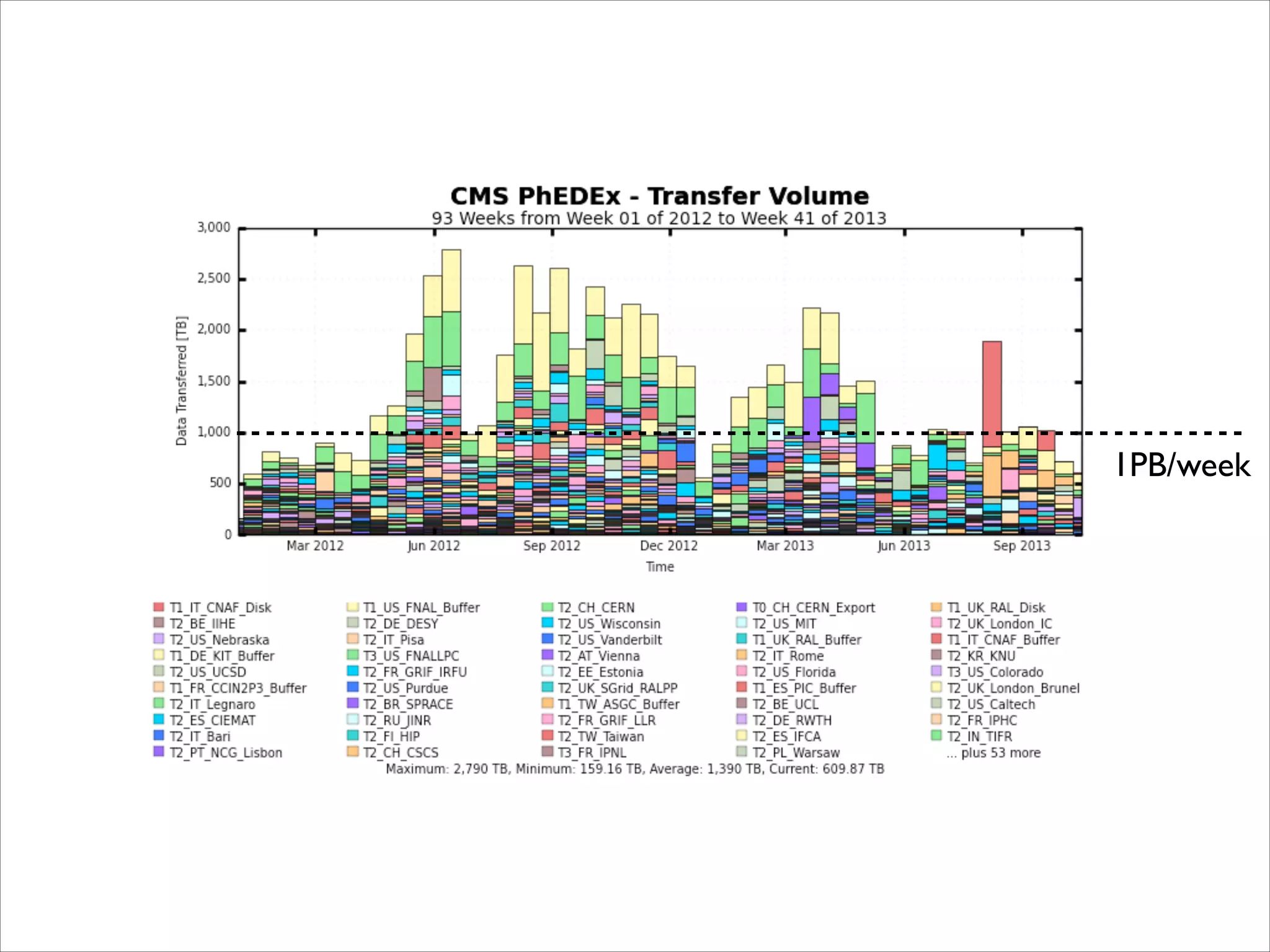
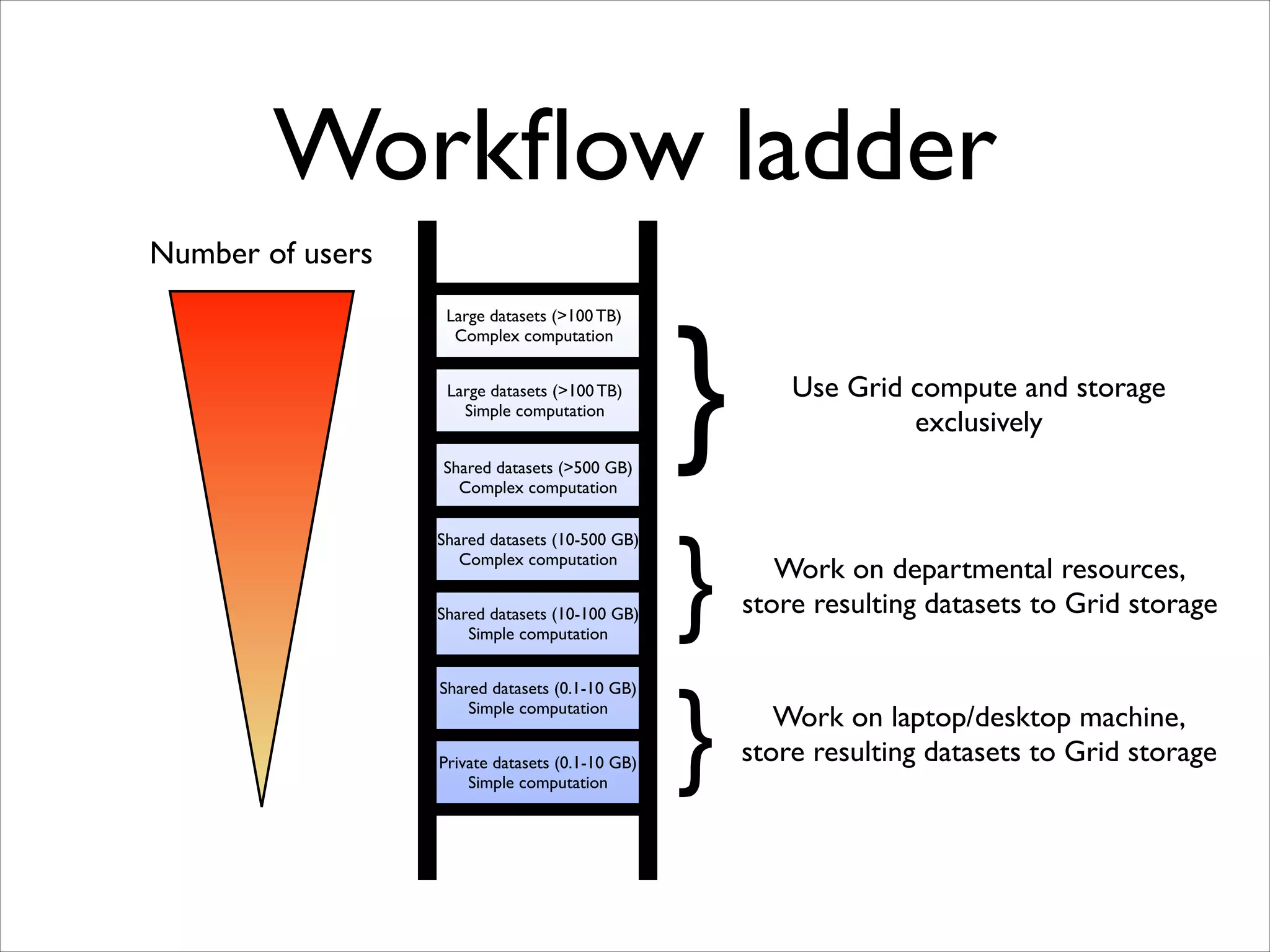
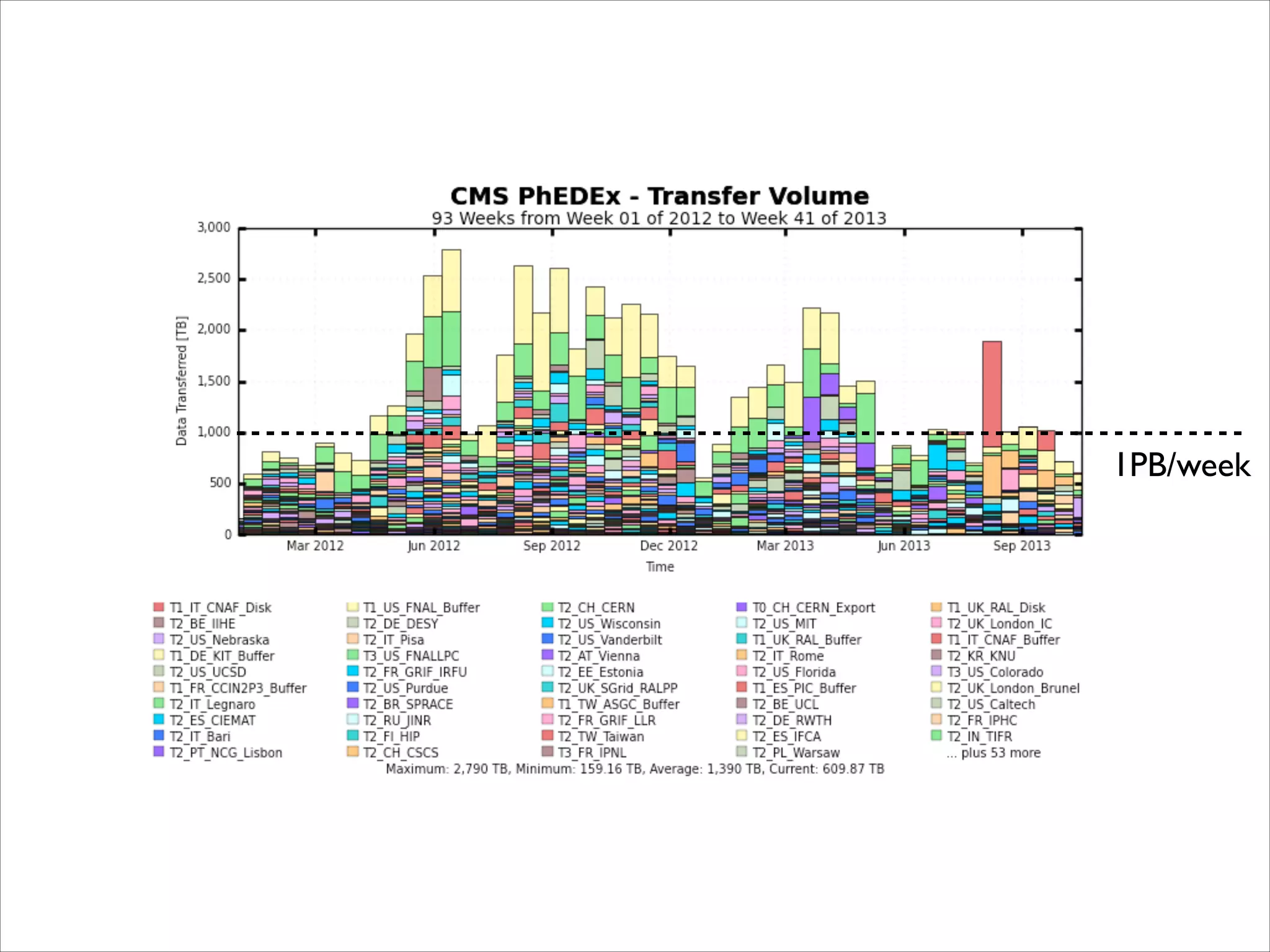
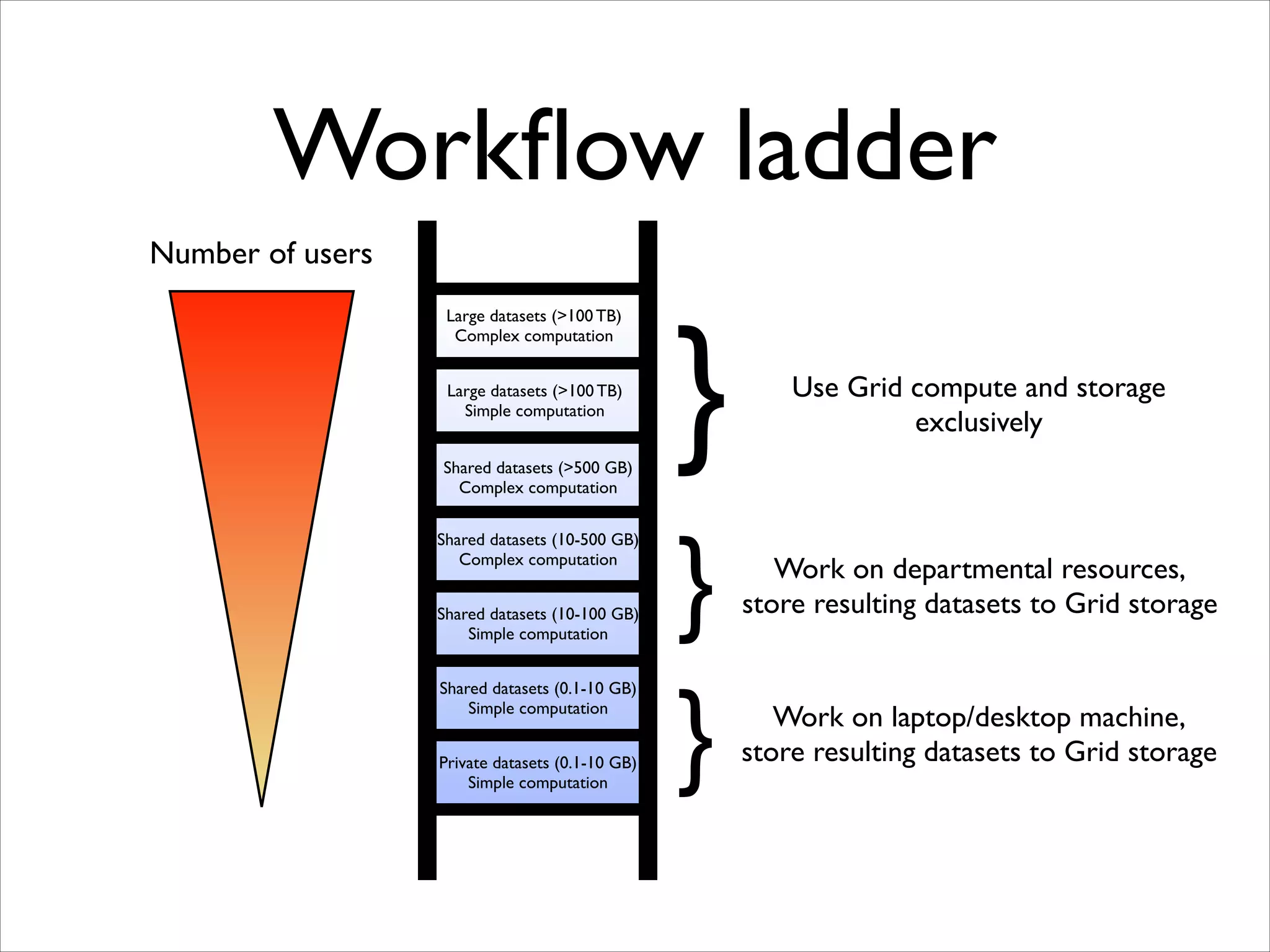
The document discusses the data workflow and processing lifecycle of the Large Hadron Collider (LHC), illustrating the stages from data detection to analysis. It emphasizes the extensive data management techniques required due to massive data volumes, involving multiple sites and complex computational resources. Additionally, it addresses challenges and strategies for engaging users and optimizing workflows in big data environments.